openGauss 7.0.0-RC2:Bypass 与 MMAP 技术革新,提升 AI 核心场景数据库性能
openGauss 7.0.0-RC2版本通过创新技术大幅提升AI场景性能表现
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
引言
在 2025 年,openGauss 作为华为开源的企业级关系型数据库管理系统,继续推动数据库技术向 AI 原生方向演进。最新发布的 openGauss 7.0.0-RC2 版本(发布日期:2025-10-11),以其创新特性进一步强化了在 AI、向量数据库和 RAG(Retrieval-Augmented Generation)场景下的性能。该版本生命周期为 6 个月,重点引入 Bypass 和 MMAP 两大技术特性,针对向量检索等高频 AI 操作进行优化。同时,结合灵衢(UnifiedBus)超节点互联协议、资源池化 HTAP 行列融合、内存语义算子以及基于内存池的共享内存机制,openGauss 7.0.0-RC2 为企业级 AI 应用提供了更高效、可靠的数据库支撑。
这些特性不仅提升了数据库的执行效率,还在确保 ACID 一致性的前提下,突破了传统 I/O 和内存管理的瓶颈。以下将详细解读这些技术要点、实际性能表现、使用示例以及在 AI 生态中的价值。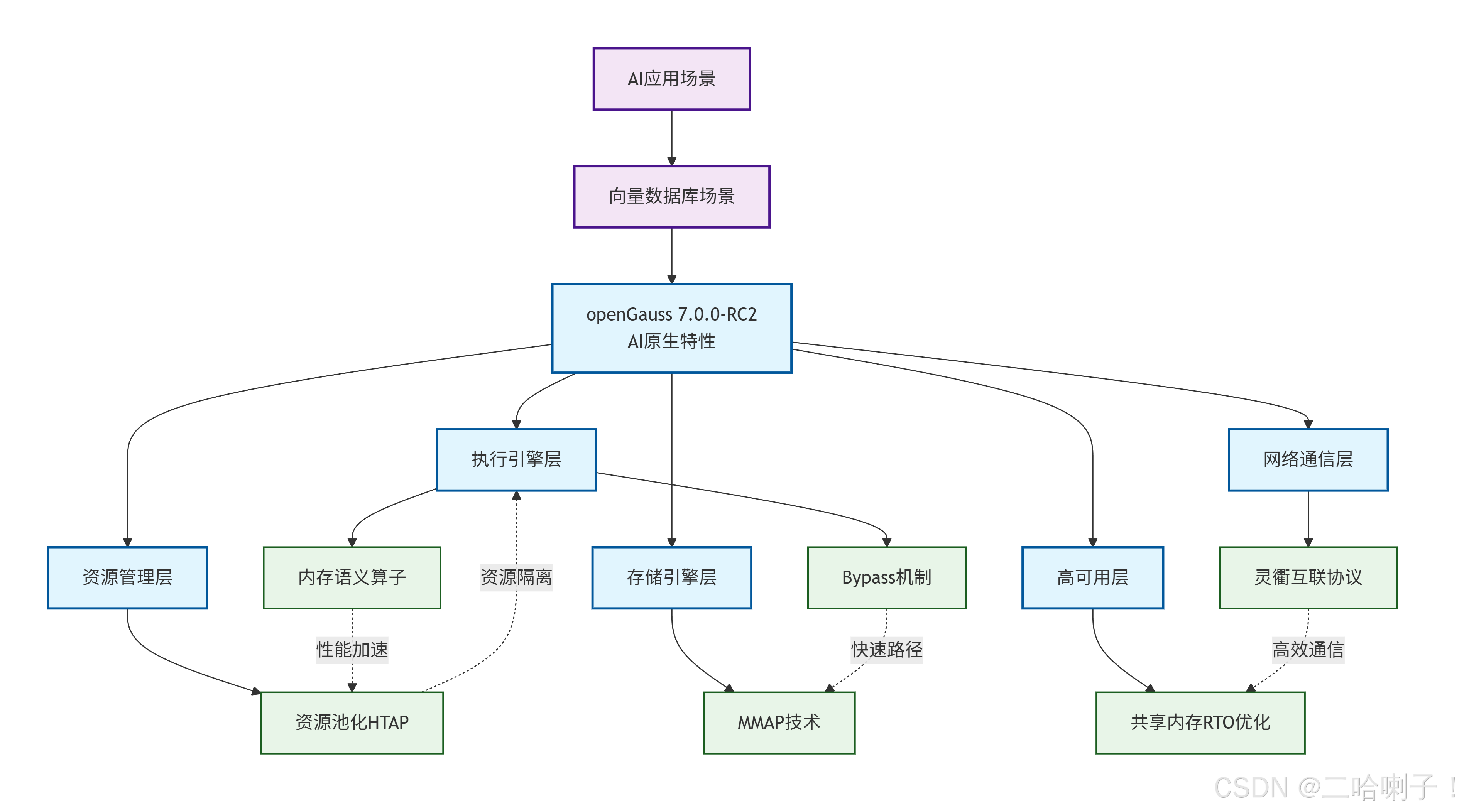
Bypass 机制:按需简化,效率跃升
openGauss 7.0.0-RC2 创新性地推出 Bypass 机制,这是一种基于场景优化的技术,通过精准识别可简化的操作路径,在不破坏数据库 ACID 特性的前提下,跳过非核心流程,实现关键操作的效率提升。其核心理念是“按需简化”:针对资源消耗大、冗余度高的环节,如校验、日志记录或交互,选择性绕过,从而为高频场景开辟专属优化通道。
在向量数据库领域,Bypass 机制特别适用于语义搜索、推荐系统和计算机视觉等 AI 核心场景。向量索引检索的效率直接影响 AI 应用的响应速度,而 openGauss 7.0.0-RC2 通过将 Bypass 与向量检索打通,提供精准优化。例如,在高频查询中,系统可识别并省略非必需步骤,同时保障向量计算的准确性和结果完整性。这不仅仅是性能提升,更是工程化落地的灵活手段,帮助用户在极致效率与数据安全之间取得平衡。
Bypass 机制工作流程图如下: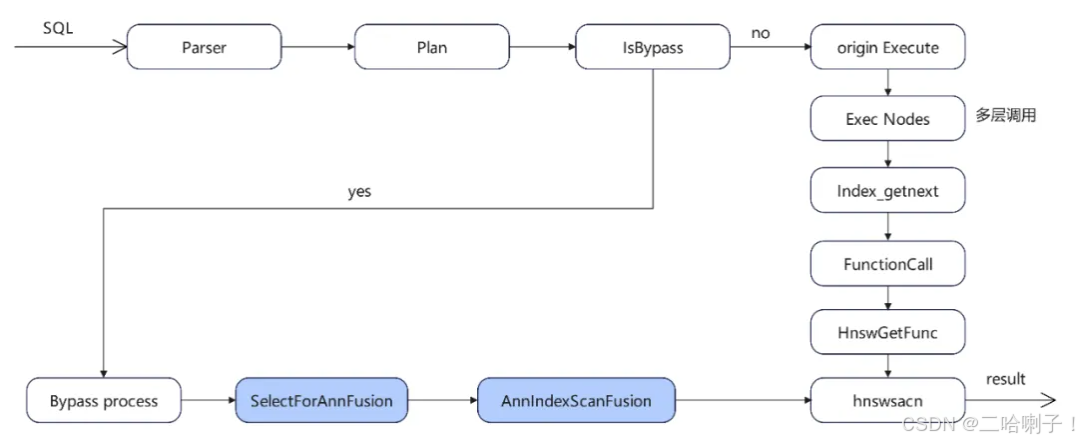
MMAP 技术:突破向量数据库性能检索边界
针对向量数据库的 HNSW(Hierarchical Navigable Small World)索引检索,openGauss 7.0.0-RC2 引入 MMAP(Memory-Mapped Files)技术。这项技术深度整合操作系统级内存管理,将向量索引文件直接映射到进程虚拟地址空间,实现“内存般的直接访问”,从而颠覆传统 I/O 流程。
MMAP 的关键优势包括:
- 零拷贝加速:避免用户态与内核态的数据拷贝,尤其适合向量索引的大文件随机访问场景,读操作效率提升 30%~50%。
- 简化 I/O 链路:摒弃传统的 read/write 系统调用,系统调用开销降低 50%。
在 AI 场景下,MMAP 使毫秒级向量检索成为常态。例如,在亿级向量数据的近似查询中,结合 Bypass 算子复用,单并发 QPS 从 80 提升至 110,提升幅度超过 30%。此外,通过 MMAP + 鲲鹏 NUMA 架构优化 + 线程亲核绑定的组合,高并发 HNSW 检索性能比竞品提升 30%+。
openGauss 7.0.0-RC2 已全面开放 MMAP 功能,支持通过 GUC 参数和索引创建属性启用。
如下是MMAP 技术原理图: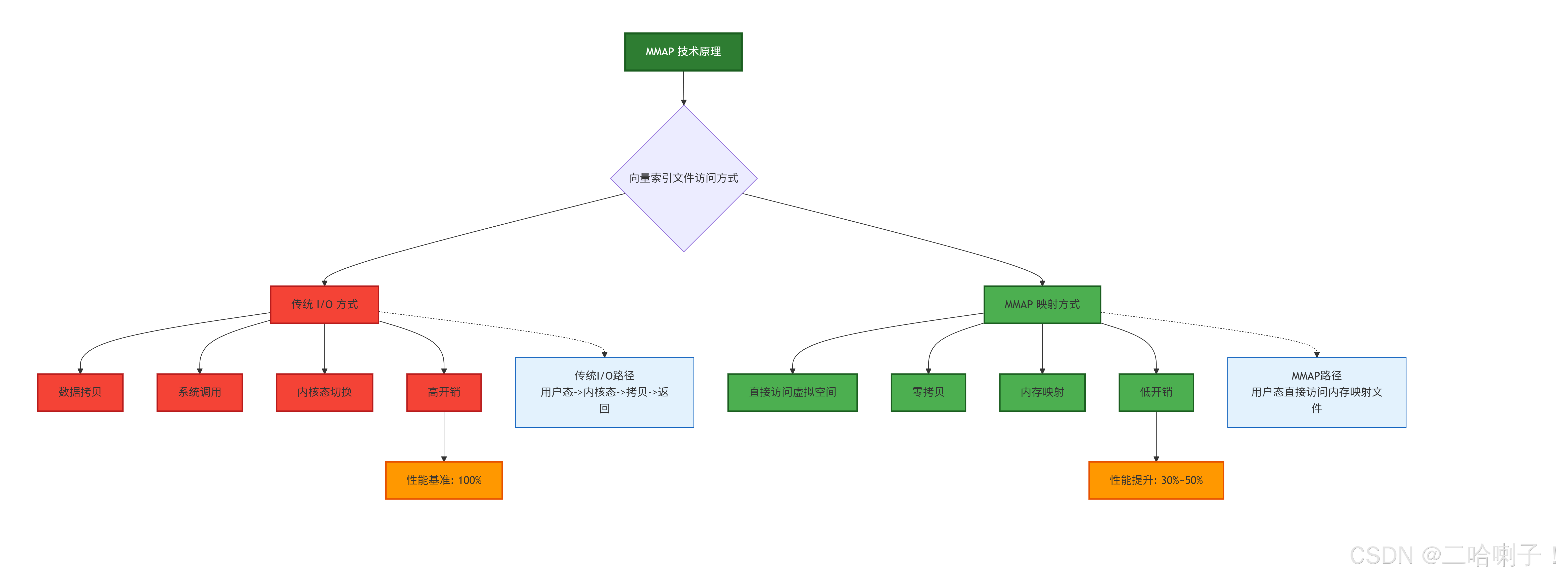
AI 场景实测:性能与可靠性的双重保障
在实际 AI 应用中,Bypass 和 MMAP 的结合显著提升了 openGauss 的表现。以 Cohere 1M 768 维数据集为例,使用 VectorDBBench 测试显示,向量检索响应时间大幅缩短,高并发场景下承载能力翻倍。
- 向量索引检索:毫秒级响应,QPS 提升 30%+。
- 读密集型业务:结合多重优化,并发性能比友商高 30%+。
此外,openGauss 7.0.0-RC2 支持灵衢超节点互联协议,构建“超节点 + 集群”算力解决方案。通过适配灵衢的内存共享和借用能力,提升复杂语句处理和 AP 检索过程,同时减少数据库恢复日志量,降低 RTO(Recovery Time Objective)时间。在 70 万 tpmc 下,开启极致 RTO 时,备机 failover 升主时间小于 6 秒。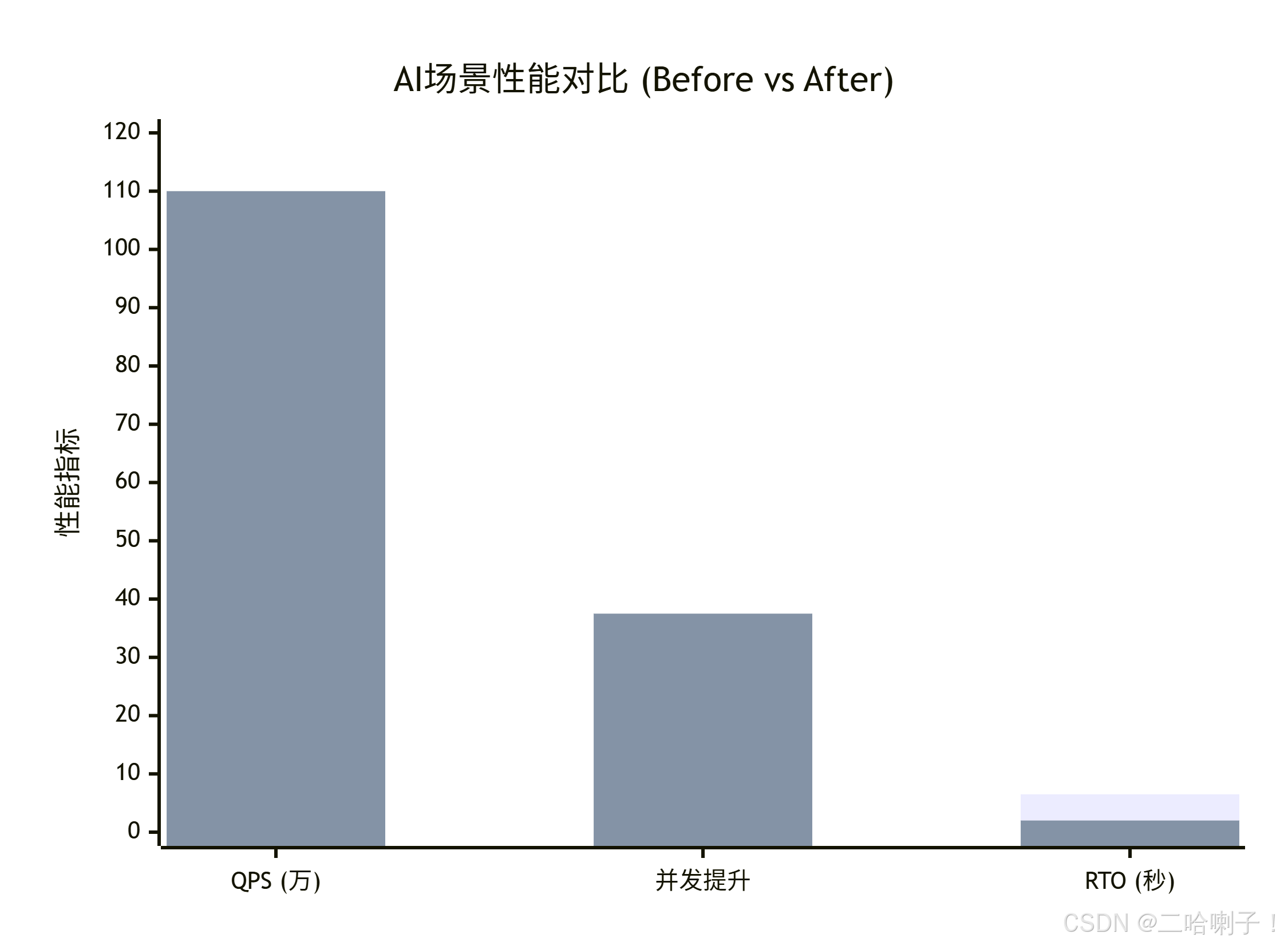
资源池化 HTAP 行列融合与内存语义算子
openGauss 7.0.0-RC2 在资源池化存算分离场景下,实现 HTAP(Hybrid Transactional/Analytical Processing)行列融合。通过主从节点的行列双格式内存模式,支持本地内存和共享内存(灵衢)两种场景。在共享内存模式下,主从节点共享一份列存数据,提升 OLAP 分析能力。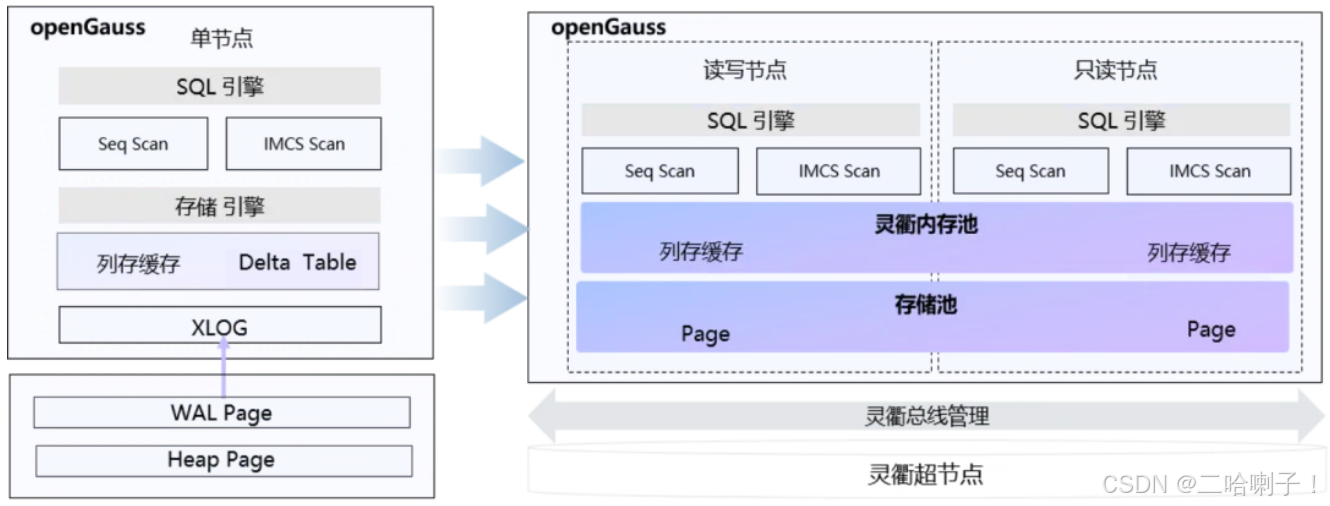
- 行列数据转换:用户可在主节点发起转换请求,本地场景分片存储,共享场景存储到远端内存。
- 基于 DMS 的多机行列缓存同步:确保从节点数据实时性。
- 多机并行列缓存查询:新增 SPQ-CStore-Scan 算子,优化执行计划。
内存语义算子基于灵衢内存借用,支持 HashAgg、HashJoin、Sort 等算子动态借用远端内存,提升内存密集型查询效率 30%(典型 TPCH 1T 场景)。
基于内存池的共享内存进一步降低 RTO,通过 UBS Memory 服务,将修改页异步写入共享内存,故障恢复时跳过部分日志回放。
使用示例
Bypass 与 MMAP 使用
- 前置参数:
- enable_mmap = on(GUC 配置,重启生效)
- hnsw_use_mmap = on(会话级别)
- use_mmap = true(创建索引时)
创建带 MMAP 的 HNSW 索引:
CREATE TABLE items (val vector(3));
CREATE INDEX ON items USING hnsw (embedding vector_l2_ops) WITH (use_mmap=true);
插入数据:
INSERT INTO items (val) VALUES ('[1,2,3]'), ('[4,5,6]');
查询:
SELECT /*+ indexscan(items items_embedding_idx) */ * FROM items ORDER BY embedding <-> '[3,1,2]';
共享内存行列转换
配置:.
ss_htap_cluster_map = 'node1|x.x.x.x|12300,node2|x.x.x.x|12300'
shared_preload_libraries = 'spqplugin'
lmemfabric_client_path = 'lmemfabric_client.so'
ss_max_imcs_cache = 10GB
转换:
ALTER TABLE table_name IMCSTORED WITH SHARE_MEMORY;
多机查询:
set spqplugin.enable_spq = on;
set enable_imcsscan = on;
set spqplugin.cluster_map = 'node1|x.x.x.x|12300,node2|x.x.x.x|12300';
EXPLAIN SELECT imcstored_columns FROM table_name;
内存借用配置
max_rack_memory = 64GB
borrow_work_mem = 16GB
共享内存 RTO 优化
max_smb_memory = 10GB # 主备场景建议
结论
openGauss 7.0.0-RC2 通过 Bypass、MMAP 等特性,以及灵衢协议和资源池化优化,显著提升了 AI 核心场景下的数据库性能。该版本不仅满足了向量检索的高效需求,还强化了可靠性和扩展性,为企业构建 AI 原生基础设施提供了强大支撑。未来,随着 AI 趋势的深化,openGauss 将继续引领数据库创新。
openGauss产品地址:https://opengauss.org/zh/
产品使用说明:https://docs.opengauss.org/zh/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)