从原型到量产:经40+落地案例验证的AI Agent 7步实操路线图
企业AI落地中,AIAgent常面临"实验室可用、生产不可用"的困境。本文基于40+实战案例,提出7步量产路线图:1)选型适配的LLM(不盲目追求大模型);2)集成必需工具与API(定义严格I/O规范);3)定义Agent逻辑(从简单到复杂迭代);4)添加记忆模块(区分短期/长期记忆);5)分配单一明确任务;6)构建多Agent系统(需协调者Agent);7)渐进式部署。核心建
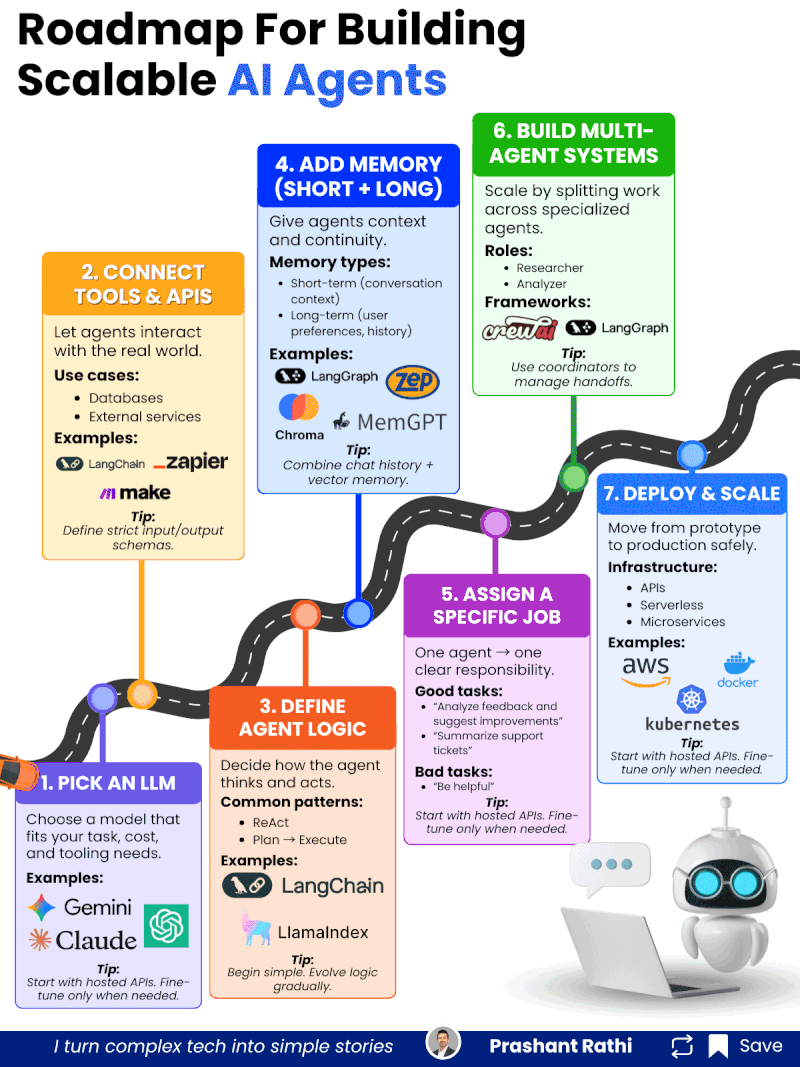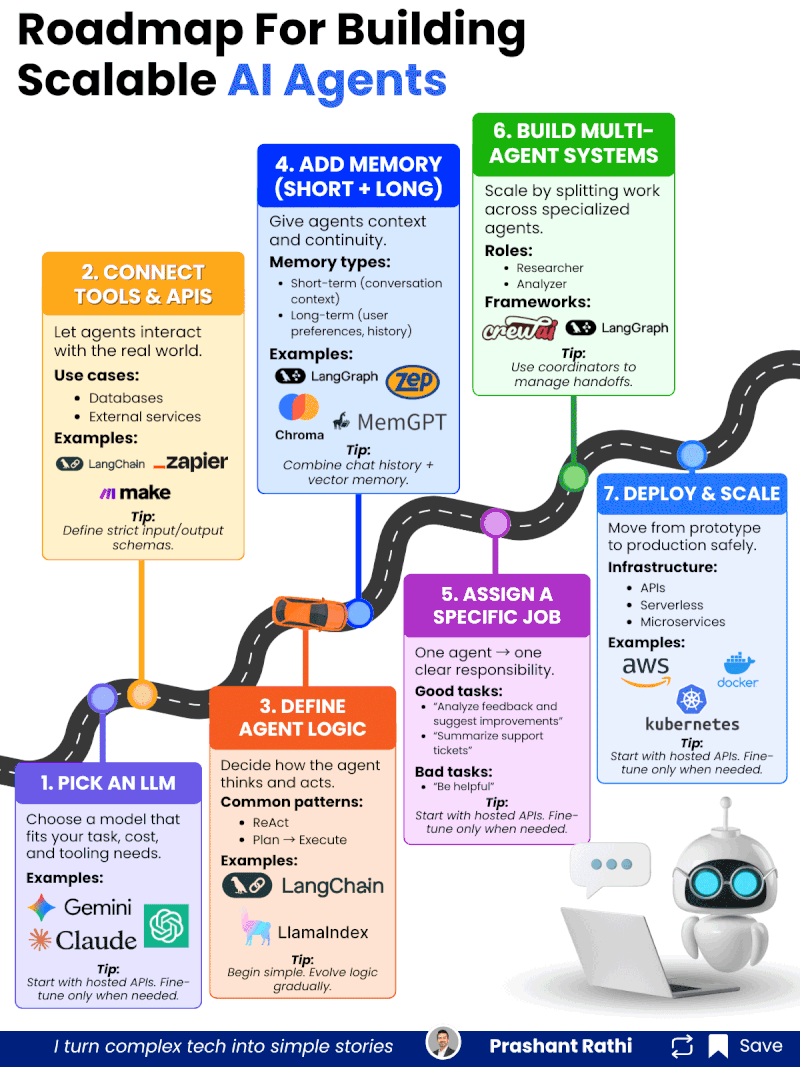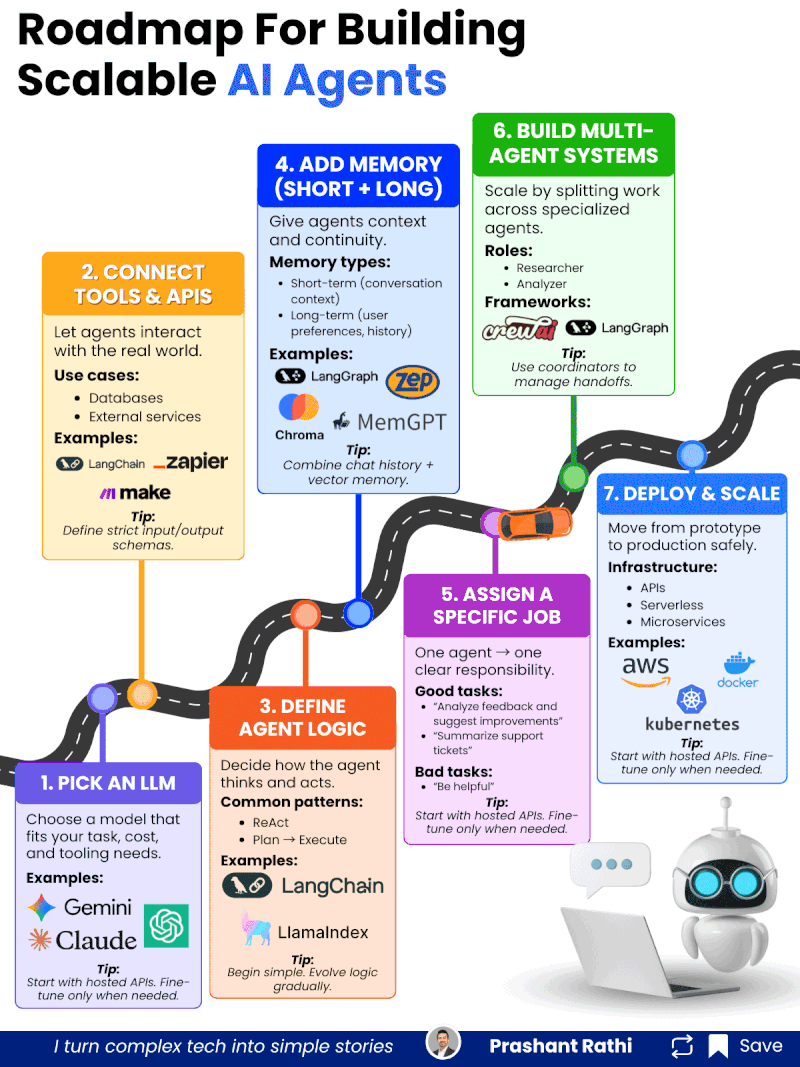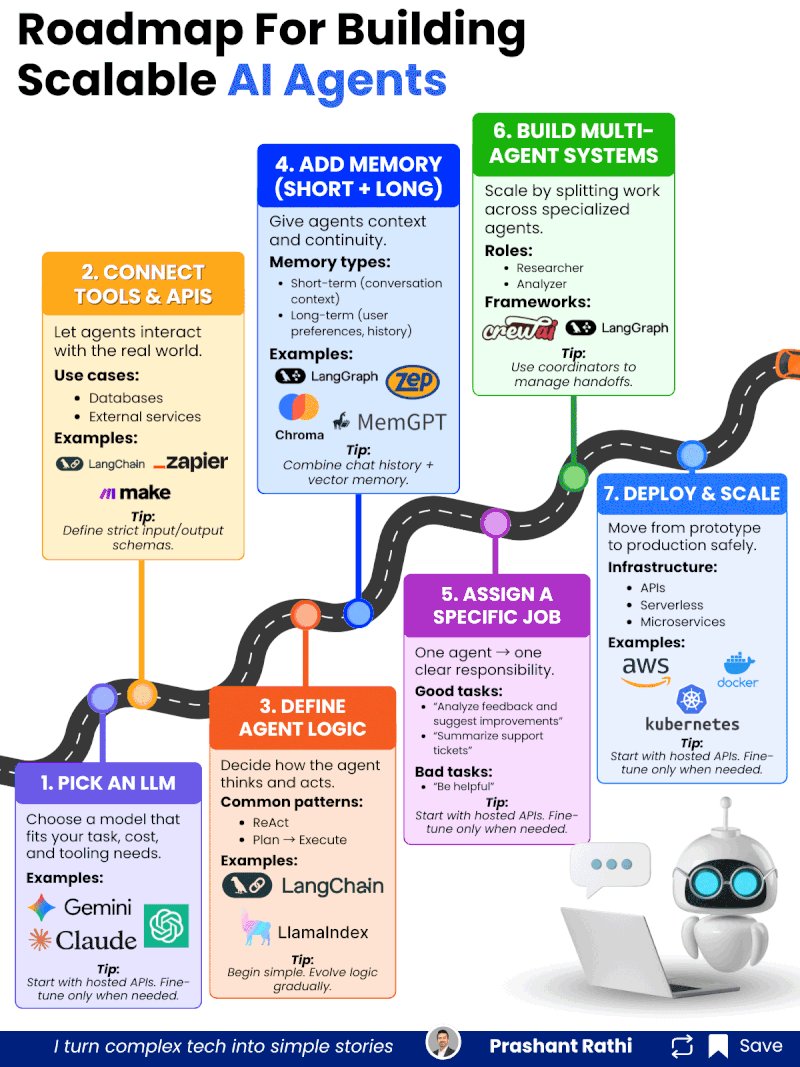
在企业AI落地进程中,AI Agent(智能代理)被寄予厚望——它能够自主理解任务、规划流程、调用工具、交互反馈,甚至协同其他Agent完成复杂工作,有望彻底重构企业的自动化流程与服务模式。但现实中,多数AI Agent项目停留在原型demo阶段,难以突破“实验室可用、生产环境不可用”的瓶颈,要么无法稳定调用工具,要么上下文丢失,要么协同混乱,最终沦为“技术玩具”。
笔者凭借搭建40+生产级Agentic Systems(智能代理系统)的实战经验,总结出一套可复现、高落地的AI Agent量产路线图。这套路线图并非理论推演,而是从无数次试错、迭代中沉淀的实操框架,所有成功部署的Agent系统,均严格遵循这一递进逻辑。本文将详细拆解每一步的核心动作、技术选型、实操技巧,同时揭秘企业落地中最易踩的坑、核心原则及资源分配建议,助力团队高效推进AI Agent从原型到量产的落地。
一、AI Agent量产7步实操路线图(从基础到进阶,循序渐进)
AI Agent的量产核心,不在于“堆砌更多功能”,而在于“层层夯实能力底座”。每一步都是下一步的基础,跳过任何一步,都会导致后续系统稳定性、可靠性大幅下降。以下7步,需严格遵循递进顺序,不可急于求成。
Step 1:选型适配的LLM(核心基础,决定Agent的“思考上限”)
LLM(大语言模型)是AI Agent的“大脑”,其性能、成本、适配性直接决定Agent能否完成核心任务。很多团队在这一步最易陷入“追新追强”的误区——盲目选用参数最大、性能最强的模型,最终导致成本失控、部署复杂,反而影响落地效率。
核心动作:围绕“任务需求、成本预算、工具生态”三大维度,筛选最适配的LLM,而非最优的LLM。
-
选型关键考量:任务复杂度(如简单问答vs复杂逻辑推理)、输入输出长度(如短文本交互vs长文档分析)、响应速度要求(如实时客服vs离线分析)、成本敏感度(如高频调用vs低频使用)、工具集成兼容性(如是否支持LangChain、LlamaIndex等框架)。
-
主流选型示例:Google Gemini(适配多模态任务、实时数据交互,适合需要图文、语音协同的场景)、Anthropic Claude(长文本处理能力突出,上下文窗口大,适合法律、金融等需要深度分析长文档的场景)、OpenAI GPT系列(工具生态完善,适配多数通用场景,性价比适中)。
-
实操核心技巧:优先采用托管API(如Gemini API、Claude API)启动项目,而非本地部署或微调。托管API可大幅降低部署成本、减少运维压力,无需投入大量资源在模型优化、服务器维护上;仅当任务有特殊需求(如行业专属数据、个性化交互逻辑),且托管API无法满足时,再考虑模型微调——微调需投入数据标注、算法优化等资源,成本较高,且需验证微调后的效果是否优于托管API。
误区提醒:不要盲目追求“大模型”,小型专用模型若能适配任务,成本更低、响应更快,落地效率更高。
Step 2:集成工具与API(打破边界,让Agent“链接现实世界”)
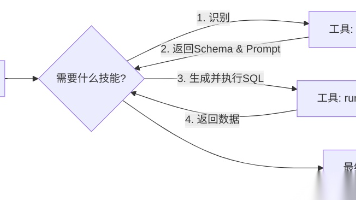
纯LLM只能实现“思考”,无法完成“行动”——要让AI Agent真正产生价值,必须让它链接现实世界的工具、数据和服务,实现“思考-行动”的闭环。这一步的核心是“打通Agent与外部系统的接口”,让Agent能够自主调用工具完成具体任务(如查询数据库、调用第三方服务、执行自动化操作)。
核心动作:明确Agent需完成的“行动类任务”,筛选适配的工具与API,定义严格的交互规范,实现无缝集成。
-
常见应用场景:数据库查询(如从MySQL、PostgreSQL中提取数据并分析)、第三方服务调用(如调用支付API、短信API、地图API)、自动化操作(如批量处理Excel、发送邮件、更新系统数据)、文档交互(如读取PDF、编辑Word)。
-
主流集成工具:LangChain(最常用的Agent工具集成框架,支持多种工具、API的快速集成,提供丰富的工具调用模板,适合复杂工具链编排)、Zapier(无代码工具集成平台,适合非技术团队快速集成第三方服务,无需编写代码)、Make(自动化工作流平台,适配高频、复杂的自动化任务,可与LangChain协同使用)。
-
实操核心技巧:必须定义严格的输入/输出(I/O)schema。Agent调用工具时,需明确“输入什么参数、格式是什么”,工具返回结果时,需明确“输出什么内容、格式是什么”——模糊的I/O规范会导致Agent调用工具失败、数据解析错误,进而影响任务执行效率。例如,调用数据库查询工具时,需定义查询语句的格式、参数类型,以及查询结果的返回格式(如JSON、表格),避免出现语法错误或数据混乱。同时,需添加异常处理逻辑,当工具调用失败(如API超时、参数错误)时,Agent能够自主重试或反馈错误信息,确保流程不中断。
关键提醒:工具集成不在于“多”,而在于“精”——只集成Agent必需的工具,多余的工具会增加系统复杂度、提高出错概率,还会增加成本。
Step 3:定义Agent逻辑(规范行为,让Agent“有章可循”)
有了“大脑”(LLM)和“手脚”(工具/API),还需要“行为准则”——即Agent的思考与行动逻辑。这一步的核心是明确“Agent如何思考、如何决策、如何行动”,避免Agent出现“思考混乱、行动失控”的问题(如反复调用同一工具、忽略关键步骤、做出不符合预期的决策)。
核心动作:基于任务需求,选择合适的Agent逻辑模式,从简单逻辑起步,逐步迭代优化。
-
常见逻辑模式:
-
ReAct模式(最基础、最常用):遵循“思考(Reason)→行动(Act)→观察(Observe)”的循环,Agent先分析任务、思考需要执行的动作,再调用工具执行,最后根据执行结果调整下一步动作,适合简单的单任务流程。
-
Plan→Execute模式(适合复杂任务):Agent先将复杂任务拆解为多个简单子任务,制定详细的执行计划,再逐步执行每个子任务,最后汇总结果,适合需要多步骤协同的复杂任务(如市场分析、报告生成)。
-
-
主流实现框架:LangChain(提供ReAct、Plan→Execute等多种逻辑模板,可灵活定制Agent的思考流程)、LlamaIndex(侧重文档检索与知识整合,适合需要基于知识库进行思考决策的Agent)。
-
实操核心技巧:切忌一开始就设计复杂逻辑,应从最简单的逻辑起步,逐步迭代优化。例如,初期可实现“单一任务→单一工具调用”的简单逻辑,验证流程通顺后,再添加“多步骤决策”“异常处理”“优先级排序”等复杂逻辑。复杂逻辑不仅会增加开发难度,还会提高调试成本,且易出现逻辑漏洞——简单、可靠的逻辑,远比复杂、不完善的逻辑更易落地。同时,需将逻辑模块化,便于后续修改、扩展。
Step 4:添加记忆模块(赋予连续性,让Agent“记住过往”)
默认情况下,LLM不具备记忆能力——每次交互都是“孤立的”,Agent无法记住上一轮的对话内容、用户偏好、任务进度,导致无法实现个性化交互、连续任务执行(如多轮对话、长期项目跟进)。记忆模块是AI Agent从“一次性交互”升级为“持续性服务”的关键,其核心是让Agent具备“短期记忆”和“长期记忆”,实现上下文的连续性。
核心动作:区分短期记忆与长期记忆,选择合适的记忆存储工具,实现“记忆存储-检索-更新”的闭环。
-
记忆类型及作用:
-
短期记忆(Short-term Memory):主要存储当前对话上下文、近期任务进度(如“用户上一轮要求分析某份数据”“当前已完成3个子任务”),作用是维持单轮或多轮交互的连贯性,避免重复提问、逻辑断裂。
-
长期记忆(Long-term Memory):主要存储用户偏好、历史交互记录、行业知识、任务模板等长期有效信息(如“用户喜欢简洁的报告格式”“某客户的历史合作数据”),作用是实现个性化服务、复用过往经验,提升Agent的智能化程度。
-
-
主流记忆工具:LangGraph(适合构建复杂的记忆流,支持记忆的动态更新与关联)、Zep(轻量级记忆服务,专注于对话记忆的存储与检索,部署简单)、Chroma(向量数据库,适合存储长期记忆中的非结构化数据,如文档、对话记录,可快速检索相关记忆)、MemGPT(专注于长程记忆管理,解决LLM上下文窗口有限的问题,适合需要长期跟进的任务)。
-
实操核心技巧:最优方案是“聊天记录+向量记忆”结合使用。将短期记忆(聊天记录)存储在轻量化工具(如Zep)中,确保交互连贯性;将长期记忆(用户偏好、文档知识)转化为向量嵌入,存储在向量数据库(如Chroma)中,便于快速检索。同时,需设置记忆的“过期机制”和“清理规则”,避免记忆冗余(如过期的对话记录、无用的临时数据),降低存储成本,提升检索效率。此外,记忆的更新要实时——当用户偏好、任务进度发生变化时,需及时更新记忆,确保Agent的决策符合最新情况。
Step 5:分配具体任务(聚焦核心,让Agent“术业有专攻”)
很多团队在落地AI Agent时,会陷入“全能Agent”的误区——试图让一个Agent完成所有任务(如“既要处理客服咨询,又要生成报告,还要管理项目进度”),最终导致Agent精力分散、每个任务都做不好,稳定性极差。AI Agent落地的关键的是“专注”——一个Agent只承担一个明确的、具体的职责,实现“术业有专攻”。
核心动作:拆解业务需求,为每个Agent分配单一、明确的任务,明确任务边界与输出标准。
-
优质任务示例:“分析用户反馈,提炼核心问题并给出改进建议”“汇总每日客户支持工单,生成简洁的日报(包含工单数量、核心问题、处理进度)”“监控数据库异常,当出现数据波动时,发送告警并初步分析原因”——这类任务目标明确、边界清晰、有可衡量的输出,Agent能够精准落地。
-
劣质任务示例:“做一个有用的Agent”“帮助团队提高效率”“处理所有客户相关的工作”——这类任务范围过宽、边界模糊、无法衡量效果,Agent无法明确思考方向,更无法落地执行,最终只会沦为“无效原型”。
-
实操核心技巧:任务分配需遵循“单一职责原则”,一个Agent只做一件事,且做到极致。同时,任务难度要循序渐进——初期分配简单、高频、标准化的任务(如数据汇总、简单咨询),验证Agent的稳定性后,再逐步分配复杂、个性化的任务(如深度分析、决策建议)。此外,需明确每个Agent的输入、输出标准,便于后续与其他Agent协同(若需),也便于评估Agent的落地效果。
关键原则:一个可靠的“专才Agent”,远比一个混乱的“全能Agent”更有生产价值。
Step 6:构建多Agent系统(规模化扩展,实现复杂任务协同)
当单一Agent能够稳定完成自身任务后,若需处理更复杂的业务场景(如“市场调研→报告生成→方案优化→客户推送”这类多环节协同的任务),再考虑构建多Agent系统——通过多个专业Agent的分工协作,实现“1+1>2”的效果。这一步是AI Agent规模化落地的关键,但也是最易踩坑的一步。
核心动作:基于业务流程,拆分角色、明确分工,选择合适的协同框架,实现Agent间的高效交接与协同。
-
常见Agent角色分工:根据复杂任务的流程,拆分出不同专业角色的Agent,例如:研究员Agent(负责数据采集、市场调研)、分析师Agent(负责数据处理、核心结论提炼)、执行者Agent(负责报告生成、任务落地)、审核者Agent(负责结果校验、错误修正)。
-
主流协同框架:CrewAI(专门用于构建多Agent协同系统,支持角色定义、任务分配、协同规则设置,上手简单,适合快速搭建协同场景)、LangGraph(通过图结构定义Agent间的交互流程,适合复杂的、多环节的协同任务,可灵活定制交接逻辑)。
-
实操核心技巧:必须设置“协调者Agent”(Coordinator),专门负责Agent间的任务交接、冲突处理、进度管控。多Agent协同的核心痛点是“交接混乱、职责不清”——例如,研究员Agent完成调研后,无法精准将数据传递给分析师Agent,或多个Agent同时处理同一任务导致冲突。协调者Agent的作用就是解决这些问题,制定交接规则(如数据格式、传递时机),监控任务进度,当出现冲突时及时调整,确保整个协同流程顺畅高效。此外,多Agent系统的复杂度要与业务需求匹配,不要为了“多Agent”而搭建多Agent——若单一Agent可完成,无需强行拆分。
Step 7:部署与规模化(安全落地,实现生产级稳定运行)
当单一Agent或多Agent系统在实验室环境中验证通过后,就需要进入“部署与规模化”阶段——将原型转化为生产级系统,确保其在真实业务场景中稳定、高效、安全运行,并能够根据业务需求灵活扩展。这一步的核心是“保障稳定性、安全性,降低运维成本”。
核心动作:选择合适的部署基础设施,完成环境适配、性能优化、监控告警,逐步实现规模化扩展。
-
主流部署基础设施:
-
云服务API(如AWS API Gateway、阿里云API网关):适合托管Agent服务,提供高可用、高并发支持,无需投入大量资源在服务器维护上。
-
Serverless(无服务器架构):适合流量波动较大的场景(如高峰时段调用频繁、低谷时段调用较少),可实现“按需付费”,降低运维成本,自动扩展资源。
-
容器化与集群管理(Docker+Kubernetes):适合复杂的多Agent系统,可实现环境一致性、快速部署、弹性扩展,便于运维管理。
-
-
实操核心技巧:部署过程需遵循“循序渐进”原则——先进行灰度发布(仅开放给小部分用户或业务场景),验证系统稳定性、响应速度、错误率等指标,解决出现的问题后,再逐步全面上线。同时,需搭建完善的监控告警系统,实时监控Agent的运行状态(如调用成功率、响应时间、错误类型),当出现异常(如API超时、工具调用失败、记忆丢失)时,及时告警并自动恢复(如重试、切换备用工具),确保生产环境不中断。此外,需做好数据安全防护——Agent调用工具、交互数据时,需加密传输与存储,严格控制权限,避免数据泄露;同时,做好版本管理,便于后续迭代升级、回滚。
二、企业落地AI Agent最易踩的坑(90%团队栽在这里)
结合40+落地案例的经验,笔者发现,多数团队无法实现AI Agent量产,核心不是技术能力不足,而是“急于求成、跳过基础步骤”——最常见的错误,就是跳过Step 1-5,直接进入Step 6(构建多Agent系统),试图通过“堆砌Agent数量”实现规模化,最终导致系统彻底失败。
跳过基础步骤的典型后果:
-
上下文丢失:未做好记忆模块(Step 4),Agent无法记住过往交互内容,多轮对话逻辑断裂,甚至重复执行同一任务。
-
工具调用不可靠:未定义严格的I/O schema(Step 2)、未优化Agent逻辑(Step 3),导致Agent频繁调用工具失败,或调用错误的工具,无法完成核心任务。
-
协同混乱:单一Agent未实现稳定落地(Step 5),就搭建多Agent系统,Agent间职责不清、交接混乱,出现任务遗漏、重复执行、冲突等问题,整个系统陷入无序状态。
-
生产环境失败:未经过充分的原型验证(Step 1-5),直接部署多Agent系统,导致系统稳定性极差、错误率居高不下,无法适应真实业务场景的复杂需求,最终被迫下线。
本质原因:多Agent系统是“能力的叠加”,而非“数量的堆砌”。如果每个单一Agent都无法稳定运行、无法精准完成自身任务,再多的Agent叠加,也只会放大问题,而非解决问题。
三、AI Agent落地的核心建议(经实战验证,可直接复用)
要实现AI Agent的成功量产,核心是“回归基础、拒绝急躁”,笔者结合经验,给出3条可直接复用的核心建议:
1. 资源分配:60%的时间投入Step 1-5
不要急于搭建多Agent系统,应将60%的时间、人力、资源投入到Step 1-5(LLM选型、工具集成、逻辑定义、记忆添加、任务分配),先实现“单一Agent的精通”——确保单一Agent能够稳定、高效、精准地完成自身任务,调用工具成功率、任务完成率达到90%以上,再考虑Step 6-7(多Agent协同、部署规模化)。
资源分配参考:30%时间用于Step 1-3(基础能力搭建),20%时间用于Step 4-5(能力强化与落地验证),10%时间用于Step 6-7(规模化扩展)。
2. 核心原则:单一Agent精通 > 多Agent复杂
记住:可规模化的AI Agent,不是靠“增加更多Agent”实现的,而是靠“掌握每一层能力底座”实现的。一个能够稳定完成任务、可靠性达标的单一Agent,胜过十个无法稳定运行、逻辑混乱的Agent。
落地优先级:先把“单一Agent”做到极致,再考虑“多Agent协同”;先解决“能不能用”,再解决“能不能规模化”。
3. 迭代逻辑:小步快跑,持续优化
AI Agent的落地不是“一蹴而就”的,而是一个持续迭代的过程。不要一开始就追求“完美系统”,应从最简单的原型起步(如“单一任务+单一工具+简单逻辑”),逐步添加记忆、优化逻辑、扩展任务,每迭代一次,就验证一次效果,解决出现的问题,逐步提升系统的稳定性与实用性。
迭代重点:每次迭代只优化一个核心能力(如本次迭代优化工具调用成功率,下次迭代优化记忆检索效率),避免多方面同时优化,导致问题无法定位。
四、总结:AI Agent量产的本质,是“夯实基础、循序渐进”
AI Agent的量产,从来不是“技术堆砌”的游戏,而是“层层递进、步步夯实”的工程实践。笔者搭建40+生产级Agent系统的核心经验,就是“不跳过任何一步,不急于求成”——LLM选型决定基础,工具集成打破边界,逻辑定义规范行为,记忆模块赋予连续,任务分配聚焦核心,多Agent协同实现扩展,部署规模化保障落地。
最后,不妨问问自己:你当前正处于这7步中的哪一步?你是否在急于跳过某一步,追求“更快的规模化”?
记住:AI Agent的落地,慢即是快。先掌握每一层能力底座,再追求扩展与规模化,才能真正实现从原型到量产的突破,让AI Agent真正为业务创造价值。
PS. 本文观点仅代表笔者个人,不代表本人雇主(麦肯锡公司)及其关联机构的观点、政策或立场。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)