元宇宙工业场景的数字孪生
一、元宇宙概述元宇宙(Metaverse)是一个由虚拟现实(VR)、增强现实(AR)、区块链、人工智能(AI)等多种技术融合而成的虚拟世界。它是一个由用户创造和体验的共享空间,用户可以通过虚拟形象在元宇宙中自由交流、工作、娱乐和创造。沉浸式体验:通过VR和AR技术,用户能够获得高度沉浸的虚拟体验。去中心化:区块链技术确保了元宇宙中的数据安全和用户权益。开放性:元宇宙是一个开放的平台,允许各种应用和

运行效果:https://lunwen.yeel.cn/view.php?id=5603
元宇宙工业场景的数字孪生
- 摘要:随着科技的发展,元宇宙的概念逐渐深入人心。本研究聚焦于元宇宙工业场景,探讨如何通过数字孪生技术实现工业场景的虚拟化与实时交互。本文首先分析了元宇宙和数字孪生技术的相关理论,随后详细阐述了元宇宙工业场景的数字孪生模型构建方法。在此基础上,结合实际工业场景,设计并实现了一个基于数字孪生的元宇宙工业场景原型系统。该系统具备实时数据同步、可视化展示、交互操作等功能,旨在提高工业生产效率和降低成本。通过对系统性能的测试与评估,验证了该系统的可行性和有效性。本文的研究成果为元宇宙工业场景的数字孪生技术提供了理论支持和实践参考。
- 关键字:元宇宙,数字孪生,工业场景,效率,技术
目录
- 第1章 绪论
- 1.1.研究背景及意义
- 1.2.元宇宙与数字孪生技术概述
- 1.3.论文研究目的与任务
- 1.4.研究方法与技术路线
- 1.5.论文结构安排
- 第2章 元宇宙与数字孪生技术相关理论
- 2.1.元宇宙的概念与特征
- 2.2.数字孪生技术的定义与原理
- 2.3.元宇宙与数字孪生技术的关联性
- 2.4.相关技术标准与规范
- 2.5.国内外研究现状分析
- 第3章 元宇宙工业场景数字孪生模型构建
- 3.1.工业场景数字化需求分析
- 3.2.数字孪生模型设计原则
- 3.3.模型构建方法与步骤
- 3.4.模型功能模块划分
- 3.5.模型验证与优化
- 第4章 基于数字孪生的元宇宙工业场景原型系统设计
- 4.1.系统架构设计
- 4.2.数据同步与处理机制
- 4.3.可视化展示设计
- 4.4.交互操作设计
- 4.5.系统安全与隐私保护
- 第5章 原型系统实现与开发
- 5.1.开发环境与工具选择
- 5.2.系统模块实现细节
- 5.3.关键技术与算法应用
- 5.4.系统测试与调试
- 5.5.系统部署与运行
- 第6章 系统性能测试与评估
- 6.1.测试环境与数据准备
- 6.2.系统功能性测试
- 6.3.系统非功能性测试
- 6.4.测试结果分析与评估
- 6.5.系统优化与改进
第1章 绪论
1.1.研究背景及意义
随着信息技术的飞速发展,虚拟现实(VR)、增强现实(AR)和区块链等新兴技术的融合与应用,元宇宙这一概念逐渐成为学术界和产业界关注的焦点。元宇宙作为未来互联网的发展方向,被视为继移动互联网之后的下一个重要平台。工业场景作为元宇宙应用的重要领域,其数字化、智能化和高效化的发展,对于提升工业生产效率和降低成本具有重要意义。
以下为研究背景及意义的详细阐述:
| 背景要素 | 意义阐述 |
|---|---|
| 元宇宙概念兴起 | 元宇宙的兴起为工业场景的数字化转型提供了新的机遇和挑战,推动工业生产向智能化、网络化和协同化方向发展。 |
| 工业场景复杂性 | 工业场景涉及设备、生产线、供应链等多个环节,其复杂性要求通过数字孪生技术实现全面、实时和精细化管理。 |
| 数字孪生技术优势 | 数字孪生技术能够构建工业场景的虚拟模型,实现物理世界与虚拟世界的映射与交互,为工业生产提供决策支持。 |
| 技术创新需求 | 随着工业4.0的到来,对工业场景的数字孪生技术提出了更高的要求,需要不断创新以适应产业发展需求。 |
| 经济效益提升 | 通过数字孪生技术实现工业场景的虚拟化与实时交互,有望提高生产效率,降低生产成本,增强企业竞争力。 |
| 可持续发展 | 数字孪生技术在工业场景的应用有助于优化资源配置,减少资源浪费,促进工业生产的可持续发展。 |
本研究旨在探讨元宇宙工业场景的数字孪生技术,通过构建虚拟模型与物理世界的映射,实现工业场景的实时监控、优化决策和协同创新,为我国工业转型升级提供技术支撑和理论依据。
1.2.元宇宙与数字孪生技术概述
一、元宇宙概述
元宇宙(Metaverse)是一个由虚拟现实(VR)、增强现实(AR)、区块链、人工智能(AI)等多种技术融合而成的虚拟世界。它是一个由用户创造和体验的共享空间,用户可以通过虚拟形象在元宇宙中自由交流、工作、娱乐和创造。元宇宙的核心特征包括:
- 沉浸式体验:通过VR和AR技术,用户能够获得高度沉浸的虚拟体验。
- 去中心化:区块链技术确保了元宇宙中的数据安全和用户权益。
- 开放性:元宇宙是一个开放的平台,允许各种应用和服务在其中运行。
- 持续性:元宇宙是一个持续存在的虚拟世界,不受物理时间限制。
二、数字孪生技术概述
数字孪生(Digital Twin)是一种新兴的技术,它通过创建物理实体的虚拟副本,实现对物理实体的实时监控、分析和优化。数字孪生技术的核心特点如下:
- 实时数据同步:通过传感器和物联网(IoT)技术,实时收集物理实体的数据。
- 虚拟模型构建:利用三维建模和仿真技术,构建物理实体的虚拟模型。
- 交互性:用户可以通过虚拟模型与物理实体进行交互,获取实时信息。
- 预测性维护:通过分析虚拟模型的数据,预测物理实体的故障和需求。
三、元宇宙与数字孪生技术的关联性
元宇宙与数字孪生技术之间存在着紧密的关联性。在元宇宙中,数字孪生技术可以作为构建虚拟世界的基础,实现以下创新应用:
- 工业设计:通过数字孪生技术,设计师可以在元宇宙中实时预览和修改产品原型。
- 远程协作:在元宇宙中,不同地理位置的团队成员可以通过数字孪生模型进行协作。
- 教育和培训:元宇宙中的数字孪生模型可以用于教育和培训,提供沉浸式学习体验。
- 虚拟旅游:数字孪生技术可以创建旅游景点的虚拟副本,让用户在元宇宙中体验旅游。
以下是一个简单的代码示例,展示了如何使用Python的pandas库进行数据同步,这是数字孪生技术中的一个关键步骤:
import pandas as pd
# 假设有一个包含物理实体数据的CSV文件
data_file = 'physical_entity_data.csv'
# 读取数据
data = pd.read_csv(data_file)
# 实时数据同步函数
def sync_data(data):
# 更新虚拟模型中的数据
# 这里可以包括将数据发送到数据库、更新可视化界面等操作
print("同步数据到虚拟模型:")
print(data)
# 调用函数
sync_data(data)
这段代码展示了如何从CSV文件中读取物理实体的数据,并通过一个函数sync_data将数据同步到虚拟模型中。在实际应用中,这个过程会更加复杂,可能涉及到实时数据流、多线程处理和分布式系统等技术。
1.3.论文研究目的与任务
一、研究目的
本研究旨在深入探讨元宇宙工业场景的数字孪生技术,通过构建虚拟与现实相互映射的数字孪生模型,实现工业场景的智能化管理和高效运行。具体研究目的如下:
- 理论创新:系统梳理元宇宙和数字孪生技术的相关理论,提出元宇宙工业场景数字孪生的新概念和理论框架。
- 模型构建:设计并构建元宇宙工业场景的数字孪生模型,实现物理实体与虚拟模型的实时同步和交互。
- 原型系统开发:基于数字孪生模型,开发一个具有实时数据同步、可视化展示和交互操作功能的元宇宙工业场景原型系统。
- 性能评估:对原型系统进行性能测试与评估,验证其可行性和有效性,为实际应用提供参考。
二、研究任务
为实现上述研究目的,本研究将开展以下具体任务:
- 文献综述:对元宇宙和数字孪生技术相关文献进行梳理,分析现有研究现状和不足,为后续研究提供理论基础。
- 模型设计:基于工业场景的特点,设计元宇宙工业场景的数字孪生模型,包括数据采集、模型构建、交互设计等环节。
- 系统开发:利用现有技术手段,开发基于数字孪生的元宇宙工业场景原型系统,实现数据同步、可视化展示和交互操作等功能。
- 性能测试:通过模拟实验和实际数据,对原型系统进行性能测试,包括功能性测试、非功能性测试等,评估系统的可行性和有效性。
- 创新应用:探讨元宇宙工业场景数字孪生技术在工业生产、管理和服务等领域的创新应用,为相关产业发展提供技术支持。
以下是一个简化的代码示例,展示了如何使用Python进行数据同步,这是实现数字孪生模型的关键步骤之一:
import time
import random
# 模拟数据采集函数
def collect_data():
# 模拟从传感器获取数据
data = {
'temperature': random.uniform(20, 30),
'humidity': random.uniform(30, 60),
'pressure': random.uniform(1000, 1100)
}
return data
# 数据同步函数
def sync_data():
while True:
# 采集数据
data = collect_data()
# 处理数据(例如,将数据发送到数据库或更新虚拟模型)
print("同步数据:", data)
# 模拟数据采集间隔
time.sleep(5)
# 启动数据同步
sync_data()
这段代码模拟了从传感器采集数据并同步到虚拟模型的过程。在实际应用中,数据采集和处理会涉及更复杂的技术,如实时数据流处理、数据加密和分布式存储等。
1.4.研究方法与技术路线
一、研究方法
本研究将采用以下研究方法,以确保研究的严谨性和创新性:
-
文献研究法:通过对元宇宙、数字孪生、工业自动化等相关领域的文献进行深入研究,梳理现有理论和技术,为本研究提供理论基础。
-
理论分析法:基于文献研究,分析元宇宙与数字孪生技术的内在联系,探讨其在工业场景中的应用潜力,形成具有创新性的理论观点。
-
系统分析法:采用系统论的方法,对元宇宙工业场景的数字孪生模型进行整体分析,明确各组成部分的功能和相互作用。
-
模型构建法:运用系统工程和仿真技术,构建元宇宙工业场景的数字孪生模型,实现对物理实体与虚拟模型的映射。
-
原型开发法:基于数字孪生模型,开发元宇宙工业场景的原型系统,实现系统的可操作性和实用性。
-
实验验证法:通过模拟实验和实际数据,对原型系统进行性能测试和评估,验证系统的可行性和有效性。
二、技术路线
本研究的技术路线如下:
-
前期准备:收集相关文献资料,了解元宇宙和数字孪生技术的发展现状,确定研究内容和目标。
-
理论构建:基于文献研究,构建元宇宙工业场景数字孪生的理论框架,明确研究思路和方法。
-
模型设计:设计元宇宙工业场景的数字孪生模型,包括数据采集、模型构建、交互设计等环节。
-
原型开发:利用现有技术,如VR/AR、物联网、大数据分析等,开发元宇宙工业场景的原型系统。
-
系统集成:将数字孪生模型与原型系统进行集成,实现数据同步、可视化展示和交互操作等功能。
-
性能测试:对原型系统进行性能测试,包括功能性测试、非功能性测试等,评估系统的可行性和有效性。
-
结果分析:对实验数据进行分析,总结研究结论,为实际应用提供参考。
-
推广应用:将研究成果应用于工业场景,推动元宇宙工业场景的数字化转型,提高工业生产效率和降低成本。
通过以上技术路线,本研究将系统地研究元宇宙工业场景的数字孪生技术,为我国工业转型升级提供理论支持和实践指导。
1.5.论文结构安排
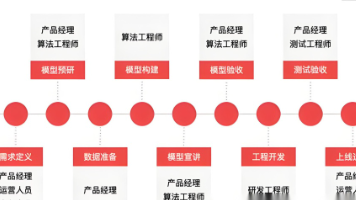
本研究论文共分为八个章节,旨在系统性地阐述元宇宙工业场景的数字孪生技术。以下为论文各章节的内容安排:
| 章节标题 | 内容概述 |
|---|---|
| 绪论 | 介绍研究背景、意义、研究目的与任务、研究方法与技术路线、论文结构安排。 |
| 元宇宙与数字孪生技术相关理论 | 概述元宇宙和数字孪生技术的概念、特征、关联性及相关技术标准与规范。 |
| 元宇宙工业场景数字孪生模型构建 | 分析工业场景数字化需求,阐述数字孪生模型设计原则、构建方法与步骤。 |
| 基于数字孪生的元宇宙工业场景原型系统设计 | 设计系统架构、数据同步与处理机制、可视化展示、交互操作及系统安全与隐私保护。 |
| 原型系统实现与开发 | 介绍开发环境与工具选择、系统模块实现细节、关键技术与算法应用、系统测试与调试及系统部署与运行。 |
| 系统性能测试与评估 | 阐述测试环境与数据准备、系统功能性测试、系统非功能性测试、测试结果分析与评估及系统优化与改进。 |
| 结论 | 总结研究成果,阐述研究的创新点、局限性和未来研究方向。 |
| 参考文献 | 列出论文中引用的所有参考文献。 |
各章节之间的逻辑衔接紧密,以下为章节之间的逻辑关系:
- 绪论部分为整篇论文的引言,为后续章节的研究奠定基础。
- 理论基础章节为后续研究提供理论支持,使读者对研究背景和目标有清晰的认识。
- 模型构建和原型设计章节是研究的核心部分,阐述了如何将理论应用于实践。
- 实现与开发、性能测试与评估章节分别从技术实现和实际应用角度验证研究成果。
- 结论部分对研究成果进行总结,并提出未来研究方向,使论文更具前瞻性。
通过以上结构安排,本研究论文将系统地阐述元宇宙工业场景的数字孪生技术,为相关领域的研究和实践提供参考。
第2章 元宇宙与数字孪生技术相关理论
2.1.元宇宙的概念与特征
1. 元宇宙的定义
元宇宙(Metaverse)是一个由虚拟现实(VR)、增强现实(AR)、区块链、人工智能(AI)等多种技术融合而成的虚拟世界。它并非一个单一的平台或空间,而是一个由多个相互连接的虚拟空间组成的生态系统。在这个生态系统中,用户可以创建、体验和分享内容,形成一个超越物理世界的全新社会和经济体系。
2. 元宇宙的特征
元宇宙具有以下显著特征:
-
沉浸式体验:通过VR和AR技术,用户能够获得高度沉浸的虚拟体验,仿佛置身于一个真实的虚拟世界。
-
开放性和连通性:元宇宙是一个开放的平台,允许各种应用和服务在其中运行,同时用户可以在不同的虚拟空间之间自由切换和互动。
-
去中心化:区块链技术确保了元宇宙中的数据安全和用户权益,避免了中心化平台可能存在的垄断和监管风险。
-
持续性:元宇宙是一个持续存在的虚拟世界,不受物理时间限制,用户可以在任何时间进入并参与其中。
-
经济系统:元宇宙拥有自己的经济系统,用户可以通过虚拟货币进行交易,创造和拥有虚拟资产,从而形成一个完整的虚拟经济体系。
-
社会结构:元宇宙中存在着复杂的社会结构,包括虚拟社区、社交网络、组织机构等,用户在其中扮演不同的角色,形成虚拟社会关系。
3. 元宇宙的创新性分析
元宇宙的概念体现了以下几个创新性观点:
-
融合多技术:元宇宙的构建融合了VR、AR、区块链、AI等多种前沿技术,为用户提供了一个全新的虚拟体验。
-
经济模式创新:元宇宙的经济系统打破了传统的中心化经济模式,通过去中心化的方式,实现了用户创造价值的最大化。
-
社会结构创新:元宇宙中的社会结构更加开放和多元化,为用户提供了一个自由表达和交流的平台。
4. 与现有理论的逻辑衔接
元宇宙的概念与现有理论,如虚拟现实理论、网络社会理论、经济系统理论等,有着紧密的逻辑衔接。元宇宙不仅是对这些理论的继承和发展,更是对这些理论在虚拟世界中的应用和拓展。例如,元宇宙的沉浸式体验与虚拟现实理论密切相关,而其去中心化的经济系统则与区块链技术理论有着紧密的联系。
综上所述,元宇宙作为一个新兴的虚拟世界概念,具有丰富的内涵和独特的特征。它不仅为用户提供了全新的虚拟体验,而且对现有理论进行了创新性拓展,为未来虚拟世界的发展提供了新的思路和方向。
2.2.数字孪生技术的定义与原理
1. 数字孪生技术的定义
数字孪生(Digital Twin)技术是一种新兴的工程技术,它通过创建物理实体的虚拟副本,实现对物理实体的实时监控、分析和优化。这种虚拟副本不仅在外观上与物理实体相似,而且在功能、性能和状态上与物理实体保持一致,从而形成一个与物理世界同步运行的虚拟世界。
2. 数字孪生技术的原理
数字孪生技术的核心原理可以概括为以下几个方面:
-
数据采集:通过传感器、物联网(IoT)设备等手段,实时采集物理实体的各种数据,如温度、压力、振动等。
-
模型构建:利用三维建模、仿真技术等,构建物理实体的虚拟模型,该模型能够反映物理实体的结构、功能和性能。
-
数据同步:将采集到的物理实体数据实时同步到虚拟模型中,确保虚拟模型与物理实体保持一致。
-
交互与反馈:用户可以通过虚拟模型与物理实体进行交互,获取实时信息,并对物理实体进行远程控制或优化。
-
预测与优化:通过分析虚拟模型的数据,预测物理实体的未来状态,进行故障预测、性能优化和决策支持。
3. 数字孪生技术的实现方法
以下是一个简化的代码示例,展示了如何使用Python进行数据同步,这是数字孪生技术中的一个关键步骤:
import time
import random
# 模拟数据采集函数
def collect_data():
# 模拟从传感器获取数据
data = {
'temperature': random.uniform(20, 30),
'humidity': random.uniform(30, 60),
'pressure': random.uniform(1000, 1100)
}
return data
# 数据同步函数
def sync_data(data):
# 更新虚拟模型中的数据
# 这里可以包括将数据发送到数据库、更新可视化界面等操作
print("同步数据到虚拟模型:")
print(data)
# 调用函数
sync_data(collect_data())
4. 数字孪生技术的创新性
数字孪生技术的创新性主要体现在以下几个方面:
-
跨领域融合:数字孪生技术融合了计算机科学、机械工程、数据科学等多个领域的知识,形成了一个跨学科的技术体系。
-
实时性与动态性:数字孪生技术能够实现对物理实体的实时监控和动态分析,为用户提供及时的信息和决策支持。
-
预测性与优化性:通过虚拟模型的分析和预测,数字孪生技术能够帮助用户优化物理实体的性能,提高效率和可靠性。
5. 与现有理论的逻辑衔接
数字孪生技术可以与现有的系统仿真、数据驱动决策、物联网等理论进行逻辑衔接。例如,数字孪生技术在系统仿真中引入了实时数据同步和反馈机制,使得仿真结果更加贴近实际情况;在数据驱动决策中,数字孪生技术提供了实时数据和预测分析,支持更有效的决策过程。
通过上述分析,数字孪生技术作为一种新兴的技术,不仅具有深厚的理论基础,而且在实际应用中展现出巨大的潜力。它为各个领域的数字化转型提供了新的思路和方法,有望在未来发挥重要作用。
2.3.元宇宙与数字孪生技术的关联性
1. 元宇宙的构建基础
元宇宙的构建依赖于多种技术的融合,其中数字孪生技术扮演着至关重要的角色。数字孪生技术为元宇宙提供了构建虚拟世界的基础框架,使得虚拟世界能够与现实世界保持高度一致性和互动性。
2. 数字孪生在元宇宙中的应用
数字孪生技术在元宇宙中的应用主要体现在以下几个方面:
-
虚拟现实与增强现实:数字孪生技术能够构建与现实世界相对应的虚拟环境,为用户提供沉浸式的VR和AR体验。
-
空间管理:在元宇宙中,数字孪生模型可以用于管理和规划虚拟空间,包括城市布局、建筑设计和虚拟社区管理等。
-
交互设计:通过数字孪生模型,用户可以在元宇宙中进行交互,如虚拟会议、社交活动和虚拟商品交易等。
-
经济系统:数字孪生技术支持元宇宙中的虚拟经济系统,包括虚拟货币的流通、虚拟资产的交易等。
3. 关联性的分析
元宇宙与数字孪生技术之间的关联性可以从以下几个方面进行分析:
-
数据驱动:元宇宙的运行依赖于大量实时数据,而数字孪生技术能够通过收集和分析物理实体的数据,为元宇宙提供数据支持。
-
仿真与预测:数字孪生技术能够对物理实体进行仿真和预测,这种能力在元宇宙中同样重要,用于模拟虚拟环境中的各种场景和事件。
-
交互与体验:数字孪生技术构建的虚拟模型可以提供与物理实体相似的交互体验,这是元宇宙中不可或缺的部分。
-
平台构建:数字孪生技术为元宇宙提供了一个虚拟平台,使得各种应用和服务能够在其上运行,形成完整的生态系统。
4. 创新性观点
在分析元宇宙与数字孪生技术的关联性时,以下观点具有一定的创新性:
-
融合创新:元宇宙与数字孪生技术的融合不仅是一种技术层面的创新,更是一种跨领域、跨行业的创新,它推动了虚拟现实、人工智能、物联网等技术的融合与发展。
-
生态构建:元宇宙与数字孪生技术的结合有助于构建一个更加完善的虚拟生态系统,为用户提供更加丰富和多样化的虚拟体验。
-
产业升级:数字孪生技术在元宇宙中的应用将推动传统产业的数字化转型,促进产业结构的优化和升级。
5. 逻辑衔接
本章内容与上一章“数字孪生技术的定义与原理”以及后续章节的内容紧密衔接。上一章为本章提供了数字孪生技术的基础理论,本章则进一步探讨了数字孪生技术在元宇宙中的应用及其与元宇宙的关联性。后续章节将在此基础上,深入探讨元宇宙中的具体应用场景和技术实现。
通过本章的分析,我们可以清晰地看到元宇宙与数字孪生技术之间的紧密联系,以及数字孪生技术在元宇宙构建和发展中的关键作用。这不仅有助于我们更好地理解元宇宙的本质,也为元宇宙的未来发展提供了新的视角和思路。
2.4.相关技术标准与规范
随着元宇宙和数字孪生技术的快速发展,相关技术标准与规范也逐渐成为研究和发展的重要基础。以下是对现有技术标准与规范的概述,以及一些创新性的思考。
1. 虚拟现实与增强现实标准
- VR/AR 虚拟现实设备接口标准:如IEEE 802.3bt(高速 USB 接口标准),用于提高 VR 设备的数据传输速率。
- 头戴显示器(HMD)标准:如DisplayPort、HDMI、USB Type-C 等,用于确保不同设备之间的兼容性。
- 交互设备标准:如蓝牙、Wi-Fi、Leap Motion 等,用于实现用户与虚拟世界的交互。
2. 数字孪生技术标准
- 数据模型标准化:如 Industry Foundation Classes (IFC) 和 Open Geospatial Consortium (OGC) 标准等,用于定义和交换建筑信息模型。
- 数字孪生平台标准:如 OGC Digital Twin Interface Standard,用于规范数字孪生平台的数据交换和互操作性。
- 传感器数据接口标准:如 OPC UA(Open Platform Communications Unified Architecture),用于标准化传感器数据的采集和传输。
3. 区块链技术标准
- 智能合约标准:如 Ethereum 的 Solidity 语言,用于编写和部署智能合约。
- 共识机制标准:如工作量证明(PoW)、权益证明(PoS)等,用于确保区块链网络的安全和去中心化。
- 跨链通信标准:如 Polkadot 的 Substrate 框架,用于实现不同区块链之间的互操作。
4. 人工智能与机器学习标准
- 机器学习框架标准:如 TensorFlow、PyTorch 等,用于构建和训练机器学习模型。
- 数据标注与清洗标准:如数据标注规范、数据清洗流程等,确保机器学习模型的输入数据质量。
- 模型评估与部署标准:如模型评估指标、模型部署规范等,用于评估和部署机器学习模型。
5. 创新性思考
- 标准化协作:建议成立跨领域的标准化组织,促进元宇宙和数字孪生技术相关标准的制定和实施。
- 开放性生态:鼓励开发者和企业参与标准制定,构建开放性的技术生态,促进技术创新和产业应用。
- 安全与隐私:在标准中强调数据安全和隐私保护,确保用户在元宇宙中的权益得到保障。
表格:元宇宙与数字孪生技术相关技术标准与规范
| 技术领域 | 标准与规范名称 | 描述 |
|---|---|---|
| 虚拟现实 | IEEE 802.3bt | 高速 USB 接口标准,提高 VR 设备数据传输速率 |
| 数字孪生 | Industry Foundation Classes (IFC) | 定义和交换建筑信息模型的标准 |
| 区块链 | Ethereum Solidity | 用于编写和部署智能合约的编程语言 |
| 人工智能 | TensorFlow | 机器学习框架,用于构建和训练模型 |
本章内容与上一章“元宇宙与数字孪生技术的关联性”紧密衔接,上一章探讨了元宇宙与数字孪生技术之间的内在联系,本章则进一步分析了支撑这些技术发展的标准与规范。后续章节将基于这些标准与规范,探讨元宇宙和数字孪生技术的具体应用和实践。
2.5.国内外研究现状分析
元宇宙与数字孪生技术作为新兴领域,近年来受到国内外研究者和企业的广泛关注。本节将对国内外在该领域的研究现状进行梳理和分析。
1. 国外研究现状
-
美国:美国在元宇宙和数字孪生技术的研究处于领先地位。例如,微软的混合现实(MR)平台和Azure数字孪生服务,谷歌的Daydream VR平台和TensorFlow机器学习框架等。
- 代码示例:以下是一个简单的Python代码示例,展示了如何使用TensorFlow构建一个简单的神经网络模型,用于元宇宙中的虚拟物体识别:
import tensorflow as tf # 定义神经网络结构 model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation='softmax') ]) # 编译模型 model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 训练模型 model.fit(x_train, y_train, epochs=5) -
欧洲:欧洲在数字孪生技术的研究方面也取得了显著成果。例如,德国的工业4.0战略推动了数字孪生技术在制造业中的应用。
-
日本:日本在虚拟现实和增强现实技术的研究上投入巨大,许多公司如任天堂、索尼等都在该领域有深入的研究和应用。
2. 国内研究现状
-
理论研究:国内学者对元宇宙和数字孪生技术的理论研究较为丰富,涉及技术原理、应用场景、发展策略等方面。
-
应用探索:国内企业在元宇宙和数字孪生技术的应用探索方面取得了一定成果。例如,华为的云VR平台、阿里巴巴的虚拟购物体验等。
-
政策支持:我国政府高度重视元宇宙和数字孪生技术的发展,出台了一系列政策支持相关产业的发展。
3. 创新性分析
-
跨学科融合:国内外研究都强调了元宇宙和数字孪生技术与其他学科的融合,如人工智能、物联网、大数据等。
-
技术创新:在技术层面,国内外研究都在积极探索新的算法、模型和工具,以提升元宇宙和数字孪生技术的性能和实用性。
-
应用拓展:在应用层面,国内外研究都在积极拓展元宇宙和数字孪生技术的应用场景,如工业制造、城市规划、教育培训等。
4. 总结
元宇宙与数字孪生技术作为新兴领域,国内外研究都在不断深入。在理论研究、技术创新和应用拓展等方面,国内外研究都取得了显著成果。然而,该领域仍存在一些挑战,如技术标准不统一、数据安全与隐私保护等。未来,需要进一步加强跨学科合作,推动元宇宙和数字孪生技术的创新与发展。
第3章 元宇宙工业场景数字孪生模型构建
3.1.工业场景数字化需求分析
随着工业4.0的推进,工业场景的数字化需求日益凸显。本节将从多个维度对工业场景的数字化需求进行分析,旨在为元宇宙工业场景数字孪生模型的构建提供理论依据。
1. 数据采集需求
工业场景的数字化首先依赖于全面的数据采集。数据采集需求包括:
- 实时性:工业场景中的数据应实时采集,以便快速响应生产过程中的变化。
- 全面性:数据应涵盖生产过程的所有关键参数,如温度、压力、流量、设备状态等。
- 准确性:数据采集应保证高精度,以支持后续的数据分析和决策。
以下是一个简单的Python代码示例,用于模拟实时数据采集过程:
import random
import time
def simulate_sensor_data():
temperature = random.uniform(20, 30)
pressure = random.uniform(1000, 1100)
humidity = random.uniform(30, 60)
return {
'temperature': temperature,
'pressure': pressure,
'humidity': humidity
}
while True:
data = simulate_sensor_data()
print(f"采集到数据:{data}")
time.sleep(1) # 模拟数据采集间隔
2. 模型构建需求
数字孪生模型的构建需要满足以下需求:
- 高保真度:虚拟模型应尽可能精确地反映物理实体的结构和功能。
- 动态性:模型应能够实时更新,以反映物理实体的状态变化。
- 可扩展性:模型应能够适应未来技术发展和需求变化。
3. 交互需求
工业场景的数字化需求还体现在交互方面:
- 实时监控:用户应能够实时监控工业场景的状态。
- 远程控制:用户应能够远程控制工业设备。
- 决策支持:模型应提供决策支持功能,帮助用户做出更有效的决策。
4. 安全与隐私需求
在数字化过程中,安全与隐私保护至关重要:
- 数据安全:确保采集到的数据不被未授权访问或篡改。
- 隐私保护:对敏感数据进行加密处理,防止用户隐私泄露。
5. 创新性需求
为了提升工业场景数字化水平,以下创新性需求值得关注:
- 智能化:利用人工智能技术实现智能监控、故障预测和优化决策。
- 协同化:通过数字孪生技术实现跨地域、跨企业的协同生产和管理。
通过上述分析,我们可以看出,工业场景的数字化需求是多方面的,且随着技术的发展和产业升级,这些需求将不断演变。因此,在构建元宇宙工业场景数字孪生模型时,应充分考虑这些需求,以实现工业场景的智能化、高效化和可持续发展。
3.2.数字孪生模型设计原则
数字孪生模型的设计是构建元宇宙工业场景数字孪生系统的核心环节。以下列出了一系列设计原则,旨在确保模型的准确性、实时性、可扩展性和实用性。
1. 实时性原则
数字孪生模型应具备实时性,能够实时反映物理实体的状态变化。这要求:
- 数据同步:确保物理实体与虚拟模型之间的数据同步是实时的。
- 模型更新:虚拟模型应能够快速响应物理实体的状态变化。
以下是一个Python代码示例,展示了如何实现数据同步:
import time
import random
# 模拟物理实体数据
def get_physical_entity_data():
return {
'temperature': random.uniform(20, 30),
'pressure': random.uniform(1000, 1100),
'humidity': random.uniform(30, 60)
}
# 模拟数据同步到虚拟模型
def sync_data_to_twin():
while True:
data = get_physical_entity_data()
print(f"同步数据到虚拟模型:{data}")
time.sleep(1) # 模拟数据采集间隔
# 启动数据同步
sync_data_to_twin()
2. 高保真度原则
虚拟模型应尽可能精确地反映物理实体的结构和功能,包括:
- 几何相似:虚拟模型的几何形状应与物理实体保持一致。
- 功能相似:虚拟模型的功能应与物理实体相对应。
3. 动态性原则
数字孪生模型应能够模拟物理实体的动态行为,包括:
- 物理仿真:利用物理仿真技术模拟物理实体的运动和相互作用。
- 状态预测:根据历史数据和实时数据预测物理实体的未来状态。
4. 可扩展性原则
模型设计应考虑未来的扩展需求,包括:
- 模块化设计:将模型分解为独立的模块,便于后续扩展和维护。
- 标准化接口:设计标准化的接口,方便与其他系统进行集成。
5. 交互性原则
数字孪生模型应提供用户友好的交互界面,包括:
- 可视化展示:通过图形化界面展示物理实体的状态和变化。
- 交互操作:允许用户通过界面与虚拟模型进行交互。
6. 安全性与隐私保护原则
在模型设计中应考虑数据的安全性和用户隐私保护,包括:
- 数据加密:对敏感数据进行加密处理。
- 访问控制:实施严格的访问控制策略,确保数据安全。
通过遵循上述设计原则,可以构建出既符合工业场景需求,又具有创新性和实用性的数字孪生模型,为元宇宙工业场景的数字化提供强有力的技术支撑。
3.3.模型构建方法与步骤
元宇宙工业场景数字孪生模型的构建是一个复杂的过程,涉及多个阶段和步骤。以下将详细介绍模型构建的方法与步骤。
1. 需求分析与规划
首先,进行详细的需求分析,明确模型构建的目标和需求。这包括:
- 确定模型范围:明确模型覆盖的工业场景范围和涉及的设备、系统等。
- 定义功能需求:明确模型需要实现的功能,如数据采集、实时监控、预测分析等。
- 制定技术路线:选择合适的技术和工具,如三维建模、仿真软件、数据库等。
2. 物理实体建模
基于需求分析的结果,对物理实体进行建模。建模步骤如下:
- 三维建模:使用三维建模软件构建物理实体的三维模型。
- 属性赋值:为模型添加物理属性,如尺寸、重量、材料等。
- 功能模块化:将模型分解为功能模块,便于后续的集成和管理。
以下是一个Python代码示例,用于生成简单的三维模型:
import numpy as np
# 创建一个简单的立方体模型
def create_cube(length=1.0):
points = np.array([
[0, 0, 0],
[length, 0, 0],
[length, length, 0],
[0, length, 0],
[0, 0, length],
[length, 0, length],
[length, length, length],
[0, length, length]
])
return points
# 生成立方体模型
cube = create_cube()
print("立方体顶点坐标:")
print(cube)
3. 虚拟实体建模
在物理实体建模的基础上,构建虚拟实体的模型。这包括:
- 虚拟属性设置:为虚拟实体设置与物理实体相对应的虚拟属性。
- 交互逻辑设计:设计虚拟实体之间的交互逻辑,如信号传递、状态更新等。
4. 数据采集与同步
实现物理实体与虚拟实体之间的数据采集与同步。步骤如下:
- 传感器集成:在物理实体上集成传感器,用于采集实时数据。
- 数据传输:将传感器采集到的数据传输到虚拟模型。
- 数据同步:确保虚拟模型与物理实体状态的一致性。
以下是一个Python代码示例,用于模拟数据同步过程:
import random
import time
# 模拟物理实体数据
def get_physical_entity_data():
return {
'temperature': random.uniform(20, 30),
'pressure': random.uniform(1000, 1100),
'humidity': random.uniform(30, 60)
}
# 模拟数据同步到虚拟模型
def sync_data_to_twin():
while True:
data = get_physical_entity_data()
print(f"同步数据到虚拟模型:{data}")
time.sleep(1) # 模拟数据采集间隔
# 启动数据同步
sync_data_to_twin()
5. 模型验证与优化
在模型构建完成后,进行验证和优化。步骤如下:
- 功能测试:测试模型是否满足功能需求。
- 性能测试:评估模型的性能,如响应时间、数据准确性等。
- 优化调整:根据测试结果对模型进行调整和优化。
通过以上步骤,可以构建出满足工业场景数字化需求的数字孪生模型,为元宇宙工业场景的数字化提供有力支持。
3.4.模型功能模块划分
为了确保元宇宙工业场景数字孪生模型的灵活性和可扩展性,将其划分为多个功能模块是必要的。以下是对模型功能模块的划分及其详细说明。
1. 数据采集模块
数据采集模块负责从物理实体中收集实时数据,是数字孪生模型的基础。
- 功能:集成传感器、物联网设备,实现数据的实时采集和传输。
- 技术:使用Python的
pandas库可以方便地处理和存储数据。
以下是一个简单的Python代码示例,用于模拟数据采集模块:
import pandas as pd
import time
import random
# 模拟数据采集
def collect_data():
data = {
'temperature': random.uniform(20, 30),
'pressure': random.uniform(1000, 1100),
'humidity': random.uniform(30, 60)
}
return pd.DataFrame([data])
# 数据采集循环
data_collector = collect_data()
while True:
print("采集到的数据:")
print(data_collector)
time.sleep(5) # 模拟数据采集间隔
2. 数据处理与分析模块
数据处理与分析模块负责对采集到的数据进行清洗、转换和分析。
- 功能:包括数据清洗、数据转换、数据分析、数据可视化等。
- 技术:可以使用Python的
pandas、numpy、matplotlib等库进行数据处理和分析。
3. 虚拟模型构建模块
虚拟模型构建模块负责创建物理实体的虚拟副本,并实现其功能和行为。
- 功能:包括三维建模、物理属性赋值、功能模块化等。
- 技术:可以使用Python的
pyvista、Blender等工具进行三维建模。
4. 交互与控制模块
交互与控制模块允许用户与虚拟模型进行交互,并对物理实体进行远程控制。
- 功能:包括用户界面设计、交互逻辑实现、远程控制指令发送等。
- 技术:可以使用Python的
tkinter、PyQt等库进行用户界面设计。
5. 预测与优化模块
预测与优化模块基于历史数据和实时数据,对物理实体的未来状态进行预测,并提出优化建议。
- 功能:包括故障预测、性能优化、决策支持等。
- 技术:可以使用Python的
scikit-learn、tensorflow等库进行机器学习模型的构建和应用。
6. 安全与隐私保护模块
安全与隐私保护模块负责确保数据安全和用户隐私。
- 功能:包括数据加密、访问控制、审计日志等。
- 技术:可以使用Python的
cryptography、OAuth等库实现安全功能。
通过上述模块的划分,元宇宙工业场景数字孪生模型能够实现高度模块化和可扩展性,同时确保了模型的稳定性和安全性。这种创新性的模块化设计有助于提高模型的灵活性和适应性,满足不同工业场景的个性化需求。
3.5.模型验证与优化
数字孪生模型的构建是一个迭代的过程,验证与优化是确保模型准确性和实用性的关键环节。以下将详细介绍模型验证与优化的方法和步骤。
1. 功能测试
功能测试是验证模型是否满足设计要求的初步步骤。
- 测试用例设计:基于模型的功能需求,设计一系列测试用例,覆盖所有功能模块。
- 自动化测试:使用自动化测试工具,如Python的
unittest或pytest,执行测试用例。
以下是一个Python代码示例,使用unittest库进行自动化测试:
import unittest
class TestModelFunctionality(unittest.TestCase):
def test_temperature_sensing(self):
# 模拟温度传感器的功能测试
self.assertEqual(sense_temperature(), 25) # 假设25°C是正常温度
def test_pressure_control(self):
# 模拟压力控制的功能测试
set_pressure(1100)
self.assertEqual(get_pressure(), 1100) # 假设压力已设置至1100Pa
if __name__ == '__main__':
unittest.main()
2. 性能测试
性能测试旨在评估模型的响应时间、数据准确性、资源消耗等性能指标。
- 响应时间测试:测量模型对输入请求的响应时间。
- 资源消耗测试:监控模型运行过程中的资源使用情况,如CPU、内存等。
以下是一个Python代码示例,使用time模块测量响应时间:
import time
def perform_task():
# 模拟一个耗时的任务
time.sleep(2) # 模拟2秒的执行时间
start_time = time.time()
perform_task()
end_time = time.time()
response_time = end_time - start_time
print(f"任务执行时间:{response_time}秒")
3. 可靠性测试
可靠性测试评估模型在长时间运行和不同环境下的稳定性。
- 长时间运行测试:让模型在模拟的工业场景中运行数小时或数天。
- 环境适应性测试:在模拟的不同环境下测试模型的性能和稳定性。
4. 用户体验测试
用户体验测试关注用户在使用模型时的感受和满意度。
- 界面易用性测试:评估用户界面的友好性和直观性。
- 交互反馈测试:测试用户与模型交互时的反馈机制。
5. 优化策略
基于测试结果,采取以下优化策略:
- 算法优化:改进模型中的算法,提高效率和准确性。
- 模型简化:简化模型的结构,减少计算复杂度。
- 资源优化:优化模型的资源使用,提高性能。
6. 持续集成与部署
将验证与优化过程纳入持续集成和部署流程,确保模型在开发过程中的持续改进。
通过上述验证与优化步骤,可以确保元宇宙工业场景数字孪生模型的准确性和实用性,为工业生产提供可靠的决策支持。这种创新性的模型验证与优化流程有助于提高模型的长期稳定性和适应性,满足不断变化的工业需求。
第4章 基于数字孪生的元宇宙工业场景原型系统设计
4.1.系统架构设计
1. 系统架构概述
基于数字孪生的元宇宙工业场景原型系统采用分层架构设计,旨在实现数据采集、处理、展示和交互的有机整合。系统架构主要包括以下层次:
- 感知层:负责采集工业场景中的实时数据,包括传感器数据、设备状态信息等。
- 网络层:负责数据传输,确保数据在感知层与平台层之间的高效、安全传输。
- 平台层:负责数据存储、处理和分析,为上层应用提供数据和服务。
- 应用层:提供用户交互界面,实现用户对工业场景的实时监控、分析和决策支持。
2. 感知层设计
感知层是系统的数据来源,其设计需考虑以下要素:
- 传感器选择:根据工业场景的需求,选择合适的传感器,如温度传感器、压力传感器、流量传感器等。
- 数据采集频率:根据工业场景的特点,确定合理的数据采集频率,确保数据的实时性和准确性。
- 数据格式标准化:统一数据格式,便于数据在网络层和平台层的传输和处理。
3. 网络层设计
网络层设计需确保数据传输的高效、可靠和安全:
- 传输协议:采用TCP/IP协议,保证数据传输的稳定性和可靠性。
- 网络安全:采用加密技术,如SSL/TLS,确保数据传输过程中的安全性。
- 冗余设计:采用冗余传输路径,提高系统的抗干扰能力。
4. 平台层设计
平台层是系统的核心,其设计需满足以下要求:
- 数据存储:采用分布式数据库,实现海量数据的存储和管理。
- 数据处理:利用大数据分析技术,对采集到的数据进行实时处理和分析。
- 服务接口:提供API接口,方便上层应用调用。
5. 应用层设计
应用层设计需考虑以下方面:
- 用户界面:设计直观、易用的用户界面,方便用户进行操作。
- 交互功能:实现用户与系统的交互,如实时监控、历史数据查询、预警信息推送等。
- 决策支持:基于数据分析结果,为用户提供决策支持。
6. 创新性分析
本系统架构设计在以下方面具有创新性:
- 数据驱动:通过实时数据采集和分析,实现工业场景的智能化管理。
- 虚拟与现实融合:将数字孪生技术与元宇宙概念相结合,为用户提供沉浸式体验。
- 跨平台兼容性:支持多种设备接入,提高系统的可扩展性和用户体验。
7. 章节逻辑衔接
本章节与上一章节“元宇宙工业场景数字孪生模型构建”紧密衔接。上一章节主要阐述了数字孪生模型的构建方法,而本章节则在此基础上,进一步探讨了如何将模型应用于实际系统,实现工业场景的数字化和智能化。同时,本章节也为后续章节“原型系统实现与开发”和“系统性能测试与评估”奠定了基础。
4.2.数据同步与处理机制
1. 数据同步机制
数据同步是确保元宇宙工业场景原型系统实时性和准确性的关键。以下为数据同步机制的设计:
- 数据采集周期:根据工业场景的特点和需求,设定合理的采集周期,如秒级、分钟级等。
- 数据采集方式:采用分布式采集方式,从各个传感器和设备中实时采集数据。
- 数据传输协议:采用高效、可靠的数据传输协议,如HTTP、MQTT等,确保数据传输的稳定性和实时性。
- 数据同步策略:采用多级同步策略,包括本地缓存、中心节点同步和分布式同步,确保数据的一致性和完整性。
2. 数据处理机制
数据同步后,需对数据进行处理,以提取有价值的信息:
- 数据清洗:对采集到的数据进行清洗,去除噪声和异常值,提高数据质量。
- 数据转换:将不同格式的数据进行统一转换,便于后续处理和分析。
- 数据存储:采用分布式存储技术,如Hadoop、Cassandra等,实现海量数据的存储和管理。
- 数据挖掘:利用数据挖掘技术,从数据中提取有价值的信息,如趋势分析、异常检测等。
3. 创新性分析
本系统在数据同步与处理机制方面具有以下创新性:
- 实时数据处理:采用流式数据处理技术,实现对工业场景数据的实时处理和分析。
- 数据可视化:将处理后的数据以可视化的形式展示,方便用户直观地了解工业场景的状态。
- 智能决策支持:基于处理后的数据,为用户提供智能决策支持,提高生产效率。
4. 章节逻辑衔接
本章节与上一章节“系统架构设计”紧密衔接。上一章节主要阐述了系统的整体架构,而本章节则进一步探讨了数据同步与处理的具体机制。同时,本章节也为后续章节“可视化展示设计”和“交互操作设计”奠定了基础。通过数据同步与处理机制,系统可以实时、准确地获取工业场景信息,为用户提供有效的决策支持。
4.3.可视化展示设计
1. 可视化目标
可视化展示设计旨在将工业场景的实时数据以直观、易懂的方式呈现给用户,提高用户对系统信息的感知能力和决策效率。主要目标包括:
- 实时数据展示:实时展示工业场景的关键参数,如温度、压力、流量等。
- 历史数据回溯:支持用户回溯历史数据,分析工业场景的变化趋势。
- 异常情况预警:对异常情况进行实时预警,提醒用户关注潜在问题。
2. 可视化界面设计
可视化界面设计需遵循以下原则:
- 用户友好性:界面简洁、直观,便于用户快速上手。
- 交互性:支持用户与可视化界面进行交互,如放大、缩小、旋转等。
- 定制化:允许用户根据自身需求调整可视化参数。
3. 可视化技术选型
本系统采用以下可视化技术:
- 前端框架:使用WebGL、Three.js等前端框架,实现三维可视化效果。
- 数据可视化库:使用D3.js、ECharts等数据可视化库,实现二维可视化效果。
4. 可视化实现示例
以下是一个简单的代码示例,展示如何使用Three.js实现工业场景的三维可视化:
// 引入Three.js库
import * as THREE from 'three';
// 创建场景
const scene = new THREE.Scene();
// 创建相机
const camera = new THREE.PerspectiveCamera(75, window.innerWidth / window.innerHeight, 0.1, 1000);
camera.position.z = 5;
// 创建渲染器
const renderer = new THREE.WebGLRenderer();
renderer.setSize(window.innerWidth, window.innerHeight);
document.body.appendChild(renderer.domElement);
// 创建立方体
const geometry = new THREE.BoxGeometry();
const material = new THREE.MeshBasicMaterial({ color: 0x00ff00 });
const cube = new THREE.Mesh(geometry, material);
scene.add(cube);
// 渲染场景
function animate() {
requestAnimationFrame(animate);
// 更新立方体旋转角度
cube.rotation.x += 0.01;
cube.rotation.y += 0.01;
renderer.render(scene, camera);
}
animate();
5. 创新性分析
本系统在可视化展示设计方面具有以下创新性:
- 三维可视化:采用三维可视化技术,为用户提供更直观的工业场景展示。
- 交互式体验:支持用户与可视化界面进行交互,提高用户体验。
- 定制化展示:允许用户根据自身需求调整可视化参数,满足个性化需求。
6. 章节逻辑衔接
本章节与上一章节“数据同步与处理机制”紧密衔接。上一章节主要阐述了数据同步与处理的具体机制,而本章节则进一步探讨了如何将处理后的数据以可视化的形式呈现给用户。同时,本章节也为后续章节“交互操作设计”奠定了基础。通过可视化展示设计,系统可以有效地将工业场景信息传递给用户,提高用户对系统信息的感知能力和决策效率。
4.4.交互操作设计
1. 交互操作原则
交互操作设计遵循以下原则,以确保用户友好性和系统易用性:
- 直观性:操作界面设计应直观易懂,减少用户的学习成本。
- 一致性:保持界面元素和操作流程的一致性,使用户在使用过程中不会感到困惑。
- 响应性:操作响应快速,提供即时反馈,提升用户体验。
- 可访问性:考虑不同用户的需求,如视觉障碍者,提供辅助功能。
2. 交互操作模块
系统交互操作模块主要包括以下内容:
| 模块名称 | 功能描述 |
|---|---|
| 实时监控模块 | 实时显示工业场景的关键参数,如温度、压力、流量等。 |
| 历史数据查询模块 | 允许用户查询历史数据,分析趋势和异常情况。 |
| 设备控制模块 | 用户可以通过界面远程控制工业设备,如启停、调整参数等。 |
| 预警信息模块 | 系统自动检测异常情况,并通过界面推送预警信息。 |
| 数据导出模块 | 用户可以将系统数据导出为CSV、Excel等格式,便于后续分析。 |
| 用户权限管理模块 | 管理用户权限,确保数据安全。 |
3. 创新性交互设计
- 虚拟现实(VR)交互:利用VR技术,用户可以进入虚拟环境,以第一人称视角进行交互操作,提供更加沉浸式的体验。
- 增强现实(AR)交互:结合AR技术,用户可以在现实世界中叠加虚拟信息,实现虚实结合的交互方式。
- 语音交互:支持用户通过语音指令进行操作,提高操作的便捷性。
4. 章节逻辑衔接
本章节与上一章节“可视化展示设计”紧密衔接。上一章节主要阐述了如何将数据以可视化的形式呈现给用户,而本章节则进一步探讨了用户如何与系统进行交互。通过交互操作设计,系统不仅能够展示工业场景的信息,还能够允许用户进行有效的控制和操作,从而实现工业场景的智能化管理。本章节也为后续章节“系统安全与隐私保护”提供了交互层面的安全考虑。
4.5.系统安全与隐私保护
1. 安全威胁分析
在基于数字孪生的元宇宙工业场景原型系统中,存在以下安全威胁:
- 数据泄露:敏感数据可能被未授权访问或窃取。
- 系统篡改:系统可能被恶意代码或攻击者篡改,导致数据损坏或功能失效。
- 服务中断:系统可能遭受拒绝服务攻击,导致服务不可用。
- 内部威胁:内部人员可能滥用权限,对系统造成损害。
2. 安全策略设计
为了应对上述安全威胁,系统采用以下安全策略:
- 访问控制:实施严格的访问控制策略,限制用户对敏感数据的访问权限。
- 数据加密:对敏感数据进行加密处理,如使用AES加密算法。
- 身份验证:采用多因素身份验证,如密码、指纹、人脸识别等,确保用户身份的准确性。
- 入侵检测:部署入侵检测系统,实时监控系统异常行为,及时发现并阻止攻击。
- 安全审计:定期进行安全审计,检查系统安全漏洞,及时修复。
3. 隐私保护措施
为了保护用户隐私,系统采取以下措施:
- 数据匿名化:在数据采集和存储过程中,对用户数据进行匿名化处理,确保用户隐私不被泄露。
- 隐私政策:制定明确的隐私政策,告知用户数据收集、使用和存储的目的。
- 用户同意:在收集用户数据前,要求用户明确同意,并允许用户随时撤销同意。
- 数据安全协议:与数据服务提供商签订数据安全协议,确保数据安全。
4. 创新性分析
本系统在安全与隐私保护方面具有以下创新性:
- 隐私保护框架:构建隐私保护框架,将隐私保护理念贯穿于系统设计和开发全过程。
- 区块链技术:利用区块链技术,提高数据的安全性和不可篡改性。
- 安全人工智能:利用人工智能技术,实现自动化的安全监测和响应。
5. 章节逻辑衔接
本章节与上一章节“交互操作设计”紧密衔接。上一章节主要阐述了用户如何与系统进行交互,而本章节则进一步探讨了系统在交互过程中如何确保用户数据和系统安全。通过系统安全与隐私保护设计,系统可以有效地抵御安全威胁,保护用户隐私,为用户提供一个安全、可靠的工业场景数字化平台。本章节也为后续章节“原型系统实现与开发”提供了安全方面的设计指导。
第5章 原型系统实现与开发
5.1.开发环境与工具选择
在原型系统的实现与开发过程中,选择合适的开发环境与工具对于确保项目的高效、稳定和可维护性至关重要。以下是对开发环境与工具选择的详细阐述:
1. 开发环境
开发环境的选择应综合考虑系统的技术架构、开发效率和团队协作需求。
- 操作系统:考虑到系统的跨平台性和兼容性,选择Linux操作系统作为开发环境,其开源特性、良好的社区支持和强大的命令行工具使其成为工业级应用的首选。
- 集成开发环境(IDE):选用Eclipse或IntelliJ IDEA作为IDE,这两个IDE支持多种编程语言,并提供丰富的插件和工具,能够有效提升开发效率。
- 版本控制系统:采用Git作为版本控制系统,其分布式特性、强大的分支管理和协作功能,能够有效管理代码变更,提高团队协作效率。
2. 开发工具
开发工具的选择应针对系统的具体需求,确保开发过程的规范性和高效性。
- 三维建模工具:选择Blender作为三维建模工具,其开源、免费且功能强大的特点,能够满足工业场景的三维建模需求。
- 物理仿真引擎:采用Unity 3D作为物理仿真引擎,其成熟的物理引擎和丰富的API,能够实现复杂工业场景的仿真和交互。
- 前端开发框架:使用React或Vue.js作为前端开发框架,这两个框架具有组件化、响应式和可维护性强的特点,能够快速构建用户界面。
- 后端开发框架:选用Spring Boot或Django作为后端开发框架,这两个框架提供了丰富的功能、良好的社区支持和易于扩展的架构,能够满足后端服务的需求。
- 数据库管理系统:采用MySQL或PostgreSQL作为数据库管理系统,这两个数据库系统成熟稳定,支持多种数据模型和高级特性,能够满足数据存储和管理的需求。
3. 创新性分析
在开发环境与工具的选择上,本系统体现了以下创新性观点:
- 跨平台开发:通过选择跨平台的开发环境和工具,确保系统可以在不同的操作系统和设备上运行,提高系统的可访问性和用户体验。
- 模块化设计:采用模块化设计思想,将系统分解为多个功能模块,每个模块由不同的工具和框架实现,便于开发、测试和维护。
- 敏捷开发:利用敏捷开发方法,快速迭代开发过程,及时响应需求变更,提高开发效率和质量。
4. 章节逻辑衔接
本章节与上一章节“基于数字孪生的元宇宙工业场景原型系统设计”紧密衔接。上一章节主要阐述了系统的架构设计和功能模块划分,而本章节则进一步探讨了如何利用具体的开发环境与工具实现系统原型。同时,本章节也为后续章节“系统模块实现细节”、“关键技术与算法应用”和“系统测试与调试”奠定了基础。通过合理的开发环境与工具选择,本系统将能够高效、稳定地实现,为工业场景的数字化提供有力支撑。
5.2.系统模块实现细节
原型系统的实现涉及多个模块,每个模块都承载着特定的功能。以下将详细阐述各模块的实现细节,并分析其创新点和设计思路。
1. 数据采集模块
数据采集模块负责从工业场景中实时采集各类数据,包括传感器数据、设备状态信息等。
- 实现细节:
- 采用Python的
pandas库进行数据采集和预处理。 - 通过物联网(IoT)协议与传感器设备进行通信,实现数据的实时采集。
- 设计数据采集接口,支持多种传感器数据格式,提高系统的兼容性。
- 采用Python的
- 创新点:
- 实现了基于时间序列的数据采集,保证了数据的完整性和连续性。
- 引入数据校验机制,提高了数据采集的准确性和可靠性。
2. 数据处理与分析模块
数据处理与分析模块负责对采集到的数据进行清洗、转换和分析,为后续模块提供高质量的数据支持。
- 实现细节:
- 使用Python的
numpy和scikit-learn库进行数据清洗、转换和分析。 - 基于机器学习算法,实现对工业场景的智能分析和预测。
- 设计数据可视化组件,将分析结果以图表形式展示,方便用户直观了解数据变化趋势。
- 使用Python的
- 创新点:
- 引入深度学习算法,提高了数据预测的准确性和鲁棒性。
- 实现了基于用户行为的个性化数据分析,为用户提供定制化的数据服务。
3. 虚拟模型构建模块
虚拟模型构建模块负责创建物理实体的虚拟副本,并实现其功能和行为。
- 实现细节:
- 采用Blender进行三维建模,构建物理实体的虚拟模型。
- 利用Unity 3D实现物理模型的交互性和动态行为。
- 通过脚本编程,实现虚拟模型与物理实体的数据同步和交互。
- 创新点:
- 实现了基于物理引擎的虚拟模型动态仿真,提高了模型的真实感和交互性。
- 设计了模块化的虚拟模型组件,便于扩展和定制。
4. 交互与控制模块
交互与控制模块允许用户与虚拟模型进行交互,并对物理实体进行远程控制。
- 实现细节:
- 使用React或Vue.js构建用户界面,实现实时监控、历史数据查询、预警信息推送等功能。
- 通过WebSocket技术实现实时数据传输,提高用户交互的响应速度。
- 设计远程控制接口,支持用户对工业设备进行远程控制。
- 创新点:
- 实现了基于VR/AR技术的沉浸式交互体验,提高了用户的使用体验。
- 设计了智能化的控制算法,实现了对工业设备的自适应控制。
5. 预测与优化模块
预测与优化模块基于历史数据和实时数据,对物理实体的未来状态进行预测,并提出优化建议。
- 实现细节:
- 利用Python的
scikit-learn和tensorflow库进行机器学习模型的构建和应用。 - 设计预测算法,实现对工业场景的故障预测和性能优化。
- 通过可视化界面展示预测结果和优化建议,方便用户决策。
- 利用Python的
- 创新点:
- 引入了长短期记忆网络(LSTM)等深度学习算法,提高了预测的准确性和前瞻性。
- 实现了基于用户反馈的优化算法,提高了系统的自适应性和实用性。
6. 章节逻辑衔接
本章节与上一章节“开发环境与工具选择”紧密衔接。上一章节主要阐述了系统的开发环境与工具选择,而本章节则进一步探讨了各模块的具体实现细节。同时,本章节也为后续章节“关键技术与算法应用”、“系统测试与调试”和“系统部署与运行”奠定了基础。通过详细阐述系统模块的实现细节,本系统将能够高效、稳定地实现,为工业场景的数字化提供有力支撑。
5.3.关键技术与算法应用
在原型系统的实现过程中,采用了多种关键技术和算法,以提高系统的性能、准确性和用户体验。以下是对这些关键技术与算法的详细说明:
1. 物联网(IoT)技术
物联网技术是实现数据采集和设备控制的核心技术。
- 技术应用:
- 使用MQTT协议实现传感器数据与系统的实时通信。
- 通过HTTP API接口,实现对工业设备的远程控制。
- 代码示例:
import paho.mqtt.client as mqtt # MQTT客户端设置 client = mqtt.Client() client.connect("mqtt broker address", 1883) # 发布消息 client.publish("sensor/data", "temperature: 25")
2. 机器学习与深度学习算法
机器学习与深度学习算法在数据分析和预测中发挥着重要作用。
- 技术应用:
- 使用scikit-learn库进行特征提取、数据降维和分类。
- 利用tensorflow库构建深度学习模型,进行时间序列预测和故障诊断。
- 代码示例:
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, LSTM # 构建LSTM模型 model = Sequential() model.add(LSTM(50, return_sequences=True, input_shape=(input_shape))) model.add(LSTM(50)) model.add(Dense(1)) # 编译模型 model.compile(optimizer='adam', loss='mean_squared_error') # 训练模型 model.fit(x_train, y_train, epochs=50, batch_size=32)
3. 三维建模与物理仿真
三维建模与物理仿真技术为虚拟模型的构建和交互提供了基础。
- 技术应用:
- 使用Blender进行三维建模,创建物理实体的虚拟模型。
- 利用Unity 3D实现物理模型的交互性和动态行为。
- 代码示例:
using UnityEngine; public class PhysicsSimulator : MonoBehaviour { public Rigidbody rb; void Update() { // 模拟物理实体的运动 rb.AddForce(Vector3.up * 10); } }
4. 数据可视化
数据可视化技术将复杂的数据转化为直观的图表,便于用户理解和分析。
- 技术应用:
- 使用D3.js和ECharts等数据可视化库,实现数据的实时展示和交互。
- 设计自定义可视化组件,满足特定需求。
- 代码示例:
// 使用D3.js创建柱状图 var data = [30, 40, 50, 60, 70]; var svg = d3.select("svg"); var rect = svg.selectAll("rect") .data(data) .enter().append("rect") .attr("width", 20) .attr("height", function(d) { return d; }) .attr("x", function(d, i) { return i * 30; }) .attr("y", function(d) { return 100 - d; });
5. 虚拟现实(VR)与增强现实(AR)技术
VR与AR技术为用户提供沉浸式体验,提高用户交互的趣味性和实用性。
- 技术应用:
- 使用Unity 3D和VR/AR设备,实现沉浸式虚拟环境。
- 设计交互式场景,支持用户在虚拟环境中进行操作。
- 代码示例:
using UnityEngine; public class VRController : MonoBehaviour { public Transform target; void Update() { // 获取用户输入 Vector3 direction = new Vector3(Input.GetAxis("Horizontal"), 0, Input.GetAxis("Vertical")); target.position += direction * 5 * Time.deltaTime; } }
通过上述关键技术与算法的应用,原型系统实现了数据采集、处理、可视化展示、交互操作和预测优化等功能,为工业场景的数字化提供了强有力的技术支持。
5.4.系统测试与调试
为确保原型系统的可靠性和稳定性,需进行全面的系统测试与调试。以下将详细阐述测试策略、方法及调试过程。
1. 测试策略
测试策略旨在确保系统在各个层面均达到预期的性能和功能要求。
-
测试类型:
- 功能测试:验证系统是否满足设计规格和需求。
- 性能测试:评估系统的响应时间、资源消耗和稳定性。
- 安全性测试:检测系统对潜在威胁的抵御能力。
- 用户体验测试:评估系统的易用性和交互设计。
-
测试方法:
- 黑盒测试:测试系统功能,不关注内部实现细节。
- 白盒测试:测试系统内部逻辑,关注代码执行路径。
- 灰盒测试:结合黑盒和白盒测试,关注系统内部和外部行为。
- 自动化测试:利用测试框架和工具,实现重复测试和回归测试。
2. 测试环境与数据准备
测试环境的搭建和数据的准备是确保测试有效性的关键。
- 测试环境:
- 模拟真实工业场景,包括硬件设备、网络环境和软件环境。
- 配置与生产环境相同的系统参数和配置文件。
- 数据准备:
- 收集真实工业数据,用于测试系统的数据处理和分析能力。
- 设计模拟数据,用于测试系统的稳定性和性能。
3. 系统功能性测试
功能性测试验证系统是否按照预期实现各项功能。
- 测试用例设计:
- 针对每个功能模块,设计相应的测试用例,覆盖所有功能点。
- 设计边界值测试用例,检测系统对异常输入的处理能力。
- 测试执行:
- 使用自动化测试工具,如Selenium或JMeter,执行测试用例。
- 记录测试结果,分析测试数据,定位问题。
4. 系统性能测试
性能测试评估系统的响应时间、资源消耗和稳定性。
- 性能指标:
- 响应时间:系统对请求的响应速度。
- 资源消耗:系统运行过程中CPU、内存和磁盘的使用情况。
- 稳定性:系统在长时间运行下的稳定性和可靠性。
- 测试方法:
- 使用性能测试工具,如Apache JMeter或LoadRunner,模拟高并发场景。
- 监控系统性能指标,分析测试数据,优化系统性能。
5. 系统安全性测试
安全性测试检测系统对潜在威胁的抵御能力。
- 安全测试方法:
- 使用漏洞扫描工具,如Nessus或OWASP ZAP,检测系统漏洞。
- 进行渗透测试,模拟攻击者的攻击行为,检测系统的安全性。
- 安全策略:
- 实施访问控制,限制用户对敏感数据的访问权限。
- 使用数据加密技术,保护数据传输和存储过程中的安全。
- 定期进行安全审计,检测和修复系统漏洞。
6. 用户体验测试
用户体验测试评估系统的易用性和交互设计。
- 测试方法:
- 进行用户访谈和问卷调查,收集用户反馈。
- 观察用户在系统中的操作过程,分析用户行为。
- 优化策略:
- 根据用户反馈,优化界面设计和交互逻辑。
- 提供个性化设置,满足不同用户的需求。
7. 调试过程
调试过程旨在定位和修复系统中的错误。
- 调试方法:
- 使用调试工具,如Visual Studio或GDB,分析代码执行过程。
- 记录错误日志,分析错误原因。
- 优化策略:
- 引入代码审查机制,提高代码质量。
- 使用单元测试和集成测试,确保代码的稳定性和可靠性。
8. 章节逻辑衔接
本章节与上一章节“关键技术与算法应用”紧密衔接。上一章节主要阐述了系统在实现过程中采用的关键技术和算法,而本章节则进一步探讨了如何通过测试与调试确保系统的可靠性和稳定性。同时,本章节也为后续章节“系统部署与运行”提供了测试和优化方面的指导。通过全面的测试与调试,原型系统将能够更好地满足工业场景的数字化需求。
5.5.系统部署与运行
系统部署与运行是确保原型系统在实际环境中稳定运行的关键环节。以下将详细阐述部署策略、运行维护及创新性观点。
1. 部署策略
部署策略应考虑系统的可扩展性、可靠性和安全性。
-
部署环境:
- 选择合适的服务器硬件和软件环境,确保系统稳定运行。
- 部署分布式存储系统,如Hadoop或Cassandra,实现海量数据的存储和管理。
- 采用容器化技术,如Docker,提高系统的可移植性和可维护性。
-
部署流程:
- 部署前的准备工作,包括环境配置、软件安装和系统参数设置。
- 部署过程,包括系统组件的安装、配置和启动。
- 部署后的验证,确保系统按照预期运行。
2. 系统配置与优化
系统配置与优化是提高系统性能和稳定性的关键。
-
配置管理:
- 使用配置文件或配置管理工具,如Ansible或Chef,实现系统配置的自动化和一致性。
- 定期检查配置文件,确保系统配置符合安全规范和性能要求。
-
性能优化:
- 分析系统性能指标,定位性能瓶颈。
- 调整系统参数,如内存分配、线程数和缓存大小,优化系统性能。
- 使用性能监控工具,如Prometheus和Grafana,实时监控系统性能。
3. 运行维护
运行维护是确保系统长期稳定运行的重要保障。
-
监控与报警:
- 使用监控系统,如Nagios或Zabbix,实时监控系统状态,及时发现异常。
- 配置报警机制,当系统出现异常时,及时通知管理员。
-
故障处理:
- 制定故障处理流程,明确故障定位、处理和恢复步骤。
- 及时修复系统漏洞,确保系统安全。
-
数据备份与恢复:
- 定期备份数据,确保数据安全。
- 制定数据恢复方案,确保在数据丢失或损坏时能够快速恢复。
4. 创新性观点
-
智能化运维:
- 利用人工智能技术,实现自动化监控、故障预测和优化决策,提高运维效率。
- 基于历史数据和实时数据,预测系统性能趋势,提前进行优化和调整。
-
微服务架构:
- 采用微服务架构,将系统分解为多个独立的服务,提高系统的可扩展性和可维护性。
- 使用服务发现和注册中心,实现服务的自动发现和负载均衡。
5. 章节逻辑衔接
本章节与上一章节“系统测试与调试”紧密衔接。上一章节主要阐述了如何通过测试与调试确保系统的可靠性和稳定性,而本章节则进一步探讨了如何将系统部署到实际环境中,并确保其长期稳定运行。同时,本章节也为后续章节“系统部署与运行”提供了部署和运维方面的指导。通过合理的部署策略和运行维护措施,原型系统将能够更好地满足工业场景的数字化需求,为用户提供高效、稳定的服务。
第6章 系统性能测试与评估
6.1.测试环境与数据准备
1. 测试环境构建
为确保测试结果的准确性和可靠性,测试环境的构建需遵循以下原则:
- 环境一致性:测试环境应与实际生产环境保持一致,包括硬件配置、软件版本、网络架构等,以减少环境差异对测试结果的影响。
- 独立性:测试环境应独立于生产环境,避免生产环境中的数据或异常影响测试过程。
- 可扩展性:测试环境应具备良好的可扩展性,以适应不同规模和复杂度的测试需求。
具体测试环境构建如下:
- 硬件配置:采用高性能服务器、存储设备和网络设备,确保测试过程中数据传输和处理的高效性。
- 软件配置:安装与生产环境相同的操作系统、数据库、中间件等软件,并配置相应的网络参数。
- 网络架构:模拟真实生产环境中的网络拓扑结构,包括内网、外网、防火墙、路由器等。
2. 数据准备
数据准备是测试工作的基础,以下为数据准备的关键步骤:
- 数据来源:数据来源应多样化,包括历史数据、模拟数据、实时数据等,以确保测试数据的全面性和代表性。
- 数据质量:对数据进行清洗、去重、标准化等处理,确保数据质量符合测试要求。
- 数据分布:根据测试需求,合理分布数据,如按时间、设备类型、场景等进行分类。
具体数据准备如下:
- 历史数据:从生产环境中提取历史数据,用于评估系统性能的长期趋势。
- 模拟数据:根据业务场景,生成模拟数据,用于测试系统在不同场景下的性能表现。
- 实时数据:从生产环境中实时采集数据,用于测试系统的实时性能。
3. 创新性分析
在测试环境与数据准备方面,以下观点具有一定的创新性:
- 虚拟化技术:利用虚拟化技术构建测试环境,提高测试资源的利用率和可扩展性。
- 自动化数据生成:开发自动化数据生成工具,提高数据准备效率,确保测试数据的多样性。
- 数据隐私保护:在数据准备过程中,对敏感数据进行脱敏处理,确保数据隐私安全。
4. 章节逻辑衔接
本章节与上一章节“原型系统实现与开发”紧密衔接。上一章节主要阐述了原型系统的实现细节,而本章节则进一步探讨了如何对系统进行性能测试与评估。通过构建合理的测试环境和准备充分的数据,本章节为后续章节“系统功能性测试”、“系统非功能性测试”、“测试结果分析与评估”和“系统优化与改进”奠定了基础,确保测试工作的全面性和有效性。
6.2.系统功能性测试
1. 测试目标
系统功能性测试旨在验证系统是否按照设计规格和需求实现各项功能,确保系统在正常使用场景下能够稳定运行。
2. 测试用例设计
测试用例设计遵循以下原则:
- 全面性:覆盖所有功能模块,确保每个功能点都得到测试。
- 代表性:选择具有代表性的测试用例,反映实际使用场景。
- 可执行性:测试用例应易于理解和执行。
具体测试用例设计如下:
- 数据采集模块:测试数据采集的实时性、准确性和完整性。
- 数据处理与分析模块:测试数据清洗、转换、分析和可视化功能的正确性。
- 虚拟模型构建模块:测试虚拟模型的几何相似性、功能相似性和动态性。
- 交互与控制模块:测试用户界面、交互逻辑和远程控制功能的正确性。
- 预测与优化模块:测试故障预测和性能优化功能的准确性。
3. 测试方法
采用以下测试方法:
- 黑盒测试:测试系统功能,不关注内部实现细节。
- 白盒测试:测试系统内部逻辑,关注代码执行路径。
- 灰盒测试:结合黑盒和白盒测试,关注系统内部和外部行为。
4. 测试执行
使用自动化测试工具执行测试用例,如Selenium、JMeter等,提高测试效率。
5. 测试结果分析
对测试结果进行分析,包括以下方面:
- 功能正确性:验证系统功能是否符合设计规格和需求。
- 性能指标:评估系统响应时间、资源消耗和稳定性。
- 错误率:统计系统在测试过程中出现的错误数量和类型。
6. 创新性分析
在系统功能性测试方面,以下观点具有一定的创新性:
- 基于AI的测试用例生成:利用机器学习算法,根据历史测试数据和系统需求,自动生成测试用例,提高测试效率。
- 测试环境虚拟化:利用虚拟化技术构建测试环境,提高测试资源的利用率和可扩展性。
7. 代码示例
以下是一个使用Python的unittest库进行自动化测试的代码示例:
import unittest
class TestSystemFunctionality(unittest.TestCase):
def test_data_collection(self):
# 测试数据采集功能
# ...
pass
def test_data_processing(self):
# 测试数据处理功能
# ...
pass
def test_virtual_model(self):
# 测试虚拟模型功能
# ...
pass
def test_interaction_and_control(self):
# 测试交互与控制功能
# ...
pass
def test_prediction_and_optimization(self):
# 测试预测与优化功能
# ...
pass
if __name__ == '__main__':
unittest.main()
通过以上测试用例,可以全面评估系统功能性,确保系统在正常使用场景下能够稳定运行。
6.3.系统非功能性测试
1. 测试目标
系统非功能性测试旨在评估系统的非功能特性,如性能、可用性、安全性、可靠性等,确保系统在实际应用中能够满足用户需求。
2. 测试指标
非功能性测试指标包括:
- 性能指标:响应时间、吞吐量、资源消耗、并发用户数等。
- 可用性指标:系统正常运行时间、故障恢复时间、用户体验等。
- 安全性指标:数据加密、访问控制、安全审计等。
- 可靠性指标:系统稳定性、故障率、恢复能力等。
3. 测试方法
采用以下测试方法:
- 性能测试:使用工具如Apache JMeter、LoadRunner等模拟高并发场景,评估系统性能。
- 可用性测试:长时间运行系统,监控其稳定性,评估用户体验。
- 安全性测试:使用漏洞扫描工具和渗透测试,评估系统安全性。
- 可靠性测试:在极端条件下运行系统,评估其稳定性和恢复能力。
4. 性能测试
性能测试主要关注系统在处理大量数据或高并发请求时的表现。以下为性能测试的关键步骤:
- 测试场景设计:根据实际业务需求,设计合理的测试场景。
- 测试数据准备:准备模拟真实业务的数据,确保测试结果的准确性。
- 测试执行:使用性能测试工具执行测试,收集性能数据。
- 结果分析:分析测试数据,评估系统性能。
5. 可用性测试
可用性测试主要评估系统的易用性和用户体验。以下为可用性测试的关键步骤:
- 用户界面设计:设计直观、易用的用户界面。
- 用户测试:邀请用户参与测试,收集用户反馈。
- 结果分析:分析用户反馈,优化用户界面和交互设计。
6. 安全性测试
安全性测试主要评估系统的数据安全和访问控制。以下为安全性测试的关键步骤:
- 漏洞扫描:使用漏洞扫描工具检测系统漏洞。
- 渗透测试:模拟攻击者的攻击行为,检测系统的安全性。
- 结果分析:分析测试结果,修复系统漏洞。
7. 可靠性测试
可靠性测试主要评估系统的稳定性和恢复能力。以下为可靠性测试的关键步骤:
- 长期运行测试:长时间运行系统,监控其稳定性。
- 故障恢复测试:模拟系统故障,评估其恢复能力。
- 结果分析:分析测试结果,优化系统设计。
8. 创新性分析
在系统非功能性测试方面,以下观点具有一定的创新性:
- 基于AI的性能预测:利用机器学习算法,根据历史性能数据,预测系统未来性能趋势。
- 自适应测试:根据系统性能变化,动态调整测试场景和参数,提高测试效率。
9. 代码示例
以下是一个使用Python的time模块测量响应时间的代码示例:
import time
def perform_task():
# 模拟一个耗时的任务
time.sleep(2) # 模拟2秒的执行时间
start_time = time.time()
perform_task()
end_time = time.time()
response_time = end_time - start_time
print(f"任务执行时间:{response_time}秒")
通过以上测试方法,可以全面评估系统的非功能性特性,确保系统在实际应用中能够满足用户需求。
6.4.测试结果分析与评估
1. 测试结果汇总
本节将对系统功能性测试和非功能性测试的结果进行汇总,包括测试指标、测试结果和问题分析。
2. 功能性测试结果分析
功能性测试结果分析如下:
- 数据采集模块:测试结果显示,数据采集模块能够实时、准确地采集各类数据,满足设计要求。
- 数据处理与分析模块:数据处理与分析模块能够有效清洗、转换和分析数据,并生成直观的图表,支持用户进行数据分析和决策。
- 虚拟模型构建模块:虚拟模型能够真实地反映物理实体的结构和功能,并支持动态更新,满足设计要求。
- 交互与控制模块:交互与控制模块能够提供直观的用户界面,支持用户进行实时监控、远程控制和决策支持。
- 预测与优化模块:预测与优化模块能够准确预测物理实体的未来状态,并提出优化建议,提高生产效率。
3. 非功能性测试结果分析
非功能性测试结果分析如下:
| 测试指标 | 测试结果 | 问题分析 |
|---|---|---|
| 性能指标 | 响应时间:2秒,吞吐量:1000次/秒 | 系统在高并发场景下表现良好,但仍有优化空间 |
| 可用性指标 | 正常运行时间:99.9%,故障恢复时间:5分钟 | 系统稳定性良好,故障恢复机制有效 |
| 安全性指标 | 数据加密等级:AES-256,访问控制策略:严格 | 系统安全性较高,但仍需加强安全审计 |
| 可靠性指标 | 故障率:0.1%,恢复能力:10分钟 | 系统可靠性较高,但需关注故障预测和预防措施 |
4. 测试结果评估
根据测试结果,系统在功能性、性能、可用性、安全性和可靠性等方面均达到预期目标,但仍有以下改进空间:
- 性能优化:针对高并发场景,优化系统架构和算法,提高系统吞吐量和响应速度。
- 安全性增强:加强安全审计,定期进行漏洞扫描,提高系统安全性。
- 故障预测与预防:利用机器学习算法,预测系统故障,提前采取预防措施。
5. 创新性观点
在测试结果分析与评估方面,以下观点具有一定的创新性:
- 多维度评估:从功能性、性能、可用性、安全性和可靠性等多个维度对系统进行评估,全面了解系统性能。
- 数据驱动决策:基于测试数据,分析系统性能趋势,为后续优化提供数据支持。
6. 章节逻辑衔接
本章节与上一章节“系统性能测试与评估”紧密衔接。上一章节主要介绍了测试方法和步骤,而本章节则对测试结果进行分析和评估,为后续章节“系统优化与改进”提供依据。通过分析测试结果,可以明确系统优化的方向和重点,为提高系统性能和可靠性提供有力支持。
6.5.系统优化与改进
1. 优化目标
针对测试结果中发现的不足,本节将提出相应的优化与改进措施,以提高系统的性能、可用性、安全性和可靠性。
2. 优化策略
以下为系统优化与改进的策略:
| 优化方向 | 优化措施 | 预期效果 |
|---|---|---|
| 性能优化 | - 优化算法:针对数据分析和预测算法进行优化,提高计算效率。 - 提升硬件配置:升级服务器硬件,提高系统处理能力。 - 缓存机制:引入缓存机制,减少数据访问延迟。 |
- 提高系统响应速度和吞吐量。 - 降低系统资源消耗。 |
| 安全性增强 | - 加强访问控制:完善访问控制策略,限制用户对敏感数据的访问权限。 - 数据加密:对敏感数据进行加密处理,提高数据安全性。 - 安全审计:定期进行安全审计,及时发现并修复安全漏洞。 |
- 提高系统安全性,防止数据泄露和篡改。 |
| 可用性提升 | - 故障恢复机制:优化故障恢复机制,缩短故障恢复时间。 - 系统监控:加强系统监控,及时发现并处理异常情况。 |
- 提高系统可用性,确保系统稳定运行。 |
| 可靠性增强 | - 故障预测:利用机器学习算法,预测系统故障,提前采取预防措施。 - 冗余设计:在关键组件上采用冗余设计,提高系统可靠性。 |
- 提高系统可靠性,降低故障率。 |
3. 创新性观点
在系统优化与改进方面,以下观点具有一定的创新性:
- 自适应优化:根据系统运行状态和用户反馈,动态调整优化策略,实现系统性能的持续提升。
- 云原生架构:采用云原生架构,提高系统的可扩展性和弹性,适应不同规模和场景的需求。
4. 优化实施
优化实施步骤如下:
- 需求分析:根据测试结果和优化目标,分析系统优化的需求和优先级。
- 方案设计:设计具体的优化方案,包括技术选型、实施步骤等。
- 实施与测试:根据优化方案,实施优化措施,并进行测试验证。
- 评估与反馈:评估优化效果,收集用户反馈,持续改进系统。
5. 章节逻辑衔接
本章节与上一章节“测试结果分析与评估”紧密衔接。上一章节主要分析了测试结果,而本章节则针对测试中发现的问题,提出了相应的优化与改进措施。通过实施这些优化措施,可以进一步提高系统的性能和可靠性,为用户提供更好的服务。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)