Claude Opus 4.6 正式发布-百万级上下文、自适应推理、顶级编码能力
2026年2月5日,Anthropic 正式发布了其最新旗舰大语言模型 Claude Opus 4.6。这是 Claude 4.5 模型家族的最新成员,也是目前 Anthropic 最先进、最智能的模型。Opus 4.6 在编码能力、长上下文理解、智能体协作、领域专业知识等多个维度实现了显著提升,同时定价与前代 Opus 4.5 保持一致。
百万级上下文窗口:长文本理解的质变
Opus 4.6 是 Opus 系列中首个支持 100 万 token 上下文窗口的模型(目前为 beta 阶段)。这意味着它可以一次性处理相当于数本书的内容量,而不会出现性能崩溃。
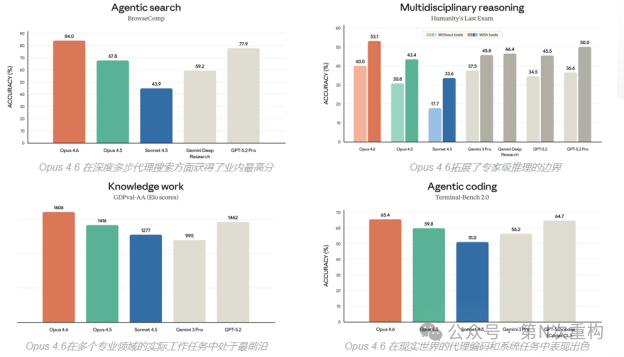
在 MRCR v2 基准测试(8-needle, 1M context)中,Opus 4.6 得分高达 76%,而此前 Sonnet 4.5 仅为 18.5%。这不是简单的量变,而是长上下文模型能力的质变。长期困扰业界的"上下文腐蚀"问题——即长对话导致模型表现下降——在 Opus 4.6 中得到了有效解决。
此外,最大输出 token 数从前代的 64K 翻倍至 128K,使模型能够完成更大规模的输出任务,无需拆分为多次请求。自适应思维:更聪明的推理方式
Opus 4.6 引入了全新的自适应思维(Adaptive Thinking)机制,取代了此前简单的"开/关"式扩展思考模式。新机制提供四个努力等级:

这种分级机制让开发者能够在推理质量、推理速度和成本之间灵活权衡,根据不同场景选择最合适的策略。
编码与智能体能力:全面领先
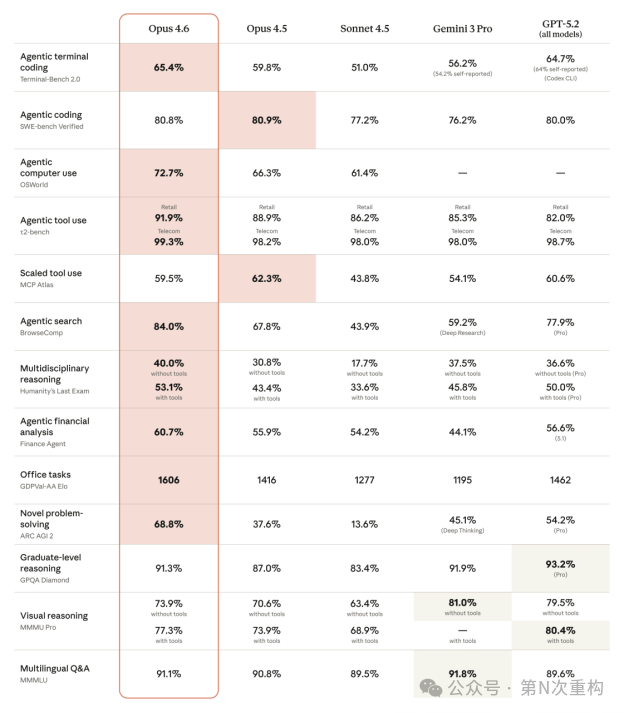
编码能力一直是 Claude 模型的核心竞争力,Opus 4.6 在这一方向上继续拉开差距。模型在任务规划上更加审慎,能在大型代码库中更可靠地工作,代码审查和自我纠错能力也显著增强。
核心基准对比:

Cursor 联合创始人 Michael Truell 评价道,Opus 4.6 在处理最难问题上表现尤为突出。在实际测试中,该模型曾一次性完整生成了一个功能完备的物理引擎,展现出处理大规模、多层次任务的能力。
Agent Teams:多智能体协作时代
伴随 Opus 4.6 的发布,Claude Code 引入了 Agent Teams 功能。开发者现在可以启动多个独立的 Claude 智能体实例,让它们并行工作、自主协调。一个"领导"智能体负责整体协调,多个"成员"智能体各自执行具体任务,每个成员拥有自己独立的上下文窗口。
这一功能尤其适合代码审查等读密集型工作——不同智能体可以同时分析代码库的不同部分,大幅提升效率。Notion AI 负责人 Sarah Sachs 表示,Opus 4.6 不再像一个工具,而是一个真正有能力的协作者。
领域能力跃升:生命科学与金融
Opus 4.6 在多个专业领域展现出令人瞩目的进步。在生命科学方面,模型在计算生物学、结构生物学、有机化学和系统发育学测试上的表现接近 Opus 4.5 的两倍。在金融领域,Real-World Finance 评估得分较 Sonnet 4.5 提升超过 23 个百分点,Finance Agent 达到 60.7%,TaxEval 达到 76.0%。在法律领域,BigLaw Bench 得分高达 90.2%。
在综合推理能力测试 Humanity's Last Exam 中,Opus 4.6 在所有前沿模型中得分最高;在 GDPval-AA 实际工作任务评估中,以 1606 Elo 领先 GPT-5.2 达 144 分。
新 API 特性与开发者体验
Opus 4.6 在 API 层面带来了多项重要更新。对话压缩(Compaction)功能可以在上下文接近窗口上限时自动摘要早期对话内容,从而支持近乎无限长的对话交互。Fast Mode 可将 Opus 模型的输出速度提升最高 2.5 倍(以 $30/$150 每百万 token 的高级价格提供)。美国本土推理(US-only Inference)选项确保所有计算在美国境内完成,加价 10%。
值得注意的是,Opus 4.6 也带来了一些破坏性变更:助手消息预填(prefill)功能已不再支持;output_format 参数已迁移至 output_config.format;此前的 budget_tokens 扩展思考方式已废弃,需迁移至自适应思维模式。
安全性:能力提升,过度拒绝降低
在安全性方面,Opus 4.6 的整体不对齐行为评分约 1.8/10,是 Anthropic 所有已测试 Claude 模型中最低的(Opus 4.5 约 1.9,Haiku 4.5 约 2.2,Sonnet 4.5 约 2.7)。同时,它的过度拒绝率也是近期 Claude 模型中最低的——在保持必要安全边界的同时,更少拒绝合理的用户请求。
Anthropic 表示,此次发布进行了公司历史上最全面的安全评估,包括用户福祉评估、更复杂的危险请求拒绝测试,以及来自可解释性研究的新方法。
定价与可用性
尽管能力大幅提升,Opus 4.6 的 API 定价维持不变:输入 $5 / 百万 token,输出 $25 / 百万 token。模型已通过 claude.ai、Claude API、Amazon Bedrock 及 Google Cloud 等平台全面上线。在 claude.ai 上,Pro($20/月)、Team 及 Enterprise 用户均可使用。
模型 API 标识为 claude-opus-4-6,采用了不带日期后缀的简化命名方式。
写在最后
Claude Opus 4.6 不是一次简单的迭代升级。百万级上下文窗口、自适应推理架构、多智能体协作,以及生命科学和金融等垂直领域的大幅进步,共同构成了一次全方位的能力跃迁。在当前 GPT-5.2、Gemini 3 Pro 等竞品激烈角逐的前沿模型市场中,Opus 4.6 以不变的价格交出了一份极具竞争力的答卷。
对于开发者和企业用户而言,Opus 4.6 意味着更长的上下文、更强的推理、更高效的协作,以及更低的过度拒绝率。正如 Anthropic 所言,这个模型"在第一次尝试中就能更接近生产级质量"——而这或许正是 AI 工具从辅助角色走向核心生产力的关键一步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)