【AI大模型】从单步到多步RAG:提升大模型复杂任务处理能力的完整指南
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选很简单,这些岗位缺人且高薪智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。AI产业的快速扩张,也让人才供需矛盾愈发突出。
多步检索增强生成(RAG)已成为增强大型语言模型(LLMs)在需要全局理解和深入推理任务中的广泛策略。 许多RAG系统集成了工作内存模块以整合检索到的信息。
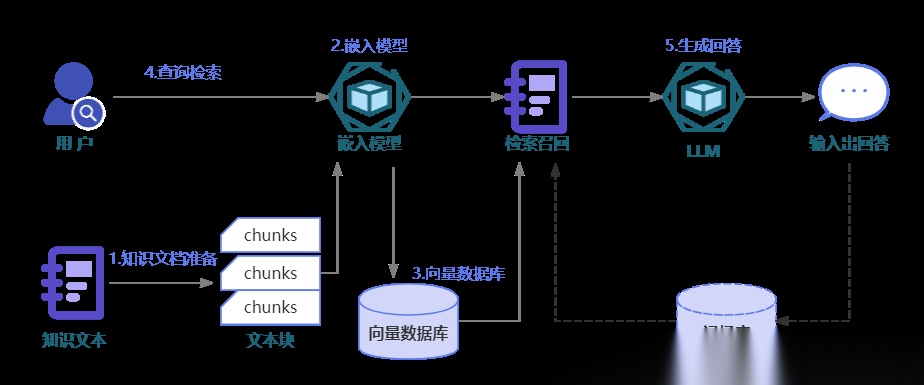
当大语言模型(LLM)面对 “分析某公司近 3 年营收波动的多维度原因”“拆解长论文中多个实验的关联逻辑” 这类复杂任务时,仅靠 “一次检索信息 + 一次生成回答” 的单步 RAG(检索增强生成),往往会因信息覆盖不足、推理深度不够而 “力不从心”。
于是,多步 RAG作为进阶方案应运而生 —— 它让 LLM 通过 “多轮检索补信息、多轮推理理逻辑” 的循环,逐步攻克复杂任务,但这一方案也暗藏新的痛点,而一篇最新论文提出的 “超图记忆机制”,正为其提供了优化思路。
从单步到多步:RAG 的能力升级
要理解多步 RAG 的价值,首先需要明确它与单步 RAG 的核心差异:
单步 RAG
是 “1 次检索 + 1 次生成” 的简单闭环,适合 “某产品上市时间” 这类单一信息查询任务,优势是流程快、成本低,但短板也很明显 —— 无法覆盖复杂任务的多维度信息,回答易片面。
多步 RAG
则是 “多轮检索 + 多轮推理” 的动态循环:LLM 会先拆解复杂任务为子问题,第一次检索某部分信息后,基于推理发现信息缺口,再针对性进行下一次检索,直到补全所有必要信息后,整合生成最终回答。比如分析公司营收波动时,它会先检索 “近 3 年营收数据”,发现缺 “波动原因” 后,再检索 “对应年份的行业政策、公司动作”,最后补全 “竞品动态”,最终形成完整分析。
这种升级让多步 RAG 能胜任长文档分析、多关系问答、跨领域信息整合等复杂任务,但它也有自己的 “软肋”。
单步 RAG vs 多步 RAG 核心对比清单
| 对比维度 | 单步 RAG | 多步 RAG |
|---|---|---|
| 核心定位 | 基础版 RAG,“1 次检索 + 1 次生成” 的单次闭环 | 进阶版 RAG,“多轮检索 + 多轮推理” 的循环闭环 |
| 适用场景 | 简单任务:1. 单一信息查询(如 “某产品上市时间”)2. 短文本的直接问答 | 复杂任务:1. 长文档 / 多文档综合分析(如 “拆解论文的 3 个实验结论”)2. 多关系 / 多维度问答(如 “某事件的时间线 + 参与者 + 影响”)3. 跨领域信息整合(如 “结合政策 + 数据分析行业趋势”) |
| 典型工作流程 | 1. 接收用户查询2. 1 次检索相关信息3. 直接生成回答 | 1. 接收用户查询→拆解为子任务2. 多轮 “检索子任务信息→推理补全缺口”3. 整合所有信息后生成回答 |
| 核心优势 | 1. 流程简单,响应速度快2. 检索 / 推理成本低 | 1. 能覆盖复杂任务的多维度信息2. 推理更深入、回答更全面 |
| 主要痛点 | 1. 无法处理需要多信息的复杂任务2. 信息覆盖不足,回答易片面 | 1. 多轮检索 / 推理效率低、成本高2. 易出现 “事实碎片化”(忽略信息间关联) |
| 典型实现工具 / 方案 | LangChain 基础 RAG 流程、Weaviate 单轮检索 | LangGraph 多智能体 RAG、HGMem 超图记忆 |
多步 RAG 的痛点:被忽略的 “事实高阶关联”
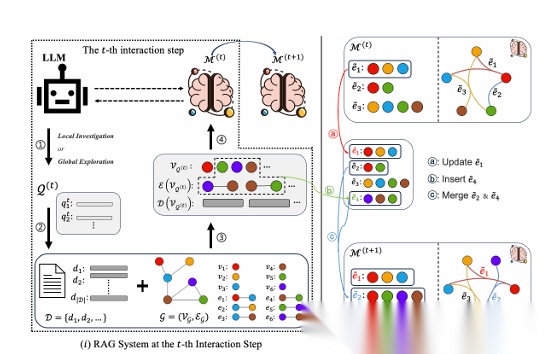
现有多步 RAG 的核心缺陷,在于它的 “工作记忆” 是被动的 “孤立事实仓库”—— 每次检索到的信息,只是被简单堆存在记忆里,而非主动关联。
比如分析营收波动时,“2023 年行业监管收紧”“2024 年公司推出新品” 这两个事实,在传统多步 RAG 的记忆中是孤立的,LLM 无法自动捕捉 “监管收紧倒逼公司调整产品策略” 的高阶关联。这种 “静态存储” 会导致推理碎片化:LLM 只能零散调用单个事实,却无法整合多事实的联动关系,最终在长上下文任务中 “理不清全局逻辑”。
论文方案:用 “超图记忆” 织起事实的关联网
针对这一痛点,《IMPROVING MULTI-STEP RAG WITH HYPERGRAPH-BASED MEMORY…》一文提出了HGMem(基于超图的记忆机制),将多步 RAG 的 “被动存储记忆” 升级为 “主动关联的超图结构”:
超图的 “节点” 对应每次检索到的事实(比如 “2023 年监管收紧”“2024 年新品上市”);
超图的 “超边” 则用来连接多个节点(普通图只能连接 2 个节点,超图可连接多个),专门捕捉事实间的高阶关联(比如 “监管收紧→公司调整策略→推出新品” 的链条)。
简单来说,HGMem 不是 “堆事实”,而是把孤立的信息织成一张 “关联网”—— 它会主动识别事实间的复杂关系,将零散信息整合为有结构的知识,让 LLM 在后续推理中能调用 “关联后的全局信息”,而非孤立事实。

效果:让多步 RAG 的推理更连贯、更全局
论文在聊天任务、长文档处理等复杂场景中测试了 HGMem,结果显示:这一方案能持续提升多步 RAG 的性能,在不同任务中均优于传统多步 RAG 基线系统 —— 它让 LLM 不再 “碎片化推理”,而是能基于事实间的高阶关联,完成更深入的全局逻辑分析。
从单步 RAG 到多步 RAG,是 LLM 处理复杂任务的能力跃迁;而 HGMem 的出现,则补上了多步 RAG 的 “关联短板”。这一探索也意味着:未来的 RAG 优化,将更聚焦 “如何让记忆从‘存储’转向‘理解’”,让 LLM 在长上下文、复杂关系任务中,真正实现 “连贯、全局的推理”。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
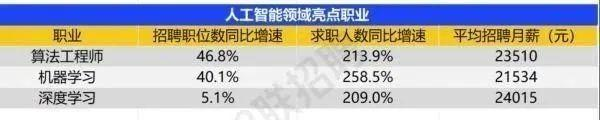
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献513条内容
已为社区贡献513条内容

所有评论(0)