RAG详解
摘要:本文介绍了检索增强生成(RAG)技术的基本原理,重点讲解了文档处理流程(加载、切片、向量化、存储)。详细展示了多种文档加载方法,包括PDF、网页、CSV、Excel等格式的处理,并提供了代码示例。文章还涉及多模态处理(图片解析)、网页特定内容抓取、文档标识等高级技巧,最后演示了如何自定义文档加载器。RAG通过将用户问题向量化后匹配数据库信息,补充大模型的垂直领域知识。
什么是检索增强生成RAG: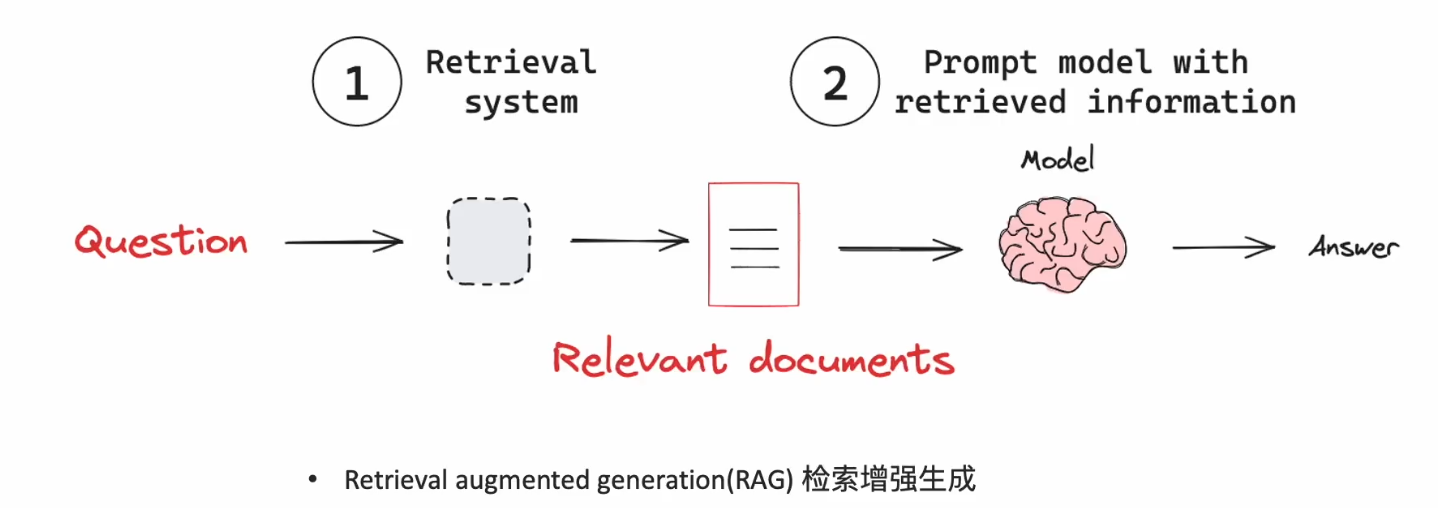
当用户问一个问题,把这个问题进行向量化,然后去RAG的向量数据库中匹配,把找到的信息和问题,组成提示词一起交给大模型,这样大模型就补充了它没有的垂直领域的知识。
对于文档的处理流程:
LOAD -》 SPLIT -》 EMBED -》 STORE
把文档进行切片,然后进行EMBED向量化处理,再把向量数据放入向量数据库。EMBED叫嵌入模型。用户问的问题也是通过它进行向量化的。市场上有很多嵌入模型,LangChain提供了标准接口。向量数据库也提供了很多查找算法,比如:
余弦相似度,欧几里德距离,点积。
为什么要对文档splits切片呢,一是上下文端口有限制,二是小文档可以增强检索匹配能力。
一、加载文档
如何加载PDF
pip install pypdf
file_path=‘deepseek.pdf’
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(file_path) #绑定资源创建文件
pages = []
async for page in loader.alazy_load():
pages.append(page) #每读完一页PDF就返回 page是Document类对象
print(f"{pages[0].metadata}\n") #第一页的附加信息
print(pages[0].page_content) #第一页的内容
对于包含图片的pdf
file_path=‘z2021.pdf’
pip install -qU PyMuPDF pillow langchain-openai IPython
import base64
import io
import fitz
from PIL import Image
def pdf_page_to_base64(pdf_path: str, page_number: int):
pdf_document = fitz.open(pdf_path)
page = pdf_document.load_page(page_number - 1) # input is one-indexed
pix = page.get_pixmap()
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
buffer = io.BytesIO()
img.save(buffer, format="PNG")
return base64.b64encode(buffer.getvalue()).decode("utf-8")
from IPython.display import Image as IPImage
from IPython.display import display
base64_image = pdf_page_to_base64(file_path, 11)
display(IPImage(data=base64.b64decode(base64_image)))

然后使用多模态处理图片内容:
from langchain_openai import ChatOpenAI
import os
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
api_key=os.environ.get("OPENAI_API_KEY"),
base_url=os.environ.get("OPENAI_API_BASE"),
)
from langchain_core.messages import HumanMessage
query = "一线城市消费者占比有多少?"
#其中content的类型Union[str, List[Dict]],str只是在对话时使用HumanMessage(content="你叫什么名字呢?")
#多模态时用如下方法。其实str最终也会被补全如下格式
message = HumanMessage(
content=[
{"type": "text", "text": query},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
},
],
)
response = llm.invoke([message])
print(response.content)
输出:
根据图表,一线城市消费者占比为46.4%
解析网页,这里介绍网页,cvs等,还有更多比如B站,youtube等。
! pip install -qU langchain-community beautifulsoup4 unstructured
! pip install -qU langchain-unstructured
import bs4
from langchain_community.document_loaders import WebBaseLoader
page_url = "https://python.langchain.com/docs/how_to/chatbots_memory/"
loader = WebBaseLoader(web_paths=[page_url])
docs = []
async for doc in loader.alazy_load():
docs.append(doc)
assert len(docs) == 1
doc = docs[0]
print(f"{doc.metadata}\n")
print(doc.page_content[:500].strip())
加载网页的某一部分
loader = WebBaseLoader(
web_paths=[page_url],
bs_kwargs={
"parse_only": bs4.SoupStrainer(class_="theme-doc-markdown markdown"), #只抓取theme-doc-markdown markdown这部分,它是HTML
},
bs_get_text_kwargs={"separator": " | ", "strip": True},
)
docs = []
async for doc in loader.alazy_load():
docs.append(doc)
assert len(docs) == 1
doc = docs[0]
print(f"{doc.metadata}\n")
print(doc.page_content[:500])
高级:不熟悉网页结构的情况下解析网页
from langchain_unstructured import UnstructuredLoader
page_url = "https://python.langchain.com/docs/how_to/chatbots_memory/"
loader = UnstructuredLoader(web_url=page_url)
docs = []
async for doc in loader.alazy_load():
docs.append(doc)
for doc in docs[:5]:
print(doc.page_content)
加载CVS
from langchain_community.document_loaders.csv_loader import CSVLoader
file_path = "PMBOK6.csv"
loader = CSVLoader(file_path=file_path)
data = loader.load()
for record in data[:2]:
print(record)
标识文档
loader = CSVLoader(file_path=file_path, source_column="名称")
data = loader.load()
for record in data[:2]:
print(record)
解析excel
这里使用微软云的Document intelligence服务来解析,需要申请KEY,其实也可以有本地部署的解决方案
! pip install --upgrade --quiet langchain langchain-community azure-ai-documentintelligence
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
file_path = "PMBOK62.xlsx"
endpoint ="https://jiaoxue.cognitiveservices.azure.com/"
key = "FdsAwGHwsQhEKkEYUN1OaBvR4a5f8GXJqPMPMYTAM70lABs1QgSHJQQJ99BCAC8vTInXJ3w3AAALACOGTQvM"
loader = AzureAIDocumentIntelligenceLoader(
api_endpoint=endpoint, api_key=key, file_path=file_path, api_model="prebuilt-layout"
)
documents = loader.load()
自定义文档加载器

! pip install aiofiles
from typing import AsyncIterator, Iterator
from langchain_core.document_loaders import BaseLoader
from langchain_core.documents import Document
class CustomDocumentLoader(BaseLoader):
"""逐行读取文件的文档加载器示例"""
def __init__(self, file_path: str) -> None:
"""使用文件路径初始化加载器
参数:
file_path: 要加载的文件路径
"""
self.file_path = file_path
def lazy_load(self) -> Iterator[Document]: # <-- 不接受任何参数
"""逐行读取文件的惰性加载器
当实现惰性加载方法时,你应该使用生成器
一次生成一个文档
"""
with open(self.file_path, encoding="utf-8") as f:
line_number = 0
for line in f:
yield Document(
page_content=line,
metadata={"line_number": line_number, "source": self.file_path},
)
line_number += 1
# alazy_load 是可选的
# 如果不实现它,将使用一个默认实现,该实现会委托给 lazy_load!
async def alazy_load(
self,
) -> AsyncIterator[Document]: # <-- 不接受任何参数
"""逐行读取文件的异步惰性加载器"""
# 需要 aiofiles (通过 pip 安装)
# https://github.com/Tinche/aiofiles
import aiofiles
async with aiofiles.open(self.file_path, encoding="utf-8") as f:
line_number = 0
async for line in f:
yield Document(
page_content=line,
metadata={"line_number": line_number, "source": self.file_path},
)
line_number += 1
测试
with open("meow.txt", "w", encoding="utf-8") as f:
quality_content = "meow meow🐱 \n meow meow🐱 \n meow😻😻"
f.write(quality_content)
loader = CustomDocumentLoader("meow.txt")
测试懒加载
## 测试懒加载
for doc in loader.lazy_load():
print()
print(type(doc))
print(doc)
二、切片文档
为什么要对文档splits切片呢,一是上下文端口有限制,二是小文档可以增强检索匹配能力,有以下切分策略:
- 按照长度切分
- 按照文本架构进行切分(句子、段落)
- 按照文档格式切分
- 基于语义进行切分
基于长度是简单暴力的,但可能破坏语义,因此可以基于架构,也就是段落和句子进行切分。根据文档,就是根据文档格式,比如pdf,csv等。智能的切分最大程度的保留语义,这也是终极目标。
pip install langchain-text-splitters
file_path=‘deepseek.pdf’
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(file_path)
pages = []
async for page in loader.alazy_load():
pages.append(page)
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=50, chunk_overlap=10
) #其中cl100k_base为分词器,chunk_size为每个切片的token大小,chunk_overlap为两个切片之间交际的部分的token数
texts = text_splitter.split_text(pages[1].page_content)
print(texts) #从0开始的,这其实是第一个切片的值
docs = text_splitter.create_documents([pages[2].page_content,pages[3].page_content])
print(docs)
输出:
['2. 算⼒需求分析\n模型 参数规\n模\n计算精\n度\n最低显存需\n求 最低算⼒需求\nDeepSeek-R1 (671B)671B FP8 ≥890GB 2*XE9680(16*H20\nGPU)\nDeepSeek-R1-Distill-\n70B 70B BF16 ≥180GB 4*L20 或 2*H20 GPU\n三、国产芯⽚与硬件适配⽅案\n1. 国内⽣态合作伙伴动态\n企业 适配内容 性能对标(vs\nNVIDIA)\n华为昇\n腾\n昇腾910B原⽣⽀持R1全系列,提供端到端推理优化\n⽅案 等效A100(FP16)\n沐曦\nGPU\nMXN系列⽀持70B模型BF16推理,显存利⽤率提升\n30% 等效RTX 3090\n海光\nDCU 适配V3/R1模型,性能对标NVIDIA A100 等效A100(BF16)\n2. 国产硬件推荐配置\n模型参数 推荐⽅案 适⽤场景\n1.5B 太初T100加速卡 个⼈开发者原型验证\n14B 昆仑芯K200集群 企业级复杂任务推理\n32B 壁彻算⼒平台+昇腾910B集群 科研计算与多模态处理\n四、云端部署替代⽅案\n1. 国内云服务商推荐\n平台 核⼼优势 适⽤场景']
[Document(metadata={}, page_content='硅基流动 官⽅推荐API,低延迟,⽀持多模态模型 企业级⾼并发推理\n腾讯云 ⼀键部署+限时免费体验,⽀持VPC私有化 中⼩规模模型快速上线\nPPIO派欧云 价格仅为OpenAI 1/20,注册赠5000万tokens 低成本尝鲜与测试\n2. 国际接⼊渠道(需魔法或外企上⽹环境\n!\n)\n英伟达NIM:企业级GPU集群部署(链接)\nGroq:超低延迟推理(链接)\n五、完整671B MoE模型部署(Ollama+Unsloth)\n1. 量化⽅案与模型选择\n量化版本 ⽂件体\n积\n最低内存+显存需\n求 适⽤场景\nDeepSeek-R1-UD-\nIQ1_M 158 GB ≥200 GB 消费级硬件(如Mac\nStudio)\nDeepSeek-R1-Q4_K_M 404 GB ≥500 GB ⾼性能服务器/云GPU\n下载地址:\nHuggingFace模型库\nUnsloth AI官⽅说明\n2. 硬件配置建议\n硬件类型 推荐配置 性能表现(短⽂本⽣成)\n消费级设备 Mac Studio(192GB统⼀内存) 10+ token/秒\n⾼性能服务器4×RTX 4090(96GB显存+384GB内存) 7-8 token/秒(混合推理)\n3. 部署步骤(Linux示例)\n1. 安装依赖⼯具:\n# 安装llama.cpp(⽤于合并分⽚⽂件)\n/bin/bash -c "$(curl -fsSL \nhttps://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"\nbrew install llama.cpp'), Document(metadata={}, page_content='2. 下载并合并模型分⽚:\n3. 安装Ollama:\n4. 创建Modelfile:\n5. 运⾏模型:\n4. 性能调优与测试\nGPU利⽤率低:升级⾼带宽内存(如DDR5 5600+)。\n扩展交换空间:\n六、注意事项与⻛险提示\n1. 成本警示:\n70B模型:需3张以上80G显存显卡(如RTX A6000),单卡⽤户不可⾏。\n671B模型:需8xH100集群,仅限超算中⼼部署。\n2. 替代⽅案:\n个⼈⽤户推荐使⽤云端API(如硅基流动),免运维且合规。\n3. 国产硬件兼容性:需使⽤定制版框架(如昇腾CANN、沐曦MXMLLM)。\nllama-gguf-split --merge DeepSeek-R1-UD-IQ1_M-00001-of-00004.gguf \nDeepSeek-R1-UD-IQ1_S.gguf\ncurl -fsSL https://ollama.com/install.sh | sh\nFROM /path/to/DeepSeek-R1-UD-IQ1_M.gguf \nPARAMETER num_gpu 28 # 每块RTX 4090加载7层(共4卡) \nPARAMETER num_ctx 2048 \nPARAMETER temperature 0.6 \nTEMPLATE "<|end▁of▁thinking|>{{ .Prompt }}<|end▁of▁thinking|>"\nollama create DeepSeek-R1-UD-IQ1_M -f DeepSeekQ1_Modelfile\nollama run DeepSeek-R1-UD-IQ1_M --verbose\nsudo fallocate -l 100G /swapfile\nsudo chmod 600 /swapfile\nsudo mkswap /swapfile\nsudo swapon /swapfile')]
基于文本架构
比如这个文档有三个段落,那么就会被切分成三个切片。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=50, chunk_overlap=0)
texts = text_splitter.split_text(pages[1].page_content)
print(texts)
输出
['2. 算⼒需求分析\n模型 参数规\n模\n计算精\n度\n最低显存需\n求 最低算⼒需求', 'DeepSeek-R1 (671B)671B FP8 ≥890GB 2*XE9680(16*H20', 'GPU)\nDeepSeek-R1-Distill-', '70B 70B BF16 ≥180GB 4*L20 或 2*H20 GPU', '三、国产芯⽚与硬件适配⽅案\n1. 国内⽣态合作伙伴动态\n企业 适配内容 性能对标(vs', 'NVIDIA)\n华为昇\n腾\n昇腾910B原⽣⽀持R1全系列,提供端到端推理优化', '⽅案 等效A100(FP16)\n沐曦\nGPU\nMXN系列⽀持70B模型BF16推理,显存利⽤率提升', '30% 等效RTX 3090\n海光', 'DCU 适配V3/R1模型,性能对标NVIDIA A100 等效A100(BF16)', '2. 国产硬件推荐配置\n模型参数 推荐⽅案 适⽤场景', '1.5B 太初T100加速卡 个⼈开发者原型验证\n14B 昆仑芯K200集群 企业级复杂任务推理', '32B 壁彻算⼒平台+昇腾910B集群 科研计算与多模态处理\n四、云端部署替代⽅案', '1. 国内云服务商推荐\n平台 核⼼优势 适⽤场景']
基于文档架构
- markdown 根据标题拆分(例如,#、##、###)
! pip install -qU langchain-text-splitters
基于markdown格式进行切分
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n ### Boo \n\n Hi this is Lance \n\n ## Baz\n\n Hi this is Molly"
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
] #定义规则:一个#号是一级标题,二个就是二级标题,按照这样的格式进行切分
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits
输出
[Document(metadata={'Header 1': 'Foo', 'Header 2': 'Bar'}, page_content='Hi this is Jim \nHi this is Joe'),
Document(metadata={'Header 1': 'Foo', 'Header 2': 'Bar', 'Header 3': 'Boo'}, page_content='Hi this is Lance'),
Document(metadata={'Header 1': 'Foo', 'Header 2': 'Baz'}, page_content='Hi this is Molly')]
基于JSON格式进行切分,它是根据json字段来分片的
import json
import requests
json_data = requests.get("https://api.smith.langchain.com/openapi.json").json()
from langchain_text_splitters import RecursiveJsonSplitter
splitter = RecursiveJsonSplitter(max_chunk_size=300)
json_chunks = splitter.split_json(json_data=json_data)
for chunk in json_chunks[:3]:
print(chunk)
输出
{'openapi': '3.1.0', 'info': {'title': 'LangSmith', 'version': '0.1.0'}, 'paths': {'/api/v1/sessions/{session_id}': {'get': {'tags': ['tracer-sessions'], 'summary': 'Read Tracer Session', 'description': 'Get a specific session.'}}}}
{'paths': {'/api/v1/sessions/{session_id}': {'get': {'operationId': 'read_tracer_session_api_v1_sessions__session_id__get', 'security': [{'API Key': []}, {'Tenant ID': []}, {'Bearer Auth': []}]}}}}
{'paths': {'/api/v1/sessions/{session_id}': {'get': {'parameters': [{'name': 'session_id', 'in': 'path', 'required': True, 'schema': {'type': 'string', 'format': 'uuid', 'title': 'Session Id'}}, {'name': 'include_stats', 'in': 'query', 'required': False, 'schema': {'type': 'boolean', 'default': False, 'title': 'Include Stats'}}, {'name': 'accept', 'in': 'header', 'required': False, 'schema': {'anyOf': [{'type': 'string'}, {'type': 'null'}], 'title': 'Accept'}}]}}}}
# 生成langchain Document
docs = splitter.create_documents(texts=[json_data])
for doc in docs[:3]:
print(doc)
输出
page_content='{"openapi": "3.1.0", "info": {"title": "LangSmith", "version": "0.1.0"}, "paths": {"/api/v1/sessions/{session_id}": {"get": {"tags": ["tracer-sessions"], "summary": "Read Tracer Session", "description": "Get a specific session."}}}}'
page_content='{"paths": {"/api/v1/sessions/{session_id}": {"get": {"operationId": "read_tracer_session_api_v1_sessions__session_id__get", "security": [{"API Key": []}, {"Tenant ID": []}, {"Bearer Auth": []}]}}}}'
page_content='{"paths": {"/api/v1/sessions/{session_id}": {"get": {"parameters": [{"name": "session_id", "in": "path", "required": true, "schema": {"type": "string", "format": "uuid", "title": "Session Id"}}, {"name": "include_stats", "in": "query", "required": false, "schema": {"type": "boolean", "default": false, "title": "Include Stats"}}, {"name": "accept", "in": "header", "required": false, "schema": {"anyOf": [{"type": "string"}, {"type": "null"}], "title": "Accept"}}]}}}}'
基于语义切片
先把把文本转化为向量数据,然后判断语句之间的联系,根据联系在对原来的文本进行切分,如下流程:
! pip install --quiet langchain_experimental langchain_openai
with open("meow.txt") as f:
meow = f.read()
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
# 使用OpenAIEmbeddings进行向量化
text_splitter = SemanticChunker(OpenAIEmbeddings())
docs = text_splitter.create_documents([meow])
print(docs[0].page_content)
三、LangChain的嵌入式模型
嵌入适配器和嵌入适配器模型
嵌入适配器:是langchain封装的遵循一套跟嵌入适配器模型交互API规则的类,嵌入模型则是具体执行嵌入过程把文本/图片转换为向量的,可以本地部署,也可以按token花钱使用云端服务。
嵌入模型:有很多比如硅基流动平台可以搜到很多模型:
https://cloud.siliconflow.cn/me/models?types=embedding
嵌入适配器类的通用接口如下:
- embed_documents 用于嵌入多个文本(文档)
- embed_query 用于嵌入单个文本(查询)
langchain封装了多种嵌入适配器类,如下: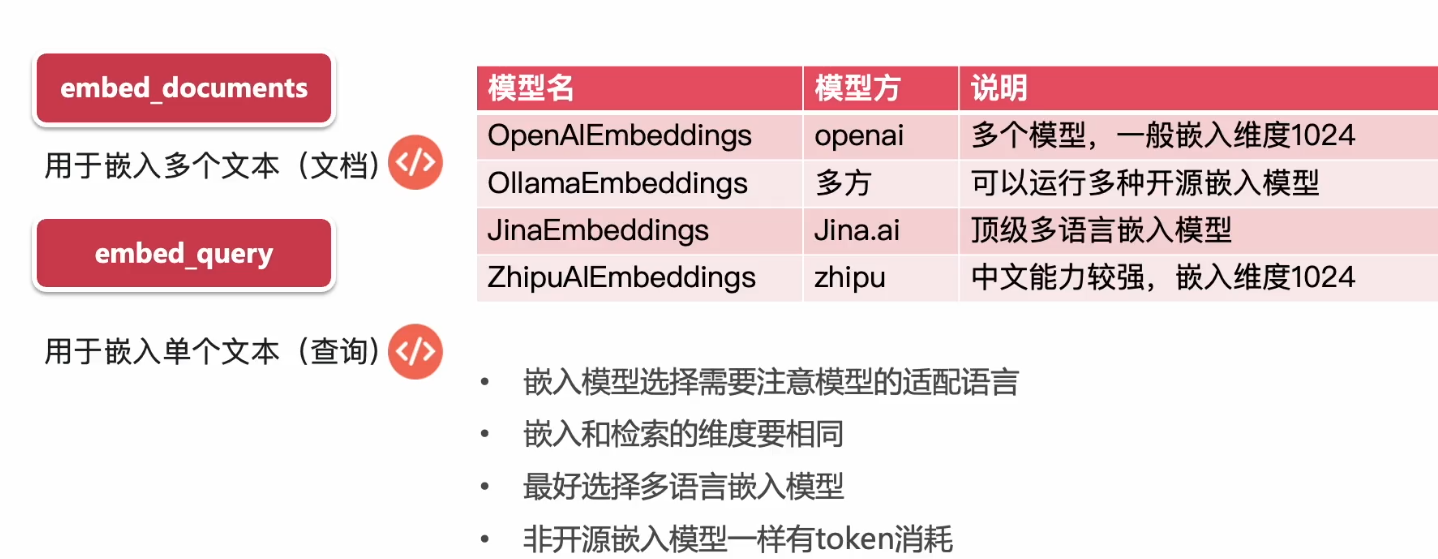
其中多语言是指支持多国语言,适配器的唯独要与向量数据库维度相同。
embed_documents使用:
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings() #如果未填入参数,默认使用model = "text-embedding-3-small" 这个是openai云端的嵌入模型,要设置API Key ,如果没有设置会去找这个变量export OPENAI_API_KEY="sk-xxxx"
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
) #会
print(len(embeddings))
print(len(embeddings[0]))
输出如下,说明embed_documents的默认维度是1536
5, 1536
embed_query使用
query_embedding = embeddings_model.embed_query("What is the meaning of life?")
print(query_embedding)
输出如下,它被转换为了高纬度向量的一组坐标,如果使用同一个嵌入式模型,只要文本不变,它转换的向量坐标是不变的。
[0.004411248955875635, -0.0296554546803236, -0.00819849781692028, -0.003228119807317853,
省略。。。
一个demo
因为调用嵌入模型也需要消耗token,因此对于同一个问题,没必要调用两遍,可以把第一遍的结果存储起来。
! pip install --upgrade --quiet langchain-openai faiss-cpu
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import LocalFileStore
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
underlying_embeddings = OpenAIEmbeddings()
#存储路径
store = LocalFileStore("/tmp/langchain_cache")
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings, store, namespace=underlying_embeddings.model
)
list(store.yield_keys())
加载并切分文档
raw_documents = TextLoader("meow.txt").load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
创建向量存储
%%time
db = FAISS.from_documents(documents, cached_embedder)
输出
CPU times: user 21.3 ms, sys: 11.5 ms, total: 32.8 ms
Wall time: 2.58 s
再次创建读取缓存,从而加快速度降低成本
%%time
db2 = FAISS.from_documents(documents, cached_embedder)
输出
CPU times: user 1.75 ms, sys: 1.28 ms, total: 3.03 ms
Wall time: 2.49 ms
可以看到明显变快
list(store.yield_keys())[:5]
输出
[‘text-embedding-ada-00263c0fca5-f3da-5691-8a86-2beceea627f5’]
使用国产嵌入模型,更改嵌入适配器中的嵌入模型
再https://cloud.siliconflow.cn/me/models?types=embedding上找到BAAI/bge-m3模型,使用如下:
from langchain_openai import OpenAIEmbeddings
import os
#一个LangChain封装类,它会按照 OpenAI Embedding API 协议跟Embedding模型交互,这只是个适配器,用它是通行的做法
embeddings_model = OpenAIEmbeddings(
model="BAAI/bge-m3", #北京智源研究院(BAAI) / DeepSeek / SiliconFlow / Moonshot / Together / 阿里百炼 / 火山 都提供了 OpenAI Embedding API
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url=os.environ.get("DEEPSEEK_API_BASE")+"/v1",
)#这里key和url换成服务器的,/v1是因为遵循openai格式,必加。
四、向量数据库
这些都是langchain支持的向量数据库,langchain支持很多接口,但不是所有的向量数据库都支持这些接口,对和差就是这些数据库对接口的支持情况
其中常用的几个如下,最常用的是Faiss和Chroma这两个: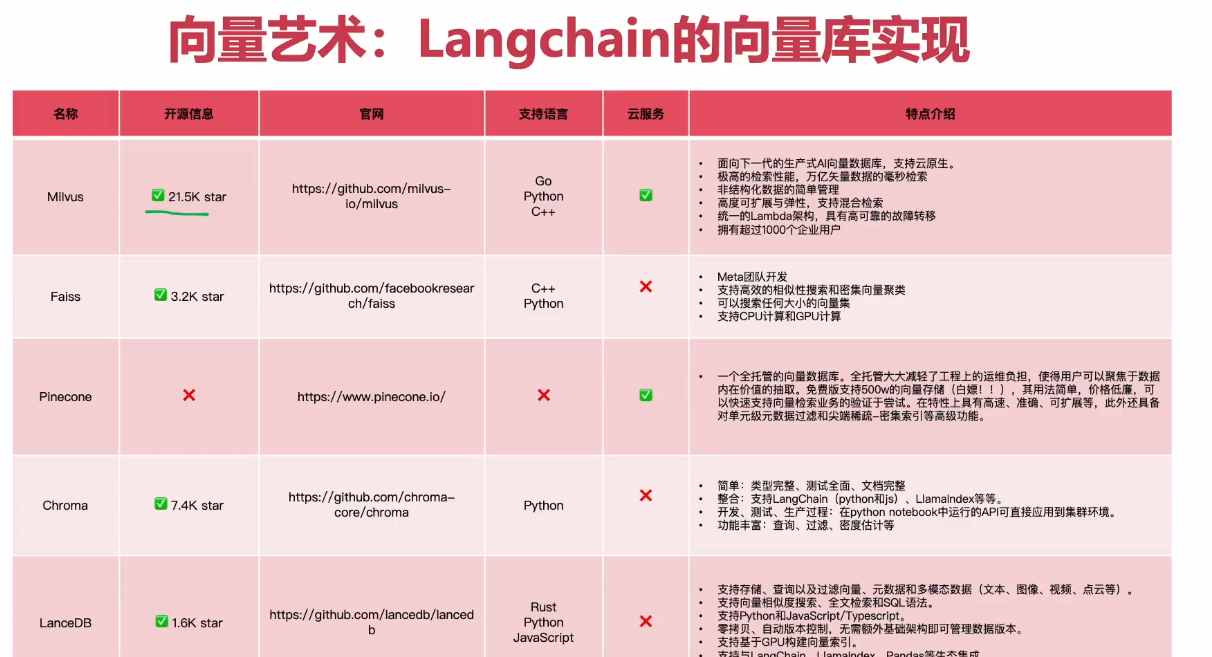
向量数据库的使用
- 向量库的数据增加
- 向量库的数据删除
- 向量库的相似性搜索
- 高级使用:MMR
- 高级使用:混合搜索
向向量数据库查询时,能以文本查找向量,也能以向量查询向量;混合搜索是指先用关键词进行搜索,然后再用向量的方式进行匹配;注意用向量的方式都是相似度匹配,向量查找不像文字查找;similarity_search这个查找方式,向量数据库一般都支持,但它的精准度也是最低的
向向量数据库增加数据:
一个demo,使用内存向量数据库,它将向量暂存在内存中,并使用字典以及numpy计算搜索的余弦相似度。
from langchain_openai import OpenAIEmbeddings
import os
embeddings_model = OpenAIEmbeddings(
model="BAAI/bge-m3",
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url=os.environ.get("DEEPSEEK_API_BASE")+"/v1",
)
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embedding=embeddings_model)
from langchain_core.documents import Document
document_1 = Document(
page_content="今天在抖音学会了一个新菜:锅巴土豆泥!看起来简单,实际炸了厨房,连猫都嫌弃地走开了。",
metadata={"source": "社交媒体"},
)
document_2 = Document(
page_content="小区遛狗大爷今日播报:广场舞大妈占领健身区,遛狗群众纷纷撤退。现场气氛诡异,BGM已循环播放《最炫民族风》两小时。",
metadata={"source": "社区新闻"},
)
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)
你可以为添加的文档增加ID索引,便于后面管理
vector_store.add_documents(documents=documents, ids=["doc1", "doc2"])
向量库的删除
vector_store.delete(ids=["doc1"])
向量库的相似性搜索,以文字查向量
其实还是先转化为向量,因为文字跟向量根本没办法做相似度匹配。
query = "遛狗"
docs = vector_store.similarity_search(query) #(query, k=10)返回最相近的10,默认是4个
print(docs[0].page_content) #打印第一个,因为它的相似度最高 那么这个的内容是多大呢,这其实就是之前TextSplitter切分文档时的一个切片,大小由切分时的chunk_size(token/字符数)决定
输出:
小区遛狗大爷今日播报:广场舞大妈占领健身区,遛狗群众纷纷撤退。现场气氛诡异,BGM已循环播放《最炫民族风》两小时。
还可以使用“向量”查相似”向量“的方式来进行搜索
embedding_vector = embeddings_model.embed_query(query)
docs = vector_store.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
输出:
小区遛狗大爷今日播报:广场舞大妈占领健身区,遛狗群众纷纷撤退。现场气氛诡异,BGM已循环播放《最炫民族风》两小时。
pinecone数据向量库使用:
注意:langchain只是在接口层面进行了封装,具体的搜索实现要依赖向量库本身的能力,比如Pinecone就可以进行元数据过滤,内存向量就不可以。
Pinecone官网: https://docs.pinecone.io/guides/get-started/quickstart
! pip install -qU langchain-pinecone pinecone-notebooks
import getpass
import os
import time
from pinecone import Pinecone, ServerlessSpec
if not os.getenv("PINECONE_API_KEY"):
os.environ["PINECONE_API_KEY"] = getpass.getpass("Enter your Pinecone API key: ")
pinecone_api_key = os.environ.get("PINECONE_API_KEY")
pc = Pinecone(api_key=pinecone_api_key)
初始化
import time
index_name = "langchain-test-index" # change if desired
existing_indexes = [index_info["name"] for index_info in pc.list_indexes()]
if index_name not in existing_indexes:
pc.create_index(
name=index_name,
dimension=3072, #注意维度要一致
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1"),
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
index = pc.Index(index_name)
添加嵌入模型
from langchain_pinecone import PineconeVectorStore
# 因为国产嵌入模型的维度只有1024,所以无法使用
vector_store = PineconeVectorStore(index=index, embedding=OpenAIEmbeddings(model="text-embedding-3-large"))
from uuid import uuid4
from langchain_core.documents import Document
document_1 = Document(
page_content="今天早餐吃了老王家的生煎包,馅料实在得快从褶子里跳出来了!这才是真正的上海味道!",
metadata={"source": "tweet"},
)
document_2 = Document(
page_content="明日天气预报:北京地区将出现大范围雾霾,建议市民戴好口罩,看不见脸的时候请不要慌张。",
metadata={"source": "news"},
)
document_3 = Document(
page_content="终于搞定了AI聊天机器人!我问它'你是谁',它回答'我是你爸爸',看来还需要调教...",
metadata={"source": "tweet"},
)
document_4 = Document(
page_content="震惊!本市一男子在便利店抢劫,只因店员说'扫码支付才有优惠',现已被警方抓获。",
metadata={"source": "news"},
)
document_5 = Document(
page_content="刚看完《流浪地球3》,特效简直炸裂!就是旁边大妈一直问'这是在哪拍的'有点影响观影体验。",
metadata={"source": "tweet"},
)
document_6 = Document(
page_content="新发布的小米14Ultra值不值得买?看完这篇测评你就知道为什么李老板笑得合不拢嘴了。",
metadata={"source": "website"},
)
document_7 = Document(
page_content="2025年中超联赛十大最佳球员榜单新鲜出炉,第一名居然是他?!",
metadata={"source": "website"},
)
document_8 = Document(
page_content="用LangChain开发的AI助手太神奇了!问它'人生的意义',它给我推荐了一份外卖优惠券...",
metadata={"source": "tweet"},
)
document_9 = Document(
page_content="A股今日暴跌,分析师称原因是'大家都在抢着卖',投资者表示很有道理。",
metadata={"source": "news"},
)
document_10 = Document(
page_content="感觉我马上要被删库跑路了,祝我好运 /(ㄒoㄒ)/~~",
metadata={"source": "tweet"},
)
documents = [
document_1,
document_2,
document_3,
document_4,
document_5,
document_6,
document_7,
document_8,
document_9,
document_10,
]
uuids = [str(uuid4()) for _ in range(len(documents))]
vector_store.add_documents(documents=documents, ids=uuids)
删除最后一项:
vector_store.delete(ids=[uuids[-1]])
相似性搜索支持元数据过滤
#这就是这个数据库的能力,既支持向量相似度搜索,又支持检索filter过滤
results = vector_store.similarity_search(
"看电影",
k=1, #只返回相似度最高的那一个
filter={"source": "tweet"}, #过滤的关键字,去Document的metadata中过滤信息
)
for res in results:
print(f"* {res.page_content} [{res.metadata}]")
输出:
刚看完《流浪地球3》,特效简直炸裂!就是旁边大妈一直问’这是在哪拍的’有点影响观影体验。 [{‘source’: ‘tweet’}]
通过分数进行搜索
#这个接口返回的是(Document, score),相对于上个接口多了一个分数(也就是置信度)
results = vector_store.similarity_search_with_score(
"明天热吗?", k=1, filter={"source": "news"}
)
for res, score in results:
print(f"* [SIM={score:3f}] {res.page_content} [{res.metadata}]")
输出:
[SIM=0.468292] 明日天气预报:北京地区将出现大范围雾霾,建议市民戴好口罩,看不见脸的时候请不要慌张。 [{‘source’: ‘news’}]
最大边际相关性搜索
并非所有向量库支持
在source为website 的文档中,找一条与“新手机”高度相关、同时尽量不冗余的信息
vector_store.max_marginal_relevance_search(
query="新手机",
k=1,
lambda_val=0.8,#0.8的相关性,0.2的不相关性
filter={"source": "website"},
)
混合搜索
混合搜索是指先用关键词进行搜索,然后再用向量的方式进行匹配
! pip install --upgrade --quiet pinecone pinecone-text pinecone-notebooks
import os
api_key = os.environ["PINECONE_API_KEY"]
from langchain_community.retrievers import (
PineconeHybridSearchRetriever,
)
#初始化
import os
from pinecone import Pinecone, ServerlessSpec
index_name = "langchain-pinecone-hybrid-search"
# initialize Pinecone client
pc = Pinecone(api_key=api_key)
# create the index
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=1536, # dimensionality of dense model
metric="dotproduct", # sparse values supported only for dotproduct
spec=ServerlessSpec(cloud="aws", region="us-east-1"),
)
index = pc.Index(index_name)
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
from pinecone_text.sparse import BM25Encoder
# or from pinecone_text.sparse import SpladeEncoder if you wish to work with SPLADE
# use default tf-idf values
bm25_encoder = BM25Encoder().default()
corpus = ["foo", "bar", "world", "hello"]
# fit tf-idf values on your corpus
bm25_encoder.fit(corpus)
# store the values to a json file
bm25_encoder.dump("bm25_values.json")
# load to your BM25Encoder object
bm25_encoder = BM25Encoder().load("bm25_values.json")
retriever = PineconeHybridSearchRetriever(
embeddings=embeddings, sparse_encoder=bm25_encoder, index=index
)
添加文本
retriever.add_texts(["foo", "bar", "world", "hello"])
检索
result = retriever.invoke("foo")
result[0]
五、检索器
可以像上面一样直接调用向量数据库的搜索,为什么还要向量数据库上加个检索器呢:
1.向量数据库只是检索,没法作复杂的检索策略。
2.Retriever是langchain的Runnable它是公用接口,对向量数据库做一个封装,调用不必关心下面的是什么类型的数据库,支持Runnable所有接口,可以进入langchain链条。
对他的使用包括:
-
基本检索器设置
-
词法搜索检索器
-
查询重写
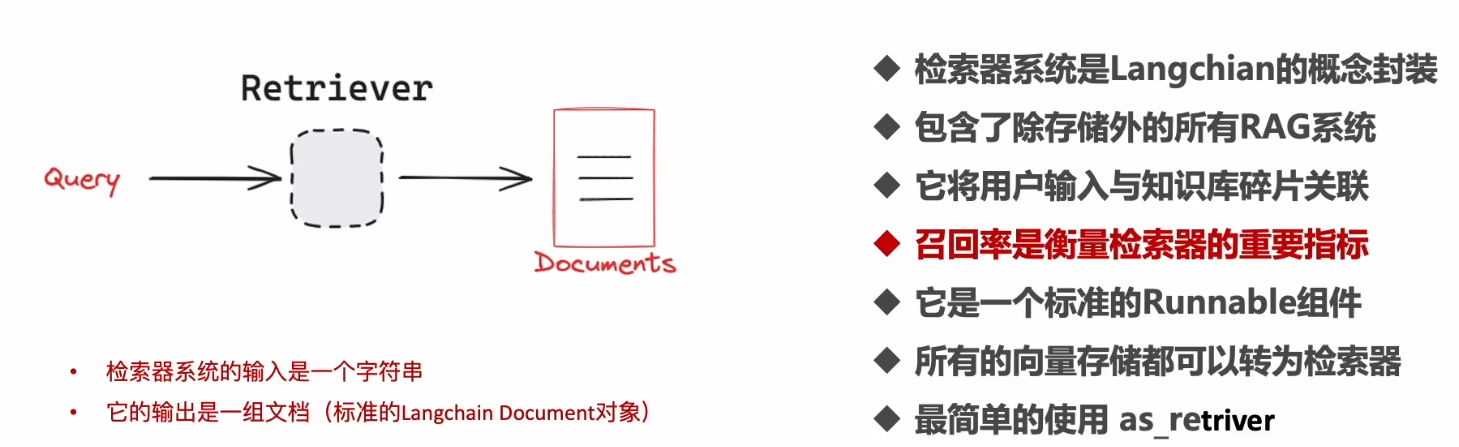

-
基本检索器设置as_retriever()
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
loader = TextLoader("test.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(texts, embeddings)
实例化检索器
retriever = vectorstore.as_retriever()
docs = retriever.invoke("deepseek是什么?")
打印docs输出
[Document(id='e60ca19a-6b5f-4995-9729-2e2aa6c08782', metadata={'source': 'test.txt'}, page_content='Deepseek R1 是⽀持复杂推理、多模态处理、技术⽂档⽣成的⾼性能通⽤⼤语⾔模型。本⼿册\n为技术团队提供完整的本地部署指南,涵盖硬件配置、国产芯⽚适配、量化⽅案、云端替代⽅\n案及完整671B MoE模型的Ollama部署⽅法。模型 参数规\n模\n计算精\n度\n最低显存需\n求 最低算⼒需求\nDeepSeek-R1 (671B) 671B FP8 ≥890GB\n2*XE9680(16*H20\nGPU)\nDeepSeek-R1-Distill-\n70B\n70B BF16 ≥180GB 4*L20 或 2*H20 GPU\n三、国产芯⽚与硬件适配⽅案\n1. 国内⽣态合作伙伴动态\n企业 适配内容 性能对标(vs\nNVIDIA)\n华为昇\n腾\n昇腾910B原⽣⽀持R1全系列,提供端到端推理优化\n⽅案 等效A100(FP16)\n沐曦\nGPU\nMXN系列⽀持70B模型BF16推理,显存利⽤率提升\n30% 等效RTX 3090\n海光\nDCU 适配V3/R1模型,性能对标NVIDIA A100 等效A100(BF16)\n2. 国产硬件推荐配置\n模型参数 推荐⽅案 适⽤场景\n1.5B 太初T100加速卡 个⼈开发者原型验证\n14B 昆仑芯K200集群 企业级复杂任务推理\n32B 壁彻算⼒平台+昇腾910B集群 科研计算与多模态处理\n12月26日,Deepseek发布了全新系列模型DeepSeek-v3,一夜之间霸榜开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及 Claude-3.5-Sonnet相提并论。\n\n该模型为MOE架构,大大降低了训练成本,据说训练成本仅600万美元,成本降低10倍,资源运用效率极高。有AI投资机构负责人直言,DeepSeek发布的53页的技术论文是黄金。\n\n那就先让我们看看论文是怎么说的吧,老规矩,先上资源地址:\n\nGithub: GitHub - deepseek-ai/DeepSeek-V3\n\n模型地址:https://huggingface.co/deepseek-ai\n\n论文地址:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf\n\n以下为技术解读:'),
- 词法搜索检索器BM25Retriever
BM25也称为Okapi BM25,是信息检索系统中用来估计文档与给定搜索查询的相关性的排名函数。
! pip install --upgrade --quiet rank_bm25
from langchain_community.retrievers import BM25Retriever
retriever_0 = BM25Retriever.from_texts(["foo", "bar", "world", "hello", "foo bar"]) #效果和from_documents()一样会自动包裹成Document对象
使用所创建的文档来创建一个新的检索器
from langchain_core.documents import Document
retriever = BM25Retriever.from_documents(
[
Document(page_content="foo"),
Document(page_content="bar"),
Document(page_content="world"),
Document(page_content="hello"),
Document(page_content="foo bar"),
]
)
result = retriever.invoke("foo")
print(result)
输出:
[Document(metadata={}, page_content='foo'),
Document(metadata={}, page_content='foo bar'),
Document(metadata={}, page_content='hello'),
Document(metadata={}, page_content='world')]
使用预处理器进行增强,在词语级别检索效果比较显著,punkt 是一个句子分割器模型
import nltk
nltk.download("punkt_tab")
from nltk.tokenize import word_tokenize
retriever = BM25Retriever.from_documents(
[
Document(page_content="foo"),
Document(page_content="bar"),
Document(page_content="world"),
Document(page_content="hello"),
Document(page_content="foo bar"),
],
k=2,
preprocess_func=word_tokenize,
)
result = retriever.invoke("bar")
print(result)
输出:
[Document(metadata={}, page_content='bar'),
Document(metadata={}, page_content='foo bar')]
- 查询重写MultiQueryRetriever
本质上就是把用户的问题,分割为更加清晰的问题,再去检索数据库,大部分AI应用都会用到,因为用户问的问题质量普遍不高。
比如:“介绍一下铜”,用户往往输出的提示不够精细,很难得到好的回答,需要改写这个问题为:“1.铜的历史 2.铜的颜色 3.铜的化学物理性质 4.铜的用处 5.铜的股价…”,然后把改写后的这些提示词代替用户的提示词来去问大模型。
但是改写成什么样子的提示词这个工作本身就需要智能,因此大模型来完成这个工作。
我们使用ARG的流程:用户问问题,到数据库里查询问题,然后把问题和数据库里的知识一起给大模型,让他来整理输出。查询重写相当于在查询数据库前,先把问题送给一个小模型进行提示词语改写。
一个实例:用户多伦对话,最后问,“还有呢”,这时需要把这个问题和上下文进行改写,把改写的内容,送入向量数据库查询,然后把查询的知识以及用户的问题,再次送入大模型里,大模型输出,给到用户。
这个过程中问了两次大模型,包括改写/重写时的那次,那么两次的大模型通常不是是同一个大模型么,重写是问小模型节省算力。相当于霸道总裁先问美丽秘书,秘书说了123,然后再具体问专家。
! pip install langchain_chroma #使用Chroma
from langchain_openai import OpenAIEmbeddings
import os
embeddings_model = OpenAIEmbeddings(
model="BAAI/bge-m3",
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url=os.environ.get("DEEPSEEK_API_BASE")+"/v1",
)
# Build a sample vectorDB
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load blog post
loader = WebBaseLoader("https://python.langchain.com/docs/how_to/MultiQueryRetriever/")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# VectorDB
vectordb = Chroma.from_documents(documents=splits, embedding=embeddings_model)
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_deepseek import ChatDeepSeek
import os
llm = ChatDeepSeek(
model="Pro/deepseek-ai/DeepSeek-V3",
temperature=0,
api_key=os.environ.get("DEEPSEEK_API_KEY"),
api_base=os.environ.get("DEEPSEEK_API_BASE"),
)
question = "如何让用户查询更准确?"
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm=llm #检索器包入小模型,用于查询重写
)
# Set logging for the queries
import logging
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
unique_docs = retriever_from_llm.invoke(question)
print(unique_docs)
len(unique_docs)
输出
INFO:langchain.retrievers.multi_query:Generated queries: ['1. 有哪些方法可以提高用户查询的精准度? ', '2. 如何优化用户查询以获得更准确的结果? ', '3. 在用户查询过程中,有哪些策略可以减少误差并提高准确性?']
[Document(id='8bd0d17d-6163-4531-b1e1-ea38ea2fb1ae', metadata={'description': 'Distance-based vector database。。。。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)