Agent思维链核心技术详解(保姆级教程)
目前 claude 4 sonnet、gemini 3 在 Agent 工具调用的场景下,都强制要求带工具调用的思考内容和签名,这个链路正常是能很大程度提升整体的推理执行效果,是 Agent 多步骤推理的必需品。但目前 Agent 模型的稳定性还是个问题,例如在某些场景下,业务逻辑明确需要下一步应该调工具 A,但模型思考后可能就是会概率性的调工具B,在以前是可以直接 hack 替换调工具调用,或手
文章介绍了Agent模型中的思维链概念,解释了不同模型对思维链的不同称呼和实现方式。核心在于将模型思考内容带入上下文,避免在多轮工具调用中重复思考,提高推理稳定性。Claude和Gemini等模型通过签名校验和加密等方式保护思考内容。思维链对Agent多步骤推理至关重要,但目前仍存在稳定性问题,需要进一步优化。
关于 Agent 模型的思维链,之前被几个高大上的词绕晕了,claude 提出 Interleaved Thinking(交错思维链),MiniMax M2 用了同样的概念,K2 叫 Thinking-in-Tools,Deepseek V3.2 写的是 Thinking in Tool-Use,gemini 则是 Thought Signature(思考签名)。了解了下,概念上比较简单,基本是一个东西,就是定义了模型思考的内容怎样在 Agent 长上下文里传递。
是什么
在25年年初 DeepSeek 的轰炸下,思考模型大家都很熟悉了,在 Chatbot 单轮对话中,模型会先输出思考的内容,再输出正文。再早的 GPT-o1 也一样,只不过 o1 不把完整的思考内容输出。
在 Chatbot 进行多轮对话时,每一次思考的内容是不会再带入上下文的。每次到下一轮时,思考的内容都会被丢弃,只有用户 prompt 和模型回答的正式内容会加到上下文。因为在普通对话的场景下没必要,更倾向于单轮对话解决问题,长上下文会干扰模型,也会增加 token 消耗。
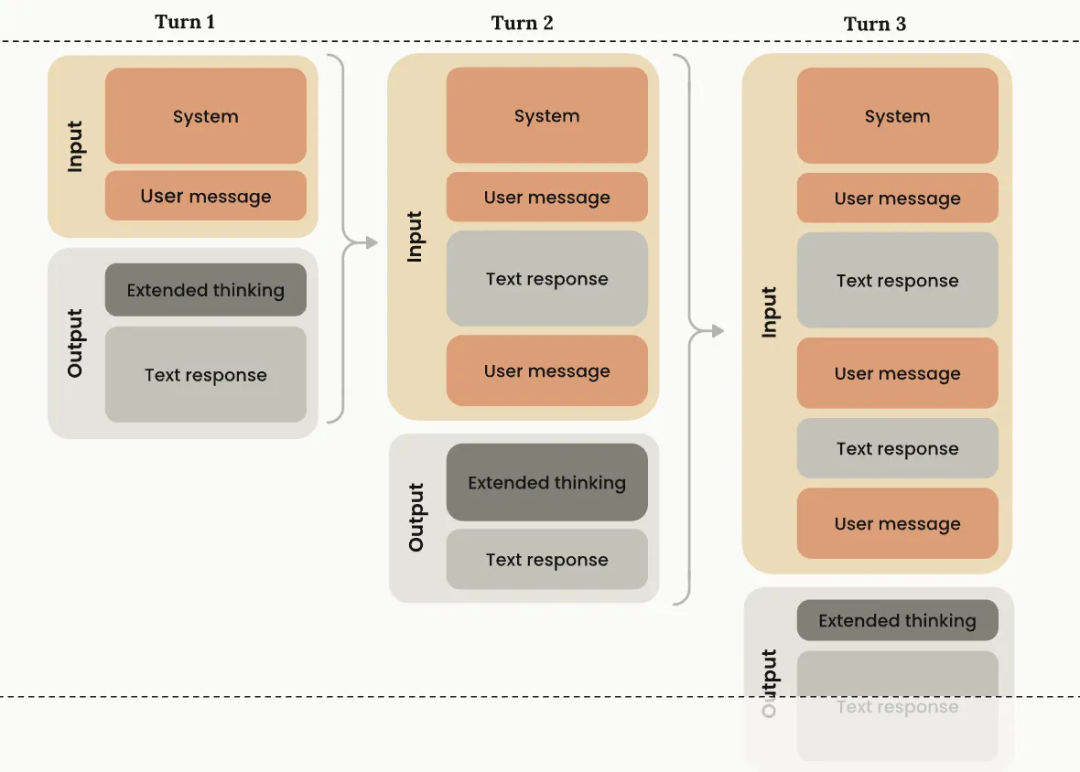
这些思考模型用到 Agent 上,就是下图这样,每次模型输出工具调用,同时都会输出思考内容,思考应该调什么工具,为什么调,但下次这个思考内容会被丢弃,不会带入上下文:
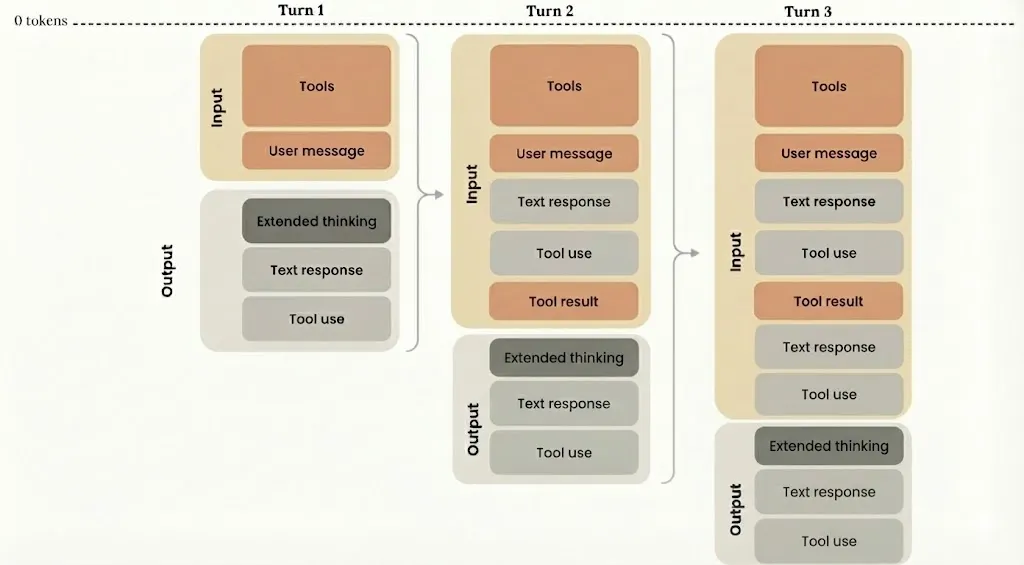
Agent 的 loop 是:用户输入 → 模型输出工具调用 → 调用工具得出结果 → 模型输入下一步工具调用 → 调用工具得出结果 → …. 直到任务完成或需要用户新的输入。
这不利于模型进行多轮长链路的推理,于是 claude 4 sonnet 提出把 thinking 内容带入上下文这个事内化到模型,以提升 Agent 性能,上下文的组织变成了这样:
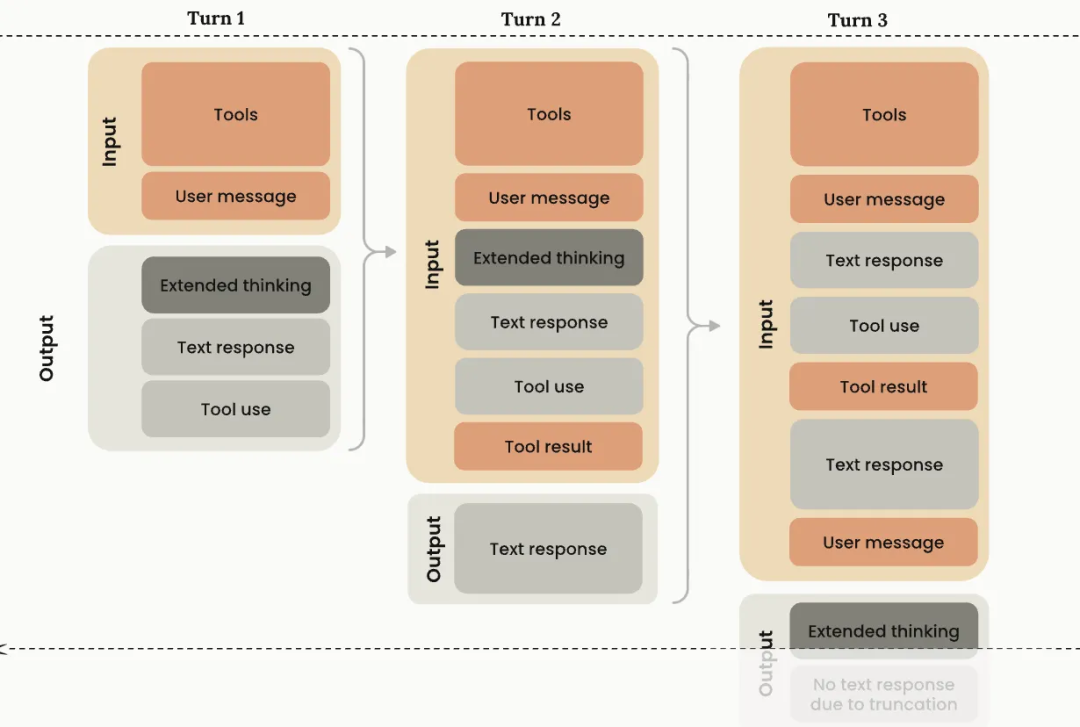
就这样一个事,称为 Interleaved Thinking,其他的叫法也都是一样的原理。
为什么要带 thinking
面向 Chatbot 的模型,倾向于一次性解决问题,尽量在一次 thinking 后一次输出解决问题。
Agent 相反,倾向于多步不断跟环境(tool和user)交互解决问题。
Agent 解决一个复杂问题可能要长达几十轮工具调用,如果模型对每次调用工具的思考内容都抛弃,只留下结果,模型每次都要重新思考每一轮为什么要调这个工具,接下来应该调什么工具。这里每一次的重新思考如果跟原来的思考推理有偏移,最终的结果就会有很大的出入和不稳定,这种偏移在多轮下几乎一定会发生。
如果每一轮调用的思考内容都放回上下文里,每次为什么调工具的推理逻辑上下文都有,思维链完整,就大大减少了模型对整个规划的理解难度和对下一步的调用计划的偏差。
有没有带 thinking 内容,对效果有多大差别?MiniMax-M2提供了他们的数据:
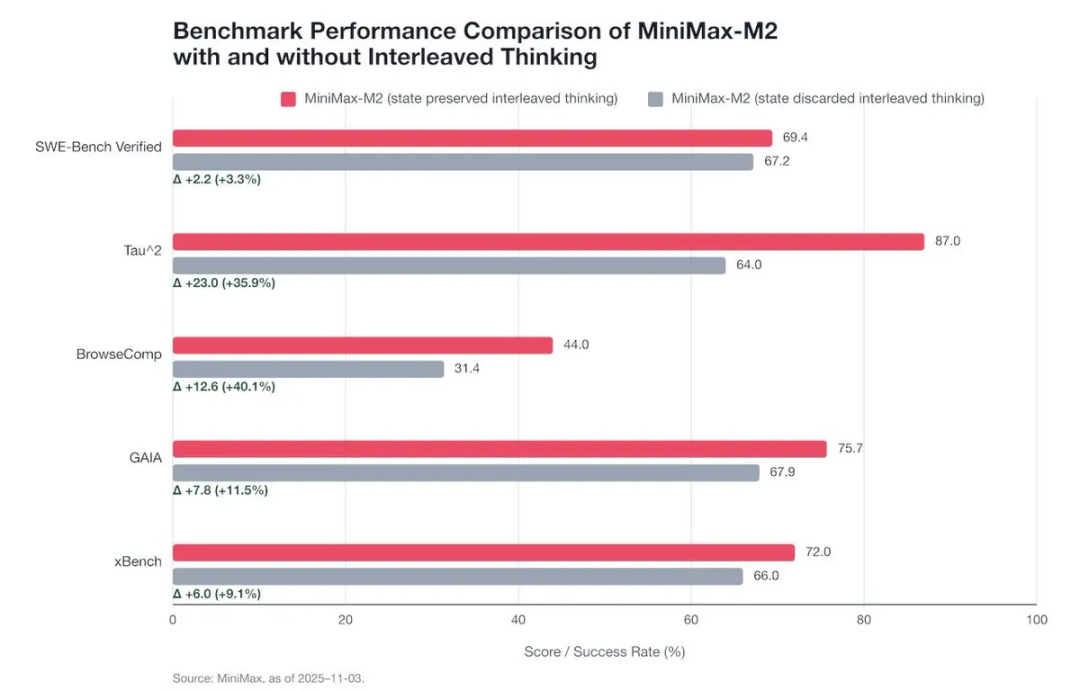
在像 Tau 这种机票预订和电商零售场景的任务 benchmark 提升非常明显,这类任务我理解需要操作的步数更多(比如搜索机票→筛选过滤→看详情→下单→支付),模型在每一步对齐前面的思路很重要,同一个工具调用可能的理由随机性更大,每一步的思考逻辑带上后更稳定。
工程也能做?
这么一个简单的事,不用模型支持,直接工程上拼一下给模型是不是也一样?比如手动把思考内容包在一个标签()里,伪装成 User Message 或 ToolResult 的一部分放在里面,也能达到保留思考的效果。
很多人应该这样做过,但跟模型原生支持还是有较大差别。
工程手动拼接,模型只会认为这部分仍是用户输入,而且模型的训练数据和流程没有这种类型的用户输入和拼接,效果只靠模型通用智能随意发挥。
模型原生支持,训练时就可以针对这样规范的上下文训练,有标注大量的包含思考过程的trajectory轨迹数据训练,响应的稳定性必然会提升,这也是 Agent 模型的重点优化点之一。
签名
上述工具调用的 thinking 内容带到下一轮上下文,不同的模型做了不同额外的处理,主要是加了不同程度的签名,有两种:
thinking 内容原文,带签名校验
claude 和 gemini 都为 thinking 的内容加了签名校验,带到下一轮时,模型会前置判断思考内容有没有被篡改。
为什么要防 thinking 内容被篡改?毕竟 prompt 也可以随便改,同样是上下文的 thinking 内容改下也没什么。
主要应该是篡改了模型的 thinking 内容会打乱模型的思路,让效果变差,这也是需要避免的。
另外模型在训练和对齐时,已经默认 thinking 是模型自己的输出,不是用户随意的输入,这是两个不同类型的数据,如果实际使用时变成跟Prompt一样可随意篡改,可能有未知的安全问题。
不过国内模型目前没看到有加这个签名校验的。
thinking 内容加密
claude 在一些情况下不会输出自然语言的 thinking 内容,而是包在redacted_thinking里,是一串加密后的数据。
而 gemini 2.5/3.0 的 Agent 思维链没有明文的 thinking 字段,而是 thought_signature,也是一串加密后的数据。
用这种加密的非自然语言数据,一个好处是,它可以是对模型内部更友好、压缩率更大的数据表述方式,也可以在一些涉及安审的场景下内容不泄露给用户。
更重要的还是防泄漏,这就跟最开始 GPT o1 不输出所有思考内容一样,主要是为了不暴露思考过程,模型发布后不会太轻易被蒸馏。
最后
目前 claude 4 sonnet、gemini 3 在 Agent 工具调用的场景下,都强制要求带工具调用的思考内容和签名,这个链路正常是能很大程度提升整体的推理执行效果,是 Agent 多步骤推理的必需品。
但目前 Agent 模型的稳定性还是个问题,例如在某些场景下,业务逻辑明确需要下一步应该调工具 A,但模型思考后可能就是会概率性的调工具B,在以前是可以直接 hack 替换调工具调用,或手动插入其他工具调用,没有副作用。
但在思维链这套机制下比较麻烦,因为没法替模型输出这个工具调用的思考内容,一旦打破这个链,对后续推理的效果和稳定性都会有影响。
可能模型厂商后续可以出个允许上层纠错的机制,例如可以在某个实际告诉函数工具选择错误,重新思考,原生支持,弥补模型难以保障稳定的不足。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献142条内容
已为社区贡献142条内容

所有评论(0)