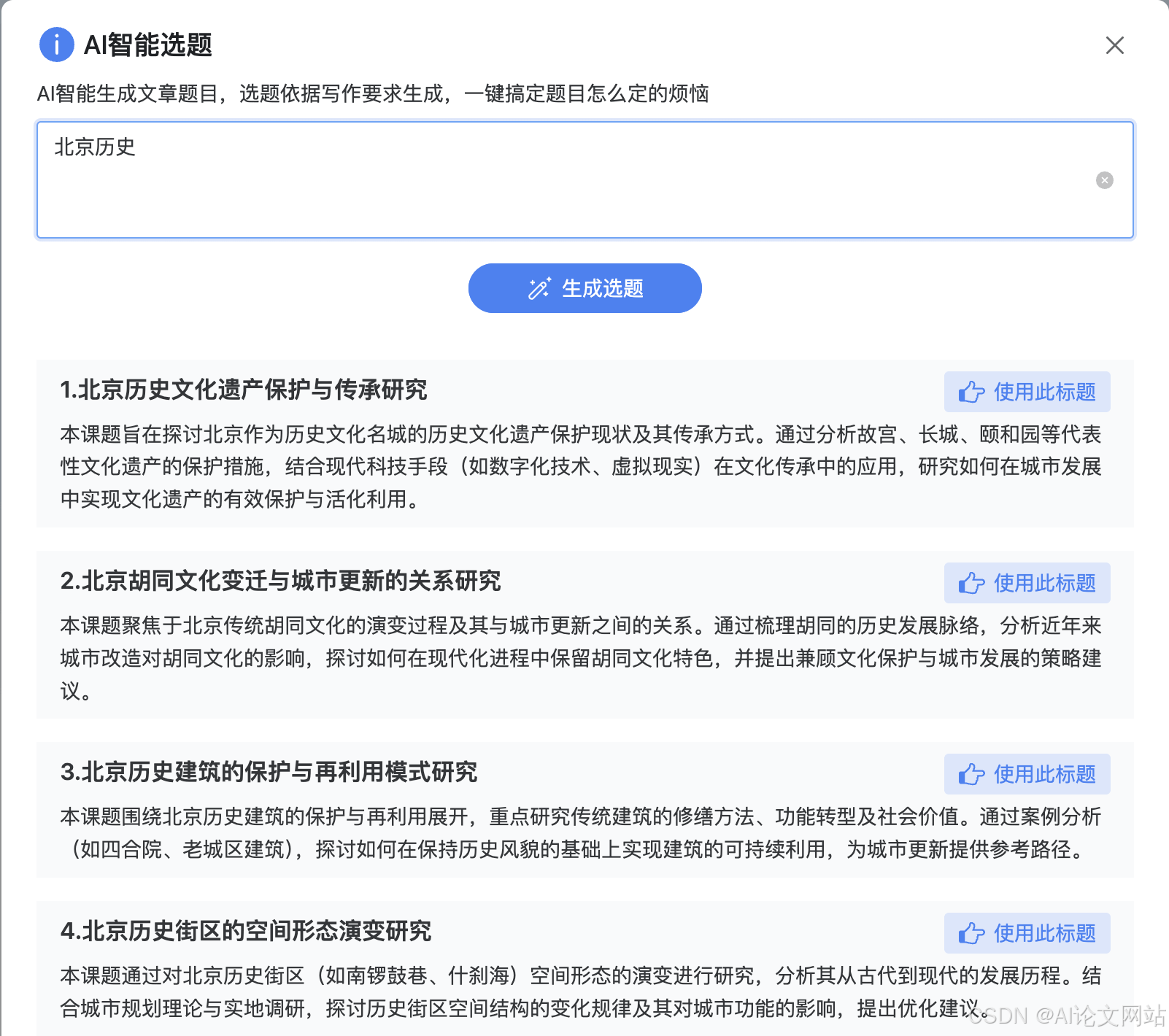
2026 年初主流大模型对比:谁更适合你的项目?
没有“最好”的模型,只有“最合适”的模型。建议先明确你的核心需求(中文/英文、创意/合规、成本/性能),然后用少量测试集快速验证。2026 年的竞争让开发者有了更多选择——用好它们,而不是被它们困住。作者发布日期标签:大模型, GPT‑4.5, DeepSeek, GLM, Claude, 模型选型, AI 对比。
·
2026 年初主流大模型对比:谁更适合你的项目?
概述
大模型赛道在 2026 年已从“狂热堆参数”进入“场景适配”阶段。本文基于近期实测,对比几款具有代表性的模型,帮你做出技术选型。
1. OpenAI GPT‑4.5 Turbo
定位:全能型商用标杆。
亮点:
- 推理链完整:复杂逻辑任务(代码调试、多步规划)表现稳定。
- 工具调用精准:API 设计成熟,支持函数调用、多模态输入。
- 上下文 128K:长文档处理能力强,且价格已降至 $0.001/1K tokens。
短板: - 访问需梯子,国内团队有延迟风险。
- 定制化能力有限(无法微调底层权重)。
适合:企业级应用、产品原型快速验证、需要稳定输出的生产环境。
2. DeepSeek‑V3.2(千帆版)
定位:国产开源旗舰,性价比之王。
亮点:
- 完全免费(通过千帆平台),支持 128K 上下文。
- 代码生成突出:在 Python/JavaScript 等常见语言上媲美 GPT‑4。
- 中文理解自然:成语、古文、网络用语处理得更接地气。
短板: - 复杂推理(如数学证明、多轮对话)偶尔会“跳步”。
- 工具调用生态尚未成熟。
适合:国内团队、学生项目、代码辅助、中文内容创作。
3. GLM‑4.7(智谱)
定位:中文场景专用模型。
亮点:
- 中文领域知识最新:对 2025‑2026 年国内政策、科技动态覆盖更好。
- 多模态原生支持:图像理解、表格解析无需额外配置。
- 企业级服务:支持私有化部署、数据隔离。
短板: - 英文任务略弱于前述两者。
- 创意写作风格偏“正经”,幽默感不足。
适合:政务、金融、教育等中文强相关行业,以及需要多模态输入的内部系统。
4. Claude 3.5 Sonnet(Anthropic)
定位:安全与合规优先。
亮点:
- 拒绝机制完善:对敏感、有害请求处理得更“谨慎”,适合合规场景。
- 长文档分析强:200K 上下文,且记忆保持能力优秀。
- 写作风格优雅:适合文案、报告等正式文本生成。
短板: - 有时过于“保守”,创造性任务可能受限。
- 价格偏高($0.003/1K tokens)。
适合:法律、医疗、金融等高风险行业,以及需要高度合规的跨国团队。
5. 开源新星:Qwen2.5‑72B
定位:可完全自托管的开源替代。
亮点:
- Apache 2.0 协议:商用无忧,可随意修改、分发。
- 多语言均衡:中、英、德、法等多语言表现接近。
- 硬件友好:支持 INT4 量化,可在消费级 GPU(如 RTX 4090)运行。
短板: - 需要自行部署和维护,技术门槛较高。
- 实时知识更新依赖外部检索插件。
适合:有自研团队的公司、对数据隐私要求极高的场景、研究机构。
选型建议
| 需求场景 | 首选模型 | 次选模型 |
|---|---|---|
| 快速原型、产品 MVP | GPT‑4.5 Turbo | DeepSeek‑V3.2 |
| 国内项目、成本敏感 | DeepSeek‑V3.2 | GLM‑4.7 |
| 中文多模态(图/表) | GLM‑4.7 | GPT‑4.5 Turbo |
| 高风险、强合规 | Claude 3.5 Sonnet | GLM‑4.7 |
| 完全自主可控、可修改源码 | Qwen2.5‑72B | 自行微调 LLaMA‑3 |
趋势观察
- 价格战持续:主流模型单价每季度下降 10‑15%,推理成本不再是核心瓶颈。
- 场景垂直化:通用模型基础上,涌现出代码、法律、医疗等垂直优化版本。
- 小型化:7B‑14B 参数模型在特定任务上已接近千亿模型,边缘部署成为可能。
结语
没有“最好”的模型,只有“最合适”的模型。建议先明确你的核心需求(中文/英文、创意/合规、成本/性能),然后用少量测试集快速验证。2026 年的竞争让开发者有了更多选择——用好它们,而不是被它们困住。
作者:13810319282
发布日期:2026‑02‑13
标签:大模型, GPT‑4.5, DeepSeek, GLM, Claude, 模型选型, AI 对比

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)