
AI大模型的原理及发展现状概要介绍
AI的核心目标是,例如语言理解、图像识别、复杂问题解决等。• 早期阶段:以规则为基础的专家系统,依赖预设的逻辑和规则。——规则库• 机器学习时代:通过数据训练模型,使机器能够从数据中学习规律。——几十、几百个参数• 深度学习时代:利用神经网络模拟人脑的复杂结构,处理更复杂的任务。——几百万个参数• 大模型时代:以大规模数据和算力为基础,构建通用性强、性能卓越的AI模型。

一、AI的分类
AI的核心目标是让机器能够执行通常需要人类智能的任务,例如语言理解、图像识别、复杂问题解决等。
• 早期阶段:以规则为基础的专家系统,依赖预设的逻辑和规则。 ——规则库
• 机器学习时代:通过数据训练模型,使机器能够从数据中学习规律。 ——几十、几百个参数
• 深度学习时代:利用神经网络模拟人脑的复杂结构,处理更复杂的任务。 ——几百万个参数
• 大模型时代:以大规模数据和算力为基础,构建通用性强、性能卓越的AI模型。——671b个参数(6710亿)
AI分类如下:

生成式AI:包括大语言模型(GPT、deepseek、千问),场景客服咨询、内容创作;生图/生视频模型(Sora、DALL-E、Midjourney),如进行产品设计、影视预览。
分析式AI:视觉识别模型(YOLO、ResNet),场景如智能制造、医疗影像分析,能准确辨别影像中的物体、人脸、文字等;自动驾驶模型(复合模型),场景如无人配送、高级辅助驾驶。
二、LLM是如何训练的
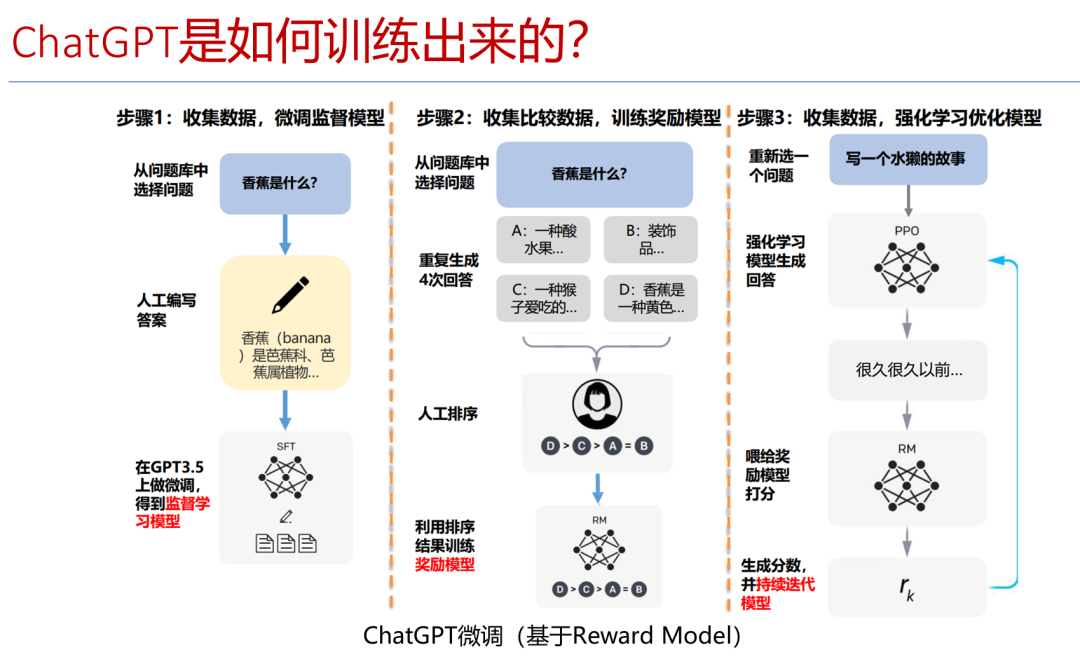
LLM的训练过程通俗的表述可以参考下图。早些时候是通过监督学习,明确告诉模型“香蕉是什么”;后来模型生成多个答案,人类通过来对答案进行优劣排序的方式训练模型;再后来,模型知道了一些人类的偏好,通过强化学习生成答案,人类通过一些打分机制,使模型进一步自我迭代进化。
早在2018年时GPT的参数量约为1.17亿,预训练数据量约5GB;2019年,GPT-2参数量为15亿,预训练数据量为40GB;2020年,GPT-3的参数量为1750亿,预训练数据为45TB。如今,GPT-5参数量预估约为100万亿。ChatGPT可以实现对用户真实意图的理解,上下文衔接能和及对知识和逻辑的理解能力。
在互联网时代诞生的APP功能越来越复杂,有限的屏幕难以呈现复杂的功能,未来APP极有可能演进为极简页面的对话形式,比如人们在淘宝对话框输入想要的穿搭风格,淘宝自动搜索相应的服装套件,并将其放入购物车。
三、LLM中的Token
Token是大型语言模型处理文本的最小单位。由于模型本身无法直接理解文字,因此需要将文本切分成一个个 Token,再将 Token转换为数字(向量)进行运算。
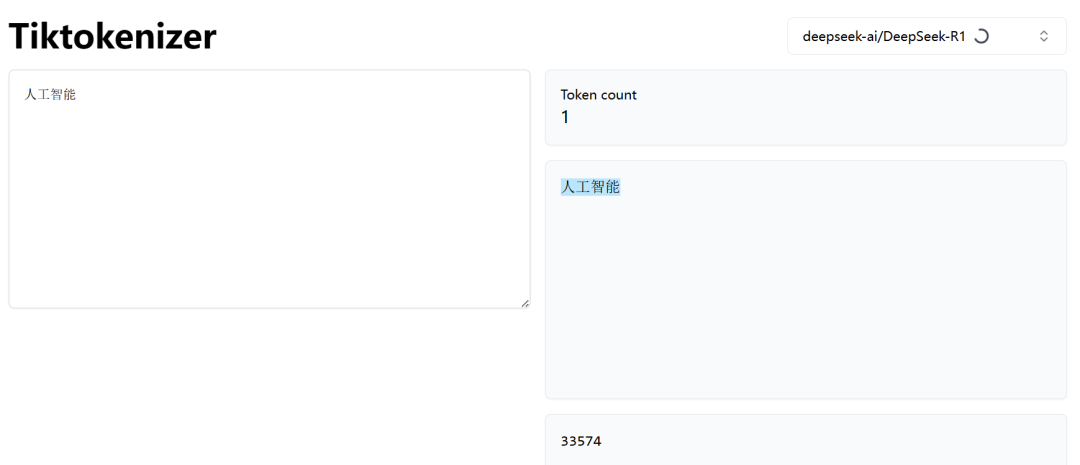
不同的模型使用不同的“分词器”(Tokenizer)来定义Token(不同模型中同样的文字编码不同)。 例如,对于英文Hello World: GPT-4o 会切分为[“Hello“, ”World“] => 对应的 token id = [13225, 5922] 。对于中文“人工智能你好啊”: DeepSeek-R1会切分为[“人工智能”, “你好”,“啊”] => 对应的token id = [33574, 30594, 3266]。
可以在科学上网模式下,通过https://tiktokenizer.vercel.app/ 查看token映射,例如“人工智能”,在deepseek中占一个token,而在GPT-4o中,则是“人工”和“智能”两个token。除了文本所占的token外,还有分隔符、起如符、结束符也会占用token。
四、Temperature 与Top P的作用
大模型生成文字的过程本质上是概率预测。大模型中的Temperature, Top P则通过调整选择不同概率的Token倾向,来控制 LLM 生成文本的多样性,但两者原理不同。
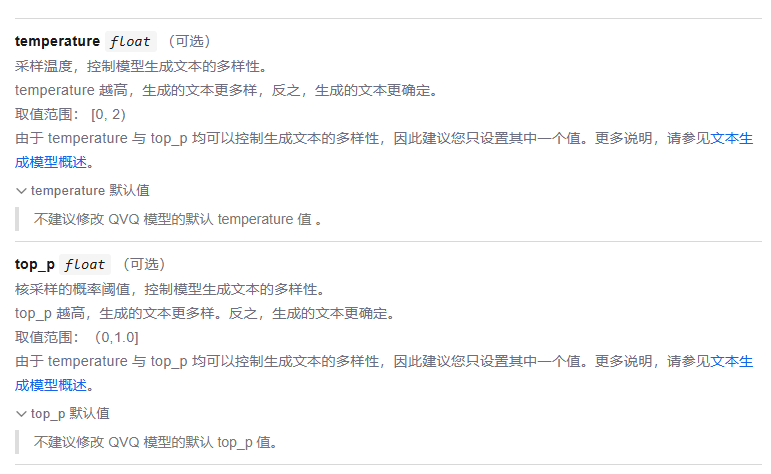
• Temperature (温度):
原理:在模型计算出下一个Token所有可能的概率分布后,Temperature会调整这个分布的“平滑度”。
高Temperature (如 1.0+):会让低概率的Token更容易被选中,使生成结果更具创造性,但可能出现不连贯的词语。
低Temperature (如 0.2):会让高概率的Token权重更大,使生成结果更稳定、更符合训练数据,但会更保守。
• Top P (核采样):
原理:它设定一个概率阈值(P),然后从高到低累加所有Token的概率,直到总和超过P为止。模型只会在这个累加出来的“核心”词汇表中选择下一个Token。
• 高Top P (如0.9):候选词汇表较大,结果更多样。
• 低Top P (如 0.1):候选词汇表非常小,结果更具确定性。
举个例子:
假设模型要完成句子:“今天天气真...”
模型预测的下一个词可能是:好(60%)、不错(30%)、糟(9%)、可乐(0.01%)。
高Temperature:会提升所有词的概率,使得“可乐”这个不相关的词也有机会被选中。
Top P (设为0.9):会选择概率总和达到90%的词。这里好(60%) + 不错(30%) = 90%,所以模型只会从“好”和“不错”中 选择,直接排除了“可乐”这种离谱的选项。
Temperature及Top P可以通过API进行设置。
参考:进入阿里云的dashscope(https://dashscope.console.aliyun.com/),dashscope网页->模型广场->(任选一个模型) API详情,然后找Temperature及Top P参数。
五、AI Chat产品的超能力——联网搜索、读取文件记忆功能
1、联网搜索
通过获取外部信息,弥补LLM训练数据截止日期的限制。
1)当用户提问涉及最新资讯时,系统会识别出这一需求,自动调用搜索工具,并将问题转化为多个简洁的搜索关键词。
2)程序调用搜索引擎API(如Google搜索)获取信息。
3)这些实时信息会作为上下文提供给模型,由模型进行总结和提炼,生成精准且与时俱进的回答。
2、读取文件
大模型一次会话窗口可以容纳32k的文字(大概3万多字),基于“检索增强生成”(Retrieval-Augmented Generation, RAG)的技术,大模型可以一次性读取多个文件(如10万字),并将关键信息提取放入窗口中,这样大模型一次性就可以读取超过32k的内容。
1)当你上传一个文件(如PDF、Word文档)时,系统首先会将其内容分割成小块(Chunks)。
2)通过Embedding技术将这些文本块转化为数学向量,并存储在专门的“向量数据库”中。
3)当你针对文件内容提问时,系统会将你的问题也转化为向量,并在数据库中快速找到最相关的文本块, 最后将这些文本块连同你的问题一起交给模型,生成答案。
比如,上传一份公司财报后,提问“第二季度的利润是多少?” RAG系统能精确定位到财报中相关的片段,让LLM直接使用。
RAG是一个LLM application,LLM看到了文件,发现文件大于 32k,于是调用了RAG能力(即:过滤内容,检索出来相关内容的能力)。
3、记忆能力
LLM本身是无状态的(无记忆能力),每次对话都是一次全新的互动,不记得之前的交流。
为了实现“记忆”,系统会在每次对话时,将最近的几轮问答作为背景信息拼接在一起发送给模型,称为“短期记忆”或“上下文窗口”。短期只能记住当前message + LLM response 不超过 32k 的内容。
对于需要长期记住的关键信息,例如你的名字或偏好,系统会通过特定算法提取这些信息,将其存储在用户专属的数据库中,在后续的对话中,系统会先从数据库中读取,为模型提供更个性化的背景知识。
比如,告诉AI“我喜欢简洁的回答风格”,系统会记录这一偏好。下次提问时,它就会倾向于给出更简练的答复。
六、全球AI发展现状
全球AI模型发展现状(中美对比):
• 美国:OpenAI、Anthropic、Google、Meta等公司主导前沿模型,如GPT-4o、Claude 4 Sonnet、Gemini 2.5 Flash。
• 中国:DeepSeek(如R1、V3)、阿里巴巴(如Qwen3)、Moonshot等公司快速追赶,部分模型(如Kimi K2, DeepSeek R1)已接近美国前沿水平。
• 关键趋势:中国模型在2024年显著缩小与美国的差距,尤其在推理模型和开源模型领域表现突出。
• 其他地区:法国(Mistral)、加拿大(Cohere)等也有前沿模型,但中美仍是主导力量。
七、出品限制与硬件影响
美国对华限制:
• 时间线:2022年10月首次限制(H100、A100),2023年10月升级(H800、A800受限),2025年1月新增“AI扩 散规则”。
• 当前状态:仅H20、L20等低性能芯片可出口中国,未来可能进一步收紧。
• 影响:中国依赖国产芯片(如华为昇腾)或降级版NVIDIA芯片(如H20,算力仅为H100的15%)。
硬件性能对比:
• NVIDIA H100:989 TFLOPs,3.35 TB/s带宽。
• NVIDIA H20:148 TFLOPs,4 TB/s带宽(专为中国市场设计)。
• AMD MI300X:1307 TFLOPs,5.3 TB/s带宽(未受限制)。
八、中国AI公司概览
大科技公司:
• 阿里巴巴:通义千问(Qwen)系列,Qwen3
• 百度:文心一言(Ernie 4.0 Turbo)
• 腾讯:混元大模型(HunyuanLarge)
• 字节跳动:豆包(Doubao1.6 Pro)
• 华为:盘古5.0(Pangu 5.0 Large)
初创公司:
• DeepSeek:R1、V3,开源模型表现优异。
• Moonshot:Kimi K2,专注长上下文窗口。
• MiniMax:Text-01,多模态能力突出。
• 其他:智谱AI(ChatGLM)、百川智能(Baichuan)等。
如何学习AGI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取