拒绝通用回答!手把手教你给 SpringBoot 项目装上“私有大脑” (DeepSeek + ChromaDB)
拒绝通用回答!手把手教你给 SpringBoot 项目装上“私有大脑” (DeepSeek + ChromaDB)
摘要:还在用 ChatGPT 猜代码?本文分享如何利用 DeepSeek + ChromaDB + Watchdog,为你的 SpringBoot 项目搭建一个能“读懂源码”、实时同步业务逻辑的本地 RAG 智能助手。
😫 痛点:AI 为什么总是不懂我?
作为一名全栈开发者,我每天都在和 AI 结对编程。但时间久了,我发现了一个非常棘手的痛点:
AI 缺乏项目上下文(Context)。
- 当我问:“用户登录报错了,帮我看看。” —— AI 给我一堆通用的 Spring Security 排查建议,但它不知道我用的是 Sa-Token。
- 当我问:“这个字段在数据库里定义成什么了?” —— AI 两手一摊,因为它看不见我的
init.sql。 - 每写一个新的业务模块,我都得把相关的 Entity、Controller、Service 复制一遍喂给 AI,它才能开始工作。
我就在想:能不能让 AI 直接“住”进我的项目里?
它应该像一个刚入职的高级同事,不仅熟读所有源码,还能在我修改代码的瞬间,自动更新它的知识库。
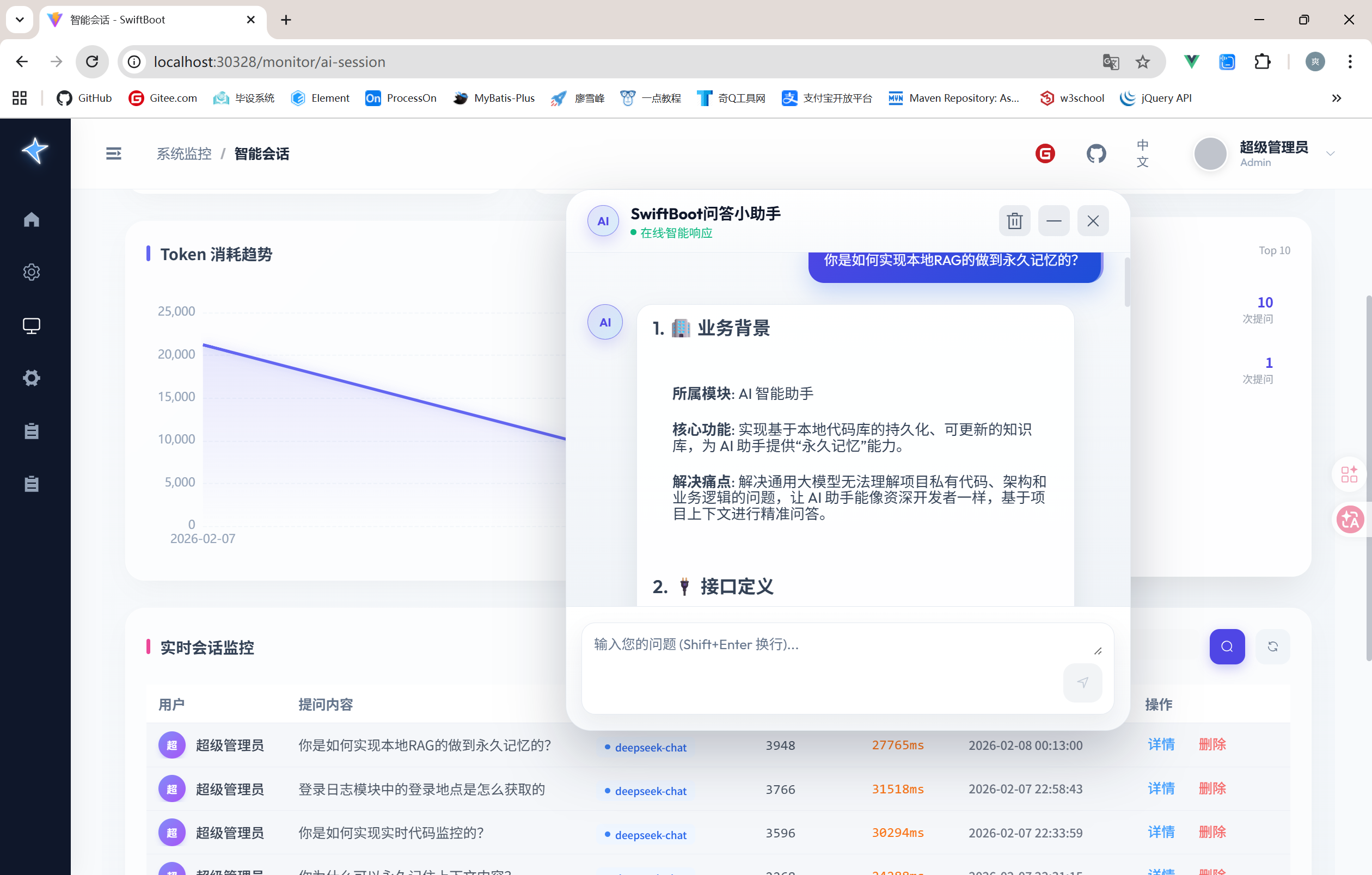
经过一番折腾,我基于 DeepSeek-V3 和 ChromaDB 实现了一套项目级 RAG(检索增强生成)架构,并将其集成到了我的开源项目 SwiftBoot 中。今天就来复盘一下这套架构的实现细节。
🛠️ 架构选型:为什么是 DeepSeek + ChromaDB?
要实现“私有化知识库”,核心就是 RAG 技术。简单来说,就是**“先查后问”**:
- 用户提问。
- 系统在本地代码库中检索相关片段。
- 将问题 + 代码片段一起喂给 LLM。
在技术选型上,我踩过不少坑,最终确定了这套方案:
- 大模型:DeepSeek-V3
- 理由:目前国内最强(没有之一),编码能力吊打 GPT-4o,而且 API 极其便宜。最重要的是,它的推理能力非常适合处理复杂的业务逻辑。
- 向量数据库:ChromaDB
- 理由:轻量级、嵌入式、无需 Docker 部署。对于一个开源框架来说,我不希望用户为了跑个 AI 还要去装 Milvus 或 Pinecone,Chroma 直接存成本地文件,体验极佳。
- 文件监听:Python Watchdog
- 理由:Java 的热部署(DevTools)主要针对 Class 文件,而我们需要监听
.java源码文件的文本变化。Python 的 Watchdog 库极其成熟,能毫秒级捕获文件修改事件。
- 理由:Java 的热部署(DevTools)主要针对 Class 文件,而我们需要监听
💻 核心实现拆解
1. 自动代码切片与向量化 (Python 端)
首先,我们需要一个“爬虫”,但它爬的不是网页,而是我们本地的 Java 源码。
我写了一个 KnowledgeIngest 类,利用 LangChain 的 RecursiveCharacterTextSplitter 对代码进行切片。
关键点:代码切片不能像切小说那样只按字符数切。Java 代码有类、方法、注解的结构。
我采用了一种策略:以“类”为单位进行粗切,以“方法”为单位进行细切,并保留文件路径作为元数据(Metadata)。
# vector_store.py 核心逻辑
from langchain.text_splitter import RecursiveCharacterTextSplitter
def process_java_file(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 使用代码专用的分隔符
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\nclass ", "\npublic ", "\nprotected ", "\nprivate ", "\n\n", "\n"]
)
docs = splitter.create_documents([content], metadatas=[{"source": file_path}])
return docs
2. 实时监听代码变更 (Watchdog)
这是让 AI 变“聪明”的关键。如果我改了 SysUserController.java,AI 的知识库里还是旧代码,那它就是在误导我。
我使用 watchdog 库监听项目根目录,一旦检测到 .java 或 .xml (Mapper) 文件变动,立即触发增量更新。
# file_watcher.py
from watchdog.events import FileSystemEventHandler
class CodeChangeHandler(FileSystemEventHandler):
def on_modified(self, event):
if event.src_path.endswith(".java"):
print(f"[监听] 检测到代码变更: {event.src_path}")
# 1. 删除向量库中该文件的旧索引
vector_store.delete(where={"source": event.src_path})
# 2. 重新切片并插入新索引
new_docs = process_java_file(event.src_path)
vector_store.add_documents(new_docs)
print("[同步] 知识库已更新!")
这样一来,你的代码就是文档。你改了代码,AI 下一秒就知道了。
3. 后端流式响应 (Java + SSE)
为了达到像官网那样的“打字机”效果,后端接口不能一次性返回所有文本。我使用了 Spring Boot 的 SseEmitter。
这里有个坑:DeepSeek 返回的是 Markdown 格式,如果直接推给前端,可能会导致代码块渲染闪烁。我们需要在前端做一下缓冲处理,但在后端,核心是保持长连接不亦断。
// SysAiController.java
@GetMapping(value = "/chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter chatStream(@RequestParam String question) {
SseEmitter emitter = new SseEmitter(0L); // 0L 表示不过期
// 异步调用 Python AI 服务
aiService.streamChat(question, chunk -> {
try {
emitter.send(chunk);
} catch (IOException e) {
emitter.completeWithError(e);
}
});
return emitter;
}
✨ 最终效果
经过这番改造,现在的 SwiftBoot AI 助手已经具备了惊人的“自我意识”:
- 懂架构:问它“这个项目的权限控制是怎么做的?”,它会精准定位到
Sa-Token的拦截器配置,并解释StpUtil的用法。 - 懂业务:问它“新增一个学生管理模块需要改哪些文件?”,它会列出 Controller、Service、Mapper 的创建步骤,甚至直接生成符合项目规范的代码。
- 零延迟:刚改完代码,马上问它,它引用的就是最新逻辑。
🎁 源码与获取
这套 DeepSeek + ChromaDB + Watchdog 的完整实现代码,我已经全部开源并集成到了 SwiftBoot 框架中。
这是一个基于 Spring Boot 3 + Vue 3 的现代化全栈框架,除了 AI 能力,还内置了:
- 🚀 可视化代码生成器 (一键生成前后端)
- 📊 智能监控大屏
- 🔄 字典自动回显
获取方式:
- Gitee (国内极速): https://gitee.com/cs_shuang/SwiftBoot
- GitHub: https://github.com/328pikapika-bot/SwiftBoot
如果你觉得这个思路对你有启发,欢迎点个 Star ⭐,或者在评论区交流你的 RAG 落地经验!
#Java #SpringBoot #AI #DeepSeek #RAG #开源项目

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)