SAA Graph 内存管理源码分析
AI的记忆能力是需要分层的,结合具体的业务场景具体使用,MultiTurnContextManager 维持的是聊天的火热度,Saver 维持的是程序的生命力,Store 维持的是知识的厚度。
·
SAA Graph 内存管理源码分析
文章目录
短期记忆 CheckpointSaver
BaseCheckpointSaver
-
核心职责:在 AI 状态图中,负责保存对话的记忆和执行状态,执行引擎的“快照”机制。它是一个“基础设施组件”。
- 断点续传:当工作流因人工审批(Human-in-the-loop)或错误中断时,可以从最后一个 Checkpoint 恢复。
- 多轮对话管理:通过 threadId 区分不同的用户会话,确保状态互不干扰。
- 版本管理/回溯:保存了状态的历史记录,允许回滚到之前的某个状态。
-
BaseCheckpointSaver接口
public interface BaseCheckpointSaver {
String THREAD_ID_DEFAULT = "$default";
Collection<Checkpoint> list(RunnableConfig config);
Optional<Checkpoint> get(RunnableConfig config);
RunnableConfig put(RunnableConfig config, Checkpoint checkpoint) throws Exception;
Tag release(RunnableConfig config) throws Exception;
record Tag(String threadId, Collection<Checkpoint> checkpoints) {
public Tag(String threadId, Collection<Checkpoint> checkpoints) {
this.threadId = threadId;
this.checkpoints = ofNullable(checkpoints).map(List::copyOf).orElseGet(List::of);
}
}
}
- BaseCheckpointSaver类图
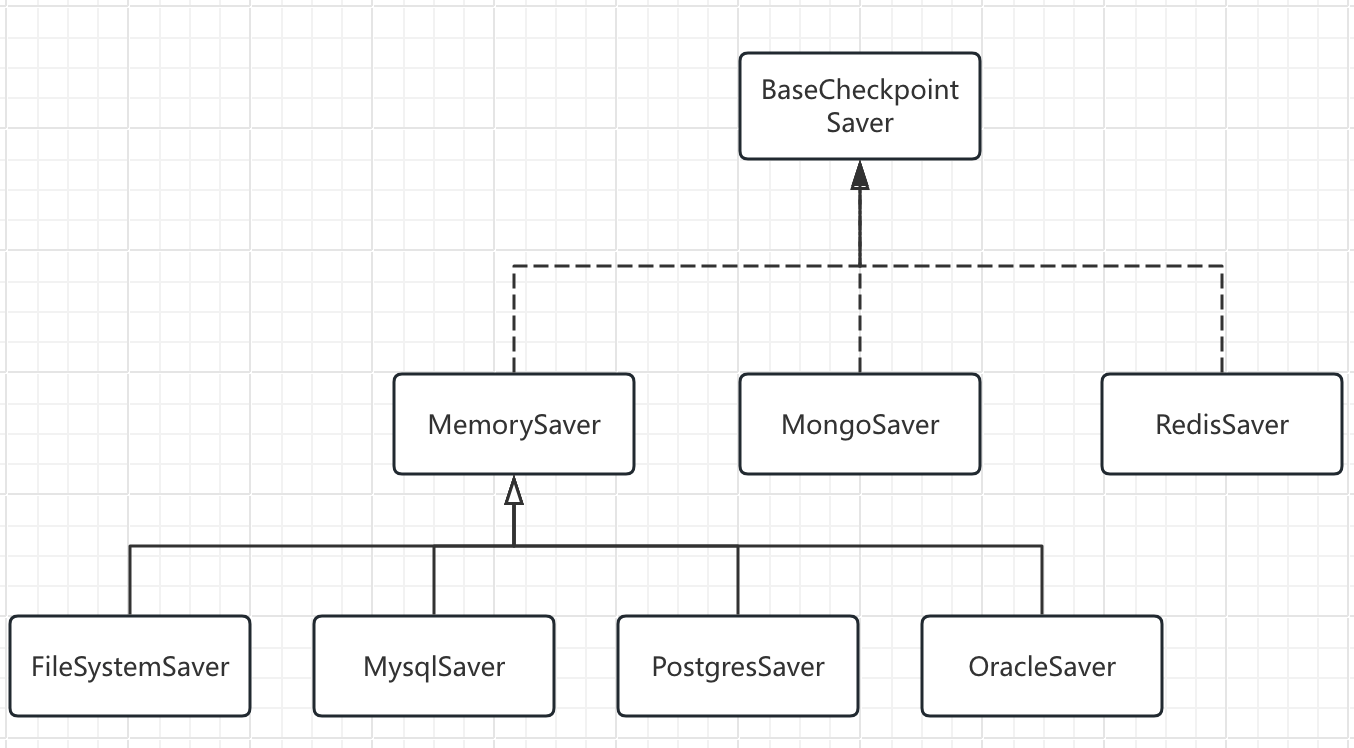
MemorySaver
- 它是一个基于内存的状态持久化器(Checkpoint Saver),主要用于在 AI 智能体(Agent)或工作流执行过程中,记录、读取和管理各个节点的“状态快照”(Checkpoints)
- OverAllState 是执行时的内存数据,而 MemorySaver 存储的是 OverAllState 在某一时刻的“快照”(Snapshot)。MemorySaver 和 OverAllState 是通过 Checkpoint 对象紧密结合在一起使用的。
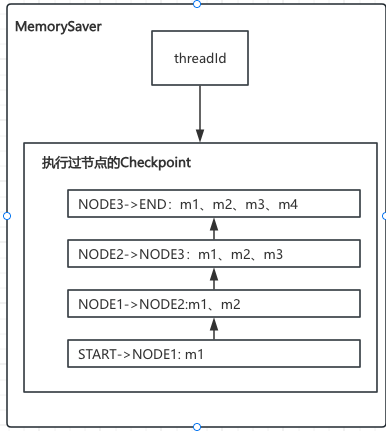
关键数据结构
- _checkpointsByThread:
- 类型:Map<String, LinkedList>
- Key 是 threadId(会话 ID)。
- Value 是一个 LinkedList,按时间顺序存储了该会话的所有状态快照。
- _lock:
- 类型:ReentrantLock
- 重要性:由于 AI 图任务通常是异步或并发执行的(如多个节点并行运行),使用重入锁确保了对内存中状态读写操作的线程安全。
核心方法解析
A. loadOrInitCheckpoints (模板方法)
这是内部最核心的辅助方法。它封装了“加锁 -> 获取 ThreadId -> 执行逻辑 -> 释放锁”的标准化流程。
- 它使用 transformer(一个函数式接口)来处理具体的增删改查逻辑,保持了代码的简洁和高并发下的安全性。
B. put (保存/更新状态
- 更新模式:如果 config 中带了 checkPointId,它会在历史记录中找到那个旧快照并替换。
- 新增模式:如果不带 ID,它会使用 checkpoints.push(checkpoint) 将新状态压入链表顶部(最新的状态始终在最前面)。
- 钩子函数:调用了 insertedCheckpoint 或 updatedCheckpoint,方便子类扩展(例如打印日志或指标统计)。
C. get (获取状态)
- 支持精准获取:通过 checkPointId 获取历史中某个特定时刻的状态。
- 支持默认获取:如果不指定 ID,调用 getLast 获取当前会话的最新状态。
D. release (释放/清理)
- 根据 threadId 彻底删除该会话的所有历史记录。这通常用于会话结束或主动清空记忆。
public class MemorySaver implements BaseCheckpointSaver {
final Map<String, LinkedList<Checkpoint>> _checkpointsByThread = new HashMap<>();
private final ReentrantLock _lock = new ReentrantLock();
//钩子方法 (Hooks):loadedCheckpoints, insertedCheckpoint,updatedCheckpoint,releasedCheckpoints 等方法都是 protected 且为空实现。这是一种模板模式,允许开发者继承 MemorySaver 来实现例如“持久化到 Redis”或“异步写入数据库”的增强功能,而不需要修改核心锁逻辑。
protected LinkedList<Checkpoint> loadedCheckpoints(RunnableConfig config, LinkedList<Checkpoint> checkpoints) throws Exception {
return checkpoints;
}
protected void insertedCheckpoint(RunnableConfig config, LinkedList<Checkpoint> checkpoints, Checkpoint checkpoint) throws Exception {
}
protected void updatedCheckpoint(RunnableConfig config, LinkedList<Checkpoint> checkpoints, Checkpoint checkpoint) throws Exception {
}
protected void releasedCheckpoints(RunnableConfig config, LinkedList<Checkpoint> checkpoints, Tag releaseTag) throws Exception {
}
protected final <T> T loadOrInitCheckpoints(RunnableConfig config,
TryFunction<LinkedList<Checkpoint>, T, Exception> transformer) throws Exception {
//它封装了“加锁 -> 获取 ThreadId -> 执行逻辑 -> 释放锁”的标准化流程。
_lock.lock();
try {
var threadId = config.threadId().orElse(THREAD_ID_DEFAULT);
return transformer.tryApply(loadedCheckpoints(config, _checkpointsByThread.computeIfAbsent(threadId, k -> new LinkedList<>())));
}
finally {
_lock.unlock();
}
}
protected final Collection<Checkpoint> remove(String threadId) {
return _checkpointsByThread.remove(Objects.requireNonNull(threadId));
}
@Override
public final Collection<Checkpoint> list(RunnableConfig config) {
try {
// 使用了 Collections::unmodifiableCollection 返回不可变集合,防止外部代码意外修改内存中的原始数据。
return loadOrInitCheckpoints(config, Collections::unmodifiableCollection);
}
catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public final Optional<Checkpoint> get(RunnableConfig config) {
try {
return loadOrInitCheckpoints(config, checkpoints -> {
//支持精准获取:通过 checkPointId 获取历史中某个特定时刻的状态。
if (config.checkPointId().isPresent()) {
return config.checkPointId()
.flatMap(id -> checkpoints.stream()
.filter(checkpoint -> checkpoint.getId().equals(id))
.findFirst());
}
//支持默认获取:如果不指定 ID,调用 getLast 获取当前会话的最新状态。
return getLast(checkpoints, config);
});
}
catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public final RunnableConfig put(RunnableConfig config, Checkpoint checkpoint) throws Exception {
return loadOrInitCheckpoints(config, checkpoints -> {
if (config.checkPointId().isPresent()) {
// 更新模式:如果 config 中带了 checkPointId,它会在历史记录中找到那个旧快照并替换。
String checkPointId = config.checkPointId().get();
int index = IntStream.range(0, checkpoints.size())
.filter(i -> checkpoints.get(i).getId().equals(checkPointId))
.findFirst()
.orElseThrow(() -> (new NoSuchElementException(format("Checkpoint with id %s not found!", checkPointId))));
checkpoints.set(index, checkpoint);
// 钩子函数:便于mysql等持久化实现
updatedCheckpoint(config, checkpoints, checkpoint);
return config;
}
//新增模式:如果不带 ID,它会使用 checkpoints.push(checkpoint) 将新状态压入链表顶部(最新的状态始终在最前面)。
checkpoints.push(checkpoint);
// 钩子函数:便于mysql等持久化实现
insertedCheckpoint(config, checkpoints, checkpoint);
return RunnableConfig.builder(config)
.checkPointId(checkpoint.getId())
.build();
});
}
@Override
public final Tag release(RunnableConfig config) throws Exception {
return loadOrInitCheckpoints(config, checkpoints -> {
//根据 threadId 彻底删除该会话的所有历史记录。这通常用于会话结束或主动清空记忆。
var threadId = config.threadId().orElse(THREAD_ID_DEFAULT);
var tag = new Tag(threadId, remove(threadId));
// 钩子函数:便于mysql等持久化实现
releasedCheckpoints(config, checkpoints, tag);
return tag;
});
}
}
实战场景分析
在你的 AI 项目中,MemorySaver 通常这样使用:
- 场景 1:流式对话
当用户问“它是谁?”时,引擎通过 threadId 调用 get 拿到上一轮的 Checkpoint,从而知道“它”指的是什么。 - 场景 1:人工审查 (Human-in-the-loop)
工作流运行到“转账确认”节点,引擎调用 put 保存状态并暂停。用户点击网页上的“同意”后,后端从内存中取出 Checkpoint,恢复图执行。
长期记忆 Store
Store
-
核心职责:用于持久化存储跨会话的数据,语义存储、用户画像、知识沉淀,当然你想让 AI 具备“成长性”(记住关于用户的长久信息):你需要自己定义数据结构并存入 MemoryStore。
- 用户偏好设置 (User Profile):
- Namespace: users/123/preferences
- Key: language -> Value: zh-CN
- 跨会话的“事实性”知识 (Learned Facts):
- AI 经过分析发现:devices/sensor_01 的正常电压范围是 220V-240V。它将此存入 Store。以后任何会话询问该设备,AI 都能直接查表获取。
- 简单的 RAG(无向量搜索需求):
- 存储一些 FAQ 或者是配置信息,不需要做复杂的向量转换,直接根据 Key 或前缀匹配。
- 用户偏好设置 (User Profile):
-
Strore接口
public interface Store {
/**
* 在指定的命名空间中存储具有给定键的项。如果具有相同命名空间和键的项已存在,则会更新该项。
*/
void putItem(StoreItem item);
/**
* 从指定的命名空间中检索具有给定键的项。
*/
Optional<StoreItem> getItem(List<String> namespace, String key);
/**
* 从指定命名空间中删除具有给定键的项。
*/
boolean deleteItem(List<String> namespace, String key);
/**
* 根据提供的搜索条件搜索。
*/
StoreSearchResult searchItems(StoreSearchRequest searchRequest);
/**
* 根据所提供的条件列出可用的命名空间。
*/
List<String> listNamespaces(NamespaceListRequest namespaceRequest);
/**
* 清空,警告:此操作不可逆,并将删除所有已存储的内容。
*/
void clear();
/**
* 获取总数。
*/
long size();
/**
* 校验是否为空
*/
boolean isEmpty();
}
- Store类图
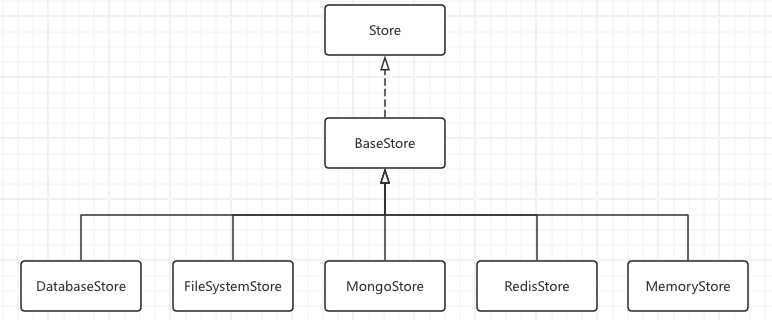
MemoryStore
- MemoryStore 本质上是一个带 命名空间(Namespace) 隔离的高级内存数据库。
- 数据结构 (ConcurrentHashMap + ReadWriteLock):
- 使用 ConcurrentHashMap 保证基础读写的并发安全。
- 引入了 ReentrantReadWriteLock(读写锁):
- 读锁 (readLock):允许多个线程同时进行 getItem、searchItems 或 listNamespaces。
- 写锁 (writeLock):在 putItem 或 deleteItem 时是互斥的。
- 设计意图:这通常是为了优化 “搜索” 性能。因为 searchItems 涉及全表扫描、过滤、排序和分页,耗时较长,读写锁能防止在搜索时数据被修改导致的不一致。
- 分层命名空间 (Namespace):
- Key 的格式是 namespace1/namespace2/key。
- listNamespaces 支持 maxDepth 参数。你可以像查询文件目录一样查询记忆的结构(例如:查询 user_1/ 下的所有子分类)。
- 高级查询能力 (searchItems):
- 它不是简单的 KV 获取,它支持:
- Filtering:根据自定义条件过滤。
- Sorting:根据字段排序。
- Pagination:支持 offset 和 limit(分页)。
- 实战含义:这证明了它的定位是存储大量、零散的信息,而不是像 MemorySaver 那样只存一个大的状态快照。
- 它不是简单的 KV 获取,它支持:
业务层记忆 MultiTurnContextManager
- 我们可以基于自身的业务设计的多轮对话上下文(记忆)管理器MultiTurnContextManager。
关键数据结构
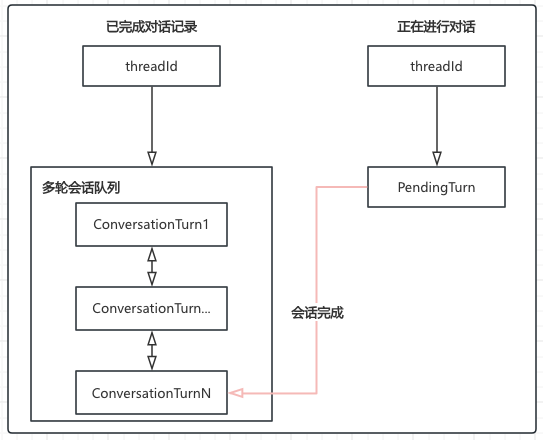
- 该类维护了两个关键的 Map,将“进行中的对话”与“已完成的对话”分开处理:
- history (历史记录):
- 存储已经完成的对话回合(User Question + AI Plan)。
- 使用 Deque(双端队列)实现一个滑动窗口。当记忆超过配置的 maxTurnHistory 时,会自动丢弃最老的一轮(FIFO),防止 Prompt 长度爆炸。
- pendingTurns (缓冲区):
- 存储当前正在生成中的对话。
- 因为 AI 的响应通常是**流式(Streaming)**返回的,所以需要一个 StringBuilder (planBuilder) 来不断追加(Append)碎片字符,直到回答结束。
- history (历史记录):
MultiTurnContextManager源码
@Slf4j
@Component
@AllArgsConstructor
public class MultiTurnContextManager {
private final AgentProperties properties;
// todo:考虑持久化存储
private final Map<String, Deque<ConversationTurn>> history = new ConcurrentHashMap<>();
private final Map<String, PendingTurn> pendingTurns = new ConcurrentHashMap<>();
/**
* 当系统接收到用户的新问题时调用。它在 pendingTurns 中开辟一块空间,记录当前的问题,并初始化一个新的计划缓冲区。
*/
public void beginTurn(String threadId, String userQuestion) {
if (StringUtils.isAnyBlank(threadId, userQuestion)) {
return;
}
pendingTurns.put(threadId, new PendingTurn(userQuestion.trim()));
}
/**
* 流式追加 (appendPlannerChunk)
*/
public void appendPlannerChunk(String threadId, String chunk) {
if (StringUtils.isAnyBlank(threadId, chunk)) {
return;
}
PendingTurn pending = pendingTurns.get(threadId);
if (pending != null) {
pending.planBuilder.append(chunk);
}
}
/**
* 完成归档 (finishTurn),当流式输出结束(Complete)时调用
*/
public void finishTurn(String threadId) {
PendingTurn pending = pendingTurns.remove(threadId);
if (pending == null) {
return;
}
String plan = StringUtils.trimToEmpty(pending.planBuilder.toString());
if (StringUtils.isBlank(plan)) {
log.debug("No planner output recorded for thread {}, skipping history update", threadId);
return;
}
String trimmedPlan = StringUtils.abbreviate(plan, properties.getMaxPlanLength());
Deque<ConversationTurn> deque = history.computeIfAbsent(threadId, k -> new ArrayDeque<>());
synchronized (deque) {
while (deque.size() >= properties.getMaxTurnHistory()) {
deque.pollFirst();
}
deque.addLast(new ConversationTurn(pending.userQuestion, trimmedPlan));
}
}
/**
* 当运行停止的时候丢失缓存的对话
*/
public void discardPending(String threadId) {
pendingTurns.remove(threadId);
}
/**
* 重新启动上一轮,以便新的规划器输出可以替换它(例如,在人工反馈之后)。 上一个已保存的轮次将被删除,其问题将被重新使用。
*/
public void restartLastTurn(String threadId) {
Deque<ConversationTurn> deque = history.get(threadId);
if (deque == null || deque.isEmpty()) {
return;
}
ConversationTurn lastTurn;
synchronized (deque) {
lastTurn = deque.pollLast();
}
if (lastTurn != null) {
pendingTurns.put(threadId, new PendingTurn(lastTurn.userQuestion()));
}
}
/**
* 构建多轮对话提示词
* 用户: [问题A]
* AI计划: [计划A]
* 用户: [问题B]
* AI计划: [计划B]
*/
public String buildContext(String threadId) {
Deque<ConversationTurn> deque = history.get(threadId);
if (deque == null || deque.isEmpty()) {
return "(无)";
}
return deque.stream()
.map(turn -> "用户: " + turn.userQuestion() + "\nAI计划: " + turn.plan())
.collect(Collectors.joining("\n"));
}
private record ConversationTurn(String userQuestion, String plan) {
}
private static class PendingTurn {
private final String userQuestion;
private final StringBuilder planBuilder = new StringBuilder();
private PendingTurn(String userQuestion) {
this.userQuestion = userQuestion;
}
}
}
对比总结
核心概念对比
| 维度 | MultiTurnContextManager | Saver (Checkpoint) | Store (Long-term) |
|---|---|---|---|
| 人类类比 | 语境意识 (Dialogue Flow) | 瞬时/短期记忆 (Working Memory) | 长久记忆/知识库 (Semantic Memory) |
| 框架层级 | 业务逻辑层 (Application) | 执行引擎层 (Graph Infrastructure) | 全局资源层 (Global Resource) |
| 存储内容 | 对话文本对(问与答的字符串) | 状态机快照(变量、中间结果、标志位) | 结构化事实/偏好(KV键值对、JSON) |
| 关注点 | 语义连贯性(用于注入 Prompt) | 执行可靠性(断点续传、人工审查) | 个性化与进化(跨会话记住用户特征) |
| 数据范围 | 当前会话的最近 N 轮 | 当前 Thread 的全量执行状态 | 全局或按 Namespace 隔离的长久数据 |
开发总结:什么时候该用谁?
-
如果你发现 AI “前言不搭后语”:
→→ 优化 MultiTurnContextManager(增加滑动窗口大小,改进 Prompt 模板)。
-
如果你希望程序报错后能接着跑,或者需要人工点击按钮才继续:
→→ 配置 Saver(将 MemorySaver 升级为 JdbcCheckpointSaver)。
-
如果你希望 AI 具备“成长性”,能记住用户的名字、常用偏好、或者之前总结的规律:
→→ 使用 Store(定义 Namespace,将业务事实写入 StoreItem)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)