C++【第八篇】 ——— 异常处理的核心机制和智能指针管理
目录
异常的基本语法与含义
#include <iostream>
using namespace std;
// 除法函数:包含异常抛出逻辑
// 功能:计算x/y的结果,若除数y为0则抛出异常
double Div(int x, int y)
{
if (y == 0)
{
// throw:抛出异常(中断当前函数执行,跳转到最近的catch块)
// 抛出的异常类型为const char*(字符串字面量),内容为"除0错误"
throw "除0错误";
}
else
{
// 正常计算:转为double类型避免整数除法
return (double)x / (double)y;
}
}
// 业务函数:调用Div,可能触发异常
void Func()
{
int a = 0, b = 0;
cin >> a >> b; // 读取用户输入的两个整数
cout << Div(a, b) << endl; // 调用Div,若b=0则触发异常
}
int main()
{
// ===================== 异常捕获核心语法 =====================
// try块:包裹“可能抛出异常的代码”,监控其中的异常
try
{
Func(); // 调用Func,Func内部调用Div,可能抛出异常
}
// catch块:捕获并处理指定类型的异常(按类型匹配)
// 第一个catch:专门捕获const char*类型的异常(匹配Div抛出的异常)
catch (const char* str)
{
// 处理异常:打印异常信息
cout << str << endl;
}
// 第二个catch:catch(...) 是“万能捕获”,捕获所有未被上面catch匹配的异常
catch (...)
{
// 处理未知异常:避免程序崩溃
cout << "未知异常" << endl;
}
return 0;
}一、C++ 异常处理的核心定义
C++ 异常处理是程序运行时错误的响应机制,用于处理 “运行时才会暴露的异常情况”(如除 0、空指针访问、文件打开失败等),核心是 “抛出(throw)- 捕获(catch)” 模型:
- 当程序检测到无法处理的错误时,通过
throw主动 “抛出异常”,中断当前函数的正常执行流程; - 程序中预先用
try-catch块 “监控” 可能出错的代码,catch会按类型匹配并捕获异常,执行错误处理逻辑; - 相比传统的 “返回错误码” 方式,异常处理能精准定位错误、跨函数传递错误信息,且不污染正常返回值。
二、异常处理的核心语法(try-throw-catch)
异常处理的语法由try(监控)、throw(抛出)、catch(捕获)三部分组成,缺一不可:
| 语法部分 | 核心作用 |
|---|---|
try { ... } |
包裹 “可能抛出异常的代码”,监控该代码块内的所有异常,是异常捕获的 “监控范围” |
throw 异常值 |
主动抛出异常(中断当前函数执行),异常值可以是任意类型(字符串、整数、自定义类等) |
catch(类型) { ... } |
捕获并处理指定类型的异常,类型需与throw抛出的异常值类型严格匹配 |
catch(...) { ... } |
万能捕获块,捕获所有未被上面catch匹配的异常,避免程序崩溃 |
异常处理的执行流程
- 正常执行:
try块内的代码无异常时,跳过所有catch块,继续执行后续代码; - 异常触发:
try块内(或嵌套调用的函数内)执行throw时,立即中断当前函数,跳转到try块后第一个匹配类型的catch块; - 异常处理:执行匹配的
catch块内的错误逻辑,处理完成后跳过剩余catch块,继续执行程序; - 未捕获异常:若无匹配的
catch块(也无catch(...)),程序会调用terminate()终止运行(崩溃)。
三、代码中的异常处理逻辑拆解
1. 异常抛出(throw):Div 函数的错误检测
double Div(int x, int y)
{
if (y == 0)
{
// 抛出异常:类型为const char*,内容为"除0错误"
// 执行throw后,Div函数立即中断,不会执行后续的return
throw "除0错误";
}
else
{
return (double)x / (double)y; // 无异常时正常返回
}
}
- 触发条件:用户输入的除数
b=0时,Div(a, b)会执行throw; - 异常类型:抛出的是
const char*类型的字符串字面量,需用catch(const char*)匹配。
2. 异常传播:Func 函数的嵌套调用
void Func()
{
int a = 0, b = 0;
cin >> a >> b;
cout << Div(a, b) << endl; // 调用Div,异常会从Div传播到Func
}
- 异常传播规则:
Div抛出的异常会 “向上传播” 到调用者(Func),若 Func 无try-catch,则继续传播到 main 函数的try块; - 传播终止:异常被
catch捕获后,传播立即停止。
3. 异常捕获(try-catch):main 函数的错误处理
try
{
Func(); // 监控Func调用过程中的异常(包括Div抛出的异常)
}
// 第一个catch:精准匹配const char*类型的异常(Div抛出的类型)
catch (const char* str)
{
cout << str << endl; // 处理异常:打印"除0错误"
}
// 第二个catch:万能捕获,处理所有未匹配的异常(兜底)
catch (...)
{
cout << "未知异常" << endl;
}
- 匹配规则:
catch按 “从上到下” 的顺序匹配异常类型,只有类型完全一致才会触发(如const char*不会匹配int类型异常); - 万能捕获:
catch(...)必须放在所有catch块的最后,用于捕获 “未被精准匹配” 的异常(如 Div 若抛出int类型异常,会被该块捕获),避免程序崩溃。
代码执行示例
- 正常输入:用户输入
10 2→Div(10,2)返回5.0→ 打印5→ 无异常,跳过所有catch; - 异常输入:用户输入
10 0→Div(10,0)抛出"除0错误"→ 异常传播到 main 的try块 → 匹配catch(const char*)→ 打印除0错误→ 程序继续执行; - 未知异常:若 Div 抛出
100(int 类型)→ 第一个catch不匹配 → 触发catch(...)→ 打印未知异常。
四、异常处理的核心特性
- 类型匹配优先:
catch块按 “从上到下” 匹配异常类型,精准类型匹配优先于catch(...); - 中断执行流程:
throw会立即中断当前函数的执行,不会执行throw后的代码; - 跨函数传播:异常可从嵌套调用的底层函数(如 Div)传播到上层调用函数(如 main),无需逐层返回错误码;
- 不污染返回值:异常是独立的错误传递通道,正常返回值无需承担 “错误码” 的职责(如 Div 的返回值仅用于正常结果)。
五、总结(关键点回顾)
- C++ 异常处理的核心是
try-throw-catch模型:try监控可能出错的代码,throw抛出异常,catch按类型捕获并处理; - 异常类型需严格匹配,
catch(...)是万能兜底捕获,避免程序崩溃; - 异常会中断当前函数执行并向上传播,直到被捕获,相比错误码更灵活、精准;
- 典型应用场景:处理运行时不可预知的错误(如除 0、文件操作失败、网络异常等)。
异常继承体系与多态
#include <iostream>
#include <string>
#include <ctime>
#include <windows.h> // Sleep函数头文件
using namespace std;
// -------------- 异常基类:所有自定义异常的父类 --------------
// 设计目的:统一异常类型,通过多态实现不同异常的差异化处理
class Exception
{
public:
// 构造函数:初始化异常信息和错误码
Exception(const string& errmsg, int id)
: _errmsg(errmsg) // 异常描述信息
, _id(id) // 错误码(区分不同错误类型)
{ }
// 虚函数what:返回异常详情(核心:为多态做准备)
// virtual关键字:允许派生类重写,实现“基类引用调用派生类函数”
virtual string what() const
{
return _errmsg;
}
protected:
string _errmsg; // 异常描述信息(protected:派生类可访问)
int _id; // 错误码
};
// -------------- 派生类:SQL相关异常 --------------
// 继承自Exception,扩展SQL专属的异常信息(SQL语句)
class SqlException : public Exception
{
public:
// 构造函数:调用基类构造,初始化SQL语句
SqlException(const string& errmsg, int id, const string& sql)
: Exception(errmsg, id)
, _sql(sql) // 出错的SQL语句
{ }
// 重写基类虚函数what:拼接SQL异常专属信息
virtual string what() const
{
string str = "SqlException: ";
str += _errmsg; // 基类的异常信息
str += " -> 执行SQL: ";
str += _sql; // 扩展的SQL语句信息
return str;
}
private:
const string _sql; // 出错的SQL语句(const:不可修改)
};
// -------------- 派生类:缓存相关异常 --------------
// 继承自Exception,仅复用基类字段(无扩展字段)
class CacheException : public Exception
{
public:
// 构造函数:直接调用基类构造
CacheException(const string& errmsg, int id)
: Exception(errmsg, id)
{ }
// 重写基类虚函数what:拼接缓存异常专属信息
virtual string what() const
{
string str = "CacheException: ";
str += _errmsg;
return str;
}
};
// -------------- 派生类:HTTP服务器相关异常 --------------
// 继承自Exception,扩展HTTP请求类型信息
class HttpServerException : public Exception
{
public:
// 构造函数:调用基类构造,初始化请求类型
HttpServerException(const string& errmsg, int id, const string& type)
: Exception(errmsg, id)
, _type(type) // HTTP请求类型(get/post等)
{ }
// 重写基类虚函数what:拼接HTTP异常专属信息
virtual string what() const
{
string str = "HttpServerException: ";
str += _type; // 请求类型
str += " -> ";
str += _errmsg; // 异常描述
return str;
}
private:
const string _type; // HTTP请求类型(get/post/put等)
};
// -------------- 业务函数:模拟SQL管理模块 --------------
// 随机抛出SqlException(概率1/7)
void SQLMgr()
{
// rand()%7==0:模拟随机触发异常(服务器运行中偶发错误)
if (rand() % 7 == 0)
{
// 抛出SqlException对象(派生类对象)
throw SqlException("权限不足", 100, "select * from user where name = '张三'");
}
}
// -------------- 业务函数:模拟缓存管理模块 --------------
// 随机抛出CacheException,内部调用SQLMgr(可能触发SqlException)
void CacheMgr()
{
// 模拟缓存异常场景1:权限不足(概率1/5)
if (rand() % 5 == 0)
{
throw CacheException("权限不足", 100);
}
// 模拟缓存异常场景2:数据不存在(概率1/6)
else if (rand() % 6 == 0)
{
throw CacheException("数据不存在", 101);
}
// 缓存无异常时,调用SQL模块(可能触发SQL异常)
SQLMgr();
}
// -------------- 业务函数:模拟HTTP服务器模块 --------------
// 随机抛出HttpServerException,内部调用CacheMgr(可能触发缓存/SQL异常)
void HttpServer()
{
// 模拟HTTP异常场景1:请求资源不存在(概率1/3)
if (rand() % 3 == 0)
{
throw HttpServerException("请求资源不存在", 100, "get");
}
// 模拟HTTP异常场景2:权限不足(概率1/4)
else if (rand() % 4 == 0)
{
throw HttpServerException("权限不足", 101, "post");
}
// HTTP无异常时,调用缓存模块(可能触发缓存/SQL异常)
CacheMgr();
}
int main()
{
// 死循环:模拟服务器持续运行
while (1)
{
// 设置随机数种子:基于当前时间,保证每次运行随机结果不同
srand((unsigned int)time(nullptr));
Sleep(500); // 休眠500ms,降低输出频率(模拟服务器间隔处理请求)
// ===================== 核心:多态捕获异常 =====================
try
{
// 调用HTTP服务器逻辑,可能抛出任意派生类异常
HttpServer();
}
// 捕获基类Exception的引用:核心利用多态!
// 无论抛出的是Sql/Cache/Http异常,都会匹配这个catch(派生类对象可赋值给基类引用)
catch (const Exception& e)
{
// 多态调用:e是基类引用,但实际调用的是对应派生类的what()
// 例如:抛出SqlException → 调用SqlException::what()
// 抛出CacheException → 调用CacheException::what()
cout << e.what() << endl;
}
// 万能捕获:处理未定义的异常(兜底,避免服务器崩溃)
catch (...)
{
cout << "Unkown Exception" << endl;
}
}
return 0;
}一、核心设计逻辑:异常类的多态体系
在大型程序(如服务器)中,不同模块(SQL、缓存、HTTP)会抛出不同类型的异常,若逐个捕获(catch(SqlException)、catch(CacheException)等)会导致代码冗余、扩展性差。因此通过继承 + 虚函数构建异常类的多态体系:
- 基类
Exception:定义统一的异常接口(虚函数what()),封装通用字段(异常信息、错误码); - 派生类(
SqlException/CacheException/HttpServerException):继承基类,重写what(),扩展模块专属字段(如 SQL 语句、HTTP 请求类型); - 核心目标:通过基类引用捕获所有派生类异常,利用多态调用对应派生类的
what(),实现 “一个 catch 处理所有异常 + 差异化信息输出”。
二、多态的基础:异常类的继承与虚函数重写
1. 基类Exception:统一异常接口
class Exception
{
public:
Exception(const string& errmsg, int id)
: _errmsg(errmsg), _id(id) { }
// 核心:虚函数what(),为多态提供统一接口
virtual string what() const
{
return _errmsg;
}
protected:
string _errmsg; // 通用异常信息
int _id; // 通用错误码
};
virtual关键字:标记what()为虚函数,允许派生类重写;protected成员:保证派生类可访问通用字段,同时对外隐藏。
2. 派生类:重写虚函数,扩展模块专属逻辑
以SqlException为例(其他派生类逻辑一致):
class SqlException : public Exception
{
public:
// 构造函数:调用基类构造,初始化专属字段_sql
SqlException(const string& errmsg, int id, const string& sql)
: Exception(errmsg, id), _sql(sql) { }
// 重写基类虚函数:拼接SQL模块专属异常信息
virtual string what() const
{
string str = "SqlException: ";
str += _errmsg; // 复用基类通用信息
str += " -> 执行SQL: ";
str += _sql; // 扩展专属信息
return str;
}
private:
const string _sql; // SQL模块专属字段:出错的SQL语句
};
- 重写规则:
what()的返回值、参数、const属性需与基类完全一致; - 差异化实现:不同派生类的
what()拼接不同模块的专属信息(如HttpServerException拼接请求类型,CacheException仅拼接模块名)。
三、多态与异常捕获的配合核心:基类引用捕获
1. 核心语法:catch(const Exception& e)
try
{
HttpServer(); // 可能抛出Sql/Cache/Http任意派生类异常
}
// 捕获基类Exception的引用:匹配所有派生类异常(多态的关键)
catch (const Exception& e)
{
// 多态调用:e是基类引用,但实际调用派生类的what()
cout << e.what() << endl;
}
catch (...) // 兜底捕获
{
cout << "Unkown Exception" << endl;
}
- 匹配规则:C++ 异常捕获支持 “派生类对象赋值给基类引用”(向上转型),因此
catch(const Exception&)能捕获所有Exception的派生类异常; - 多态调用:
e.what()的调用结果由实际抛出的异常类型决定(而非引用类型),实现 “一个 catch 处理所有异常 + 差异化输出”。
2. 避免 “切片问题”:必须用引用 / 指针捕获
若改为catch(const Exception e)(值捕获),会触发 “对象切片”:
- 派生类对象赋值给基类对象时,仅保留基类部分,派生类专属字段(如
_sql)会被截断; e.what()会调用基类的what(),而非派生类重写的版本,失去多态效果。因此捕获多态异常必须用引用(&)或指针(*),保证派生类信息完整。
四、完整执行流程(以抛出SqlException为例)
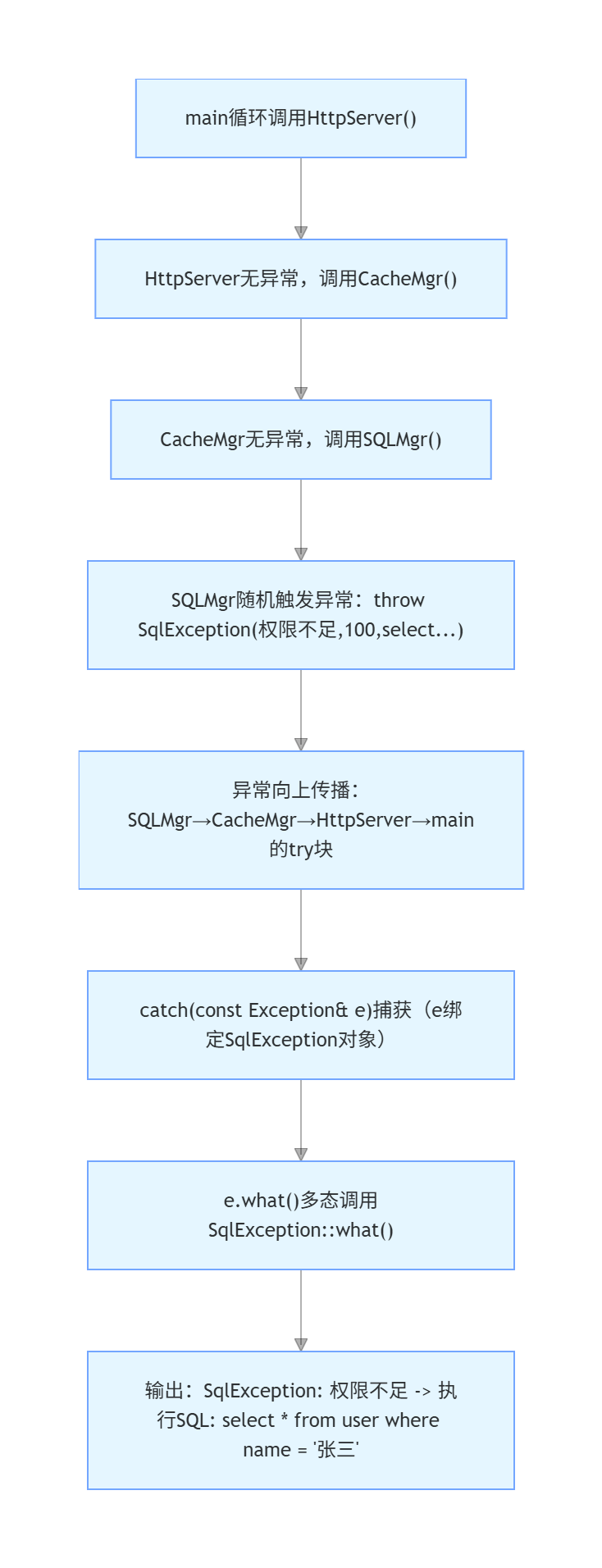
不同异常的差异化处理示例
- 抛出
CacheException:e.what()调用CacheException::what()→ 输出CacheException: 数据不存在; - 抛出
HttpServerException:e.what()调用HttpServerException::what()→ 输出HttpServerException: get -> 请求资源不存在; - 核心:无论抛出哪种派生类异常,
catch块无需修改,仅通过多态自动适配。
五、多态捕获异常的核心优势
| 维度 | 无多态(逐个捕获派生类) | 多态(基类引用捕获) |
|---|---|---|
| 代码量 | 需写多个 catch 块(catch(SqlException)、catch(CacheException)等) |
仅需 1 个 catch 块,处理所有派生类异常 |
| 扩展性 | 新增异常类需新增 catch 块,修改代码量大 | 新增异常类仅需继承基类并重写 what (),无需修改 catch |
| 维护性 | catch 块分散,逻辑不统一 | 统一异常处理入口,便于添加通用逻辑(如日志) |
| 信息完整性 | 需逐个处理派生类专属字段 | 多态调用 what (),自动输出专属信息 |
六、总结(关键点回顾)
- 异常类多态体系设计:基类定义虚函数 what (),派生类重写该函数实现模块专属异常信息;
- 捕获核心:用基类引用(const Exception&) 捕获异常,避免切片问题,保证多态调用;
- 核心优势:一个 catch 块处理所有派生类异常,代码简洁、扩展性强,是大型程序异常处理的标准方案;
- 兜底机制:保留
catch(...),处理未纳入多态体系的未知异常,避免程序崩溃。
重新抛异常
#include <iostream>
using namespace std;
// 除法函数:除数为0时抛出const char*类型异常
double Div(int x, int y)
{
if (y == 0)
throw "除0错误"; // 抛出异常,中断当前函数执行
else
return (double)x / (double)y;
}
void Func()
{
// 【异常安全问题核心】:动态分配内存(new),若后续抛异常,直接跳走会导致delete未执行,内存泄漏
int* parray = new int[10]; // 分配10个int的堆内存,需手动delete释放
// -------------- 方法1:捕获指定类型异常后,重新抛出具体异常值 --------------
try
{
int a = 0, b = 0;
cin >> a >> b;
cout << Div(a, b) << endl; // 此处可能抛出"除0错误"异常
}
catch (const char* str) // 精准捕获const char*类型异常
{
// 第一步:先释放堆内存(解决异常安全问题,避免内存泄漏)
cout << "delete [] " << parray << endl;
delete[] parray;
// 第二步:异常重新抛出(将捕获的异常值抛给上层处理)
// 注意:throw str 是抛出“当前捕获的异常值副本”,类型仍为const char*
throw str;
}
// -------------- 方法2:捕获所有异常后,重新抛出(推荐) --------------
/*
try
{
int a = 0, b = 0;
cin >> a >> b;
cout << Div(a, b) << endl;
}
catch (...) // 万能捕获:捕获所有类型的异常
{
// 第一步:释放堆内存(核心:异常安全,避免内存泄漏)
cout << "delete [] " << parray << endl;
delete[] parray;
// 第二步:异常重新抛出(throw; 不带参数)
// 关键:throw; 会原样抛出“捕获到的原始异常”,保留异常类型和信息,推荐使用
throw;
}
*/
// 若没有异常发生,正常释放堆内存
cout << "delete [] " << parray << endl;
delete[] parray;
}
int main()
{
// 上层捕获:处理Func重新抛出的异常
try
{
Func(); // 调用Func,可能接收其重新抛出的异常
}
catch (const char* str) // 处理“除0错误”异常
{
cout << str << endl; // 打印异常信息
}
catch (...) // 兜底处理未知异常
{
cout << "未知异常" << endl;
}
return 0;
}一、异常重新抛出的核心定义
异常重新抛出是 C++ 异常处理中局部清理 + 上层统一处理的核心机制:在catch块中捕获异常后,先完成局部资源的清理(如释放堆内存、关闭文件),再通过throw将异常传递给上层调用者处理。其核心目的是解决 “局部资源泄漏” 和 “异常集中处理” 的双重问题 —— 既保证异常发生时局部资源不泄漏,又让上层代码统一处理异常逻辑(如打印日志、告警)。
二、异常重新抛出的背景:解决 “异常安全问题”
代码中Func函数的核心风险是异常导致的资源泄漏:
int* parray = new int[10]; // 堆内存分配,需手动delete释放
// 若后续Div抛出异常,会直接跳转到上层catch块,下方的delete不会执行
cout << Div(a, b) << endl; // 可能抛出异常,中断执行流程
// 无异常时才会执行的释放逻辑
delete[] parray;
- 正常流程:无异常时,
delete[] parray执行,内存正常释放; - 异常流程:Div 抛出异常→跳过
delete[] parray→parray指向的堆内存无法释放→内存泄漏。
异常重新抛出的核心价值:在catch块中先释放资源,再将异常抛给上层,既解决内存泄漏,又不丢失异常信息。
三、两种异常重新抛出的方式(代码拆解)
方式 1:捕获指定类型异常后,抛出具体异常值
try
{
int a = 0, b = 0;
cin >> a >> b;
cout << Div(a, b) << endl; // 可能抛出const char*类型异常
}
catch (const char* str) // 精准捕获const char*类型异常
{
// 第一步:局部清理资源(核心:避免内存泄漏)
cout << "delete [] " << parray << endl;
delete[] parray;
// 第二步:重新抛出具体异常值(str的副本)
throw str; // 抛出const char*类型的"除0错误",传递给上层
}
- 执行逻辑:
- 捕获
Div抛出的const char*类型异常; - 释放
parray指向的堆内存(解决泄漏); - 通过
throw str将异常值("除 0 错误")重新抛出,上层main的catch(const char*)捕获并处理。
- 捕获
- 局限性:仅能处理
const char*类型异常,若 Div 抛出其他类型异常(如int),会绕过该catch块→资源无法释放→仍会泄漏。
方式 2:万能捕获后,throw;原样抛出原始异常(推荐)
try
{
int a = 0, b = 0;
cin >> a >> b;
cout << Div(a, b) << endl;
}
catch (...) // 万能捕获:匹配所有类型异常
{
// 第一步:局部清理资源(核心:无论何种异常,都保证释放)
cout << "delete [] " << parray << endl;
delete[] parray;
// 第二步:原样抛出原始异常(关键:throw; 不带参数)
throw; // 保留异常的原始类型和信息,传递给上层
}
- 核心语法:
throw;(无参数)—— 重新抛出 “当前catch块捕获到的原始异常”,不会改变异常的类型、内容,仅将异常传递给上层。 - 执行逻辑:
- 捕获所有类型的异常(包括
const char*、int、自定义类等); - 释放
parray内存(无论何种异常,资源都能释放); - 通过
throw;将原始异常原样抛给上层,上层catch按类型匹配处理(如const char*类型仍匹配catch(const char*))。
- 捕获所有类型的异常(包括
- 优势:覆盖所有异常类型,保证资源 100% 释放,是异常重新抛出的 “最佳实践”。
四、throw; vs throw 具体值的核心区别
| 语法形式 | 异常来源 | 异常类型 / 信息 | 适用场景 |
|---|---|---|---|
throw; |
当前 catch 捕获的原始异常 | 完全保留原始类型、信息 | 万能捕获(catch (...))后重新抛出(推荐) |
throw 具体值 |
新创建的异常(副本) | 与具体值类型一致(可能丢失原始信息) | 精准捕获指定类型后,需修改异常信息时 |
关键注意点:
throw;仅在catch块内有效,若在非catch块中使用,会调用terminate()终止程序;throw str本质是 “抛出新异常”(str 的副本),若原始异常是多态类型(如自定义异常类),会丢失派生类信息(切片问题),而throw;能完整保留多态特性。
五、完整执行流程(以方式 2 为例)
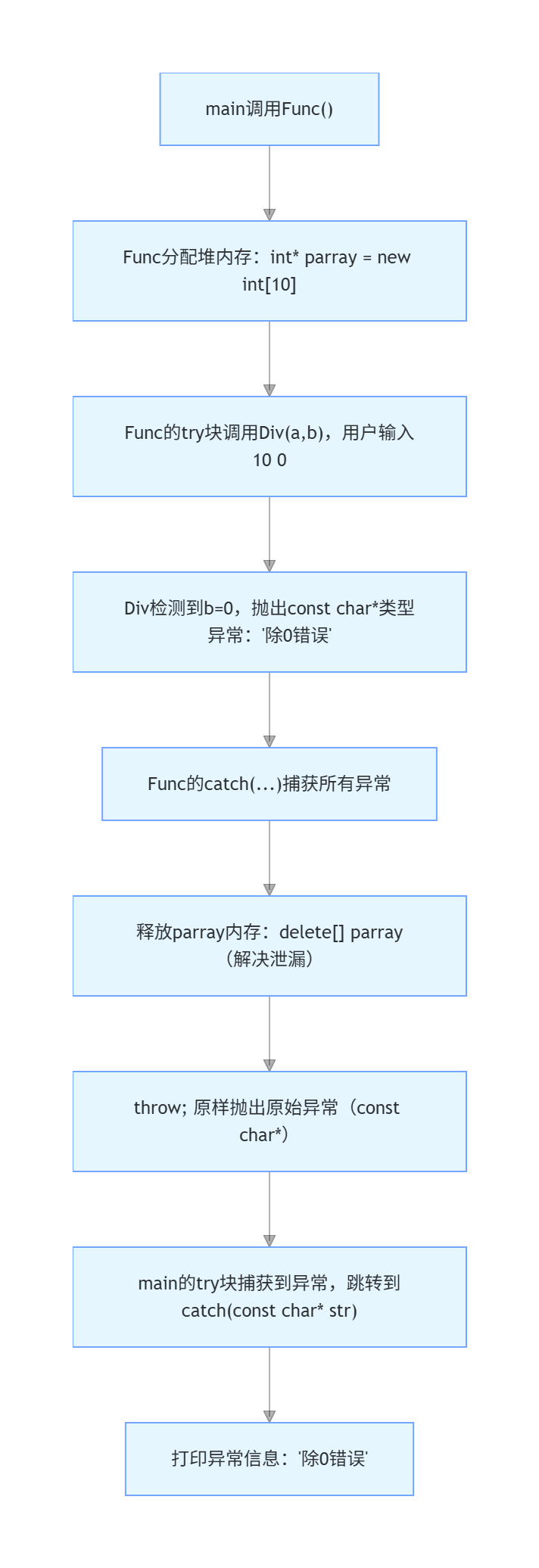
六、总结(关键点回顾)
- 异常重新抛出的核心目的:局部清理资源(避免泄漏)+ 上层统一处理异常,是解决 “异常安全问题” 的核心手段;
- 两种重新抛出方式:
- 精准捕获 +
throw 具体值:仅处理指定类型,有资源泄漏风险; - 万能捕获 +
throw;:处理所有类型,保留原始异常信息,是推荐方案;
- 精准捕获 +
throw;是异常重新抛出的最佳实践:原样保留异常的类型和信息,且仅在catch块内有效;- 核心原则:清理资源在前,重新抛出在后,确保异常发生时局部资源不泄漏。
RAII与智能指针
#include <iostream>
#include <string>
#include <functional> // function包装器头文件
#include <cstdio> // fopen/fclose头文件
using namespace std;
namespace obj
{
// -------------- 模拟实现shared_ptr(智能指针) --------------
// 核心:基于引用计数的智能指针,自动管理堆内存,避免内存泄漏
// 模板参数T:指向的对象类型
template<class T>
class shared_ptr
{
public:
// ==================== 1. 默认构造函数 ====================
// 参数:裸指针,默认值nullptr
// 核心:初始化指针+引用计数(新对象引用计数初始化为1)
shared_ptr(T* ptr = nullptr)
: _ptr(ptr) // 指向堆内存的裸指针
, _pcount(new int(1)) // 引用计数(动态分配,多个shared_ptr共享)
{ }
// ==================== 2. 定制删除器构造函数 ====================
// 模板参数D:删除器类型(支持仿函数/Lambda/普通函数)
// 参数:裸指针 + 定制删除器(解决默认delete不适用数组/文件句柄等场景)
template<class D>
shared_ptr(T* ptr, D del)
: _ptr(ptr)
, _pcount(new int(1))
, _del(del) // 替换默认删除器为用户自定义的删除逻辑
{ }
// ==================== 3. 拷贝构造函数(核心:引用计数+1) ====================
// 作用:多个shared_ptr指向同一资源,引用计数共享且递增
shared_ptr(const shared_ptr<T>& sp)
: _ptr(sp._ptr) // 共享同一裸指针
, _pcount(sp._pcount) // 共享同一引用计数
{
++(*_pcount); // 引用计数+1(表示多一个指针指向该资源)
}
// ==================== 4. 赋值重载函数(核心:先减后加) ====================
// 作用:让当前shared_ptr指向新资源,同时处理旧资源的引用计数
shared_ptr<T>& operator=(const shared_ptr<T>& sp)
{
// 防止自赋值(自己赋值给自己,无需处理)
if (_ptr != sp._ptr)
{
// 第一步:处理当前指向的旧资源
// 引用计数-1,若减到0,说明无指针指向该资源,释放资源+引用计数
if (--(*_pcount) == 0)
{
delete _ptr; // 释放旧资源
delete _pcount; // 释放引用计数的堆内存
}
// 第二步:共享新资源
_ptr = sp._ptr; // 指向新资源的裸指针
_pcount = sp._pcount; // 共享新资源的引用计数
++(*_pcount); // 新资源的引用计数+1
}
return *this; // 返回自身,支持连续赋值
}
// ==================== 5. 重载*运算符(模仿裸指针解引用) ====================
T& operator*()
{
return *_ptr; // 解引用裸指针,返回对象引用
}
// ==================== 6. 重载->运算符(模仿裸指针访问成员) ====================
T* operator->()
{
return _ptr; // 返回裸指针,支持sp->成员 的写法
}
// ==================== 7. 获取引用计数 ====================
// 作用:查看当前有多少个shared_ptr指向该资源
int use_count() const
{
return (*_pcount);
}
// ==================== 8. 获取裸指针 ====================
// 作用:兼容需要裸指针的场景(谨慎使用)
T* Get() const
{
return _ptr;
}
// ==================== 9. 析构函数(核心:引用计数-1,为0则释放资源) ====================
~shared_ptr()
{
// 引用计数-1,若减到0,说明最后一个指向该资源的指针被销毁
if (--(*_pcount) == 0)
{
_del(_ptr); // 调用删除器释放资源(默认delete,或用户定制逻辑)
delete _pcount; // 释放引用计数的堆内存
}
}
private:
T* _ptr; // 指向堆资源的裸指针
int* _pcount; // 引用计数(动态分配,多个对象共享)
// 定制删除器:默认用delete释放资源,支持用户自定义(数组/文件句柄等)
function<void(T*)> _del = [](T* ptr) {delete ptr; };
};
}
// -------------- 自定义删除器(仿函数):用于释放数组 --------------
// 解决默认delete不能释放数组的问题(数组需用delete[])
template<class T>
struct DelArray
{
void operator()(T* ptr)
{
delete[] ptr; // 数组专属释放逻辑
}
};
// -------------- 测试函数:验证shared_ptr和定制删除器 --------------
void test1()
{
// 场景1:用仿函数作为定制删除器,释放string数组
obj::shared_ptr<string> sp1(new string[10], DelArray<string>());
// 场景2:用Lambda作为定制删除器,释放string数组(更简洁)
obj::shared_ptr<string> sp2(new string[10], [](string* ptr) {delete[] ptr; });
// 场景3:用Lambda作为定制删除器,释放文件句柄(非内存资源)
obj::shared_ptr<FILE> sp3(fopen("test.cpp", "r"), [](FILE* ptr) {fclose(ptr); });
// 场景4:默认删除器(delete),释放单个string对象
obj::shared_ptr<string> sp4(new string);
}
int main()
{
test1(); // 函数结束后,所有shared_ptr析构,自动释放资源
return 0;
}一、RAII 核心思想:资源获取即初始化
RAII(Resource Acquisition Is Initialization)是 C++ 特有的资源管理范式,核心逻辑是 “利用对象的生命周期管理资源”—— 将资源(堆内存、文件句柄、网络连接、锁等)的获取绑定到对象的构造函数,资源的释放绑定到对象的析构函数。
1. RAII 的核心步骤
| 阶段 | 操作 | 核心目的 |
|---|---|---|
| 构造函数 | 获取资源(new / 打开文件等) | 资源与对象绑定,对象创建时必获取资源,避免 “漏获取” |
| 析构函数 | 释放资源(delete / 关闭文件等) | 对象销毁时(离开作用域 / 析构调用)自动释放资源,避免 “漏释放” 导致的泄漏 |
2. RAII 的核心优势
- 自动性:无需手动调用释放函数(如
delete/fclose),对象生命周期结束时析构函数自动执行; - 异常安全:即使程序抛出异常,栈上对象仍会被正常析构,资源不会泄漏(解决 “异常跳过手动释放” 的问题);
- 简洁性:将资源管理逻辑封装到类中,业务代码无需关注资源释放细节。
3. RAII 与 shared_ptr 的关联
shared_ptr是 RAII 思想的典型实现:将 “堆内存资源” 的获取(new)绑定到shared_ptr的构造函数,资源的释放(delete/ 定制逻辑)绑定到析构函数,通过引用计数实现 “多对象共享资源,最后一个对象析构时释放资源”。
二、shared_ptr 的核心设计逻辑
模拟实现的shared_ptr是基于引用计数的智能指针,核心目标是:多个shared_ptr对象共享同一堆资源,仅当最后一个指向该资源的shared_ptr被销毁时,才释放资源(避免重复释放 / 内存泄漏)。
1. 核心成员变量(RAII 的载体)
private:
T* _ptr; // 指向堆资源的裸指针(管理的核心资源)
int* _pcount; // 引用计数(动态分配,多个shared_ptr共享)
function<void(T*)> _del = [](T* ptr) {delete ptr; }; // 定制删除器
_ptr:RAII 管理的核心资源(堆内存 / 文件句柄等),构造时绑定,析构时释放;_pcount:引用计数(动态分配的int指针),多个shared_ptr共享同一计数,用于记录 “当前有多少个shared_ptr指向该资源”;_del:定制删除器(function包装器),默认用delete释放资源,支持用户自定义释放逻辑(如数组的delete[]、文件的fclose)。
2. 核心成员函数实现(RAII + 引用计数)
(1)构造函数:获取资源,初始化引用计数
// 默认构造:管理单个对象(默认删除器delete)
shared_ptr(T* ptr = nullptr)
: _ptr(ptr) // 绑定堆资源(获取资源)
, _pcount(new int(1)) // 新资源的引用计数初始化为1
{ }
// 定制删除器构造:支持数组/文件句柄等特殊资源
template<class D>
shared_ptr(T* ptr, D del)
: _ptr(ptr)
, _pcount(new int(1))
, _del(del) // 替换默认删除器,适配特殊资源释放
{ }
- 核心:构造函数接收裸指针(资源),完成 “资源获取”,同时初始化引用计数(新资源只有 1 个
shared_ptr指向它); - 定制删除器:解决默认
delete的局限性(如数组需delete[]、文件句柄需fclose)。
(2)拷贝构造函数:共享资源,引用计数 + 1
shared_ptr(const shared_ptr<T>& sp)
: _ptr(sp._ptr) // 共享同一堆资源
, _pcount(sp._pcount) // 共享同一引用计数
{
++(*_pcount); // 引用计数+1(多一个指针指向该资源)
}
- 核心逻辑:多个
shared_ptr指向同一资源时,不重新分配资源,仅共享_ptr和_pcount,并将计数 + 1; - 示例:
shared_ptr<string> sp5 = sp4;→sp5和sp4共享同一string对象,引用计数从 1 变为 2。
(3)赋值重载函数:切换资源,先减后加
shared_ptr<T>& operator=(const shared_ptr<T>& sp)
{
if (_ptr != sp._ptr) // 防止自赋值
{
// 第一步:处理旧资源(RAII释放)
if (--(*_pcount) == 0) // 旧资源引用计数-1
{
_del(_ptr); // 旧资源无指针指向,释放资源
delete _pcount; // 释放引用计数内存
}
// 第二步:共享新资源
_ptr = sp._ptr; // 绑定新资源
_pcount = sp._pcount; // 共享新资源的计数
++(*_pcount); // 新资源计数+1
}
return *this;
}
- 核心逻辑:赋值时先释放 “当前对象指向的旧资源”(计数 - 1,为 0 则释放),再共享 “新对象的资源”(计数 + 1);
- 异常安全:先处理旧资源再绑定新资源,避免赋值过程中异常导致资源泄漏。
(4)析构函数:释放资源(RAII 核心)
~shared_ptr()
{
if (--(*_pcount) == 0) // 引用计数-1,判断是否为最后一个指针
{
_del(_ptr); // 调用删除器释放资源(RAII释放)
delete _pcount; // 释放引用计数内存
}
}
- 核心逻辑:
- 析构时引用计数 - 1;
- 若计数减到 0,说明当前是最后一个指向该资源的指针,调用删除器释放资源 + 引用计数内存;
- 若计数 > 0,说明还有其他指针指向该资源,仅减少计数,不释放资源(避免提前释放)。
(5)重载 * 和 ->:模仿裸指针使用
T& operator*() { return *_ptr; } // 解引用:*sp 等价于 *裸指针
T* operator->() { return _ptr; } // 访问成员:sp->成员 等价于 裸指针->成员
- 核心目的:让
shared_ptr的使用方式和裸指针一致,降低学习成本(如shared_ptr<string> sp(new string("test")); cout << *sp;)。
(6)辅助函数:获取计数 / 裸指针
int use_count() const { return (*_pcount); } // 查看当前引用计数
T* Get() const { return _ptr; } // 兼容需要裸指针的场景(谨慎使用)
3. 定制删除器:解决默认释放的局限性
默认删除器是[](T* ptr) {delete ptr;},仅适用于单个对象的释放,无法处理数组(需delete[])、文件句柄(需fclose)等场景,因此设计 “定制删除器”:
场景 1:释放数组(仿函数删除器)
// 仿函数:数组专属释放逻辑(delete[])
template<class T>
struct DelArray
{
void operator()(T* ptr) { delete[] ptr; }
};
// 使用:管理string数组,用DelArray作为删除器
obj::shared_ptr<string> sp1(new string[10], DelArray<string>());
场景 2:释放数组(Lambda 删除器,更简洁)
// Lambda作为删除器,替代仿函数
obj::shared_ptr<string> sp2(new string[10], [](string* ptr) {delete[] ptr; });
场景 3:释放非内存资源(文件句柄)
// Lambda作为删除器,释放文件句柄(fclose)
obj::shared_ptr<FILE> sp3(fopen("test.cpp", "r"), [](FILE* ptr) {fclose(ptr); });
- 核心:
function<void(T*)>包装器统一了不同类型的删除逻辑(仿函数、Lambda、普通函数),让shared_ptr能管理任意类型的资源。
三、test1 函数的执行流程(RAII 自动释放验证)
void test1()
{
obj::shared_ptr<string> sp1(new string[10], DelArray<string>()); // 构造:绑定数组资源,计数1
obj::shared_ptr<string> sp2(new string[10], [](string* ptr) {delete[] ptr; }); // 构造:绑定数组资源,计数1
obj::shared_ptr<FILE> sp3(fopen("test.cpp", "r"), [](FILE* ptr) {fclose(ptr); }); // 构造:绑定文件资源,计数1
obj::shared_ptr<string> sp4(new string); // 构造:绑定单个string,计数1
} // 函数结束,所有sp1-sp4析构
sp1析构:计数 - 1→0 → 调用DelArray删除器,delete[]释放 string 数组;sp2析构:计数 - 1→0 → 调用 Lambda 删除器,delete[]释放 string 数组;sp3析构:计数 - 1→0 → 调用 Lambda 删除器,fclose关闭文件句柄;sp4析构:计数 - 1→0 → 调用默认删除器,delete释放单个 string;- 核心:所有资源均由析构函数自动释放,无需手动调用
delete[]/fclose,完全符合 RAII 思想。
四、总结(关键点回顾)
- RAII 核心:对象构造获取资源,析构释放资源,利用生命周期自动管理,解决资源泄漏和异常安全问题;
- shared_ptr 核心:
- 基于 RAII + 引用计数,多个对象共享资源,计数为 0 时释放;
_pcount动态分配,保证多个shared_ptr共享同一计数;- 定制删除器通过
function包装,适配数组、文件句柄等特殊资源释放;
- 核心函数逻辑:
- 拷贝构造 / 赋值:共享资源,计数 + 1;
- 析构:计数 - 1,为 0 则调用删除器释放资源;
- 赋值重载:先释放旧资源,再绑定新资源,防止自赋值。
shared_ptr的循环引用问题
// -------------- 双向链表节点结构体 --------------
struct ListNode
{
// 默认构造函数:初始化值和指针
ListNode()
: _val(0)
, _prev(nullptr) // 前驱指针(shared_ptr类型)
, _next(nullptr) // 后继指针(shared_ptr类型)
{
}
// 析构函数:用于验证是否释放(若打印则说明析构,未打印则内存泄漏)
~ListNode()
{
cout << "~ListNode()" << endl;
}
int _val; // 节点值
// 核心问题点:用shared_ptr管理前驱/后继指针,易形成循环引用
obj::shared_ptr<ListNode> _prev;
obj::shared_ptr<ListNode> _next;
};
// -------------- 测试函数:演示shared_ptr循环引用导致内存泄漏 --------------
void test()
{
// 步骤1:创建两个shared_ptr,分别指向两个ListNode堆对象
// n1管理第一个ListNode:引用计数=1(仅n1指向它)
obj::shared_ptr<ListNode> n1(new ListNode);
// n2管理第二个ListNode:引用计数=1(仅n2指向它)
obj::shared_ptr<ListNode> n2(new ListNode);
// 步骤2:建立双向引用,形成循环引用
// n1->_next = n2:第二个ListNode的引用计数+1 → 引用计数=2(n2 + n1->_next)
n1->_next = n2;
// n2->_prev = n1:第一个ListNode的引用计数+1 → 引用计数=2(n1 + n2->_prev)
n2->_prev = n1;
// 此时引用关系:
// n1 → 第一个ListNode ← n2->_prev
// n2 → 第二个ListNode ← n1->_next
// 两个ListNode互相持有对方的shared_ptr,形成“循环引用”
}
int main()
{
test(); // 调用test函数,函数执行完毕后n1/n2出作用域
// 预期:test结束后,两个ListNode应析构(打印两次~ListNode())
// 实际:无打印,说明ListNode未析构,内存泄漏
return 0;
}一、shared_ptr 循环引用的核心定义
循环引用是shared_ptr最典型的内存泄漏场景:两个(或多个)被shared_ptr管理的对象,互相持有对方的shared_ptr指针,形成 “闭环” 引用关系。最终每个对象的引用计数始终无法减到 0,析构函数无法触发,堆内存无法释放,导致内存泄漏。
二、循环引用的形成过程(结合代码逐步拆解)
1. 核心前提:节点的指针类型是shared_ptr
双向链表节点的_prev(前驱)和_next(后继)均为obj::shared_ptr<ListNode>类型,而非裸指针 —— 这是循环引用的 “基础条件”:
struct ListNode
{
int _val;
obj::shared_ptr<ListNode> _prev; // 用shared_ptr持有前驱节点
obj::shared_ptr<ListNode> _next; // 用shared_ptr持有后继节点
~ListNode() { cout << "~ListNode()" << endl; } // 析构验证
};
- 若
_prev/_next是裸指针(ListNode*),则不会触发引用计数变化,也就不会形成循环引用; - 正因为是
shared_ptr,赋值时会触发引用计数 + 1,才会导致闭环。
2. test 函数中引用计数的变化(核心步骤)
void test()
{
// 步骤1:创建两个shared_ptr,管理两个独立的ListNode
obj::shared_ptr<ListNode> n1(new ListNode); // 节点1:引用计数=1(仅n1持有)
obj::shared_ptr<ListNode> n2(new ListNode); // 节点2:引用计数=1(仅n2持有)
// 步骤2:建立双向引用,触发引用计数+1,形成闭环
n1->_next = n2; // 节点1的_next持有节点2的shared_ptr → 节点2计数+1 → 节点2计数=2
n2->_prev = n1; // 节点2的_prev持有节点1的shared_ptr → 节点1计数+1 → 节点1计数=2
// 此时引用关系(闭环):
// n1 → 节点1(计数2) ← 节点2的_prev
// n2 → 节点2(计数2) ← 节点1的_next
}
- 节点 1 的引用计数 = 2:外部
n1持有 + 节点 2 的_prev持有; - 节点 2 的引用计数 = 2:外部
n2持有 + 节点 1 的_next持有; - 核心:两个节点通过
shared_ptr互相持有,形成 “你中有我、我中有你” 的闭环。
3. test 函数结束:n1/n2 析构,但引用计数无法归 0
test 函数执行完毕后,局部变量n1和n2出作用域,触发析构:
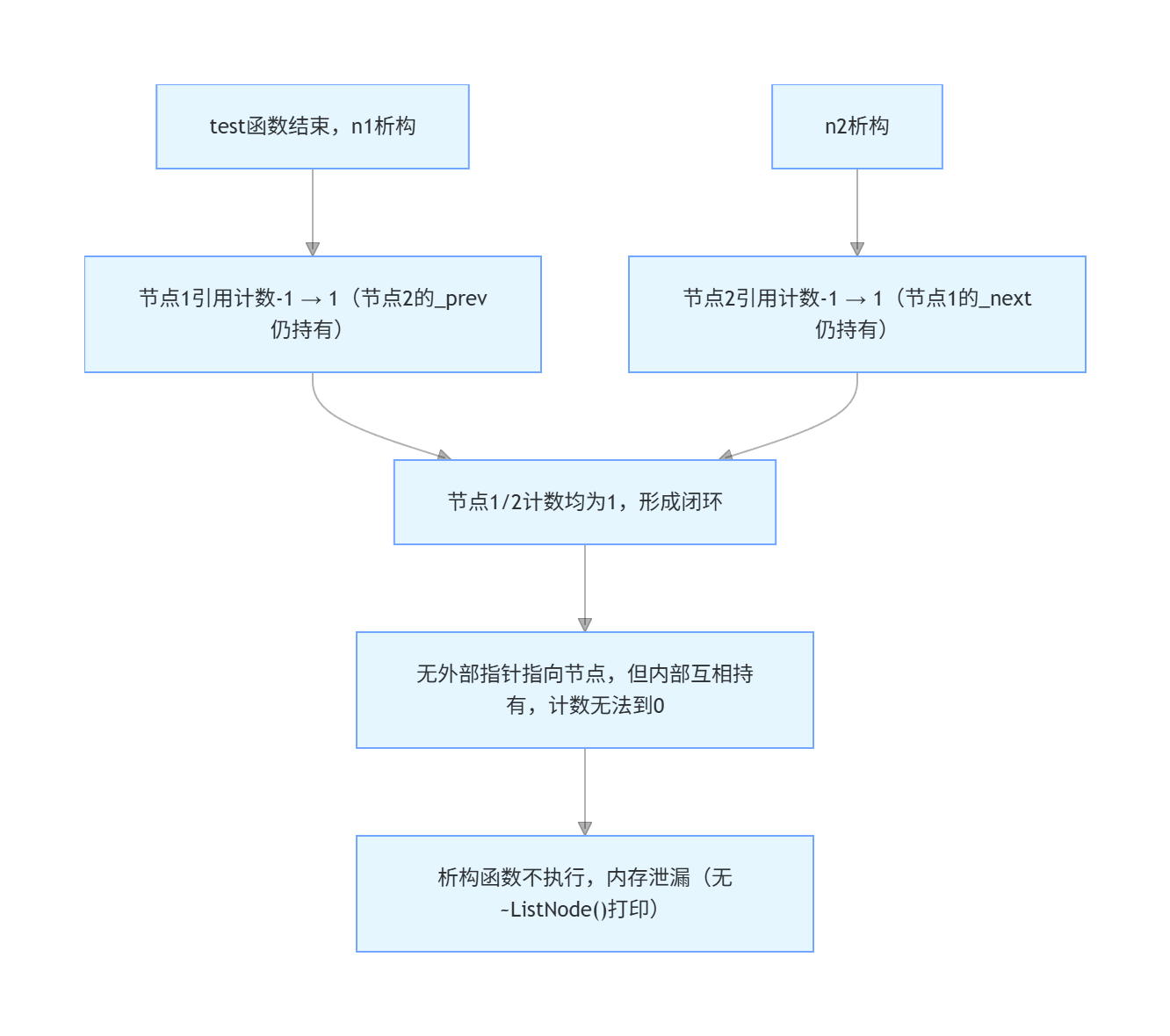
n1析构:节点 1 的引用计数从 2→1(节点 2 的_prev仍持有节点 1,计数无法到 0);n2析构:节点 2 的引用计数从 2→1(节点 1 的_next仍持有节点 2,计数无法到 0);- 最终状态:两个节点的引用计数都是 1,且互相持有对方的
shared_ptr—— 没有任何外部shared_ptr指向它们,但内部闭环导致计数永远无法减到 0,析构函数无法触发,堆内存永久泄漏。
三、循环引用导致内存泄漏的本质
shared_ptr的核心释放逻辑是:仅当引用计数减到 0 时,才调用删除器释放资源(执行析构函数)。
循环引用的本质是:
- 对象之间通过
shared_ptr互相持有,形成 “内部闭环”; - 外部所有
shared_ptr(如 n1/n2)析构后,内部持有的shared_ptr仍让每个对象的计数≥1; - 计数无法归 0 → 析构函数不执行 → 堆内存无法释放 → 内存泄漏。
四、关键对比:裸指针 vs shared_ptr(为什么裸指针不会泄漏)
若将节点的_prev/_next改为裸指针:
struct ListNode
{
int _val;
ListNode* _prev; // 裸指针
ListNode* _next; // 裸指针
~ListNode() { cout << "~ListNode()" << endl; }
};
- test 函数中
n1->_next = n2.Get();(获取裸指针),不会触发引用计数变化; - n1/n2 析构时,节点 1/2 的计数从 1→0,析构函数正常执行(打印两次
~ListNode()),无内存泄漏。
五、总结(关键点回顾)
- 循环引用的前提:对象互相持有对方的 shared_ptr(而非裸指针),赋值时触发引用计数 + 1;
- 核心原因:外部
shared_ptr析构后,内部闭环让每个对象的引用计数≥1,无法触发析构; - 泄漏本质:
shared_ptr的释放逻辑依赖 “计数归 0”,循环引用打破了这一条件,导致堆内存永久无法释放;
weak_ptr解决shared_ptr的循环引用问题
#include <iostream>
#include <functional> // shared_ptr中function包装器所需头文件
using namespace std;
namespace obj
{
// -------------- 模拟实现weak_ptr(弱引用智能指针) --------------
// 核心:弱引用,不管理引用计数,仅作为“观察者”,解决shared_ptr循环引用问题
template<class T>
class weak_ptr
{
public:
// ==================== 1. 默认构造函数 ====================
// 初始化裸指针为nullptr,无引用计数管理
weak_ptr()
: _ptr(nullptr)
{ }
// ==================== 2. 构造函数(从shared_ptr构造) ====================
// 核心:仅拷贝shared_ptr的裸指针,**不增加引用计数**!
// 区别于shared_ptr拷贝构造(会+1),weak_ptr只是“观察”shared_ptr管理的资源
weak_ptr(const shared_ptr<T>& sp)
: _ptr(sp.Get()) // 调用shared_ptr的Get()获取裸指针
{ }
// ==================== 3. 赋值重载函数(从shared_ptr赋值) ====================
// 核心:仅赋值裸指针,**不修改引用计数**!
weak_ptr<T>& operator=(const shared_ptr<T>& sp)
{
_ptr = sp.Get(); // 只拿裸指针,不影响引用计数
return *this;
}
// ==================== 4. 重载*和->(模仿指针行为) ====================
// 仅提供访问接口,无计数管理
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr; // 仅持有裸指针,无引用计数成员(核心!)
};
}
// -------------- 双向链表节点结构体 --------------
struct ListNode
{
// 默认构造:初始化值和弱引用指针
ListNode()
: _val(0)
, _prev(nullptr) // 改为weak_ptr:前驱弱引用
, _next(nullptr) // 改为weak_ptr:后继弱引用
{ }
// 析构函数:验证是否释放(打印则说明成功析构,无内存泄漏)
~ListNode()
{
cout << "~ListNode()" << endl;
}
int _val;
// 核心修改:将互相引用的指针改为weak_ptr(弱引用),不增加引用计数
obj::weak_ptr<ListNode> _prev;
obj::weak_ptr<ListNode> _next;
};
// -------------- 测试函数:验证weak_ptr解决循环引用 --------------
void test()
{
// 步骤1:创建两个shared_ptr,管理两个ListNode堆对象
// n1管理第一个节点:引用计数=1(仅n1指向,weak_ptr不计数)
obj::shared_ptr<ListNode> n1(new ListNode);
// n2管理第二个节点:引用计数=1(仅n2指向,weak_ptr不计数)
obj::shared_ptr<ListNode> n2(new ListNode);
// 步骤2:建立双向引用(用weak_ptr)
// n1->_next = n2:weak_ptr仅拷贝n2的裸指针,**n2的引用计数仍为1**(不+1)
n1->_next = n2;
// n2->_prev = n1:weak_ptr仅拷贝n1的裸指针,**n1的引用计数仍为1**(不+1)
n2->_prev = n1;
// 此时引用关系:
// n1 → 第一个节点(计数=1) ← n2->_prev(weak_ptr,不计数)
// n2 → 第二个节点(计数=1) ← n1->_next(weak_ptr,不计数)
// 无循环引用!weak_ptr仅“观察”资源,不增加计数
}
int main()
{
test(); // test函数结束,n1/n2出作用域
// 预期:打印两次~ListNode(),说明节点成功析构,无内存泄漏
// 核心:weak_ptr打破了循环引用,引用计数能减到0
return 0;
}一、weak_ptr 的核心定位:弱引用 “观察者”
weak_ptr是 C++ 为解决shared_ptr循环引用问题设计的弱引用智能指针,核心特性是:仅作为shared_ptr管理资源的 “观察者”,不参与引用计数的增减,也不管理资源的生命周期 —— 它仅持有指向资源的裸指针,既不会增加shared_ptr的引用计数,也不会在自身析构时尝试释放资源。
二、循环引用的根源回顾
shared_ptr循环引用的核心问题是:对象之间互相持有对方的shared_ptr,赋值时触发引用计数 + 1,形成闭环后计数无法归 0。以双向链表为例:
- 节点 1 的
_next(shared_ptr)持有节点 2 → 节点 2 计数 + 1; - 节点 2 的
_prev(shared_ptr)持有节点 1 → 节点 1 计数 + 1; - 外部
shared_ptr析构后,节点 1/2 的计数仍为 1,闭环导致计数无法归 0,资源泄漏。
三、weak_ptr 解决循环引用的核心逻辑(代码拆解)
1. weak_ptr 的核心设计:不管理引用计数
模拟实现的weak_ptr无引用计数成员,仅持有裸指针,且从shared_ptr构造 / 赋值时仅拷贝裸指针,不修改计数:
template<class T>
class weak_ptr
{
public:
weak_ptr() : _ptr(nullptr) { }
// 从shared_ptr构造:仅拷贝裸指针,不+1计数(核心!)
weak_ptr(const shared_ptr<T>& sp)
: _ptr(sp.Get()) // 只拿裸指针,不碰引用计数
{ }
// 从shared_ptr赋值:仅赋值裸指针,不修改计数
weak_ptr<T>& operator=(const shared_ptr<T>& sp)
{
_ptr = sp.Get(); // 无计数操作
return *this;
}
private:
T* _ptr; // 仅持有裸指针,无_pcount(引用计数)成员!
};
- 关键区别:
shared_ptr的拷贝构造 / 赋值会让_pcount+1,而weak_ptr仅拷贝_ptr,完全不影响shared_ptr的引用计数。
2. 改造节点结构:用 weak_ptr 替代 shared_ptr 存储互相引用
将双向链表节点的_prev/_next从shared_ptr改为weak_ptr,打破 “互相持有 shared_ptr” 的闭环:
struct ListNode
{
int _val;
obj::weak_ptr<ListNode> _prev; // 弱引用:不增加计数
obj::weak_ptr<ListNode> _next; // 弱引用:不增加计数
~ListNode() { cout << "~ListNode()" << endl; }
};
- 节点之间的互相引用从 “强引用(shared_ptr,影响计数)” 变为 “弱引用(weak_ptr,不影响计数)”,这是解决循环引用的核心改造。
3. 测试函数中引用计数的变化(无闭环)
void test()
{
// 步骤1:shared_ptr管理节点,计数初始化为1(仅外部shared_ptr持有)
obj::shared_ptr<ListNode> n1(new ListNode); // 节点1计数=1
obj::shared_ptr<ListNode> n2(new ListNode); // 节点2计数=1
// 步骤2:weak_ptr赋值,仅拷贝裸指针,计数不变(核心!)
n1->_next = n2; // weak_ptr赋值,节点2计数仍=1(无+1)
n2->_prev = n1; // weak_ptr赋值,节点1计数仍=1(无+1)
// 引用关系:无闭环!
// n1 → 节点1(计数=1) ← n2->_prev(weak_ptr,不计数)
// n2 → 节点2(计数=1) ← n1->_next(weak_ptr,不计数)
}
- 此时节点 1/2 的引用计数仅由外部
n1/n2决定,内部weak_ptr不参与计数,闭环彻底被打破。
4. test 函数结束:计数归 0,资源正常释放
test 函数执行完毕后,n1/n2出作用域析构:
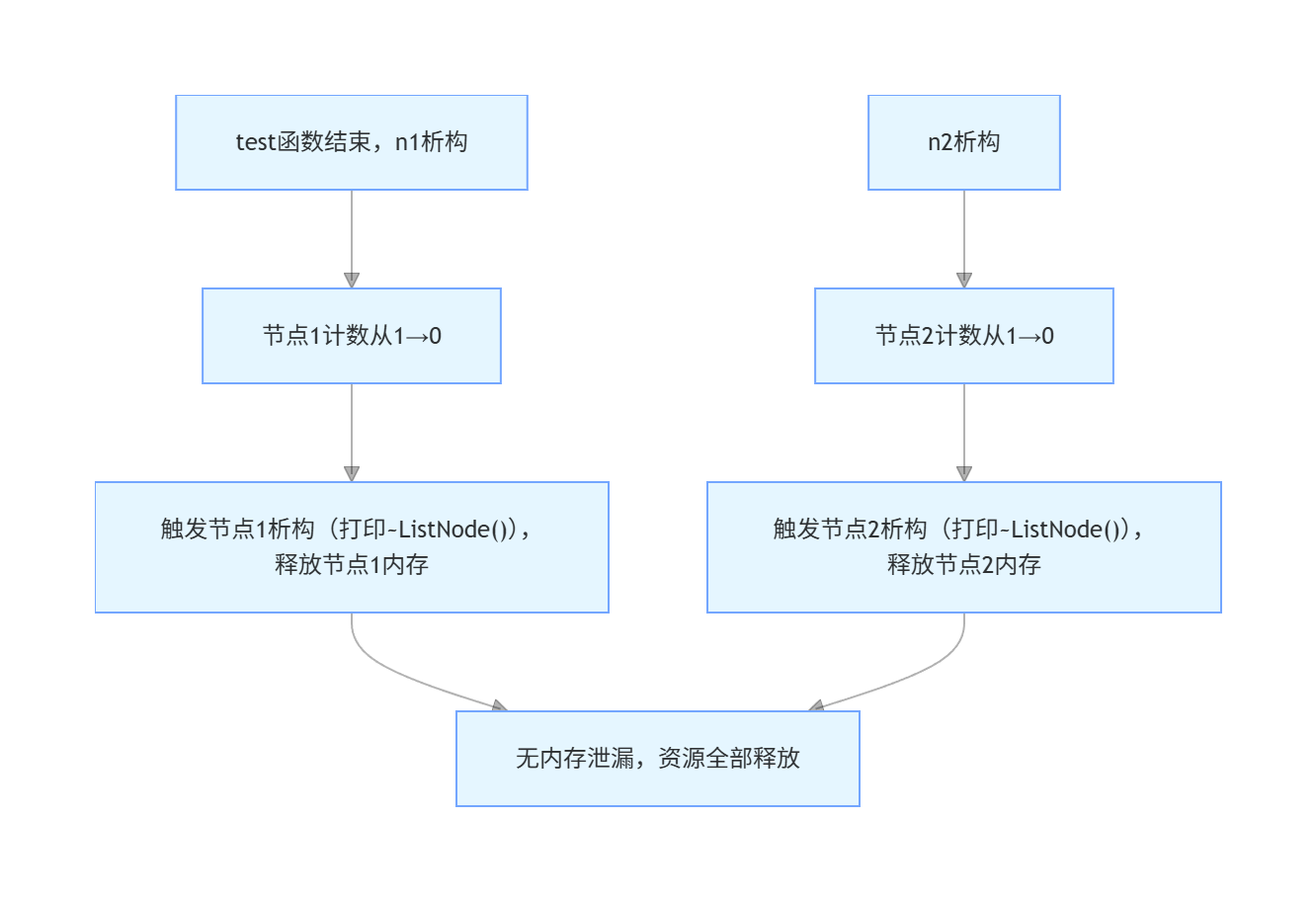
n1析构:节点 1 计数从 1→0 → 析构函数执行,释放节点 1;n2析构:节点 2 计数从 1→0 → 析构函数执行,释放节点 2;- 最终打印两次
~ListNode(),验证资源正常释放,循环引用问题解决。
四、weak_ptr 解决循环引用的本质
| 对比维度 | shared_ptr 互相引用(循环引用) | weak_ptr 替代后(无循环引用) |
|---|---|---|
| 引用类型 | 强引用(参与计数,+1) | 弱引用(不参与计数) |
| 计数变化 | 赋值后计数≥2,外部析构后≥1 | 赋值后计数 = 1,外部析构后 = 0 |
| 闭环状态 | 形成闭环,计数无法归 0 | 无闭环,计数可归 0 |
| 资源释放 | 析构不执行,内存泄漏 | 析构正常执行,资源释放 |
本质总结:weak_ptr通过 “弱引用不增加引用计数” 的特性,将对象之间的 “强引用闭环” 改为 “弱引用关联”—— 外部shared_ptr仍是资源生命周期的唯一管理者,外部shared_ptr析构后,引用计数能正常归 0,触发资源释放,彻底解决循环引用导致的内存泄漏。
五、总结(关键点回顾)
- weak_ptr 核心特性:弱引用,不管理引用计数,仅观察 shared_ptr 的资源,构造 / 赋值时仅拷贝裸指针,不修改计数;
- 解决循环引用的关键:将对象之间互相持有的
shared_ptr(强引用)改为weak_ptr(弱引用),打破 “强引用闭环”; - 资源管理逻辑:外部
shared_ptr仍负责资源的生命周期管理,weak_ptr 仅作为观察者,外部shared_ptr析构后计数能归 0,资源正常释放; - 适用场景:双向链表、父子对象互相引用等易形成循环引用的场景,内部互相引用用 weak_ptr,外部管理用 shared_ptr。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)