机器学习32:机器终生学习(Life Long Learning)
一.机器上的终身学习对于终身学习,通过浏览器搜索最有可能得到的答案不是与机器学习有关的内容,而是关于人类的活到老学到老。虽然大家关注的主题多是偏行人类如何活到老学到老,但是机器其实也是需要做终身学习。机器对于终身学习这件事也是非常接近与人类对于AI的想象。就如先教机器第一个任务学会做语音识别接着教其第二个任务做影像识别,然后第三个任务翻译等等不断教会其新的技能,等其学会上百上千万技能后就可能像终结
摘要
本文介绍了机器终生学习的基本概念及其重要性,探讨了机器在连续学习多个任务时所面临的挑战,尤其是“灾难性遗忘”现象。文中通过手写数字识别与问答任务等实例,说明了多任务训练与顺序学习之间的性能差异,并指出终生学习在实际应用中需克服存储与计算限制。此外,本文还系统阐述了终身学习的评估方法,包括正确率矩阵与后向传递指标,为后续研究提供了评价基础。
Abstract
This article introduces the fundamental concept and significance of machine life-long learning, discussing the challenges machines face when learning multiple tasks sequentially, particularly the "catastrophic forgetting" phenomenon. Through examples such as handwritten digit recognition and question-answering tasks, it illustrates the performance gap between multi-task training and sequential learning, highlighting the practical limitations in storage and computation that lifelong learning must overcome. Furthermore, the article systematically describes evaluation methods for lifelong learning, including accuracy matrices and backward transfer metrics, providing a foundation for subsequent research.
一.机器上的终身学习
对于终身学习,通过浏览器搜索最有可能得到的答案不是与机器学习有关的内容,而是关于人类的活到老学到老。
虽然大家关注的主题多是偏行人类如何活到老学到老,但是机器其实也是需要做终身学习。机器对于终身学习这件事也是非常接近与人类对于AI的想象。
就如先教机器第一个任务学会做语音识别接着教其第二个任务做影像识别,然后第三个任务翻译等等不断教会其新的技能,等其学会上百上千万技能后就可能像终结者中的天网一样。
虽说对于做出天网一样的AI还是遥远,但是对于这一终身学习思想在我们目前的应用中也是能够派上用场的。就如若在实验室中开发出某一个模型,并通过收集到的资料来训练这个模型,模型训练出来并上线之后,其会取得来自使用者的反馈。
这时候就会希望收集资料这件事情可以变成一个循环,模型上线之后可以收集到新的资料,新的资料就可以让我们来更新模型的参数,模型参数更新后就可以收集到更多的资料,有了更多的资料模型又可以更新,如此循环,最终系统就会越来越完善越厉害。
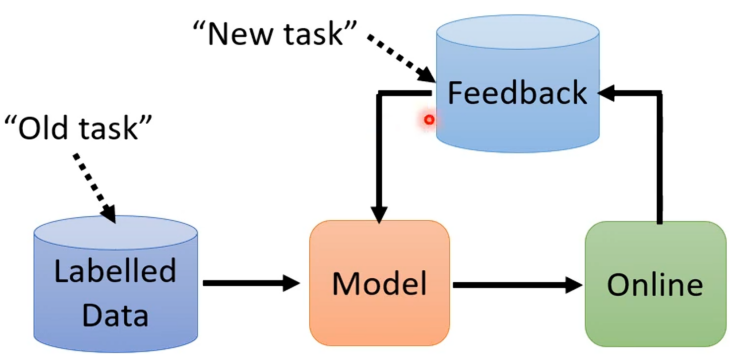
这时可以把旧有的资料当成过去的任务,把新的资料来自使用者反馈的数据当成新的任务,所以对于这样的情景也是可以看作终身学习的问题。
二.机器终身学习的难点
我们不就是让机器不断的看新数据,然后不断取更新其参数就做到了终生学习吗?所以其难点在哪呢?对此我们通过下面的例子来进行了解。
假设现在有两个任务,第一个任务就是进行手写数字辨识(图片中有杂讯),第二个任务也是手写数字辨识(图片中无杂讯)。这里用到的模型是有3层,每一层有50个neuron。现在任务1上学习得到的结果正确率有90%,就算没有通过任务二的训练其正确率也已经达到了96%。
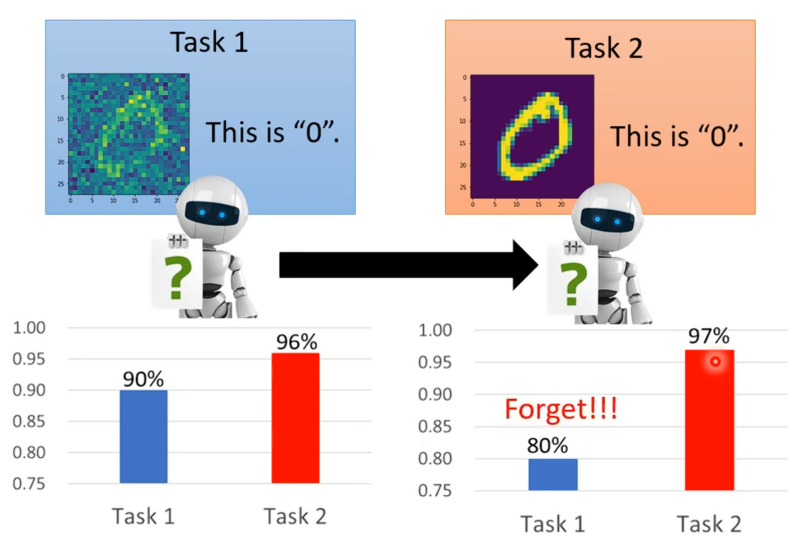
任务一学完之后,再让同一个模型继续去学任务二(在学习完的基础后再通过任务二的数据继续更新),学习完任务二之后得到再任务二上其正确率达到了97%,但是可以发现这个模型忘了如何取做任务一了,任务一的正确率掉到了80%。这里我们可以通过说内存有限来进行辩解。
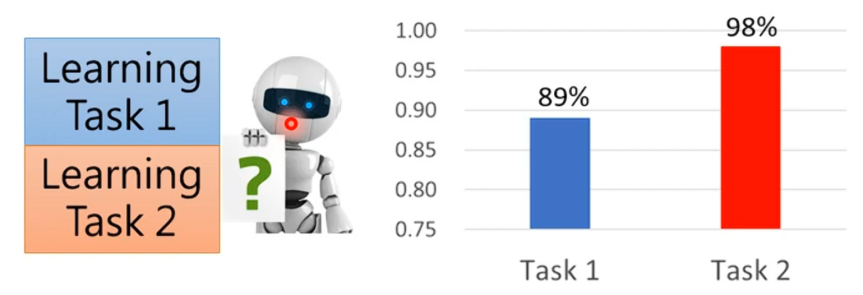
但是我们再看另外一个实验,我们将任务一与任务二的资料放在一起进行训练,得到的结果在任务一上正确率为89%,任务二正确率98%。所以说对于这个network而言,要同时学习好任务一与任务二它是办的到的。但是如果不是同时学习任务一和任务二,而是分开学习,就会对旧的任务有所遗忘。
为了证明不是特例,现在再看看自然语言处理的例子:让机器读一篇文章,然后问其一个问题机器给出答案。这里用的任务是简单的QA任务——bAbi。

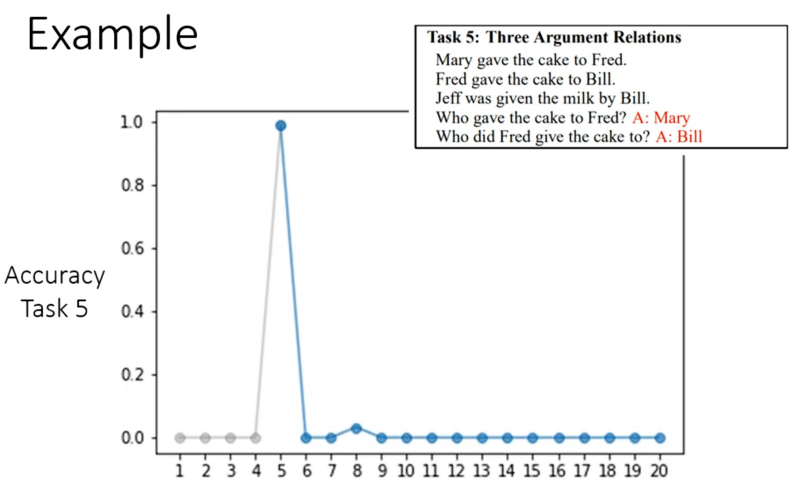
现在我们要做的就是让机器去依序学习这20个QA任务,得到的结果如下,主要是通过看任务5的正确率来进行比较,横轴是表示当前学习了前几个任务。我们可以看到前四个正确率为0,这时正常的因为并没有学习任务,学完任务之后正确率达到了100%,但是继续向后正确率就直线下降。
但是如果同时学习这20个任务,这时正确率并不是指指定的某个任务的正确率,而是横坐标对应任务的正确率。虽然有个别任务学不会,但是其还是可以同时学会好几个问题,并且正确率也是不低的。
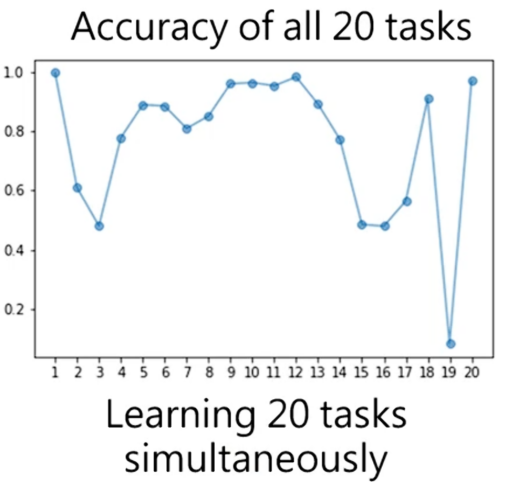
对于这个例子也是说明了机器明明有能力学习多个任务,但是让其依序学习是就会学不会多个任务。对于这个状况就称之为灾难性遗忘(Catastrophic Forgetting)。在解决这个问题之前,先了解下前面说的将资料综合后再训练,这个称之为多任务训练(Multi-task Training)。
所以通过多任务训练就可以让机器掌握多个任务,则终身学习值得研究的又在何处。因为假如当其机器学习第1000个任务,为了避免机器遗忘前面999个任务,这必须要将前面999个任务资料统统拿出与第1000个任务资料放在一起,这时机器对于这1000个任务能够掌握。
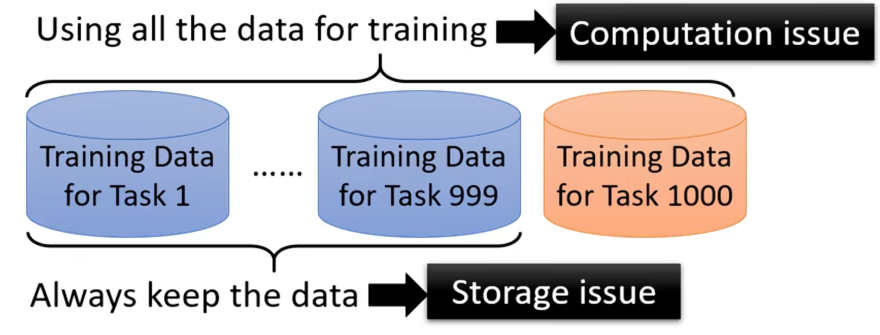
但是在实际上这是有问题的,因为就如上面若要做第1000个任务就要将其前999个任务也要记住,放大来说这就意味着机器要将其一辈子看过的资料都记住,首先就是没有那么大的空间存储,其次运算也是一个问题。
所以在很多实验中都称多任务训练的结果为LLL的上限,在实验中看看自己做成的机器的LLL能否接近这个上限。

除了多任务训练,我们也可以对这些任务都分别对应一个模型而为什么执着一个任务全解决。这是因为如果机器要学习的技能非常多,这样对应的模型数量要求的存储空间就会非常大。其次不同的任务对应不同的模型,则不同任务的资料之间就不能互通有无。
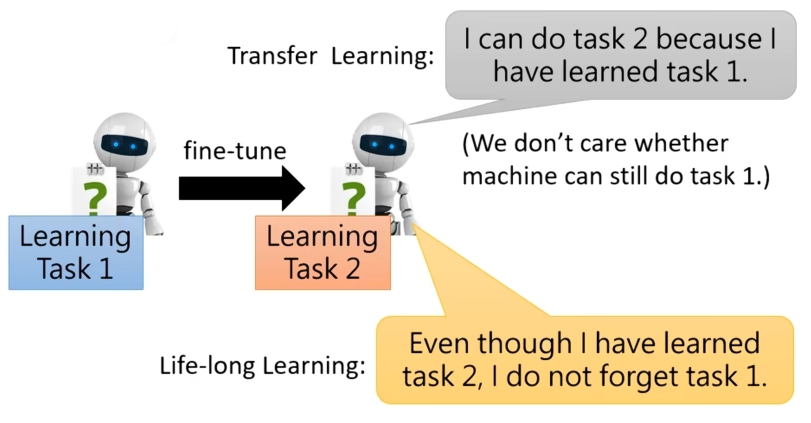
所以了解到这,我们发现这与迁移学习(Transfer Learning)类似,迁移学习就是在任务一上学习,希望在任务一上学习到的技能能够在任务二上同样有效。但是两者的关注点是不一样的,迁移学习是希望在前者上学习到的在后者上也有效,而LLL是希望在学习完前者后在学希望后者回过头,依然可以把前者做出来。
三.LLL的评估
在解决终身学习难点之前,先看看如何评估终生学习做的好不好。所以在此之前先需要有一系列的任务让机器可以依序学习。
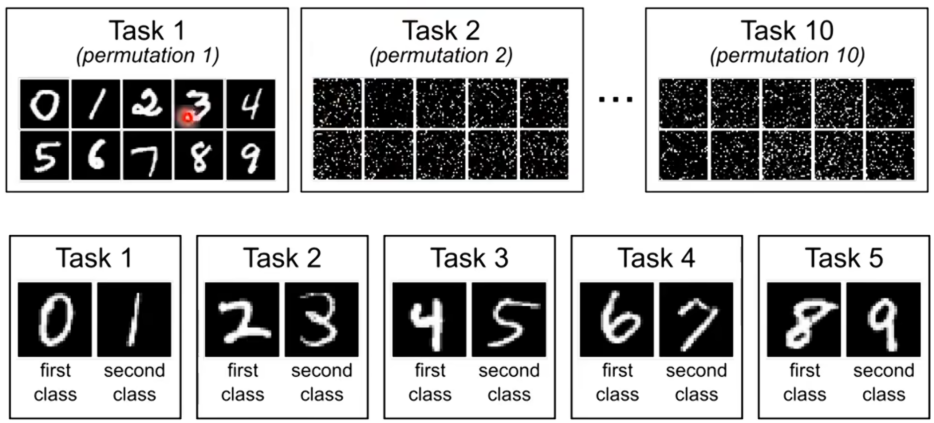
接着评估方法如下:
上边有一排的任务,先有个随机初始化的参数Rand Init,将其用在这T个任务上,得到T个正确率,接下来向下让模型先学第一个任务之后再在这T个任务上看正确率,接下来都是学习完有个就去对T个任务看正确率,直到最后有个任务T学习完成并测T个任务的正确率。
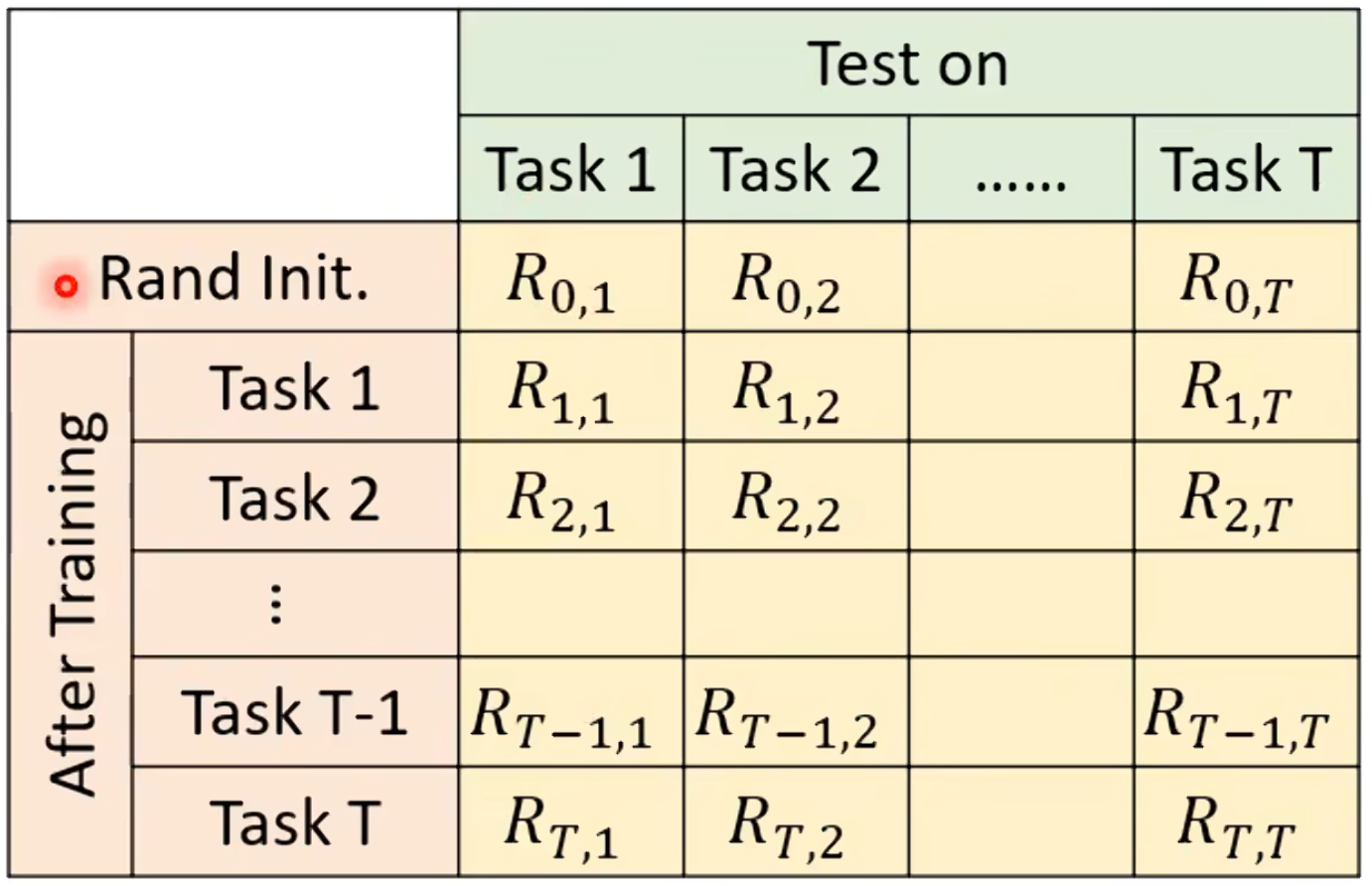
就得到如上表格,在这个表格中,表示的就是学习完第i个任务后在第j个任务上的正确率。如果i>j,则表示的是学完任务i做之前的任务j表现如何是否有忘记,若i<j,则表示在已学习的基础上,模型对于未学习资料上表现如何。
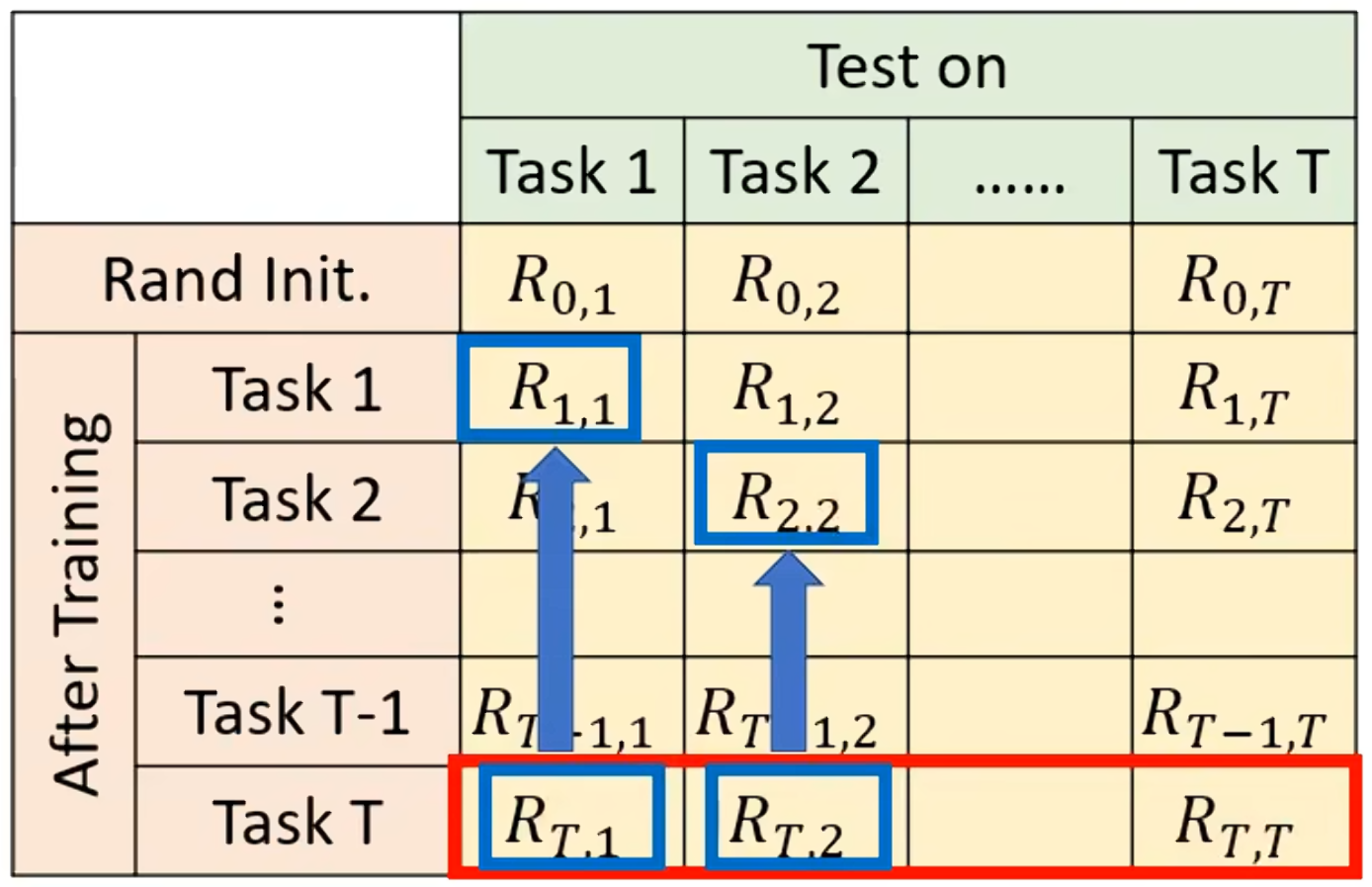
最后通过对学习完任务T后对所有任务正确率的求和取平均表示这个终身学习的好坏()。也有别的评估的方法,这个方法的公式为:Backward Transfer=
,由于
要比
小,所以这个方法最后的平均值通常是负的。
总结
本文系统阐述了机器终生学习的概念、难点与评估方法。机器在连续学习多个任务时容易出现“灾难性遗忘”,即学习新任务后遗忘旧任务,这与人类持续学习的能力形成对比。文中通过实验说明,多任务训练虽能缓解遗忘,但存储与计算成本较高;而顺序学习则需在有限资源下实现知识持续积累。最后,介绍了基于正确率矩阵的评估体系,为衡量终生学习模型的性能提供了明确指标。终身学习不仅是实现智能系统持续进化的重要方向,也是推动模型适应动态环境的关键技术。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)