夯实算子根基:CANN opbase 库让算子开发“有章可循、可复用、可演进”
在 CANN 生态中,算子(Operator)是模型计算的最小执行单元,也是性能优化的核心抓手。从 ops-math 的基础数学运算,到 ops-transformer 的 Transformer 原生加速,再到 asc-devkit 的自定义算子开发,所有高层库的能力最终都要落到“算子实现”这一层。然而,算子开发若缺乏统一的基础设施,容易陷入 重复造轮子、质量参差不齐、难以维护 的困境——不同团队写的 MatMul 可能内存管理逻辑各异,不同版本的 Attention 可能接口不兼容,新硬件适配时需要逐个修改算子代码。
华为 CANN 生态中的 opbase 库(全称 Operator Base Library,算子基础库),正是为解决这一问题而生。它是一套 面向 CANN 算子的“基础设施层”,定义了算子开发的通用接口、内存管理规范、错误处理框架与硬件适配抽象,让所有算子(无论是内置的还是自定义的)都能“站在巨人的肩膀上”开发,实现 可复用、可测试、可扩展 的目标。如果说 pto-isa 是算子的“指令画笔”,asc-devkit 是算子的“开发脚手架”,那么 opbase 就是算子的“地基与钢筋骨架”。
一、opbase 是什么?为什么需要它?
opbase 是 CANN 中专为 算子开发提供通用基础能力 的库,核心定位是:统一算子开发的底层规范与基础设施,降低算子间的集成成本,提升算子质量与可维护性。
核心痛点与解决方案
传统算子开发中,常见问题包括:
-
接口不统一:不同算子对输入输出的描述方式各异(如有的用
Tensor*指针,有的用std::vector<Tensor>),集成时需大量适配代码; -
内存管理混乱:算子内手动
malloc/free或依赖框架隐式管理,易导致内存泄漏或越界; -
错误处理碎片化:错误码定义不统一(如
-1可能表示“内存不足”或“参数非法”),调试时需逐个算子查文档; -
硬件适配困难:新硬件(如新一代 AI Core)发布时,需修改所有算子的硬件相关代码,工作量巨大。
opbase 的解决方案是 “标准化接口+统一内存管理+硬件抽象层+可测试框架”:
-
标准化算子接口:定义所有算子必须实现的
Init()、Run()、Release()生命周期方法,以及输入输出描述规范; -
统一内存管理:提供
TensorAllocator、MemoryPool等组件,实现设备内存的自动分配、复用与释放; -
硬件抽象层(HAL):封装 AI Core、CPU、GPU 等硬件的差异,算子通过 HAL 接口调用硬件功能,无需关心底层实现;
-
可测试框架:提供算子单元测试工具与 Mock 硬件环境,支持自动化验证正确性与性能。
二、opbase 的核心架构与功能模块
opbase 的架构围绕 “算子生命周期管理→内存与资源管理→硬件适配→错误处理→测试支持” 构建,核心模块可分为六大组件(如图 1 所示),为算子开发提供全流程基础能力。
(一)算子接口定义层(Operator Interface Definition)
目标:定义所有算子必须遵循的“契约”,确保接口一致性。
opbase 规定算子需继承 BaseOperator基类,并实现以下核心方法:
class BaseOperator {
public:
// 初始化算子(解析输入描述、分配资源)
virtual Status Init(const OperatorDesc& desc) = 0;
// 执行算子计算(核心逻辑)
virtual Status Run(const TensorList& inputs, TensorList& outputs) = 0;
// 释放算子资源(内存、句柄等)
virtual Status Release() = 0;
// 查询算子元数据(输入输出规格、属性等)
virtual OperatorMeta GetMeta() const = 0;
virtual ~BaseOperator() = default;
};其中,OperatorDesc是输入描述结构体(含输入输出张量规格、属性参数),TensorList是张量列表容器,Status是统一错误码类型(见下文错误处理模块)。
(二)内存管理模块(Memory Management)
目标:解决算子内存分配的“碎片化”与“泄漏”问题,提供高效、安全的设备内存管理能力。
核心组件包括:
-
TensorAllocator:统一张量内存分配接口,支持
Allocate()(分配)、Free()(释放)、Reuse()(复用)操作,自动管理设备内存生命周期; -
MemoryPool:预分配大页内存池,减少频繁
malloc/free的开销,支持按张量大小分类缓存(如 1KB/4KB/16KB 池); -
TensorView:张量视图(零拷贝切片),允许算子在不复制数据的情况下引用输入张量的子区域(如
tensor.Slice(0, 10)引用前 10 个元素)。
示例:使用 TensorAllocator 分配张量内存
#include "opbase/memory/tensor_allocator.h"
// 初始化内存分配器(绑定到 AI Core 设备)
TensorAllocator allocator(DeviceType::kNPU, /*pool_size=*/1GB);
// 分配 FP16 张量(形状 [batch=32, dim=1024])
Tensor tensor;
allocator.Allocate({32, 1024}, DataType::kFloat16, tensor);
// 使用后可复用或释放
allocator.Reuse(tensor); // 放回内存池供其他张量复用
// allocator.Free(tensor); // 显式释放(若不再使用)(三)硬件抽象层(Hardware Abstraction Layer, HAL)
目标:屏蔽不同硬件(AI Core、CPU、GPU)的实现差异,让算子代码“一次编写,多硬件运行”。
HAL 定义了一组与硬件无关的接口,例如:
-
计算接口:
HalMatMul()、HalVecAdd()(底层调用 AI Core 矩阵乘或 CPU BLAS); -
内存接口:
HalMemcpy()(自动选择设备间/设备内拷贝路径); -
同步接口:
HalStreamSync()(同步计算流与内存拷贝流)。
算子通过 HAL 接口调用硬件功能,无需直接操作硬件寄存器或汇编指令:
#include "opbase/hal/hal_compute.h"
// 调用硬件无关的矩阵乘接口(底层自动适配 AI Core 或 CPU)
Status MatMulOp::Run(const TensorList& inputs, TensorList& outputs) {
const Tensor& a = inputs[0];
const Tensor& b = inputs[1];
Tensor& c = outputs[0];
// 通过 HAL 调用矩阵乘(自动选择最优硬件实现)
return HalMatMul(a.data(), b.data(), c.data(),
a.shape()[0], a.shape()[1], b.shape()[1],
a.dtype());
}(四)错误处理框架(Error Handling Framework)
目标:统一错误码定义与错误信息格式,提升调试效率。
opbase 定义了一套层次化错误码体系:
enum class Status {
// 成功
kSuccess = 0,
// 输入错误(如形状不匹配、类型不支持)
kInvalidArgument = 1,
// 内存错误(如分配失败、越界)
kMemoryError = 2,
// 硬件错误(如 AI Core 超时、指令不支持)
kHardwareError = 3,
// 算子未初始化
kUninitialized = 4,
// 未知错误
kUnknownError = -1
};
// 错误信息结构体(含错误码、描述、调用栈)
struct ErrorInfo {
Status code;
std::string msg;
std::vector<std::string> stack_trace;
};算子需通过 OP_RETURN_IF_ERROR()宏统一返回错误,确保错误信息可追溯:
Status MatMulOp::Init(const OperatorDesc& desc) {
OP_RETURN_IF_ERROR(ValidateInputShape(desc.inputs)); // 校验输入形状
OP_RETURN_IF_ERROR(allocator_.Allocate(...)); // 分配内存
return kSuccess;
}(五)算子注册与发现模块(Operator Registration & Discovery)
目标:实现算子的动态注册与查询,支持运行时动态加载新算子(如插件式扩展)。
opbase 提供 OperatorRegistry单例,算子通过宏注册到全局表:
// 注册 MatMulOp 到全局注册表(名称为 "MatMul")
REGISTER_OPERATOR(MatMulOp, "MatMul");
// 运行时查询并创建算子实例
auto op = OperatorRegistry::GetInstance()->Create("MatMul");
if (op) {
op->Init(desc); // 初始化算子
}(六)测试支持模块(Testing Support)
目标:提供算子单元测试与性能测试工具,确保质量与性能。
核心工具包括:
-
MockTensor:模拟张量数据(支持预设值与随机值),用于单元测试;
-
OpTester:自动化测试框架,支持正确性验证(与 NumPy 参考实现对比)与性能基准测试;
-
HalMock:模拟硬件行为(如强制返回内存不足错误),验证算子错误处理逻辑。
示例:使用 OpTester 测试 MatMulOp
#include "opbase/testing/op_tester.h"
TEST(MatMulOpTest, Correctness) {
OpTester tester("MatMul"); // 指定算子名称
// 设置输入(与 NumPy 参考结果对比)
tester.AddInputFromArray<float16>({2, 3}, {1, 2, 3, 4, 5, 6}); // A
tester.AddInputFromArray<float16>({3, 2}, {7, 8, 9, 10, 11, 12}); // B
// 设置参考输出(NumPy 计算结果)
tester.AddReferenceOutputFromArray<float16>({2, 2}, {58, 64, 139, 154});
// 执行测试
tester.RunTest();
}三、opbase 的使用流程图
opbase 的核心开发流程可总结为“定义算子→实现接口→注册发现→测试验证→集成部署”,具体流程如图 2 所示: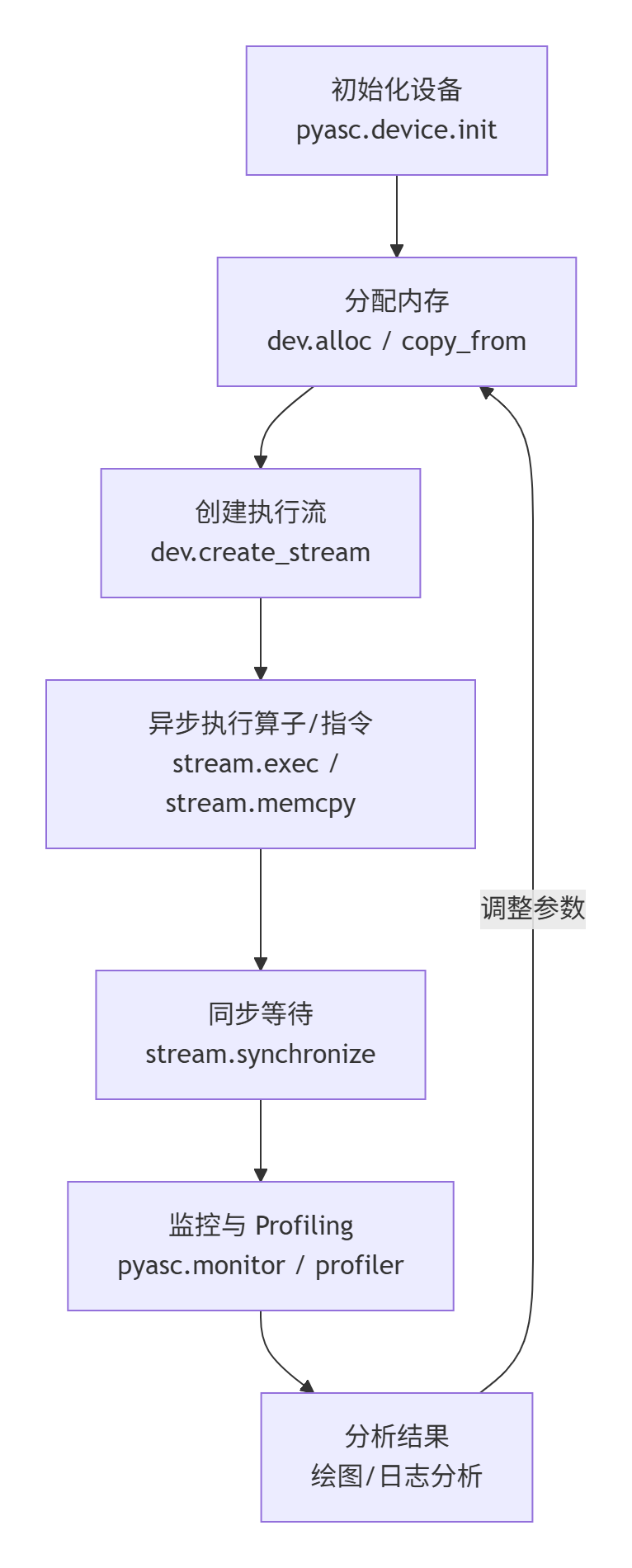
四、opbase 的独特价值
|
维度 |
传统算子开发 |
opbase 标准化开发 |
|---|---|---|
|
接口一致性 |
各算子自定义,集成困难 |
统一 BaseOperator 接口,即插即用 |
|
内存管理 |
手动管理,易泄漏/越界 |
统一 TensorAllocator,自动回收 |
|
硬件适配 |
需为每个硬件重写代码 |
HAL 抽象,一次编写多硬件运行 |
|
错误处理 |
错误码混乱,调试耗时 |
层次化错误码+调用栈,快速定位 |
|
可测试性 |
需手动构造测试数据 |
OpTester+Mock 工具,自动化验证 |
|
可维护性 |
代码风格各异,难维护 |
规范统一,新人易上手 |
五、典型应用场景
-
内置算子开发:CANN 团队开发 ops-math、ops-transformer 等库的内置算子时,基于 opbase 确保接口与质量统一;
-
自定义算子开发:企业开发者使用 asc-devkit 开发业务专属算子(如稀疏卷积),通过 opbase 快速接入 CANN 生态;
-
硬件适配:新一代 AI Core 发布时,仅需更新 HAL 层实现,所有基于 opbase 的算子自动支持新硬件;
-
算子质量保障:通过 opbase 的测试框架,实现算子的自动化回归测试,避免迭代引入新问题。
六、总结与展望
opbase 库是 CANN 生态的 “算子基础设施底座”,它通过标准化接口、统一内存管理、硬件抽象与测试支持,为所有算子开发提供了“通用语言”与“可靠地基”。与 pto-isa 的指令级控制、asc-devkit 的低代码开发形成互补,opbase 确保了算子开发从“野蛮生长”走向“工业化生产”。
未来,随着 CANN 对更多硬件架构(如存算一体、光计算)与新数据类型(如 FP8、INT4)的支持,opbase 将进一步扩展 HAL 层接口与内存管理策略,并强化与 AI 框架(如 PyTorch、TensorFlow)的算子注册协议兼容,成为跨平台、跨框架的“通用算子基础设施”。
📌 仓库地址:https://atomgit.com/cann/opbase
📌 CANN组织地址:https://atomgit.com/cann

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)