Claude Opus 4.6 vs GPT-5.3-Codex,到底谁更强?
无论是 Agentic search、超长上下文检索、跨学科极限推理,还是长程逻辑一致性,Opus 4.6 都是在把 Sonnet 这一代彻底甩在身后,同时在多个点位上正面压住 GPT-5.x(不包括最新的 GPT-5.3-Codex) 体系。从整体跑分来看,GPT-5.3-Codex 更新重点放在了「执行力」上,也就是,在「长期、可执行、需要反复试错的工程任务」这一类问题上,GPT-5.3-Co
今天又是一场恶战啊。
等了快一周的 Claude Sonnet 5 没等来,结果先冲出来的是 Claude Opus 4.6。
OpenAI 也不甘示弱,没过几分钟立马甩出了 GPT-5.3-Codex。
这个时间点,是不是有点太巧了?
果然,据 TechCrunch 报道,两家公司原本约好在太平洋时间上午 10 点同时发布。但 Anthropic 不讲武德的临时把时间提前了 15 分钟,9:47 就把消息放出来了。OpenAl 大概是刷到了推送,9:52 立刻跟上。
与此同时,大洋彼岸的我们。AI 大战也在如火如荼的进行中。就是这个模型吧,有点好喝(bushi
来自网友的总结——

跑远了。。。说回原来的话题。
老规矩,把两家的硬指标先对齐,来看看跑分。
Claude Opus 4.6 这次更新的重心,非常集中,就两个关键词:「极限推理」,以及「超长上下文下还能不掉链子」。照着“高强度 Agent 任务”这个方向死磕。
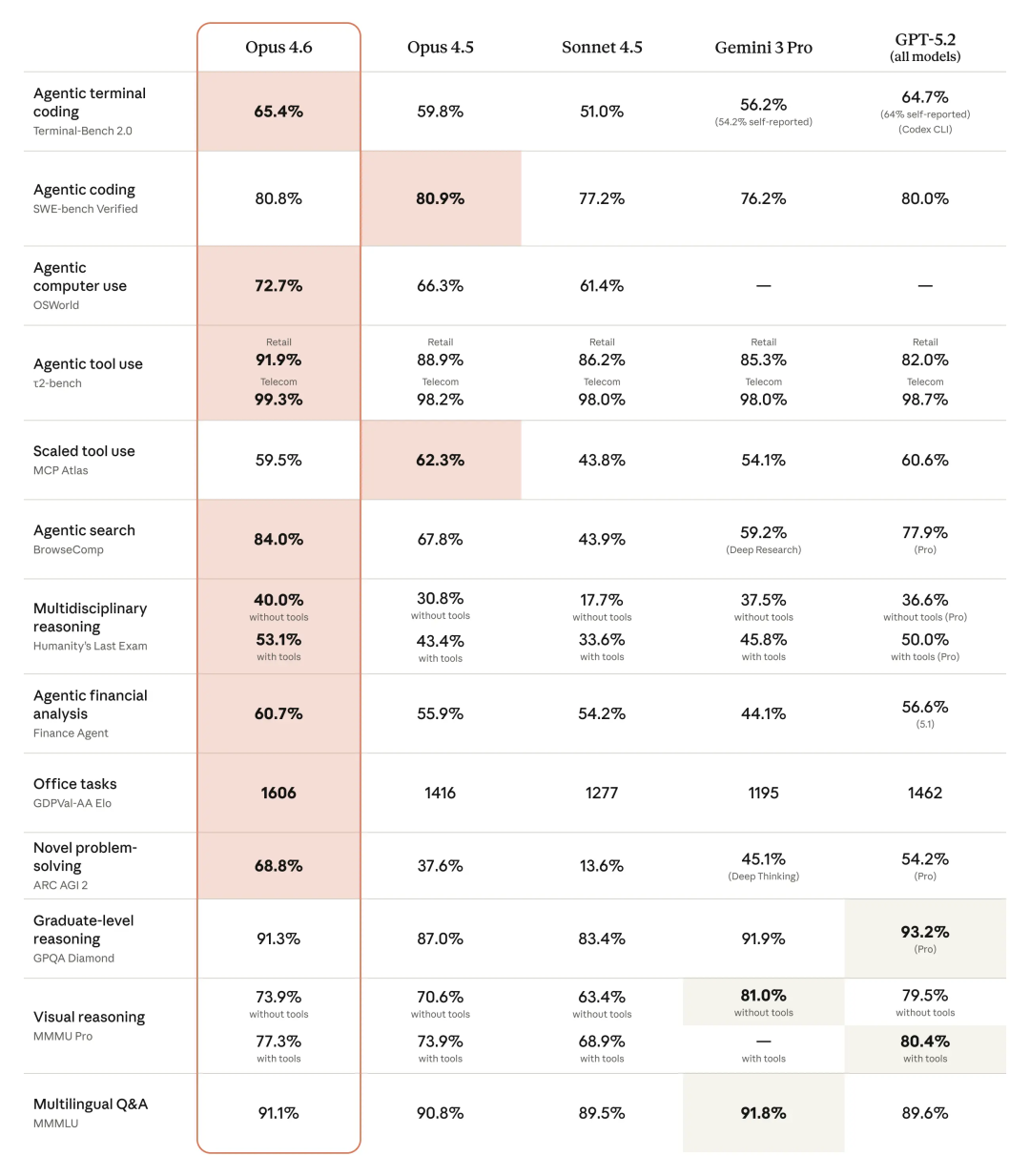
先看第一个非常直观、也最不容易被刷榜技巧掩盖的指标:Agentic search,也就是 BrowseComp。
在这个测试里,Opus 4.6 的准确率是 84.0%。
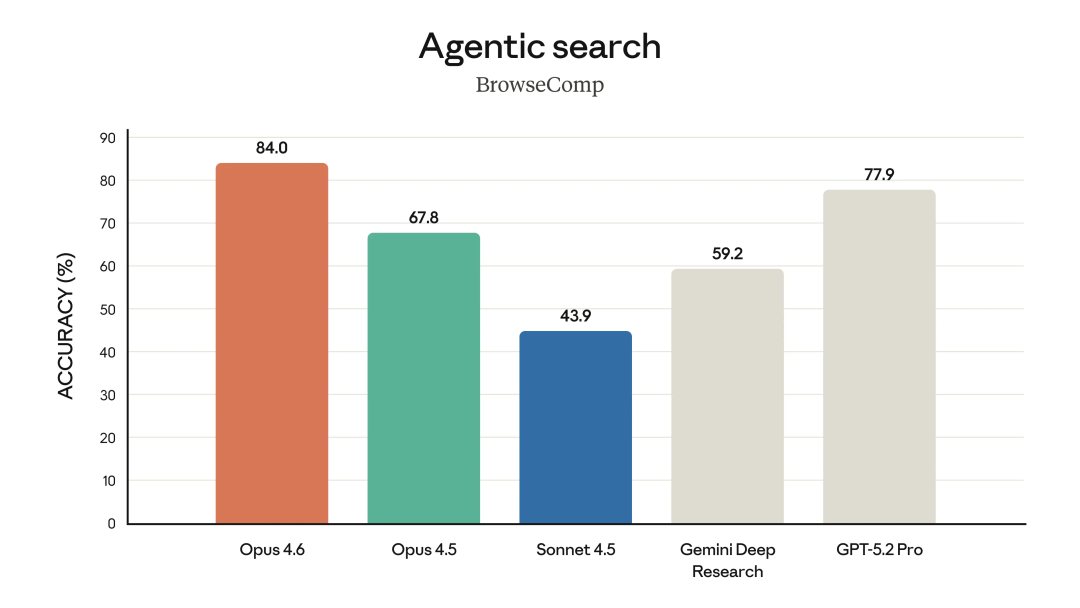
对比一下同场的几个模型:Opus 4.5 是 67.8%,Sonnet 4.5 只有 43.9%,Gemini Deep Research 是 59.2%,GPT-5.2 Pro 是 77.9%。
BrowseComp 本质上测的是,模型能不能自己规划搜索路径、在多网页、多来源里来回跳转,还能记住自己刚才看过什么、为什么要点下一页。84% 这个数,说明 Opus 4.6 在这类任务上,已经明显把 Sonnet 这一代甩开了一个身位,甚至压过了 GPT-5.2 Pro。
而从 Humanity’s Last Exam,多学科极限推理这个指标来说。
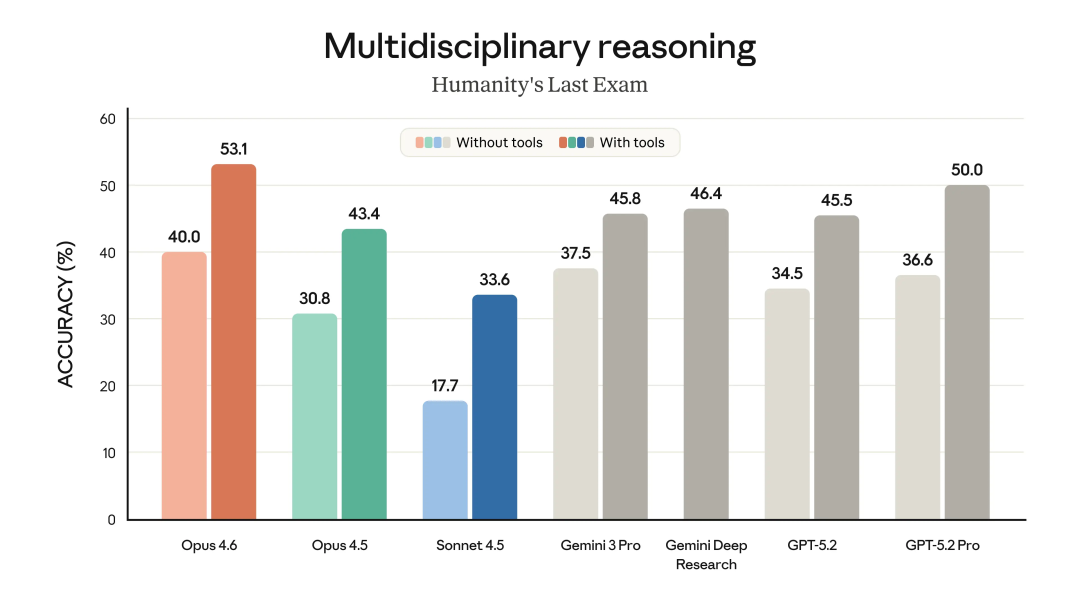
如果只看不使用工具的纯脑力版本,Opus 4.6 是 40.0%,Opus 4.5 是 30.8%,Sonnet 4.5 只有 17.7%。一旦允许使用工具,Opus 4.6 直接拉到 53.1%,而 Opus 4.5 是 43.4%,Sonnet 4.5 是 33.6%。
Opus 4.6 在“不用工具”和“用工具”两种模式下,都是同代里最稳的。甚至你仔细看, Opus 4.6 闭卷都比 Sonnet 4.5 开卷强。。。
长上下文推理一直是 Claude 的强项,这次更新也没落下。
工程师们最开心的事情来了,作为一个编程模型,Opus 系列的 Opus 4.6 终于支持 1M token 的上下文了!
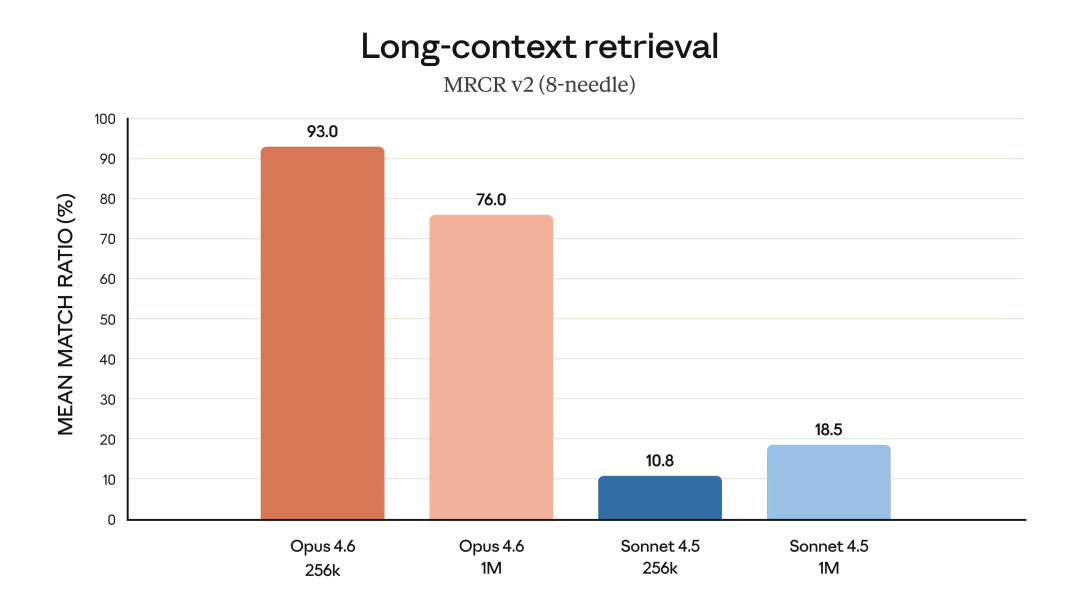
在 256k 上下文下,Opus 4.6 的 mean match ratio 是 93.0%;拉到 1M 上下文,依然能做到76.0%。
对照一下 Sonnet 4.5:256k 是 10.8%,1M 是 18.5%。
这个对比其实已经有点残酷了。因为这是一个非常原始的问题:你把东西埋在一百万 token 的长文档里,它还能不能翻出来。Opus 4.6 在 1M 规模下还能保持 76%,说明它在超长对话 + 大量历史信息的情况下,真的没有彻底迷路。Sonnet 那组 10%~18% 的数字,基本等同于靠运气。
MRCR 还是偏检索,那再看一个偏长程逻辑链的:Graphwalks(Long-context reasoning)。
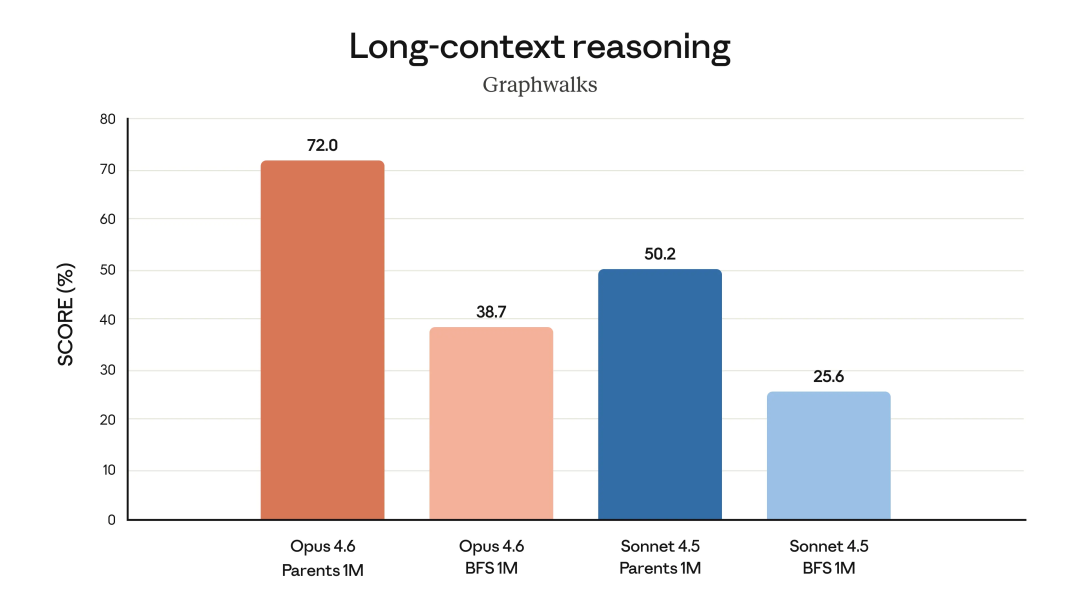
在 1M parents 路径下,Opus 4.6 的得分是 72.0%,同样条件下,Sonnet 4.5 是 50.2%。
而一旦换成更难的 BFS 路径,Opus 4.6 还有38.7%,Sonnet 掉到 25.6%。
这个测试,就是看模型能不能在一张超大的关系网里,一步一步顺着逻辑走下去,不跳步、不忘前提。能在 1M 规模下维持 70% 左右,已经非常接近人类认真推理的表现了。
在 API 层面,Anthropic 这次也给开发者补齐了「长期 Agent」真正需要的两块底盘。

通过「Adaptive Thinking(自适应思维)」,模型可以根据任务复杂度动态调节推理深度;同时配合「 Context Compression(上下文压缩)」,在长时间运行中主动精简历史信息,避免上下文越堆越厚,最终撞上长度上限直接翻车。
到这里,其实 Opus 4.6 的画像已经非常清晰了。
它这次在所有“长时间、多步骤、高记忆负担”的测试里,几乎全部拉开差距。无论是 Agentic search、超长上下文检索、跨学科极限推理,还是长程逻辑一致性,Opus 4.6 都是在把 Sonnet 这一代彻底甩在身后,同时在多个点位上正面压住 GPT-5.x(不包括最新的 GPT-5.3-Codex) 体系。
在应用层面,Anthropic 也在把 Claude 往真正的生产力工具里推。
先是 Claude in Excel。他们直接把 Claude Opus 4.6 集成进电子表格。让模型不再只是帮你想公式,而是能读懂现有表格结构,在你已经写好的数据和逻辑里动手改、补、推演。
他们还放出了 Claude in PowerPoint。形式上和 Excel 版类似。Claude 被放进了 PowerPoint 的侧边栏,但能力更偏内容生成:它可以读取你已有的版式、字体和母版规范,在不破坏风格的前提下,直接在 PPT 里生成新内容。
大家最最关心的价格。
Claude 加量不加价,Opus 4.6 API 价格不变,但是对于超过 20 万代币的提示,将收取额外费用(每百万输入/输出代币 10 美元/37.50 美元)
问题来了:那 GPT-5.3-Codex 呢?它到底是不是来砸场子的?
OpenAI 的官方文档,称 GPT-5.3-Codex 为目前最强的 agentic coding model,而且把 Codex 的工作半径从写代码扩到几乎所有专业人士在电脑上会做的事。
它把 GPT-5.2-Codex 的编程能力、GPT-5.2 的推理与职业知识揉在一起,还提速 25%,目标是让它更适合长跑任务,比如研究、工具调用、复杂执行、反复试错等等。
公开跑分里,Opus 4.6 和 GPT-5.3-Codex 目前唯一相同,可以正面对打的 benchmark,只有 Terminal-Bench 2.0。
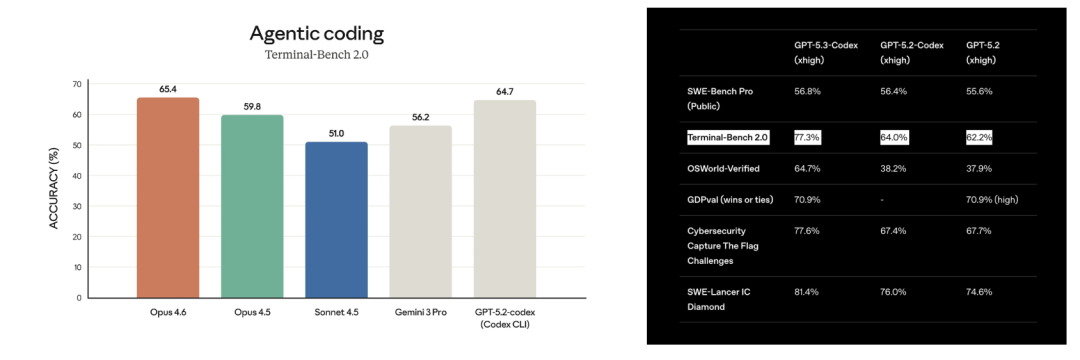
从这个来看,GPT-5.3-Codex 为 77.3%,而 Claude Opus 4.6 只有 65.4%,差了将近 12 个百分点。有点狠啊。
除此之外,GPT-5.3-Codex 还有一个单列出来的指标 OSWorld-Verified——检验的是模型在一个真实的操作系统环境里,能不能把一件任务从头到尾真的做完。
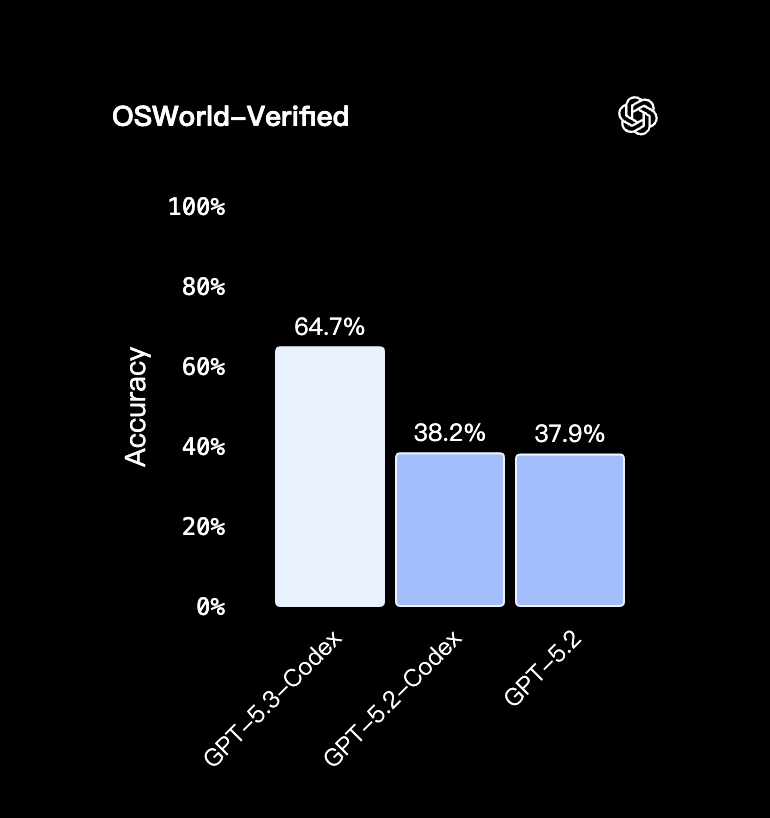
进步非常明显。
GPT-5.3-Codex 直接拉到了 64.7%,相比于前代模型,几乎跨越了一个维度。
从整体跑分来看,GPT-5.3-Codex 更新重点放在了「执行力」上,也就是,在「长期、可执行、需要反复试错的工程任务」这一类问题上,GPT-5.3-Codex 现在是明显更强的。
为了体现 GPT-5.3-Codex 代码能力和审美,OpenAI 还专门做了两个小游戏出来。
一个是赛车游戏,一个是潜水的。

游戏地址:
赛车:https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/racing_v2.html
潜水:https://cdn.openai.com/gpt-examples/7fc9a6cb-887c-4db6-98ff-df3fd1612c78/diving_game.html
OpenAI 同样还展示了给打工人做牛马的 case。包括 PPT、表格、文档等等。
就是,我怎么看都还是很 AI。。。有点丑丑的。
最后,两家也不约而同地把话题,落在了同一个地方:安全。
先看 Anthropic。
这次的 Opus 4.6 ,过度拒绝率(即模型无法回答良性查询)降到了近期 Claude 系列里的最低水平。
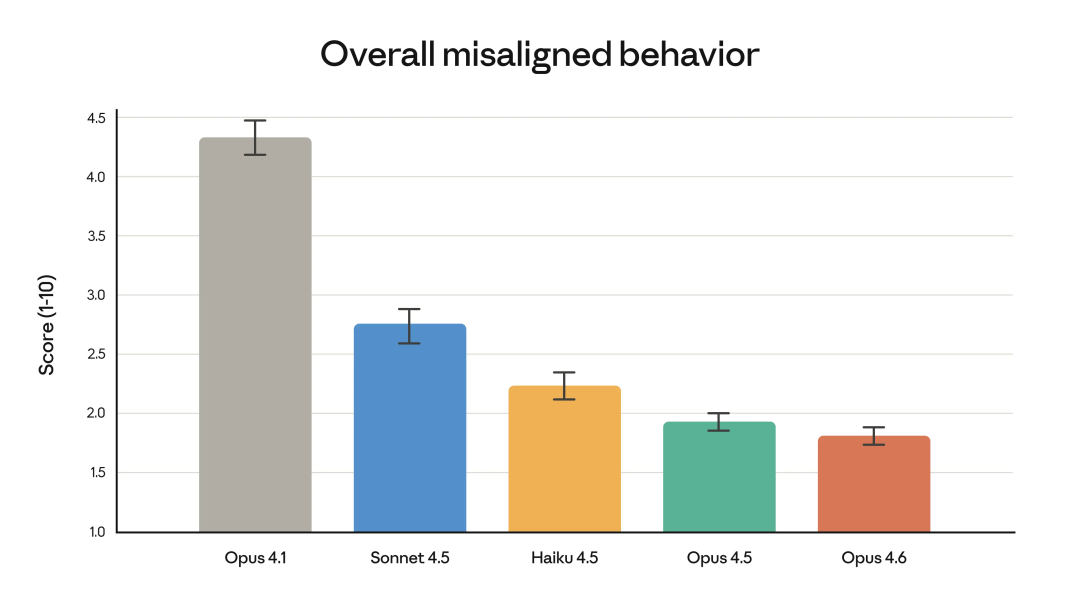
同时在欺骗、迎合、鼓励妄想、配合滥用等失配行为上,整体水平跟 Opus 4.5 持平,甚至更好。
他们对「安全测试」这件事的态度也变了。
这次对 Opus 4.6,Anthropic 跑的是一套迄今最完整的安全评估流程,明显是往工程系统方向在搭。
里面加了不少新东西,比如:
-
面向用户福祉(wellbeing)的专项评估;
-
更复杂的“该拒绝时,能不能准确拒绝”测试;
-
更新了模型是否会偷偷越线、暗中做坏事的检测方式;
-
甚至开始尝试引入可解释性方法,去追问模型为什么会在某些节点做出那个选择。专门用来补传统评测抓不到的死角。
放在 Opus 4.6 的能力升级背景下,这一套其实挺关键。
因为它这轮增强里,网络安全是个非常敏感的增量。毕竟,帮你修漏洞,很香。教你怎么搞破坏,也可能同样顺手。
所以 Anthropic 这次直接上了 6 种全新的网络安全 probes(你可以理解成“探针/暗桩”),专门用来检测模型有没有输出危险路径、有没有在边缘试探。
再看 OpenAI。
这次他们同样把「安全」放在了一个非常显眼的位置,而且思路和 Anthropic 出奇地接近。
因为 GPT-5.3-Codex 强在“执行力”,而执行力一旦落到网络安全领域,就是典型的双刃剑。
所以 OpenAI 直接把它归入 Preparedness Framework 里的 High capability(网络安全相关)级别,并且给它配了一整套目前最重的安全栈:安全训练、自动监控、受信访问、威胁情报,再到执行层面的联动管线,一套拉满。
同时,他们还推出了一个 Trusted Access for Cyber 的试点,想把更强能力优先给到防守方。
配套动作也跟上了。继续推进安全研究 agent(Aardvark),和开源维护者合作做免费安全扫描。同时还直接甩出 $10M 的 API credits,用来扶持防守侧生态。
今天这一天太热闹了。
光一个产品更新可能带来的都是一场翻天覆地的变化。更何况是俩。。
而且很明显,单纯去卷模型谁更聪明这件事,已经接近瓶颈了。算力、参数、推理分数,继续往上堆,带来的边际收益正在快速变小。
所以你会看到,各家开始把火力往外挪。模型迟早要从回答问题,走到替人干活。
那么,写到最后我只想问一个问题。千问的奶茶卷点哪家?
在线等,挺急的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献94条内容
已为社区贡献94条内容

所有评论(0)