MiniMax M2.5发布:硬刚 Claude Opus,一美元包断一小时的生产力
智能白菜价时代!MiniMax M2.5 刚刚发布,让顶级生产力一小时只要一刀。M2.5 在智力上硬刚 Claude Opus 4.6,更用一美元包断一小时的离谱价格,直接把 AI 生产力的门槛踩到了地板砖以下。它不再只是一个会陪你聊天的机器人,而是一个彻头彻尾的数字打工人。刚发布,OpenClaw 就宣布集成。它不仅能写代码,还能像架构师一样先画图纸再动工;它不仅能搜网页,还能像分析师一样做深度
智能白菜价时代!
MiniMax M2.5 刚刚发布,让顶级生产力一小时只要一刀。


M2.5 在智力上硬刚 Claude Opus 4.6,更用一美元包断一小时的离谱价格,直接把 AI 生产力的门槛踩到了地板砖以下。
它不再只是一个会陪你聊天的机器人,而是一个彻头彻尾的数字打工人。刚发布,OpenClaw 就宣布集成。
它不仅能写代码,还能像架构师一样先画图纸再动工;它不仅能搜网页,还能像分析师一样做深度调研。
最重要的是,它的使用成本低到几乎可以忽略不计,让无限智能成了现实。
代码界的总设计师
在编程评估中,M2.5 相比前几代有了显著提升,达到了 SOTA 水平。M2.5 在多语言编码任务中的表现尤为突出。
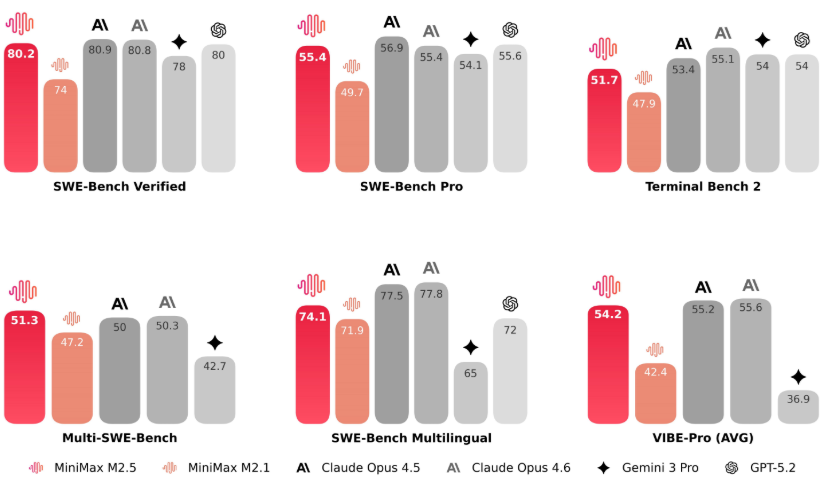
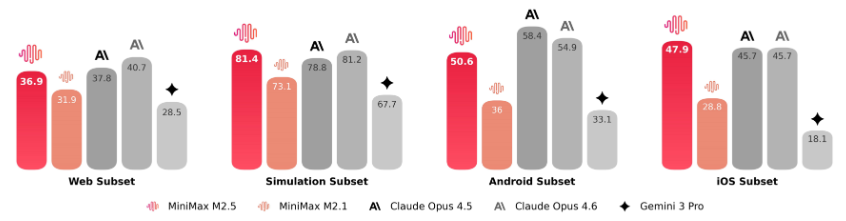
M2.5 涌现出架构师思维。
当你提出一个需求时,它不会急吼吼地马上开始敲键盘,而是先停下来思考。
它会像一个老练的架构师一样,先写 Spec 文档,把系统的功能模块、数据结构、UI 设计全部规划得明明白白。
这种谋定而后动的能力,是在两万多个真实编程环境中卷出来的。
它现在的能力覆盖了从 0 到 1 的系统搭建,到后续的功能迭代,甚至最后的代码审查。
不管是用 Python 搞后端,还是用 Kotlin 写安卓,或者是 Rust、C++ 这种硬骨头,它都能啃下来。
在 SWE-Bench Verified 这个专门考 AI 写代码能力的测试里,M2.5 拿到了 80.2% 的高分,直接把之前的版本甩在身后,甚至比 Claude Opus 4.6 还要快。
这种能力的涌现,让它在处理复杂任务时的表现有了质的飞跃。
真正的职场多面手
M2.5 还被训练成了一个真正的职场多面手。
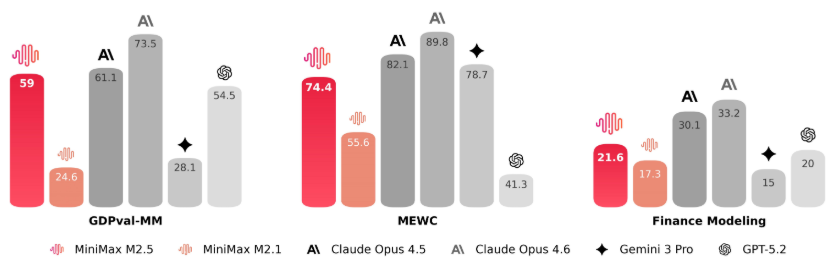
在 Word、Excel、PPT 这些工作场景中实现了显著的能力提升。
MiniMax 与金融、法律和社会科学等领域的资深专业人士进行了深入合作。他们设计需求,提供反馈,参与标准制定,并直接参与数据构建,将行业的隐性知识引入模型的培训流程。各自行业的潜规则和默会知识教给了 AI。
工具调用和搜索是模型能够自主处理更复杂任务的前提。
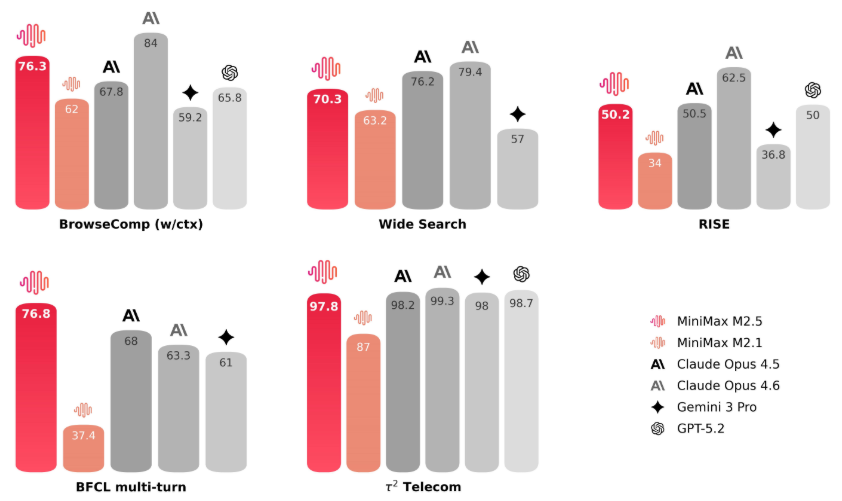
在 BrowseComp 和 Wide Search 等基准测试的评估中,M2.5 实现了行业领先的性能。
模型的泛化也有所提升,在面对陌生脚手架环境时表现更稳定。
举个例子,在做行业研究时,它不会像普通搜索引擎那样,给你扔回来一堆乱七八糟的链接。
它会遵循一套成熟的研究框架,先去搜集数据,然后梳理逻辑,最后生成一份格式严谨的研究报告。
在 Excel 里,它也不是简单地填填数字,而是能根据复杂的风控逻辑,自动生成和验证财务模型。
在这个过程中,M2.5 展现出了极强的搜索和工具使用能力。
在真实的搜索环境测试(RISE)中,它表现出了专家级的水准。它不再盲目地乱搜,而是懂得了如何用最少的步骤找到最准确的答案。
解决问题的回合数比M2.1减少了 20%。这说明它不仅是在找答案,更是在优化找答案的路径。
现在,MiniMax 自己的员工已经离不开它了。
公司里 30% 的日常任务都是由 M2.5 自动完成的,覆盖了从产品研发到人事财务的各个环节。
“自己做的菜自己先吃”的开发模式,保证了 M2.5 的能力是真正经过实战检验的。
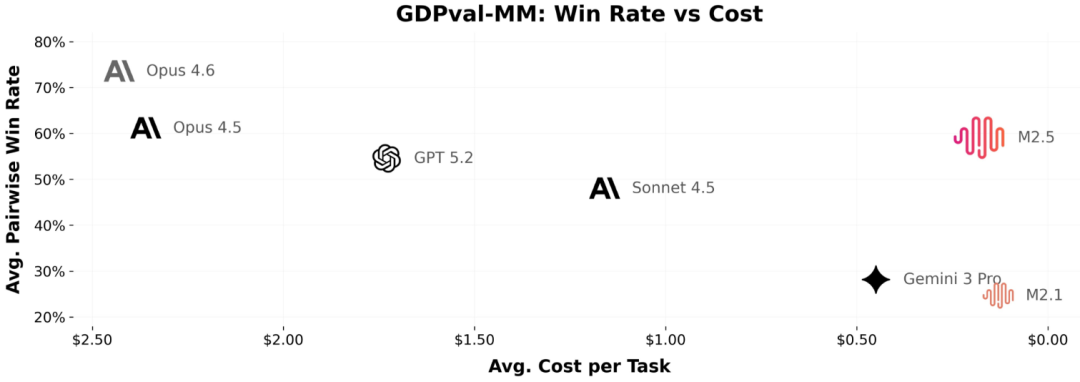
比快更快,比省更省
在 AI 圈子里,通常有一个不可能三角:模型越聪明,通常就越慢,价格也越贵。
但 MiniMax 打破了这个三角。
我们先看速度。
M2.5 的原生推理速度达到了惊人的每秒 100 Token。大部分顶尖模型的速度只有它的一半。
用它来跑复杂的任务,比如那个需要大量思考和调用的 SWE-Bench 测试,它只用了 22.8 分钟就搞定了,比上一代快了整整 37%。
时间就是金钱,在分秒必争的商业环境里,这个速度意味着生产力的直接翻倍。
再看让人跌破眼镜的价格。
官方给出的数据是:每持续运行一小时,只要 1 美元。
如果你不需要极致的 100 Token/秒 的速度,用 50 Token/秒 的标准版,成本还能再砍一半,变成 3 毛钱一小时。
换算成 Token 价格,它的输入成本是每百万 Token 0.3 美元。这简直就是把顶级算力卖出了自来水的价格。
这种成本优势,直接让很多以前想做但不敢做的重型 AI 应用变得可行了。
以前因为太贵而不敢跑的几百万次循环测试,现在可以随便跑;以前因为心疼 Token 而不敢给的长文档,现在可以随便喂。
比如巨吃 Token 的 OpenClaw。
这种极致的性价比,其实是逼出来的。
MiniMax 发现,要让 AI 真正接管复杂任务,它必须得进行大量的思考、搜索和自我修正。所以他们把成本控制做到了极致,为的就是让智能从此不再昂贵。
隐藏在背后的技术核武
M2.5 背后是一套被称为RL Scaling(强化学习规模化)的技术心法。
简单来说,MiniMax 把公司里成千上万个真实的工作场景,都变成了训练 AI 的练功房。
截止到目前,这样的环境已经积累了数十万个。
他们在内部打造了一个叫 Forge 的框架,这个框架就像是一个高效的流水线,能把各种复杂的代理任务和底层的训练引擎无缝对接。
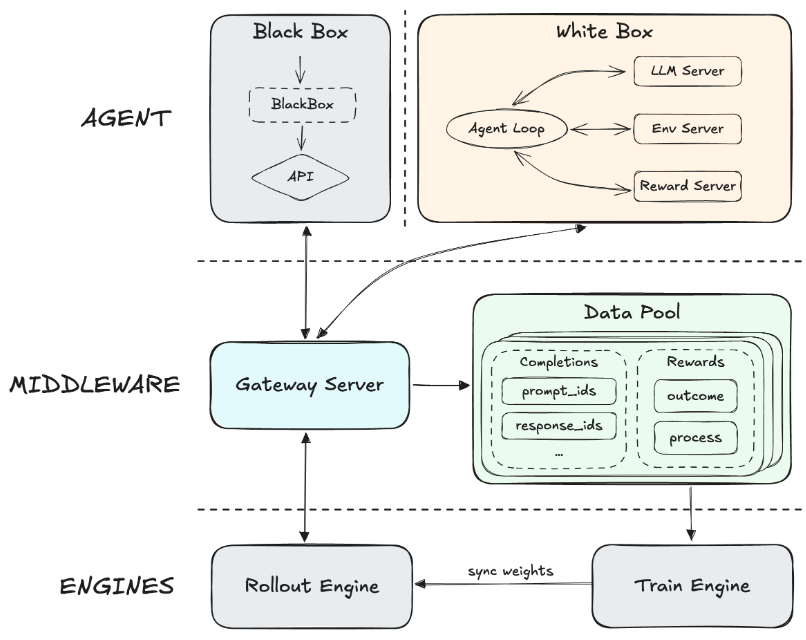
Forge 把训练速度提升了 40 倍。
它引入了一套异步调度策略,让系统在吞吐量和样本质量之间找到了完美的平衡。
同时,为了解决长文本任务中由于前因后果太长而导致 AI 搞不清哪一步做对了的问题,他们引入了过程奖励机制,全程盯着 AI 的每一步操作,随时给出反馈。
在算法层面,他们沿用了那个著名的 CISPO 算法,确保了 MoE(混合专家模型)在训练时的稳定性。
这就像是给一群天才专家装上了协调器,让他们既能各自发挥特长,又能紧密配合,不会出现三个和尚没水喝的情况。
正是这一整套从底层框架到上层算法的深度优化,才支撑起了 M2.5 那令人咋舌的性能和低廉的成本。
MiniMax 2.5 加速了智能的昂贵时代的终结。
当顶级的智力资源变得像水电一样便宜,当 AI 开始像架构师一样思考,像专家一样工作,我们每个人手中的生产力工具都将迎来一次彻底的重塑。
参考资料:
https://www.minimax.io/news/minimax-m25

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献251条内容
已为社区贡献251条内容

所有评论(0)