Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
值得注意的是,OpenAI-o1(Jaech et al., 2024)和DeepSeek-R1(Guo et al., 2025)等模型已利用RL技术(如PPO(Schulman et al., 2017)和GRPO(Shao et al., 2024))通过从经验和反馈中学习来提升逻辑推理和问题解决能力。通过RL,即使仅基于结果奖励进行训练,模型也能学习到复杂的推理能力,包括自我验证(Weng
Abstract
高效获取外部知识和最新信息对于大语言模型(LLM)的有效推理和文本生成至关重要。通过提示具有推理能力的先进LLM在推理过程中使用搜索引擎,往往效果并不理想,因为LLM可能并未完全具备与搜索引擎进行最优交互的能力。本文提出了SEARCH-R1,一种将强化学习(reinforcement learning, RL)扩展至推理框架的方法,使LLM能够在逐步推理过程中自主生成(多次)搜索查询,并实现实时检索。SEARCH-R1通过多轮搜索交互优化LLM的推理轨迹,利用检索token掩码机制实现稳定的RL训练,并采用简单的基于结果的奖励函数。在七个问答数据集上的实验表明,在相同设置下,SEARCH-R1相比各类RAG基线方法,在Qwen2.5-7B上提升了24%,在Qwen2.5-3B上提升了20%。本文还进一步提供了关于RL优化方法、LLM选择以及检索增强推理中响应长度动态变化的实证分析。代码和模型检查点已开源,地址为 https://github.com/PeterGriffinJin/Search-R1。
1 Introduction
然而,将RL应用于搜索与推理场景面临三个关键挑战:
(1)RL框架与稳定性——如何将搜索引擎有效地集成到面向LLM的RL方法中,同时确保优化过程的稳定性,尤其是在引入检索上下文时,这一问题仍不明朗。
(2)多轮交替推理与搜索——理想情况下,LLM应能够进行迭代推理和搜索引擎调用,并根据问题的复杂程度动态调整检索策略。
(3)奖励设计——为搜索和推理任务设计有效的奖励函数仍然是一个根本性挑战,因为尚不清楚简单的基于结果的奖励是否足以引导LLM学习有意义且一致的搜索行为。
为了解决上述挑战,我们提出了SEARCH-R1,一种新颖的RL框架,使LLM能够在自身推理过程中以交替的方式与搜索引擎进行交互。具体而言,SEARCH-R1引入了以下关键创新:
(1)我们将搜索引擎建模为环境的一部分,使得采样的轨迹序列能够将LLM的token生成与搜索引擎检索交替进行。SEARCH-R1兼容多种RL算法,包括PPO和GRPO,并且我们应用了检索token掩码机制以确保优化过程的稳定性。
(2)SEARCH-R1支持多轮检索与推理,当显式触发<search>和</search>标记时调用搜索。检索到的内容被包含在<information>和</information>标记中,而LLM的推理步骤则被包裹在<think>和</think>标记中。最终答案使用<answer>和</answer>标记进行格式化,从而实现结构化的迭代决策。
(3)我们采用了一种简单直接的基于结果的奖励函数,避免了基于过程的奖励所带来的复杂性。我们的实验结果表明,这种极简的奖励设计在搜索与推理场景中是有效的。因此,SEARCH-R1可以被视为DeepSeek-R1 Zero(Guo et al., 2025)的扩展,后者主要关注参数化推理,而SEARCH-R1通过引入搜索增强的RL训练来增强基于检索的决策能力。
总结而言,我们的主要贡献包括以下三个方面:
- 我们的工作分析了相关挑战,并提供了关于实施RL以改进LLM利用搜索引擎结果进行推理的见解和视角。
- 我们提出了SEARCH-R1,一种新颖的RL框架,支持LLM的rollout采样和与搜索引擎的直接优化,包括用于稳定RL训练的检索token掩码、支持复杂任务求解的多轮交替推理与搜索,以及有效的结果奖励函数。
- 我们进行了系统性实验以验证SEARCH-R1的有效性,在相同的实验设置下(如相同的检索模型、训练数据和预训练LLM),两个LLM分别实现了相对于RAG基线平均41%和20%的相对提升。
此外,我们还提供了关于推理与搜索场景下RL的实证分析,包括RL方法的选择、不同LLM的对比以及响应长度的研究。
2 Related Works
2.1 Large Language Models and Retrieva
2.2 Large Language Models and Reinforcement Learning
3 Search-R1
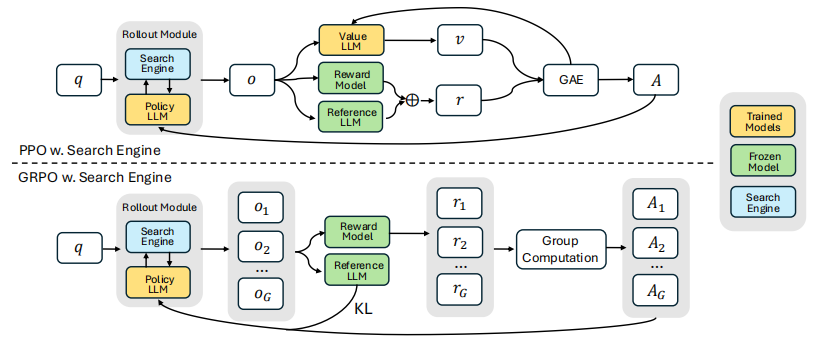
3.1 Reinforcement Learning with a Search Engine
(Policy LLM) 就是你要训练的那个LLM,
就是它的一个冻结副本,训练前复制一份,之后不更新. Rollout 就是模型生成的一整段文本
Loss Masking for Retrieved Tokens. 检索token的损失掩码。
PPO with Search Engine. 结合搜索引擎的PPO。
compute_reward(),答对=1,答错=0token_mask列表,1=LLM生成的token,0=搜索引擎返回的token是 价值函数(Value Function),也叫 Critic模型,它本质上也是一个神经网络(通常就是另一个LLM),用来预测"从当前状态开始,最终能拿到多少奖励"。
# PPO里有两个模型需要训练:
# 1. Policy LLM (π_θ) - Actor - 负责生成文本
policy_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-3B") # lr=1e-6# 2. Value LLM (V_φ) - Critic - 负责预测"这个rollout最终能不能答对"
value_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-3B") # lr=1e-5
# 通常在LLM输出层上面加一个线性层,把hidden state映射成一个标量
value_head = nn.Linear(hidden_size, 1) # 输出一个数值 注意,只是一个值,0或者1.Vϕ 的作用:计算优势 (Advantage)
def compute_advantage_ppo(value_model, value_head, rollout_tokens, final_reward, token_mask): """ PPO用V_φ来计算每个token位置的优势A_t A_t = "实际拿到的奖励" - "V_φ预测的奖励" 如果A_t > 0:说明这步做得比预期好 → 强化 如果A_t < 0:说明这步做得比预期差 → 抑制 """ # V_φ对每个token位置预测一个价值 hidden_states = value_model(rollout_tokens).hidden_states[-1] # [1, seq_len, hidden] values = value_head(hidden_states).squeeze(-1) # [1, seq_len] # values[t] 的含义:模型预测"从第t个token开始,最终拿到的奖励是多少" # 举个具体例子: # rollout: <think> I need ... </think> <search> query </search> <info>...</info> <think>...</think> <answer> X </answer> # values: [0.3, 0.3, ..., 0.3, 0.4, 0.4, ..., 0.0,...,0.0, 0.5, ..., 0.6, 0.8, 0.9] # ↑ 检索内容不重要 ↑ 越接近答案,预测越高 # 实际奖励:只在最后一个token给(答对=1,答错=0) # rewards: [0, 0, ..., 0, 0, 0, ..., 0,..., 0, 0, ..., 0, 0, 1.0] # GAE (Generalized Advantage Estimation) 计算优势 # 简化版本(论文用λ=1, γ=1,相当于蒙特卡洛): advantages = [] for t in range(len(values)): # A_t = R(最终奖励) - V_φ(t)(预测的奖励) A_t = final_reward - values[t] advantages.append(A_t) return advantages, values一个例子。
# 一个rollout的结构: rollout = """ <think> I need to find who wrote 1984. </think> <search> author of novel 1984 </search> <information> George Orwell wrote 1984... </information> <think> The author is George Orwell. </think> <answer> George Orwell </answer> """ # V_ϕ 的输入输出: # 输入:把整个rollout的token序列喂给value_model # 输出:对每一个token位置,输出一个标量值 # 具体来说: tokens = ["<think>", "I", "need", "to", "find", ..., "</think>", "<search>", "author", ..., "</search>", "<information>", "George", "Orwell", ..., "</information>", "<think>", "The", "author", ..., "</think>", "<answer>", "George", "Orwell", "</answer>"] values = [0.25, 0.25, 0.25, 0.25, 0.26, ..., 0.30, 0.32, 0.33, ..., 0.35, # <information>内容被mask,这些值不参与计算 0.50, 0.52, 0.55, ..., 0.60, 0.70, 0.80, 0.85, 0.90] # ↑ 刚开始不确定能不能答对 ↑ 搜到有用信息后,信心增加 ↑ 快要给出正确答案了,值接近1V_ϕ是逐token预测的,不是逐action预测的。但在实际效果上,由于token mask的存在,只有LLM生成的token的优势会被用到,search返回的token直接被mask(全部为0).
PPO vs GRPO 的核心区别
# ===== PPO: 用V_φ(Critic)来估计基线 ===== def ppo_advantage(value_model, rollout, reward): # 需要额外训练一个价值网络 predicted_value = value_model(rollout) # V_φ预测每个位置的价值 advantage = reward - predicted_value # 优势 = 实际 - 预测 # 同时还要更新V_φ本身(让它预测更准) value_loss = (predicted_value - reward) ** 2 # MSE损失 return advantage, value_loss # ===== GRPO: 用组内平均奖励作为基线,不需要V_φ ===== def grpo_advantage(rewards_group): # 不需要额外的模型! # 同一个问题生成5个rollout,奖励分别是 [1, 0, 1, 0, 0] mean = rewards_group.mean() # 0.4 std = rewards_group.std() # 0.55 advantage = (rewards_group - mean) / std # [1.09, -0.73, 1.09, -0.73, -0.73] return advantage ``` ## 为什么PPO需要warm-up而GRPO不需要 ``` PPO训练过程: Step 0-50: V_φ还不准,预测值乱七八糟 → 优势估计不准 → 策略更新方向不对 → 训练不稳定 Step 50-100: V_φ慢慢学会预测 → 优势估计变准 → 训练开始有效 Step 100+: V_φ预测稳定 → 训练稳定上升 GRPO训练过程: Step 0: 直接用组内比较,不需要预训练任何东西 → 马上开始有效训练 Step 100+: 但组内方差可能导致不稳定 → 容易reward collapse
GRPO with Search Engine. 结合搜索引擎的GRPO。
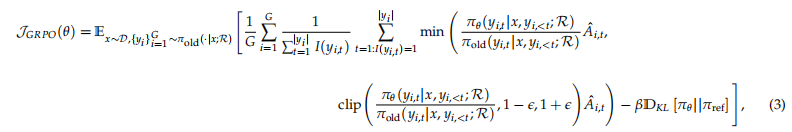
3.2 Generation with Multi-turn Search Engine Calling
在本节中,我们描述了带有交错多轮搜索引擎调用的大语言模型响应生成的推演过程,其形式化表示为:![]()
我们的方法遵循一个迭代框架,其中大语言模型在文本生成和外部搜索引擎查询之间交替进行。具体而言,系统指令引导大语言模型在需要外部检索时,将其搜索查询封装在两个指定的搜索调用标记<search>和</search>之间。在生成序列中检测到这些标记后,系统提取搜索查询,查询搜索引擎,并检索相关结果。检索到的信息随后被封装在特殊的检索标记<information>和</information>内,并附加到正在进行的推演序列[the ongoing rollout sequence]中,作为下一生成步骤的附加上下文。此过程迭代进行,直到满足以下条件之一:(1)达到最大操作次数,或(2)模型生成最终响应,该响应被封装在指定的答案标记<answer>和</answer>之间。完整的工作流程在算法1中概述。
3.3 Training Template
为了训练SEARCH-R1,我们首先制作一个简单的模板[a simple template],指导初始大语言模型遵循我们预定义的指令。如表1所示,该模板以迭代方式将模型的输出结构化为三个部分:首先是推理过程[reasoning process],然后是搜索引擎调用功能[search engine calling function],最后是答案[answer]。我们有意将约束限制在这种结构格式上,避免任何特定于内容的偏见,例如强制执行反思性推理和搜索引擎调用或支持特定的问题解决方法。这确保了模型在强化学习过程中的自然学习动态保持可观察且无偏。
表1:SEARCH-R1的模板。 question 将在训练和推理期间替换为具体问题。
回答给定的问题。每次获得新信息时,你必须首先在<think>和</think>内进行推理。推理后,如果你发现缺少某些知识,可以通过<search>查询</search>调用搜索引擎,它将在<information>和</information>之间返回排名靠前的搜索结果。你可以搜索任意次数。如果你发现不需要进一步的外部知识,可以直接在<answer>和</answer>内提供答案,无需详细说明。例如,<answer>xxx</answer>。问题:question。
3.4 Reward Modeling
奖励函数[reward function]作为主要的训练信号,指导强化学习中的优化过程。为了训练SEARCH-R1,我们采用基于规则的奖励系统,该系统仅包含最终结果奖励,用于评估模型响应的正确性。例如,在事实推理任务中,可以使用基于规则的标准(如精确字符串匹配)来评估正确性:
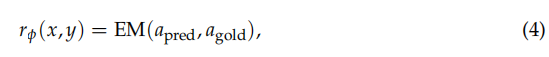
Exact Match (EM)
其中是从响应y中提取的最终答案[the extracted final answer],
是真实答案[the ground truth answer]。与Guo等人(2025)不同,我们不纳入格式奖励[format rewards],因为我们学习到的模型已经表现出很强的结构遵从性。我们将更复杂格式奖励的探索留给未来的工作。此外,我们遵循Guo等人(2025)的做法,避免训练神经奖励模型。这一决定的动机是大语言模型在大规模强化学习中对特定形式奖励的敏感性,以及重新训练这些模型所引入的额外计算成本和复杂性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)