Agent v3:当「能跑」不再够用 —— 一个 Agent 开始真正“像系统”的分水岭(七)
本文承接 Agent v2,在本地 Ollama 环境下实现 Agent v3 的关键跃迁:从“一次性调用模型”转向“流式生成中的实时感知与判断”。通过引入 streaming 推理,Agent 在模型生成过程中监听 token、维护内部状态,并在生成中做出决策,首次具备“过程感知”能力。本文完整记录了最小可运行 Agent v3 的设计思路、核心代码实现及工程取舍,明确区分了 LLM 调用脚本与
在 Agent v2 阶段,我已经解决了一个问题:
它能稳定跑起来了
但很快我发现,这远远不够
从这一篇开始,我真正进入了 Agent v3 阶段:
不是加新功能,而是第一次让 Agent 在生成过程中感知、判断、并决定行为
一、为什么 Agent v3 是一个“分水岭”
在 v2 之前,我做的事情本质上是:
-
调模型
-
拿结果
-
打印输出
即使有 while、有文件、能常驻,本质依然是:
模型是主角,程序只是壳子
而 Agent v3 要解决的问题是:
程序要开始“监听模型”,而不是被动接收结果
这一步,决定了你写的是:
-
❌ LLM 调用脚本
-
✅ Agent 系统
二、Agent v3 的核心变化
从「一次性拿完整回答」 → 「在 token 生成过程中实时判断」
这意味着三件事:
-
必须使用 streaming 推理
-
必须在生成中保存状态
-
必须在生成中做判断,而不是事后分析
三、基础前提:Ollama 本地模型已服务化
在 Agent v3 之前,我已经完成了:
ollama serve
并确认模型可通过 API 调用:
curl http://localhost:11434/api/tags
以及推理接口:
curl http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2:1b",
"prompt": "你是谁?",
"stream": true
}'
此时我第一次直观看到:
模型不是“一次性回答”,而是 token 级别地持续生成
四、Agent v3:最小可运行的「流式感知 Agent」
1️⃣ 目标定义
Agent v3 的目标非常克制:
在模型生成过程中,实时监听 token,并基于内容做判断
不是规划、不是工具、不是 RAG
只做一件事:
“它到底在说什么?”
2️⃣ Agent v3 最小实现代码
新建文件:
vim agent_v3_stream_watch.py
代码如下(可直接运行):
import requests
import json
OLLAMA_URL = "http://localhost:11434/api/generate"
payload = {
"model": "llama3.2:1b",
"prompt": "解释一下什么是 Agent。",
"stream": True
}
response = requests.post(
OLLAMA_URL,
json=payload,
stream=True
)
full_response = ""
triggered = False
print("AI 输出:")
for line in response.iter_lines():
if not line:
continue
data = json.loads(line.decode("utf-8"))
token = data.get("response", "")
done = data.get("done", False)
if token:
print(token, end="", flush=True)
full_response += token
# Agent 的第一条判断规则
if "不知道" in token or "无法" in token:
triggered = True
if done:
break
print("\n--- 完成 ---")
print("\n[Agent 判断结果]")
if triggered:
print("⚠️ 模型存在不确定性")
else:
print("✅ 模型回答稳定")
print("\n[完整回答]")
print(full_response)
运行:
python3 agent_v3_stream_watch.py
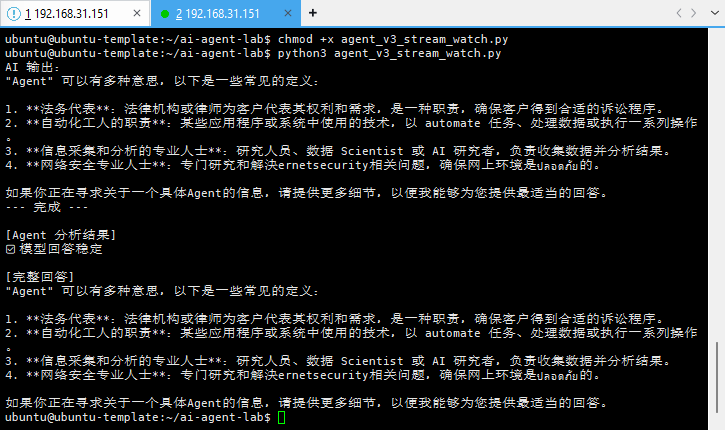
五、这一小段代码,做对了哪几件“本质的事”
1️⃣ 它不是在“等模型说完”
for line in response.iter_lines():
这是 Agent 的生命线。
模型每吐一个 token,Agent 就立刻“听到”
2️⃣ Agent 有了「生成中状态」
full_response += token
这是一个非常关键的转变:
-
没有这个变量,Agent 永远只是“终端输出”
-
有了它,Agent 才开始拥有“内部认知”
3️⃣ 判断发生在“生成中”,而不是“生成后”
if "不知道" in token or "无法" in token:
triggered = True
注意这里判断的是 token,不是完整回答
这意味着:
Agent 在模型“还没说完”时,就已经开始做判断
这是 Agent 和 LLM 应用的本质区
六、为什么有时 Agent 只输出一次就结束?
在实践中,我很快遇到了一个问题:
有时 Agent 只输出一次回答,就直接结束,没有触发后续行为
但这并不是 bug,而是 正确行为。
因为当前逻辑是:
if triggered:
# 执行后续逻辑
else:
# 什么都不做
如果模型第一次回答里 没有出现“不知道 / 无法”
Agent 的判断是:
回答可用,不需要进一步干预
这是一个健康 Agent 必须具备的能力:
知道什么时候该停
七、为什么下一步必须是「记忆」,而不是「更聪明」
在 Agent v3 结束时,我已经非常明确一件事:
没有记忆的 Agent,只是一次性反射系统
所以,下一篇我决定进入:
多轮对话与结构化记忆
核心目标只有一个:
让 Agent 记住“你是谁 + 你刚才说了什么”
而不是:
-
背概念
-
上向量库
-
讲 RAG 名词
八、Agent v3 的阶段性总结
到这一篇为止,我已经完成了:
-
本地模型服务化(Ollama)
-
API 级推理调用
-
Streaming token 监听
-
生成中状态分析
-
生成中判断分支
一句话总结 Agent v3:
这是我第一次写出一个“在思考过程中做决定的程序”
从这一刻开始,从“用模型”,逐步变为 构建智能系统
(风险声明)
本文内容仅为个人学习与实践记录,不构成任何生产环境部署建议
请勿直接照搬本文操作,由此产生的问题需自行承担

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)