
M3KG-RAG:让多模态 RAG 真正“会推理”的关键一步
原创 MindChain.AI2026年1月5日 12:01新加坡📌 一句话总结:本工作提出 M3KG-RAG,一个基于多跳多模态知识图谱的检索增强生成框架,通过模态感知检索与精细化剪枝机制,显著提升多模态大模型在音频、视频与视听联合任务中的推理深度与答案可信度。🔍 背景问题:当前多模态 RAG 在音视频场景中仍面临两类核心瓶颈:1️⃣ 现有多模态知识图谱(MMKG)多为单跳、概念级结构,难以

M3KG-RAG:让多模态 RAG 真正“会推理”的关键一步
原创 MindChain.AI MindChain.AI 2026年1月5日 12:01 新加坡
📌 一句话总结:
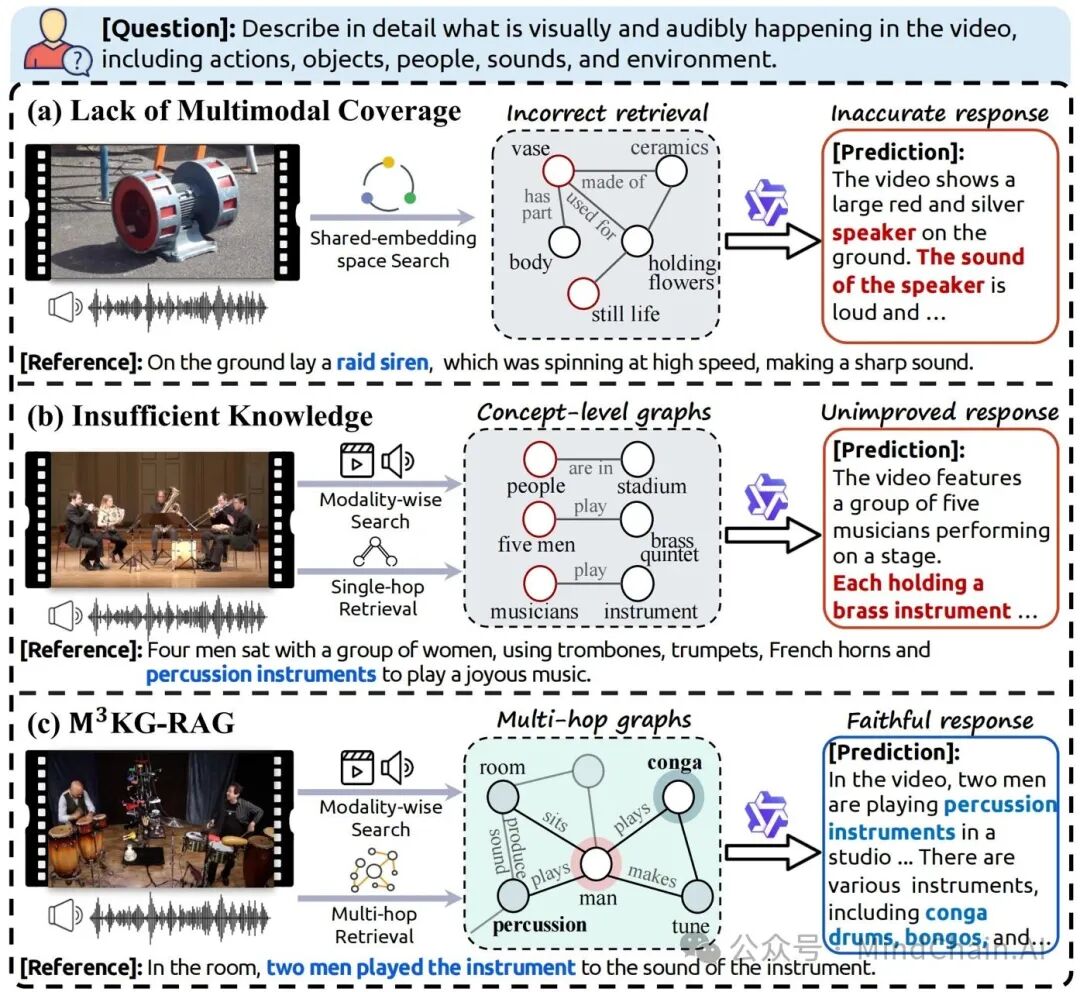
本工作提出 M3KG-RAG,一个基于多跳多模态知识图谱的检索增强生成框架,通过模态感知检索与精细化剪枝机制,显著提升多模态大模型在音频、视频与视听联合任务中的推理深度与答案可信度。
🔍 背景问题:
当前多模态 RAG 在音视频场景中仍面临两类核心瓶颈:
1️⃣ 现有多模态知识图谱(MMKG)多为单跳、概念级结构,难以支撑时序性与因果性的深层推理;
2️⃣ 主流方法依赖共享嵌入空间的相似度检索,容易引入与问题无关或冗余的多模态知识,反而干扰模型生成。
💡 方法简介:
作者提出端到端的 M3KG-RAG 框架,核心由两部分构成:
首先,设计一个轻量级多智能体流水线,从原始多模态语料中自动构建多跳多模态知识图谱(M3KG),通过“上下文增强三元组抽取—知识对齐—语境感知描述精炼”的三阶段流程,将实体、关系与音视频证据紧密绑定;
其次,引入 GRASP(Grounded Retrieval And Selective Pruning) 机制,结合视觉/音频 grounding 模型与轻量 LLM,对检索到的子图进行“是否出现在查询中、是否真正有助于回答问题”的双重筛选,仅保留答案支撑性知识;
在推理阶段,采用模态感知的检索策略,避免跨模态距离失配,形成“模态对齐检索 → 多跳证据聚合 → 精准生成”的完整闭环。
📊 实验结果:
在 Audio-QA、Video-QA 与 Audio-Visual QA 三类基准上,M3KG-RAG 在 VideoLLaMA2、Qwen2.5-Omni 以及 GPT-4o 等模型上均取得显著且稳定的性能提升;
相较 Wikidata、VTKG、M2ConceptBase、VAT-KG 等方法,在回答完整性、信息多样性与事实支撑性上全面占优;
消融实验表明,模态感知检索与 GRASP 剪枝缺一不可,二者协同是性能跃升的关键原因。
📄 论文原文:
https://arxiv.org/abs/2512.20136
✨ 一句话点评:
M3KG-RAG 不再把“多模态 RAG”停留在检索层面的相似匹配,而是通过多跳结构化知识 + grounding 驱动的精细筛选,真正把“能回答”推进到“有证据地回答”,为多模态推理型 RAG 提供了一个极具工程与研究价值的范式。
如何学习AGI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取