YOLO目标检测 一千字解析yolo最初的摸样 模型下载,数据集构建及模型训练代码
yolo目标检测是计算机视觉避不开的一个强大模型,以其强大的可并行能力以及简单的结构甚至可以运用于实时检测。本文会从yolo的基本框架算法逻辑开始讲起,也就是yolov1,直至构建一个可以识别目标的模型项目。
yolo目标检测是计算机视觉避不开的一个强大模型,以其强大的可并行能力以及简单的结构甚至可以运用于实时检测。本文会从yolo的基本框架算法逻辑开始讲起,也就是yolov1,直至构建一个可以识别目标的模型项目。
算法详解
其实yolo的模型架构就是卷积神经网络+全连接层。
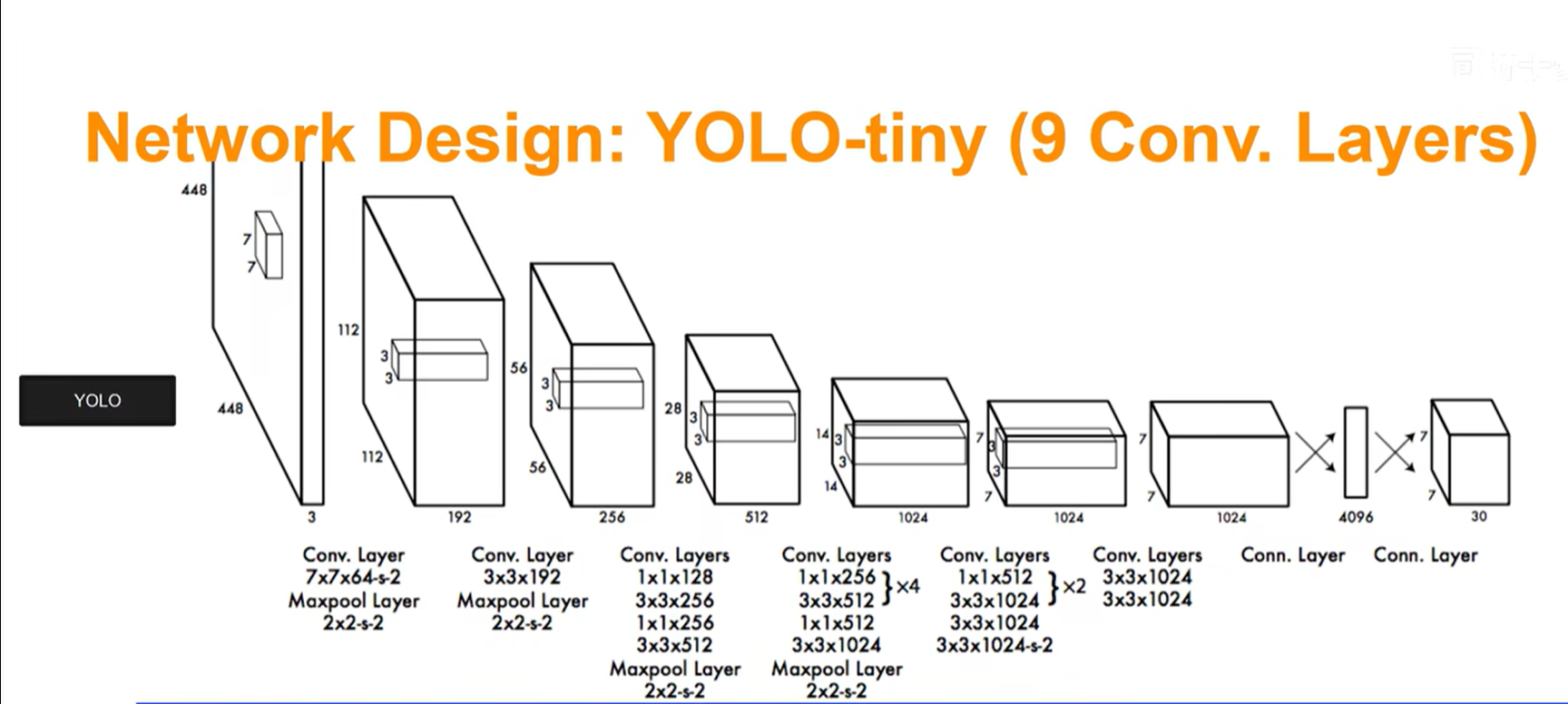
图1
总的来说,就是将输入的图片转换为448×448的尺寸,然后经历一个7×7的卷积核+五个3×3的卷积核后得到一个浓缩后的特征图,再使用全连接层将特征图转换为预测的张量结果输出。这是正向过程也就是预测,前面的卷积层都还好,都是个惯用套路,我们主要来看看全连接层干了什么,为什么输出7×7×30维度的张量。
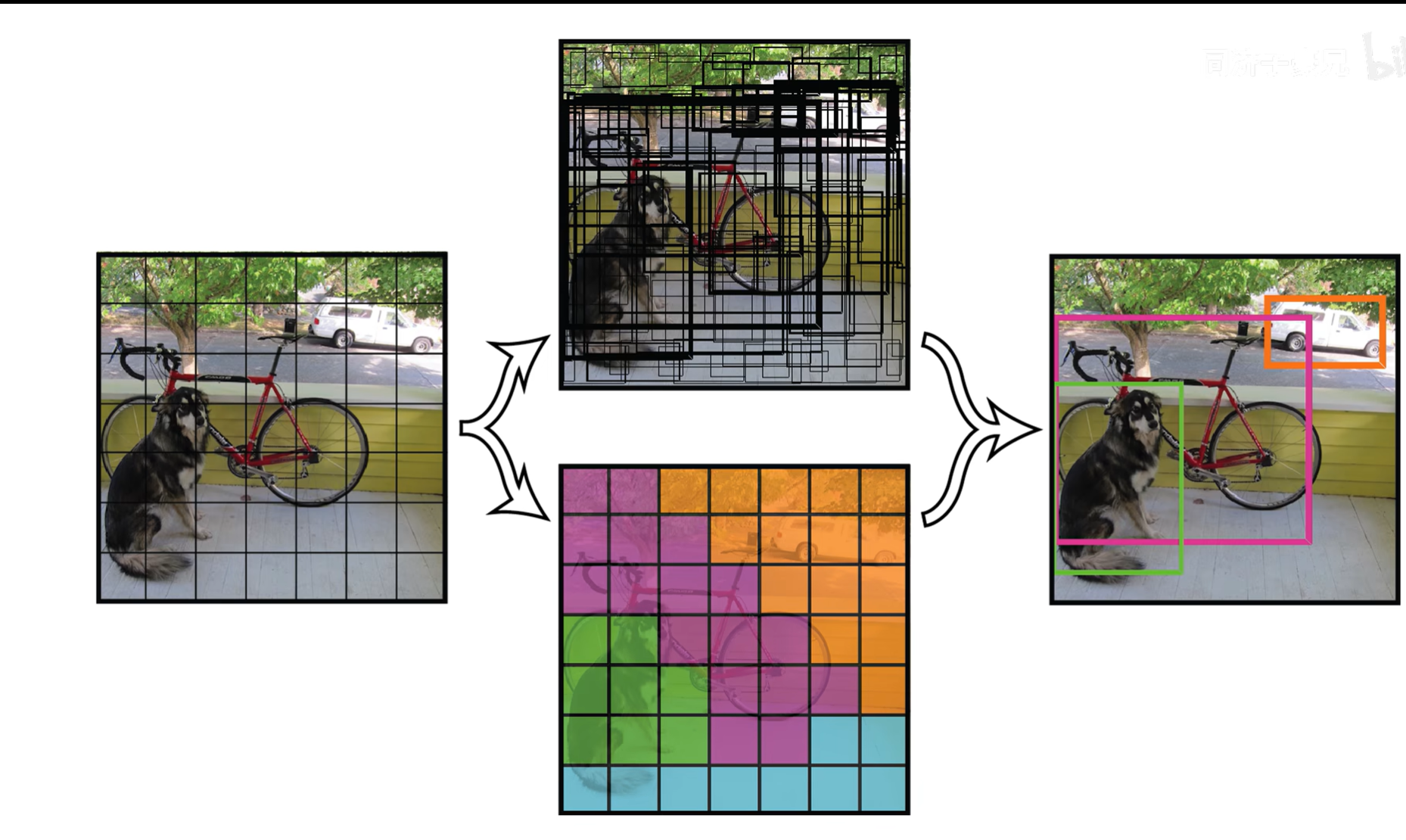
图2
对于每一张图而言,yolo的实现过程如下:首先,使用一个S×S尺寸的方格划分整个图片数据;对于每个划分的小方格,都预测B个方框,每个方框以五个数据记录下来,也就是:
[x, y, w, h, c] 其含义就是框的左顶点x、y坐标,框的宽、高,以及检测到的目标的置信度。一般而言,我们设置S为7以及B为2,也就是图片分为7×7共49个小方格,每个小方格预测出2个框,每个框以一个1×5的向量形式表示,经过汇总也就是最终输出7×7*(2×1×5)的张量。正如图2的上方的结果图所示,以框的粗细代表置信度的高低,画完所有的预测框后就变成了那样。当然这还没完,在我们训练完后模型会存储训练集的种类信息,比如说训练集的数据有20个种类,我们需要判断每个小方格代表的是哪个种类,也就是输出一个1×20维度的向量,每个位置代表是这二十个种类的其中一类的条件概率。也就是图2下方的图所示,如果将条件概率最高的可视化出来,比如紫色代表自行车,绿色代表狗,橙色代表汽车,蓝色代表没找到,最终结果就如图。然后将两个过程的张量相拼接,就得到了最终的输出结果7×7×(10+20)的张量,也就是最终的输出类别结果。简而言之,通过卷积之后的特征图我们获得小方格的种类信息,在小方格中制作预测框确定实际范围和置信度。
值得一提的是,每个预测框的大小并没有限制。在制作预测框的过程中,只要目标中心(由卷积层的感受野得出)在小方格之中,那么预测框就可以以目标中心向外一直延伸。它或许超出了小方格,跑到了别的小方格区域;或许一直延伸到图片边缘,然后被边界卡住;又或许几个预测框重叠了大半,这也是接下来的优化方向。
对于这么多个预测框,不可能全是我们最终想要的三个框,我们就必须要做取舍。首先,过滤掉那些置信度太低的,那些只是我们为了检测而创造出来凑数的。然后,就是非极大值抑制(NMS)。对于每个种类,我们先将所有的预测框以概率高低排列(需要声明的是虽然预测框本身不包含种类信息只有置信度,但是其所处的小方格包含),然后从高到低将这些预测框的重叠范围进行两两对比,并且设置一个最大重叠阈值,如果重叠区域超过了大预测框尺寸×重叠阈值,就去掉小的预测框,反之留下,以此类推。最终,就过滤成了三个预测框。
以上就是yolov1的最经典的实现部分。虽然yolo也在一步步更新,效率有了极大的提升,但是并没有像v1这种从无到有的提出,基本上是加入了一些其他模块像注意力机制、锚框等等,也就不多说了。
训练集构建
数据集标注这个网站可以做数据集标注,还挺简单的,跟着文字提示就能完成,就是有点废人。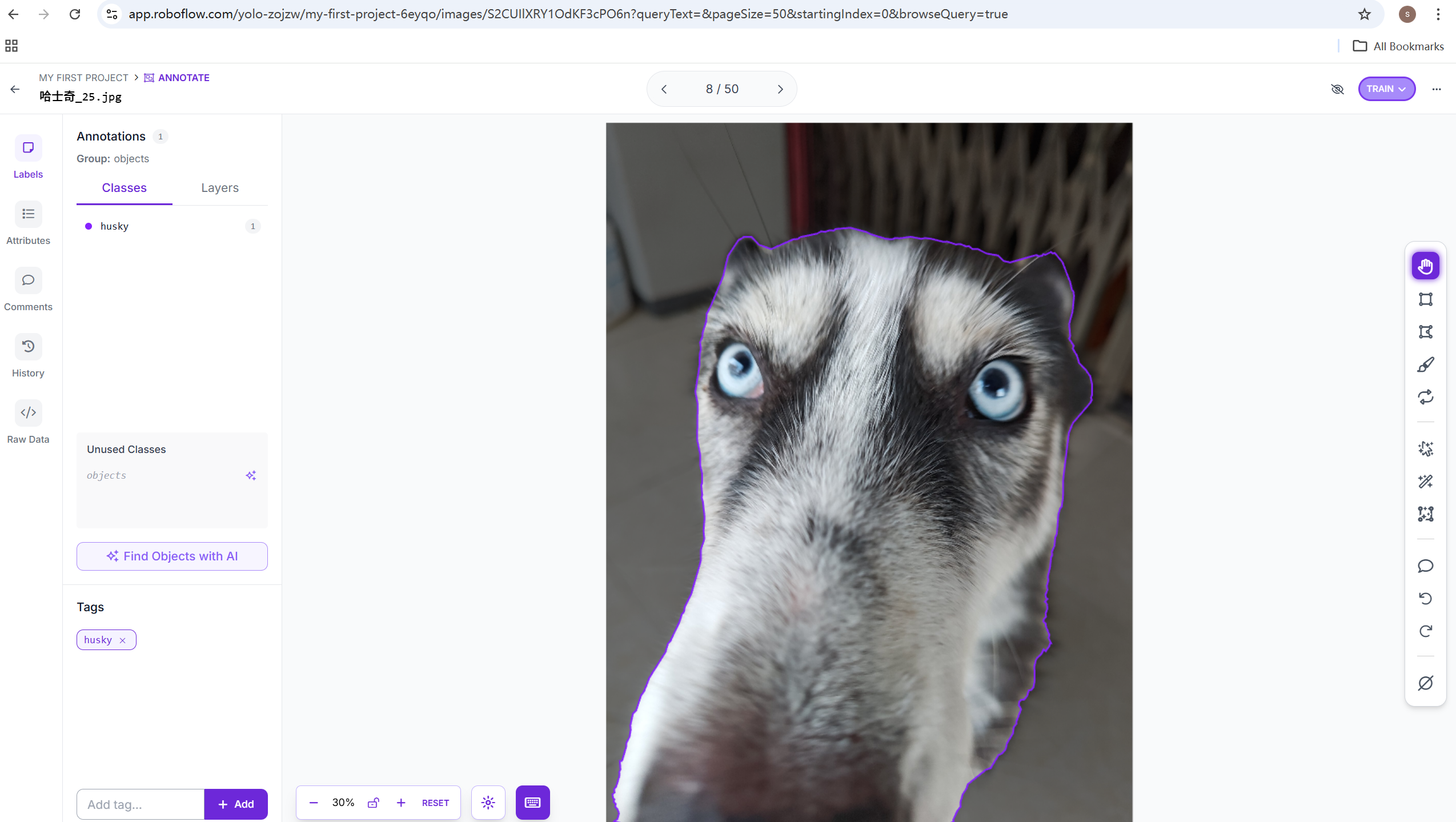
里面有智能选择只有点目标就能自动画框,算是效率比较高的了。
下载及训练代码
如果使用的是我推荐的网站,记得调整训练集验证集的比例,最终目录如下: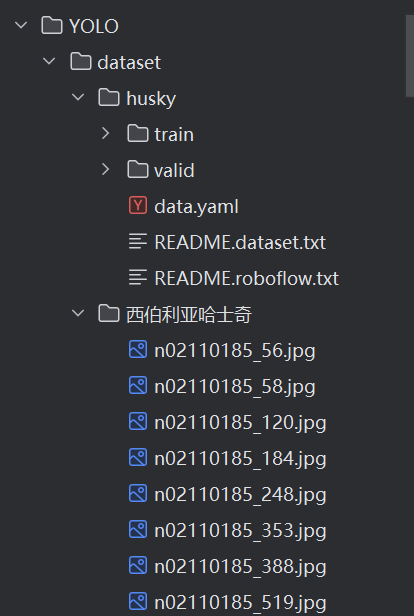
确保这个目录后,就可以训练模型了:
from ultralytics import YOLO
import torch.multiprocessing as mp
def main():
model = YOLO("yolov8n.pt")
model.train(
data="dataset/husky/data.yaml",
model="yolov8n.pt",
epochs=100,
batch=16,
imgsz=640,
mosaic=0.5,
erasing=0.1,
auto_augment=None,
amp=True,
workers=2,
plots=False
)
if __name__ == "__main__":
mp.freeze_support() # Windows 必须
main()
其中workers参数与显存有关,配置好的可以往上调。
还有训练完后的测试代码:
import cv2
from ultralytics import YOLO
model = YOLO("./runs/detect/train12/weights/best.pt")
# 将标注后的文件保存下来
def save_detection(source, out_path="output.mp4"):
cap = cv2.VideoCapture(source)
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
writer = cv2.VideoWriter(out_path, fourcc, fps, (w, h))
for result in model.predict(
source=source,
device=0,
conf=0.25,
iou=0.5,
stream=True # 关键!
):
frame = result.plot()
writer.write(frame)
cap.release()
writer.release()
# 打印检测的物品信息
def print_image_items(root):
results = model(root)
r = results[0]
# 打印每个检测框的信息
for box in r.boxes:
cls_id = int(box.cls)
conf = float(box.conf)
xyxy = box.xyxy.tolist()
print(f"类别ID: {cls_id}, 置信度: {conf:.2f}, 框: {xyxy}")
if __name__ == '__main__':
# print_image_items(r"D:\PythonProject\Pytorch\data\classification_data\train\万能梗\n02096051_7.jpg")
save_detection(r"D:\PythonProject\Pytorch\data\common\哈士奇.mp4")最后,我们来看看效果吧:
成果展示

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)