告别“人多力量大”误区:看AI团队如何通过奖励设计实现协作韧性
Arxiv文章解读:本研究提出了一种基于偏好学习的混合奖励框架,用于提升多智能体系统的协作韧性。通过定义资源消耗、公平性等4个集体福祉指标,量化干扰下系统的恢复能力,并利用调和平均计算全局韧性分数。创新性地从排序轨迹中学习奖励函数,在混合动机场景中平衡个体与集体利益。实验表明,该方法能在不牺牲个体性能的前提下,显著提升系统抗干扰能力,减少资源滥用。这一框架为构建可持续、鲁棒的智能协作系统提供了新思
告别“人多力量大”误区:看AI团队如何通过奖励设计实现协作韧性
Arxiv文章解读第1期
随着大模型和智能体技术的爆发,多智能体协作已成为解决复杂任务的关键路径,但一个被忽视的痛点是:团队协作往往导致“平庸化”,甚至引发资源滥用。论文不仅指出了混合动机系统中“盲目共识”的陷阱,更提出了一套基于偏好学习的混合奖励框架。它能在不牺牲个体性能的前提下,显著提升系统在干扰下的鲁棒性。在AI系统加速落地的当下,这项研究对于构建真正可持续、抗干扰的智能团队具有极高的参考价值。
- 论文《Learning Reward Functions for Cooperative Resilience in Multi-Agent Systems》:聚焦混合动机多智能体系统中的“协作弹性”问题,通过引入混合奖励策略(平衡个体目标与系统弹性),在不牺牲任务性能的前提下显著提升了系统在干扰下的鲁棒性,并有效减少了资源过度使用等灾难性后果,利用偏好学习从排序轨迹中自动提取奖励函数增加了方法的实用性与新颖性。
论文:Learning Reward Functions for Cooperative Resilience in Multi-Agent Systems
基本信息
- 资讯条目:🔬 多智能体系统中的协作弹性奖励函数学习
- 论文链接:https://arxiv.org/abs/2601.22292
- 作者:Chacon-Chamorro, Manuela,Giraldo, Luis Felipe,Quijano, Nicanor
- 发表时间:2026.1.29
- 发表来源:arXiv
- 由哥伦比亚洛斯安第斯大学团队完成,获谷歌和 DeepMind 资助,核心聚焦合作韧性这一多智能体强化学习(MARL)中未被充分探索的属性,提出了从排名轨迹中学习奖励函数的全新框架,解决混合动机场景下智能体个体目标与集体功能平衡的问题,相关成果已提交至《IEEE Transactions on Artificial Intelligence》
这篇论文在解决什么难题
这篇论文聚焦的核心问题是:Learning Reward Functions for Cooperative Resilience in Multi-Agent Systems 所在方向在真实应用中面临“多人协作不一定更好”的困境。在多智能体系统里,团队成员虽然可以互相交流,但并不天然意味着能把最专业成员的能力放大。作者关心的是:当任务变复杂、信息不完整、意见存在冲突时,团队是否会因为追求一致而牺牲质量。结合资讯中的观察(新颖框架:提出从排序轨迹中学习奖励函数的新框架,由协作弹性指标引导;三种奖励策略:;传统个人奖励;弹性推断奖励;混合策略(平衡两者);实验验证:在一套社会困境环境中训练智能体,使用三种奖励参数化方法:),研究把问题从“能不能协作”推进到“能不能高质量协作”,这直接关系到多智能体系统是否具备工程可用性与规模化落地价值。
它最有价值的创新点
创新类型:框架创新。该工作最关键的创新并不是简单提升一个分数,而是把过去容易被忽略的协作机制拆开分析,明确区分“识别专家”与“利用专家”这两个层次,并通过行为与结果共同验证瓶颈所在。作者还把团队规模、信息提示策略、交互模式放到同一框架下比较,让研究结论不仅可解释,而且可复用到后续系统设计。
通俗解释:很多系统以前只看“最后答得对不对”,这篇论文进一步问“为什么会错、错在团队哪一环”,相当于给多智能体协作做了一次“体检报告”,告诉大家问题不是没有专家,而是专家意见在协作中被稀释了。
核心方法详解
方法可以理解为一个分阶段的协作诊断流程。
第一步,作者先构建由不同能力智能体组成的团队,并设置多种信息条件(不标注专家、标注专家、强化提示专家),让系统在同一任务上反复运行,从而隔离“是否知道谁是专家”这一因素。
第二步,记录每轮交互内容与最终决策结果,同时衡量团队输出与最佳个体输出之间的差距,观察协作是否带来真正增益。
第三步,进行团队规模扩展实验,比较小团队与大团队在专家意见利用率上的变化,判断是否存在“规模越大越平均化”的现象。
第四步,引入对抗性或噪声条件,测试系统在追求共识时的鲁棒性和性能损失之间的权衡。最终得到的不是单点结论,而是一套可迁移的分析框架:先识别协作结构,再定位信息流断点,最后用可解释指标评估优化方向。
第五步,研究把对话片段和最终结果绑定分析,定位“专家意见被稀释”的具体节点,解释为什么团队看起来讨论充分却无法得到最优答案。
第六步,在不同团队组合、不同任务复杂度上重复实验,检查结论是否稳定,避免偶然样本导致偏差。这个流程通俗来看,就是先看团队是否听懂专家,再看团队是否愿意执行专家意见,最后确认这种执行机制能否在更多场景中持续有效。因此,这一方法不仅给出结果,更提供了可操作的协作改进路径:先改信息流,再改决策汇聚规则,最后做跨场景回归验证。
方法流程图与图解: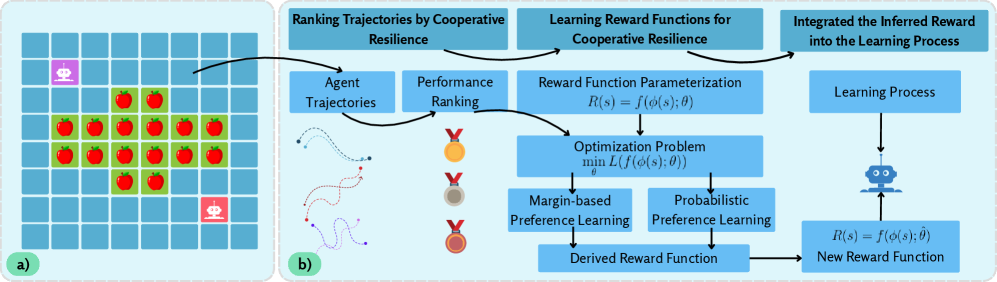
- 图 1:(a) 本研究使用的混合动机环境。两个智能体在 8x8 网格中与一棵有 16 个苹果的中央苹果树交互。(b) 我们提出的奖励学习流水线概述。该图展示了从数据收集到策略学习的完整循环。
- 图1解读:图中展示了混合动机的8x8网格环境和包含数据收集、奖励推断及策略学习的完整流水线。读者应关注中央苹果树的资源设置以及奖励函数如何从排序轨迹中推断得出,这为理解协作弹性的学习框架奠定了基础。
这篇文章的核心方法是从按合作韧性排序的智能体轨迹中,学习能提升多智能体系统合作韧性的奖励函数,解决混合动机场景下(个体利益与集体利益冲突)智能体“只顾自己、破坏集体”的问题,最终让智能体在面对干扰时既保个体性能,又能维持集体协作。
方法整体分两步核心操作:先给智能体的行为轨迹打分并排序,再用偏好学习算法从排序结果中学习出贴合“合作韧性”的奖励函数;全程结合数学公式量化计算,保证方法的严谨性和可落地性,下面一步步拆解。
首先把多智能体的交互环境抽象成马尔可夫博弈(多智能体版的马尔可夫决策过程),用数学元组表示为:
⟨S,A,P,R,γ⟩\langle S, A, P, R, \gamma \rangle⟨S,A,P,R,γ⟩
- SSS:环境的全局状态空间(比如网格世界里苹果的位置、智能体的坐标);
- A=A1×A2×⋯×AnA=A_1 \times A_2 \times \dots \times A_nA=A1×A2×⋯×An:所有智能体的联合动作空间(每个智能体的动作组合,比如“智能体1采摘、智能体2移动”);
- PPP:状态转移函数(做某个联合动作后,环境从状态sss变到s′s's′的概率);
- RRR:原始奖励函数(传统方法里的奖励,比如摘到苹果+1,只关注个体利益);
- γ\gammaγ:折扣因子(权衡即时奖励和未来奖励,0<γ\gammaγ≤1)。
每个智能体有自己的策略πi(ai∣s)\pi_i(a_i|s)πi(ai∣s)(在状态sss下选动作aia_iai的概率),智能体按策略交互会产生行为轨迹τ\tauτ,轨迹的数学定义是:
τ=(s0,a0,s1,a1,…,sT)\tau = (s_0, a_0, s_1, a_1, \dots, s_T)τ=(s0,a0,s1,a1,…,sT)
表示从初始状态s0s_0s0开始,执行联合动作a0a_0a0到s1s_1s1,直到时间步TTT的完整行为序列(比如智能体500步的采摘、移动过程)。
传统方法的问题是:原始奖励RRR只关注个体收益,会导致智能体过度采摘资源、破坏集体,面对干扰(比如苹果突然减少)时系统崩溃——这篇文章的方法就是重新学一个韧性奖励函数R^\hat{R}R^,替换/融合原始奖励,引导智能体的行为。
第一步:给轨迹打“合作韧性分”并排序
核心思路:用“合作韧性指标”量化每条轨迹的集体表现,分数越高,轨迹的合作韧性越好,再按分数给所有轨迹排个序。这一步是整个方法的基础,因为后续的奖励学习,都是以“轨迹的好坏排序”为依据。
1.1 定义4个集体福祉指标,衡量轨迹表现
文章选了4个能反映“集体好不好”的指标(可根据场景替换),每个指标都计算无干扰的基线场景和有干扰的破坏场景下的数值,对比看干扰对集体的影响:
- 累计消耗量:每个智能体的资源采摘总量(反映个体性能);
- 资源可用性:环境中剩余的资源总量(反映集体资源可持续性);
- 消耗基尼系数:智能体之间的采摘差距(反映公平性,系数越小越公平);
- 饥饿指数:智能体连续采摘的时间间隔(反映资源获取的稳定性)。
用Ik(t)I_k(t)Ik(t)表示 第kkk个指标在时间步ttt 的数值,上标baseline表示无干扰,disrupted表示有干扰,即Ikbaseline(t)I_k^{\text{baseline}}(t)Ikbaseline(t)(基线)、Ikdisrupted(t)I_k^{\text{disrupted}}(t)Ikdisrupted(t)(破坏)。
1.2 确定干扰的关键时间点
对每个指标,先定3个核心时间点(干扰是人为设定的,比如在第500步移除部分苹果):
- tdt_dtd:干扰开始时间(所有指标的tdt_dtd相同,比如500步);
- tf=argmint≥tdIkdisrupted(t)t_f = \arg\min_{t\geq t_d} I_k^{\text{disrupted}}(t)tf=argmint≥tdIkdisrupted(t):指标最差时间(干扰后,第kkk个指标跌到最小值的时间,不同指标的tft_ftf不同);
- trt_rtr:恢复结束时间(干扰后,第kkk个指标停止恢复的时间,单干扰为轨迹最后一步,多干扰为下一次干扰前)。
再定义两个时间差:
Δtf=tf−td,Δtr=tr−tf\Delta t_f = t_f - t_d, \quad \Delta t_r = t_r - t_fΔtf=tf−td,Δtr=tr−tf
分别表示“从干扰开始到指标最差的时长”“从指标最差到恢复结束的时长”。
1.3 计算单个指标的韧性分数ρk\rho_kρk
先通过积分计算失败轮廓和恢复轮廓,量化“干扰下指标的下跌程度”和“恢复程度”:
FailureProfilek=∫tdtfIkdisrupted(t)Ikbaseline(t)dt\text{FailureProfile}_k = \int_{t_d}^{t_f} \frac{I_k^{\text{disrupted}}(t)}{I_k^{\text{baseline}}(t)} dtFailureProfilek=∫tdtfIkbaseline(t)Ikdisrupted(t)dt
RecoveryProfilek=∫tftrIkdisrupted(t)Ikbaseline(t)dt\text{RecoveryProfile}_k = \int_{t_f}^{t_r} \frac{I_k^{\text{disrupted}}(t)}{I_k^{\text{baseline}}(t)} dtRecoveryProfilek=∫tftrIkbaseline(t)Ikdisrupted(t)dt
- 比值Ikdisrupted(t)Ikbaseline(t)\frac{I_k^{\text{disrupted}}(t)}{I_k^{\text{baseline}}(t)}Ikbaseline(t)Ikdisrupted(t):表示破坏场景的指标值相对于基线的比例,越接近1,受干扰影响越小;
- 积分的含义:把时间步的比例加总,反映整个失败/恢复阶段的指标表现。
再用失败、恢复轮廓计算第kkk个指标的韧性分数ρk\rho_kρk:
ρk=td+FailureProfilek⋅Δtf+RecoveryProfilek⋅Δtrtd+Δtf+Δtr\rho_k = \frac{t_d + \text{FailureProfile}_k \cdot \Delta t_f + \text{RecoveryProfile}_k \cdot \Delta t_r}{t_d + \Delta t_f + \Delta t_r}ρk=td+Δtf+Δtrtd+FailureProfilek⋅Δtf+RecoveryProfilek⋅Δtr
ρk\rho_kρk的取值越接近1,说明该指标在干扰下的表现越接近无干扰的基线,韧性越好;小于1表示指标受损,大于1表示恢复后表现更好。
1.4 计算轨迹的全局韧性分数ρ(τ)\rho(\tau)ρ(τ)
4个指标各有一个ρk\rho_kρk,用调和平均把它们融合成整条轨迹τ\tauτ的全局合作韧性分数(调和平均的优点是:惩罚单个指标的低分,避免“一个指标好、其他指标差”的轨迹被误判为高韧性):
ρ(τ)=(1K∑k=1K1ρk)−1\rho(\tau) = \left( \frac{1}{K} \sum_{k=1}^K \frac{1}{\rho_k} \right)^{-1}ρ(τ)=(K1k=1∑Kρk1)−1
其中K=4K=4K=4(指标数量)。
1.5 轨迹排序:定义偏好关系
假设有一批轨迹D={τ1,τ2,…,τN}\mathcal{D} = \{ \tau_1, \tau_2, \dots, \tau_N \}D={τ1,τ2,…,τN},每个轨迹都算出了ρ(τ)\rho(\tau)ρ(τ),按分数从高到低排序,定义偏好关系:
τi≻τj⇔ρ(τi)>ρ(τj)\tau_i \succ \tau_j \quad \Leftrightarrow \quad \rho(\tau_i) > \rho(\tau_j)τi≻τj⇔ρ(τi)>ρ(τj)
表示“轨迹τi\tau_iτi的合作韧性比τj\tau_jτj好,我们更偏好τi\tau_iτi的行为”。
比如轨迹A的ρ=0.95\rho=0.95ρ=0.95,轨迹B的ρ=0.7\rho=0.7ρ=0.7,则A≻BA \succ BA≻B,后续学习的目标就是:让智能体的行为能产生更多像A这样的高韧性轨迹。
第二步:从轨迹偏好中学习韧性奖励函数R^\hat{R}R^
核心思路:以“轨迹的偏好排序”为训练数据,用两种偏好学习算法,学习一个奖励函数R^:S→R\hat{R}: S \to \mathbb{R}R^:S→R(输入环境状态,输出韧性奖励值),让高偏好轨迹的累计韧性奖励大于低偏好轨迹——这样智能体为了获取更多奖励,自然会做出高韧性的行为。
2.1 先确定奖励函数的3种参数化形式
奖励函数需要用数学形式表示(参数化),文章提供了3种可选形式,兼顾可解释性和表达能力,核心都是基于状态的特征ϕ(s):S→Rn\phi(s): S \to \mathbb{R}^nϕ(s):S→Rn(nnn为特征维度,比如状态sss里的苹果数、智能体距离等):
- 手工特征线性模型(高可解释性):R^(s;θ)=ϕ(s)⊤w+b\hat{R}(s; \theta) = \phi(s)^\top w + bR^(s;θ)=ϕ(s)⊤w+b,θ={w,b}\theta=\{w,b\}θ={w,b}是待学参数(www为特征权重,bbb为偏置),ϕ(s)\phi(s)ϕ(s)是专家手工设计的韧性相关特征(比如资源剩余量、智能体间距离);
- 原始状态线性模型(免特征工程):R^(s;θ)=s⊤w+b\hat{R}(s; \theta) = s^\top w + bR^(s;θ)=s⊤w+b,直接把原始状态sss当作特征,不用手工设计,适合特征难定义的场景;
- 神经网络模型(强表达能力):R^(s;θ)\hat{R}(s; \theta)R^(s;θ),θ\thetaθ为神经网络的权重,能捕捉状态和奖励之间的非线性关系,适合复杂场景(但数据需求大、可解释性低)。
2.2 方法1:基于边际的偏好学习(MPL)
最直观的偏好学习方法,核心目标:让高偏好轨迹的累计韧性奖励,比低偏好轨迹至少大一个边际值δij>0\delta_{ij}>0δij>0,边际值可以是固定值(比如δij=1\delta_{ij}=1δij=1),也可以是两个轨迹的韧性分数差(δij=∣ρ(τi)−ρ(τj)∣\delta_{ij}=|\rho(\tau_i)-\rho(\tau_j)|δij=∣ρ(τi)−ρ(τj)∣),更贴合实际差距。
数学目标函数
对于所有偏好对(τi≻τj)(\tau_i \succ \tau_j)(τi≻τj),优化参数θ\thetaθ,最小化“未达到边际要求”的损失:
minθ∑(τi≻τj)max(0,δij−(∑s∈τiR^(s;θ)−∑s∈τjR^(s;θ)))\min_{\theta} \sum_{(\tau_i \succ \tau_j)} \max\left( 0, \delta_{ij} - \left( \sum_{s \in \tau_i} \hat{R}(s; \theta) - \sum_{s \in \tau_j} \hat{R}(s; \theta) \right) \right)θmin(τi≻τj)∑max
0,δij−
s∈τi∑R^(s;θ)−s∈τj∑R^(s;θ)
- ∑s∈τR^(s;θ)\sum_{s \in \tau} \hat{R}(s; \theta)∑s∈τR^(s;θ):轨迹τ\tauτ的累计韧性奖励(轨迹中所有状态的奖励之和);
- 损失项的含义:如果高偏好轨迹的累计奖励 - 低偏好轨迹的累计奖励 ≥ δij\delta_{ij}δij,则损失为0(满足要求);否则损失为“缺口值”,需要优化参数让缺口变小。
关键特点
- 若奖励函数是线性的(前两种参数化形式),目标函数是凸函数,能找到全局最优解,训练稳定;
- 若用神经网络(非线性),目标函数非凸,需加正则化避免过拟合;
- 文章还设计了3种轨迹对采样策略(随机、相邻排名、混合),提升训练效率。
2.3 方法2:概率式偏好学习(PPL)
更柔和的偏好学习方法,核心目标:定义“高偏好轨迹被选择的概率”,通过最大化这个概率的对数似然,学习参数θ\thetaθ,梯度更平滑,适合处理有噪声的轨迹排序。
定义偏好概率
对于偏好对(τi≻τj)(\tau_i \succ \tau_j)(τi≻τj),定义τi\tau_iτi被判定为“更优”的概率为:
p(τi≻τj;θ)=exp(∑s∈τiR^(s;θ))exp(∑s∈τiR^(s;θ))+exp(∑s∈τjR^(s;θ))p(\tau_i \succ \tau_j; \theta) = \frac{\exp\left( \sum_{s \in \tau_i} \hat{R}(s; \theta) \right)}{\exp\left( \sum_{s \in \tau_i} \hat{R}(s; \theta) \right) + \exp\left( \sum_{s \in \tau_j} \hat{R}(s; \theta) \right)}p(τi≻τj;θ)=exp(∑s∈τiR^(s;θ))+exp(∑s∈τjR^(s;θ))exp(∑s∈τiR^(s;θ))
这个公式的逻辑是:累计奖励差距越大,高偏好轨迹被判定为最优的概率越接近1,符合直觉。
数学目标函数
通过最小化负对数似然优化参数θ\thetaθ(等价于最大化偏好概率):
minθ−∑(τi≻τj)log(p(τi≻τj;θ))\min_{\theta} -\sum_{(\tau_i \succ \tau_j)} \log\left( p(\tau_i \succ \tau_j; \theta) \right)θmin−(τi≻τj)∑log(p(τi≻τj;θ))
展开后为:
minθ−∑(τi≻τj)log(exp(∑s∈τiR^(s;θ))exp(∑s∈τiR^(s;θ))+exp(∑s∈τjR^(s;θ)))\min_{\theta} -\sum_{(\tau_i \succ \tau_j)} \log\left( \frac{\exp\left( \sum_{s \in \tau_i} \hat{R}(s; \theta) \right)}{\exp\left( \sum_{s \in \tau_i} \hat{R}(s; \theta) \right) + \exp\left( \sum_{s \in \tau_j} \hat{R}(s; \theta) \right)} \right)θmin−(τi≻τj)∑log
exp(∑s∈τiR^(s;θ))+exp(∑s∈τjR^(s;θ))exp(∑s∈τiR^(s;θ))
关键特点
- 线性奖励函数下,目标函数仍为凸函数,可直接用凸优化求解;
- 梯度平滑,训练时收敛更稳定,对轨迹排序的微小噪声鲁棒;
- 缺点是包含指数运算,计算量比MPL稍大。
2.4 最终的奖励策略:融合个体与集体(混合策略)
学习出韧性奖励R^\hat{R}R^后,文章没有直接替换原始个体奖励RindR_{\text{ind}}Rind,而是设计了混合奖励策略(实验证明效果最好),兼顾个体性能和集体韧性:
Rhybrid=α⋅R^+(1−α)⋅RindR_{\text{hybrid}} = \alpha \cdot \hat{R} + (1-\alpha) \cdot R_{\text{ind}}Rhybrid=α⋅R^+(1−α)⋅Rind
其中α∈[0,1]\alpha \in [0,1]α∈[0,1]是权重系数,平衡韧性奖励和个体奖励(比如α=0.5\alpha=0.5α=0.5,各占一半)。
相比纯韧性奖励(α=1\alpha=1α=1),混合奖励能保证智能体在提升集体韧性的同时,不损失个体的基础任务性能(比如摘苹果的效率),避免智能体“为了保集体,完全不做个体动作”的保守行为。
方法的整体流程
- 让智能体在混合动机环境中交互,产生一批行为轨迹;
- 计算每条轨迹的4个集体福祉指标,通过积分和调和平均得到合作韧性分数,并按分数给轨迹排序,得到偏好对;
- 选择奖励函数的参数化形式(线性/神经网络),用边际式/概率式偏好学习算法,从偏好对中学习韧性奖励函数R^\hat{R}R^;
- 将韧性奖励R^\hat{R}R^与原始个体奖励融合,得到混合奖励,用于训练智能体的策略;
- 训练后的智能体,在面对干扰时能平衡个体利益和集体利益,提升系统的合作韧性。
实验与应用价值
在一套包含8x8网格苹果树采集等典型社会困境环境中进行对比实验。测试变量包括三种奖励策略(传统个人、弹性推断、混合)、三种奖励参数化方法(线性、手工特征、神经网络)。重点评估了系统在面临干扰时的鲁棒性、任务完成度及避免资源枯竭等灾难性结果的能力。
| 观察维度 | 设置/指标 | 结果/结论 |
|---|---|---|
| 实验设计 | 多任务+多团队配置 | 围绕协作有效性进行多条件对比 |
| 对比基线 | 单专家 vs 多智能体团队 | 观察团队是否真正超过最优个体 |
| 结果趋势 | 性能与鲁棒性指标 | 在一套包含8x8网格苹果树采集等典型社会困境环境中进行对比实验。测试变量… |
| 价值维度 | 解读 |
|---|---|
| 领域贡献 | 填补了多智能体强化学习在“协作弹性”属性研究上的空白,证明了通过精巧的奖励设计(特别是混合策略)可以有效引导智能体在面对不确定性和干扰时维持合作,为构建在动态不确定环境中可持续运作的鲁棒多智能体系统提供了重要的理论依据和方法论参考。 |
| 通俗理解 | 这就好比教一个团队协作,以前只告诉大家“各自把手头活干好”,现在的发明则是同时教大家“既要干好活,又要互相帮衬,遇到意外别慌,别把公用资源抢光”。研究表明,这种把“个人表现”和“团队抗压能力”结合起来的考核方式,能让团队在遇到突发状况时更稳,不会因为内耗而散伙。 |
| 与日常生活关系 | 类似于管理公共资源(如渔场或水库)。如果只奖励渔民多捕鱼(个人奖励),鱼群可能会枯竭(灾难后果)。该研究的方法相当于制定了一种新规则,既鼓励捕鱼(完成任务),又奖励那些在环境变化时能保护鱼苗、避免过度捕捞的行为(混合策略),确保社区长期有鱼可吃,实现可持续生存。 |
这项研究标志着多智能体系统从单纯追求“协作效率”向追求“协作韧性”的重要范式转变。它证明了优秀的团队不在于全员一致,而在于如何平衡个体利益与集体生存,这对构建自动驾驶、金融交易等高风险场景的AI系统具有巨大的落地价值。对于普通读者而言,这也是一面镜子:无论是公司管理还是公共资源利用,单一的个人激励往往会导致“公地悲剧”。只有设计好兼顾短期KPI与长期韧性的“奖励机制”,才能避免团队内耗,让个体与集体在动荡中实现共赢。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)