一次“千问点奶茶”失败背后的 Agent 架构拆解:问题不在大模型
一次使用千问点奶茶失败的经历,引发了我对 Agent 系统完整链路的重新审视。本文不是从模型能力出发,而是从真实执行失败的现象入手,拆解了一次 Agent 任务从输入理解、规划、工具调用到业务系统执行的完整过程,并分析了失败通常发生在哪些环节。在此基础上,进一步梳理了 Agent 场景下性能与稳定性测试的关注重点,说明为何很多问题并不出在大模型本身,而是在链路设计与失败处理机制上。
前言:
今天千问发红包了,0.1元喝奶茶,爆单了!太火爆了,试了几遍都下不了单。

一开始还以为是模型理解能力的问题——
是不是没听懂我想买什么?
是不是参数解析错了?
但在反复观察和对比之后,发现:
这类失败,往往发生在模型“已经想明白之后”,而不是之前。
刚好最近也在做Agent 项目的开发测试:
项目后续是要做性能和稳定性测试,所有把 Agent 的完整链路重新梳理了一遍。
这篇文章不是吐槽千问,也不是评测模型能力,
而是想搞清楚:
一次 Agent 任务,从“我想点杯奶茶”到“系统执行失败”,
中间到底经历了什么?问题又通常卡在哪一层?
一、先把“失败”说清楚,而不是一句“下不了单”
先把现象说具体,否则后面所有分析都是空的。
大致是这样:
-
我明确说了品类
-
Agent 能给出合理的候选结果或说明
-
但在“真正执行下单”这一步:
-
要么支付失败
-
要么提示系统繁忙
-
要么直接失败结束
-
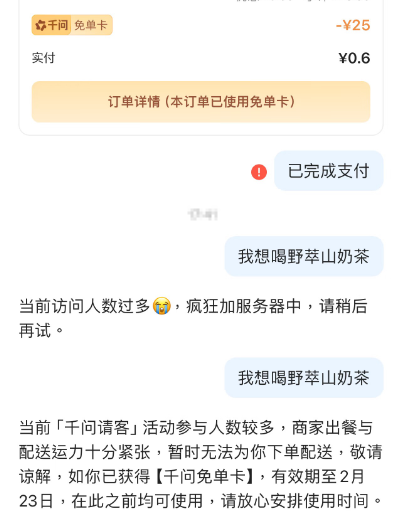
所以说这应该是:
-
这不是“听不懂人话”
-
也不像是模型胡说八道
-
更像是:执行链路中某一层扛不住了
这也是很多 Agent 系统常见的“错觉型问题”:
用户直观感受是 “AI 不聪明”,
但其实问题往往可能是 “系统不稳”。
二、先梳理 Agent 链路
在传统系统里,性能测试一般是:
-
压接口
-
看 RT / TPS
-
查 CPU / 内存
但是在 Agent 系统中,这套思路显然不够。
因为很多“慢”“失败”“卡死”的问题,根本不发生在模型推理那一刻,
而是发生在:
-
规划步骤被拉长
-
工具调用被放大
-
失败处理走了错误路径
所以,与其说“模型慢不慢”,
不如先确定:
一次 Agent 任务,从用户输入到最终结果,中间到底经历了什么?
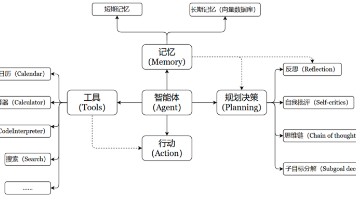
三、一条可复用的 Agent 完整链路(结合点奶茶场景)
经过查阅资料,结合多个 Agent 场景(问答、流程执行、业务操作),把 Agent 的一次完整任务拆成 6 个阶段。
1、输入理解阶段:需求有没有被放大?
点奶茶场景下:
-
用户输入往往不是结构化的
-
可能一句话里包含多个约束(品牌 / 口味 / 地址)
这里的工程细节是:
-
输入越模糊,后续规划步数越多
-
规划步数越多,对下游系统的压力越大
这一步本身不慢,但它决定了后面会不会变复杂。
2、 意图解析与规划阶段:要走多少步?
在点奶茶这种场景里,Agent 通常要做的并不是“一步到位”,而是:
-
找商家
-
找商品
-
校验配送
-
决定是否可以下单
这里的细节不是模型“会不会想”,是:
-
一次任务被拆成了多少子步骤
-
有没有条件分支
-
有没有反复规划
对性能来说,规划深度比模型速度更重要。
3、工具选择与参数生成:从“想法”到“接口”
这一层是很多失败的高发区。
在点奶茶场景中:
-
“野萃山”最终要变成 shop_id
-
“少冰”要变成规格参数
-
地址要映射成系统能识别的字段
任何一个参数对不上,
都会导致:
-
接口调用失败
-
Agent 误以为是“业务失败”,开始重试
这里失败,看起来像模型问题,其实是接口契约问题。
4、工具执行与业务系统交互:真正的瓶颈层
这是我这次最明显的感受。
在多次失败中,我注意到一个现象:
-
Agent 给出决策并不慢
-
真正卡住的是:
-
下单接口
-
运力判断
-
系统限流
-
也就是说:
模型已经“想好了”,但系统执行不了。
这也是为什么很多 Agent 在高峰期“看起来很笨”,
其实是 下游系统不允许继续执行。
5、失败反馈与二次规划:稳不稳看这里
这里是 Agent 和传统系统最大的区别。
关键不在于“有没有失败”,而在于:
-
失败后是直接结束?
-
还是尝试换路径?
-
有没有重试上限?
在点奶茶这种涉及真实资源的场景里:
-
无限重试是危险的
-
盲目换方案也可能触发风控
这一步直接决定了系统是否“可控”。
6、结果反馈与用户感知:体验往往出在最后一步
最后是:
-
用户不知道现在是“慢”还是“失败”
-
不知道还能不能继续
-
不知道该不该重试
很多“AI 不好用”的评价,其实在这里。
四、基于链路的 Agent 性能测试视角
梳理完这条链路后,再看性能测试。
传统性能测试关注:
-
RT
-
TPS
-
资源使用率
Agent 场景下更重要的是:
1、 任务级指标
-
任务完成率
-
平均任务步数
-
失败是否可恢复
2、链路级指标
-
哪一阶段最慢
-
哪一阶段失败最多
-
失败是否被放大
3、 行为级风险
-
是否出现死循环
-
是否出现无意义重试
-
是否触发不可逆操作
这些指标,
和你用的是哪家模型关系不大,
和链路设计关系很大。
五、小结:为什么问题不在大模型
回到开始的现象——
千问点奶茶失败。
综上,这并不是一个“模型不聪明”的问题,而是一个:
Agent + 业务系统链路稳定性问题。
模型只是其中一环,
真正决定体验的,是整条链路是否可控、可观测、可兜底。
所以在后续做 Agent 项目性能测试时,
应该优先从链路和失败模式入手,而不是先去调模型参数。
下一篇感觉要梳理这个问题才行:Agent 性能测试:压什么才有意义

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)