ollama v0.15.5正式发布:全新Qwen3-Coder-Next与GLM-OCR模型登场,上下游功能全面进化
是对开发者体验和模型性能的双重升级版本。双新模型接入:Qwen3-Coder-Next、GLM-OCRSub-agent 支持与参数化启动机制完善显存分级上下文长度智能设定GLM-4.7-Flash 实验性引擎支持登录与错误提示体验优化跨平台支持与稳定性增强这一版本不仅提升了大规模模型在多任务环境下的执行效率,也进一步降低了开发者的使用门槛。无论是代码生成、文档识别还是多代理协作,ollama v
一、版本发布概览
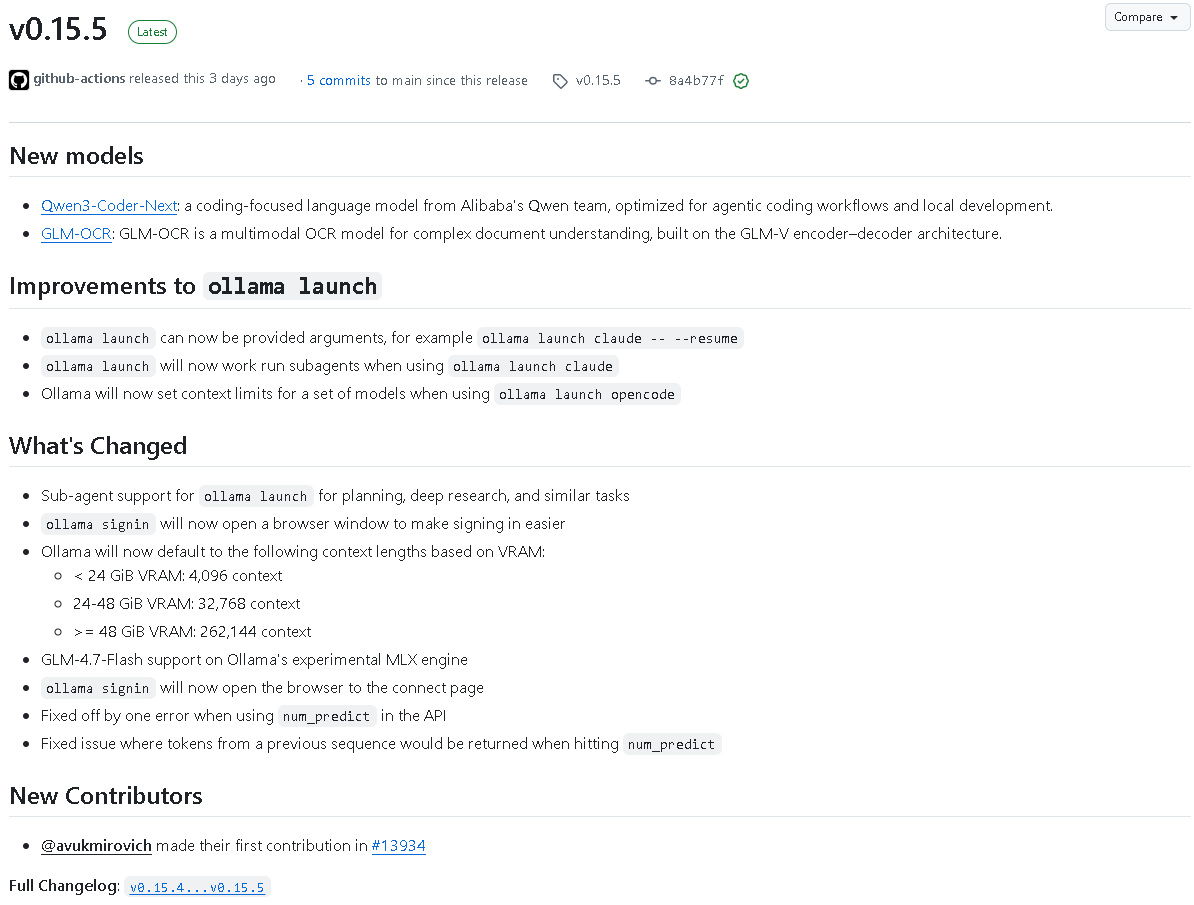
2026年2月6日,ollama 推出了 v0.15.5 最新版本。本次更新在模型阵容、性能优化和开发者体验多个层面上都有实质性突破,尤其是对 多模型协作、上下文管理 和 本地开发流程 的深度优化,为开发者提供更高效、更智能的调用体验。
二、新增模型:Qwen3-Coder-Next与GLM-OCR
1. Qwen3-Coder-Next
这是来自阿里巴巴 Qwen 团队的全新编码型语言模型,专注于 智能代码生成与本地开发代理工作流。该模型在代码理解、自动补全和多步骤代理执行方面进行了全面优化,特别适用于需要持续上下文调用的开发者场景。
2. GLM-OCR
GLM-OCR 是一款 多模态文档理解 OCR 模型,基于 GLM-V 编码-解码架构构建,聚焦于复杂文档的图像—文本解析任务。该模型的引入使 ollama 能够支持更复杂的视觉+文本混合输入,适配文档、表单等应用。
三、ollama launch 功能改进
1. 支持参数传入
现在可在启动时直接提供模型参数,例如:
ollama launch claude -- --resume
允许用户在启动模型时追加自定义指令或运行参数。
2. 支持子代理运行
在执行 ollama launch claude 等命令时,系统可运行 子代理(sub-agent),支持多层规划、深度研究与协同任务执行。
3. 优化上下文自动设定
当使用 ollama launch opencode 时,系统将根据模型类型自动设置上下文上限,避免代码模型调用时内存溢出或性能下降。
四、VRAM分级上下文长度新机制
根据显存容量,ollama 将默认采用分级上下文长度:
| VRAM容量 | 默认上下文长度 |
|---|---|
| < 24 GiB | 4,096 context |
| 24–48 GiB | 32,768 context |
| ≥ 48 GiB | 262,144 context |
这一机制确保了不同硬件环境下的最优模型加载性能,充分利用 GPU 资源。
五、核心引擎与交互改进
1. GLM-4.7-Flash 支持
在实验性 MLX 引擎中新增对 GLM-4.7-Flash 的支持,进一步提高模型推理速度与压缩能力。
2. ollama signin 浏览器登录优化
执行 ollama signin 时将自动打开浏览器窗口,简化登录流程并直接跳转至连接页面。
六、错误与稳定性修复
- 修复
num_predict参数出现的 off-by-one 错误,保证预测的 Token 数量准确。 - 修复上一次序列的 Token 误返回问题。
- 改进加载请求的错误提示,使问题更易定位。
- 优化
chatPrompt机制以减少不必要的 Token 化调用,提高响应效率。 - 修复当批次中序列被替换时计算结果错误的情况,保证推理稳定性。
- 新增对远程模型的错误提示,使远程调用过程更清晰易调试。
七、任务执行与脚本更新
- 默认为 Qwen3-Next 与 LFM 模型设置
parallel=1,保证推理序列一致性。 - 增强 macOS 平台支持,
install.sh脚本现可在 macOS 系统中直接执行。 ollama launch命令进一步优化执行逻辑,改进参数和上下文管理机制。- 云端模型在
opencode模式下可自动设置上下文限制,提高云端并行调用稳定性。
八、版本总结
ollama v0.15.5 是对开发者体验和模型性能的双重升级版本。核心亮点包括:
- 双新模型接入:Qwen3-Coder-Next、GLM-OCR
- Sub-agent 支持与参数化启动机制完善
- 显存分级上下文长度智能设定
- GLM-4.7-Flash 实验性引擎支持
- 登录与错误提示体验优化
- 跨平台支持与稳定性增强
这一版本不仅提升了大规模模型在多任务环境下的执行效率,也进一步降低了开发者的使用门槛。无论是代码生成、文档识别还是多代理协作,ollama v0.15.5 都为智能化的本地开发提供了强劲的动力。
结语:
代码地址:github.com/ollama/ollama
ollama v0.15.5 是一次面向开发者生态的核心进化。从模型到体验,它体现了开源 LLM 平台的持续迭代与深度融合趋势,为构建更强大的智能开发环境奠定了坚实基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)