2026最新版SpringAiAlibaba教程
关于SpringAiAliabba使用
前言
我认为现在的就业形势作为一个普通的Java程序员要做到找到一个合适的工作不仅仅局限于前后端分离,微服务这一块了,Ai发展这么快速的情况下我们更应该学会去使用Ai,把Ai融入到我们的程序当中,扩展一下我们的技术面,并且现在的许多公司例如美团开始要求后端不仅仅只是干后端,也需要掌握前端,光靠一个前后端工程师再这个社会是立足不了的,SpringAiAlibaba是现在主流的在SpringAi的基础之上去进行扩展的一个框架,这篇文章也能够很好的帮大家进行初步的使用以及认识
1. 环境准备
1.1 引入依赖 (Maven)
请在 pom.xml 中添加以下依赖。注意版本号需根据官方最新发布的 Release 或 RC 版本进行调整。
XML
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-agent-framework</artifactId>
<version>1.1.0.0-RC2</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.1.0.0-RC2</version>
</dependency>
</dependencies>1.2 配置文件 (application.yml)
配置 API Key 及默认模型参数。此处演示如何通过兼容模式接入 DeepSeek。
YAML
spring:
ai:
dashscope:
api-key: ${AI_API_KEY} # 建议从环境变量或配置中心读取
chat:
options:
# 指定默认模型,例如 deepseek-v3, qwen-plus 等
model: deepseek-v3
# 若使用 OpenAI 兼容协议的模型(如 DeepSeek),需配置 base-url
agent:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
# 注意:如果是使用标准 OpenAI 依赖,需将上述配置中的 'dashscope' 替换为 'openai'1.3 基础配置类
虽然 Starter 会自动配置,但显式定义 DashScopeApi Bean 可提供更灵活的控制。
Java
@Configuration
public class AiConfig {
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
@Bean
public DashScopeApi dashScopeApi() {
return DashScopeApi.builder().apiKey(apiKey).build();
}
}2. 核心组件开发
Spring AI 提供了两个核心交互接口:ChatModel(底层接口)和 ChatClient(高层流式 API)。
2.1 方式一:使用 ChatModel (底层接口)
ChatModel 直接封装了具体大模型(如 OpenAiChatModel、DashScopeChatModel)的原生 API,适合需要精细化控制模型行为的场景。
接口特性:
- 同步调用 (
call):阻塞式响应,等待模型生成全部内容后一次性返回。 - 流式调用 (
stream):基于 Reactor 的 Flux 响应,实现类似打字机的逐字显示效果。
Java
@RestController
@RequestMapping("/hello")
public class ChatController {
@Resource
private ChatModel chatModel;
/**
* 同步阻塞式对话
*/
@GetMapping("/doChat")
public String hello(@RequestParam(value = "msg", defaultValue = "你是谁") String message) {
return chatModel.call(message);
}
/**
* 流式响应 (Server-Sent Events)
*/
@GetMapping("/stream")
public Flux<String> stream(@RequestParam(value = "msg", defaultValue = "你是谁") String message) {
return chatModel.stream(message);
}
}2.2 方式二:使用 ChatClient (推荐)
ChatClient 是基于 ChatModel 封装的 Fluent API(流式编程风格),支持链式调用,能够更优雅地构建 Prompt(包含 User Message 和 System Message)以及处理回调。
2.2.1 全局配置 ChatClient
建议在配置类中通过 Builder 构建全局 Bean,避免在 Controller 中重复实例化。
Java
@Configuration
public class ChatClientConfig {
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
// 这里可以在 build 前添加默认的 System Prompt 或 Advisor
return builder.build();
}
}2.2.2 业务调用
Java
@RestController
@RequestMapping("/ai")
public class ChatClientController {
@Autowired
private ChatClient chatClient;
@GetMapping("/generate")
public String generation(@RequestParam("userInput") String userInput) {
return this.chatClient.prompt()
.user(userInput)
.call() // 发起请求
.content(); // 获取文本内容
}
@GetMapping("/stream")
public Flux<String> streamGeneration(@RequestParam("userInput") String userInput) {
return this.chatClient.prompt()
.user(userInput)
.stream() // 发起流式请求
.content();
}
}2.3 组件对比小结
|
特性 |
ChatModel |
ChatClient |
|
定位 |
底层驱动接口 |
高级应用接口 |
|
构建方式 |
手动构建 Prompt 对象 |
链式 Fluent API |
|
易用性 |
较低,需处理底层细节 |
高,代码可读性强 |
|
底层关系 |
基础实现 |
基于 ChatModel 包装 |
结论:在常规业务开发中,推荐优先使用 ChatClient。
3. 实时通信机制:SSE vs WebSocket
在 AI 对话场景中,流式输出通常使用 SSE (Server-Sent Events)。
3.1 SSE 核心思想
SSE 允许服务器向客户端主动推送数据。客户端发起一个长连接 HTTP 请求,服务器保持连接打开,并随时发送数据流。
3.2 SSE 与 WebSocket 对比
|
维度 |
SSE (Server-Sent Events) |
WebSocket |
|
通信方向 |
单向 (Server -> Client) |
双向全双工 (Server <-> Client) |
|
协议 |
基于 HTTP |
独立协议 (ws://) |
|
复杂度 |
低,浏览器原生支持 |
较高,需握手与心跳管理 |
|
适用场景 |
AI 回复、股票行情、日志推送 |
在线游戏、即时聊天室 |
为什么 AI 问答通常用 SSE?
因为 AI 问答主要是一次提问(Request),多次连续响应(Response Stream),符合 SSE 的单向推送特性,且无需建立复杂的 WebSocket 连接。
4. 高级实战:多模型并存与动态调用
在实际生产中,可能需要同时支持 DeepSeek(高性价比)和 Qwen-Plus(高质量)等多个模型。
4.1 方案一:基于 ChatModel 的多 Bean 配置
Java
@Configuration
public class MultiModelConfig {
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
@Bean("deepseekModel")
public ChatModel deepseekModel() {
return DashScopeChatModel.builder()
.dashScopeApi(DashScopeApi.builder().apiKey(apiKey).build())
.defaultOptions(DashScopeChatOptions.builder().model("deepseek-v3").build())
.build();
}
@Bean("qwenModel")
public ChatModel qwenModel() {
return DashScopeChatModel.builder()
.dashScopeApi(DashScopeApi.builder().apiKey(apiKey).build())
.defaultOptions(DashScopeChatOptions.builder().model("qwen-plus").build())
.build();
}
}Controller 调用:
Java
@RestController
@RequestMapping("/ai/model")
public class MultiModelController {
@Resource(name = "deepseekModel")
private ChatModel deepseek;
@Resource(name = "qwenModel")
private ChatModel qwen;
@GetMapping("/deepseek")
public Flux<String> chatDeepseek(@RequestParam("msg") String msg) {
return deepseek.stream(msg);
}
}4.2 方案二:基于 ChatClient 的多 Bean 配置 (推荐)
使用 ChatClient 可以在构建时绑定底层的 ChatModel 并覆盖默认配置。
Java
@Configuration
public class MultiClientConfig {
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
/**
* 构建 DeepSeek 专用 Client
*/
@Bean("deepseekClient")
public ChatClient deepseekClient() {
// 构建底层 Model
DashScopeChatModel model = DashScopeChatModel.builder()
.dashScopeApi(DashScopeApi.builder().apiKey(apiKey).build())
.build();
// 绑定 Model 并指定 Options
return ChatClient.builder(model)
.defaultOptions(ChatOptions.builder().model("deepseek-v3").build())
.build();
}
/**
* 构建 Qwen 专用 Client
*/
@Bean("qwenClient")
public ChatClient qwenClient() {
DashScopeChatModel model = DashScopeChatModel.builder()
.dashScopeApi(DashScopeApi.builder().apiKey(apiKey).build())
.build();
return ChatClient.builder(model)
.defaultOptions(ChatOptions.builder().model("qwen-plus").build())
.build();
}
}Controller 调用:
Java
@RestController
@RequestMapping("/ai/client")
public class MultiClientController {
@Resource(name = "deepseekClient")
private ChatClient deepseekClient;
@Resource(name = "qwenClient")
private ChatClient qwenClient;
@GetMapping("/deepseek")
public Flux<String> deepseek(@RequestParam("userInput") String userInput) {
return deepseekClient.prompt().user(userInput).stream().content();
}
@GetMapping("/qwen")
public Flux<String> qwen(@RequestParam("userInput") String userInput) {
return qwenClient.prompt().user(userInput).stream().content();
}
}5.理解 Prompt 中的消息角色 (Message Roles)
在构建基于 LLM 的应用时,上下文由不同“角色”的消息组成,每种角色承担着特定的职责:
1. 核心角色
- System Role (系统角色)
-
- 定义:对话的“导演”或“设定集”。
- 作用:指导 AI 的行为模式、语气风格及边界规则(例如:“你是一个严谨的法律顾问”或“只回答代码相关问题”)。
- User Role (用户角色)
-
- 定义:对话的“发起者”。
- 作用:代表最终用户的输入(Prompt),是 AI 进行推理和生成的直接依据。
- Assistant Role (助手角色)
-
- 定义:AI 的“回复”或“历史记忆”。
- 作用:既是 AI 对用户的响应,也是后续对话的上下文依据。它还可能包含Function Call Request(工具调用请求),表明 AI 意图执行特定操作(如联网搜索、数据库查询)。
2. 高级角色
- Tool/Function Role (工具角色)
-
- 定义:外部世界的“反馈者”。
- 作用:当 Assistant 发起工具调用后,代码执行该工具,并将结果(通常是 JSON 数据)通过此角色回传给 AI,以便 AI 整合信息生成最终答案。
6.代码实战:构建一个垂直领域的“旅游助手”
以下示例基于 Spring AI 框架,展示如何通过 System Prompt 锁定 AI 的行为边界。
场景描述
我们需要创建一个 AI 接口,它只能回答旅游相关的问题,对于无关问题(如编程、数学等)需要拒绝回答。
方式 1:使用 ChatClient (Fluent API)
适用场景:快速开发,代码简洁,只需关注返回的文本内容。
Java
@GetMapping("/ai/prompt")
public Flux<String> chatWithClient(@RequestParam("userInput") String userInput) {
return chatClient.prompt()
// 设定系统提示词 (System Prompt)
.system("你是一个专业的旅游指南助手。请仅回答与旅游、景点、美食攻略相关的问题;如果用户询问其他话题,请礼貌拒绝。")
.user(userInput)
.stream()
.content(); // 直接提取文本内容流
}返回结果:直接返回字符串流(String),前端接收后即可打字机式展示。
方式 2:使用 ChatModel (Low-level API)
适用场景:需要更精细的控制,或者需要获取元数据(Token 使用量、生成元数据)。
Java
@GetMapping("/ai/modelPrompt")
public Flux<ChatResponse> chatWithModel(@RequestParam("userInput") String userInput){
// 1. 构建消息对象
SystemMessage systemMsg = new SystemMessage("你是一个旅游指南助手,跟旅游无关的问题不用解答");
UserMessage userMsg = new UserMessage(userInput);
// 2. 封装 Prompt (可包含多个消息历史)
Prompt prompt = new Prompt(List.of(systemMsg, userMsg));
// 3. 调用模型流式接口
return chatModel.stream(prompt);
}返回结果:返回 Flux<ChatResponse>。前端收到的将是 JSON 对象流,包含以下丰富信息:
result: 生成的文本内容。metadata: Token 消耗统计 (Usage)。generationMetadata: 结束原因 (Finish Reason),例如是否因为触发了敏感词或长度限制而停止。
7.提示词模板
在内部,ChatClient 使用 PromptTemplate 类来处理用户和系统文本,并使用给定的 TemplateRenderer 实现将变量替换为运行时提供的值。 默认情况下,Spring AI 使用 StTemplateRenderer 实现,它基于 Terence Parr 开发的开源 StringTemplate 引擎。
Spring AI 还提供了一个 NoOpTemplateRenderer,用于不需要模板处理的情况。
如果您想使用不同的模板引擎,可以直接向 ChatClient 提供 TemplateRenderer 接口的自定义实现。您也可以继续使用默认的 StTemplateRenderer,但使用自定义配置。
@GetMapping("/ai/promptTemplate")
public Flux<String> promptTemplate(@RequestParam("topic") String topic, @RequestParam("output_format")String output_format, @RequestParam("wordCount") String wordCount){
PromptTemplate promptTemplate=new PromptTemplate(
"讲一个关于{topic}的故事" +
"并以{output_format}格式输出" +
",字数在{wordCount}左右"
);
Prompt prompt=promptTemplate.create(
Map.of("topic", topic, "output_format", output_format, "wordCount", wordCount)
);
return deepseek.prompt(prompt).stream().content();
}按照上述写法的话就变成了写死在代码当中,接下来要实现分离,
在resoure当中新建一个包,底下写入提示词模板,然后引入
@Value("classpath:/prompttemplate/test.txt")
private org.springframework.core.io.Resource prompttemplate;
@GetMapping("/ai/promptTemplate")
public Flux<String> promptTemplate(@RequestParam("topic") String topic, @RequestParam("output_format")String output_format, @RequestParam("wordCount") String wordCount){
PromptTemplate promptTemplate=new PromptTemplate(prompttemplate);
Prompt prompt=promptTemplate.create(
Map.of("topic", topic, "output_format", output_format, "wordCount", wordCount)
);
return deepseek.prompt(prompt).stream().content();
}注意:不能够直接写×resoure注入×
@Value("classpath:/prompttemplate/test.txt")
private Resource prompttemplate;这个resoure引入的是jakarta.annotation的,我们需要引入的是spring的io resource
提示词模板之角色设定以及边界
@GetMapping("/ai/promptTemplate")
public Flux<String> promptTemplate(@RequestParam("system") String system, @RequestParam("userInput")String userInput){
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate("你是一个{system}的助手,其他问题不需要回答");
Message message = systemPromptTemplate.createMessage(Map.of("system", system));
PromptTemplate userPromptTemplate=new PromptTemplate("回答一下{userInput}");
Message message1 = userPromptTemplate.createMessage(Map.of("userInput", userInput));
return deepseek.prompt(new Prompt(List.of(message, message1))).stream().content();
}8. ChatMemory:连续对话与持久化支持
ChatMemory 接口用于表示聊天对话的记忆存储机制,提供以下核心功能:
- 向对话中添加消息;
- 从对话历史中检索消息;
- 清除整个对话的历史记录。
目前框架内置了一种实现:MessageWindowChatMemory。
MessageWindowChatMemory 简介
MessageWindowChatMemory 是一种基于滑动窗口的聊天记忆实现,它最多保留指定数量的消息(默认为 20 条)。当消息数量超过该上限时,系统会自动移除最早的消息以维持窗口大小。
值得注意的是:
- 系统消息(System Messages)会被保留,即使窗口已满;
- 若新增一条系统消息,则所有先前的系统消息将被清除,确保对话始终基于最新的上下文信息,同时有效控制内存占用。
该实现依赖于 ChatMemoryRepository 抽象接口,后者定义了聊天记忆的底层存储机制。目前支持多种存储后端,包括:
InMemoryChatAssistantRepository(内存存储)JdbcChatMemoryRepository(关系型数据库)CassandraChatMemoryRepository(Apache Cassandra)Neo4jChatMemoryRepository(图数据库)
使用 Redis 持久化 ChatMemory(阿里云方案)
若希望将对话记忆持久化到 Redis,可引入阿里云提供的 Redis 集成依赖:
1<dependency>
2 <groupId>com.alibaba.cloud.ai</groupId>
3 <artifactId>spring-ai-alibaba-starter-memory-redis</artifactId>
4 <version>1.1.0.0-RC2</version>
5</dependency>
6<dependency>
7 <groupId>redis.clients</groupId>
8 <artifactId>jedis</artifactId>
9</dependency>提示:如您更倾向于使用 Spring Boot 官方的 Redis 集成(如 Lettuce),也可自行整合,但需确保与 ChatMemoryRepository 的兼容性。
配置 Redis 聊天记忆仓库
创建如下配置类,初始化基于 Redisson 的 Redis 存储实现:
1@Configuration
2public class RedisMemoryConfig {
3
4 @Value("${spring.data.redis.host}")
5 private String host;
6
7 @Value("${spring.data.redis.port}")
8 private int port;
9
10 @Bean
11 public RedissonRedisChatMemoryRepository chatMemoryRepository() {
12 return RedissonRedisChatMemoryRepository.builder()
13 .host(host)
14 .port(port)
15 .build();
16 }
17}在 AI 客户端中启用持久化对话记忆
在您的 AIConfig 配置类中,重新定义 ChatClient Bean,并注入上述 Redis 记忆仓库:
1@Bean("deepseek")
2public ChatClient deepseek(RedissonRedisChatMemoryRepository redissonRedisChatMemoryRepository) {
3 MessageWindowChatMemory windowChatMemory = MessageWindowChatMemory.builder()
4 .chatMemoryRepository(redissonRedisChatMemoryRepository)
5 .maxMessages(10) // 可根据需求调整窗口大小
6 .build();
7
8 return ChatClient.builder(
9 DashScopeChatModel.builder()
10 .dashScopeApi(DashScopeApi.builder().apiKey(apiKey).build())
11 .build()
12 )
13 .defaultOptions(ChatOptions.builder().model(DEEPSEEK).build())
14 .defaultAdvisors(MessageChatMemoryAdvisor.builder(windowChatMemory).build())
15 .build();
16}通过以上配置,您的 AI 对话将具备跨请求的上下文记忆能力,并能将对话历史持久化至 Redis,实现真正的连续对话体验。
通过advisors调用来完成持久化以及不同用户之间的数据隔离
@GetMapping("/ai/chatMemory")
public Flux<String> promptTemplate(@RequestParam("msg") String msg, @RequestParam("userId")String userId){
return deepseek.prompt(msg).advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID, userId)).stream().content();
}9. 向量化
在构建现代 AI 应用(如智能问答、语义搜索、RAG 系统等)时,向量化是连接自然语言与机器理解的关键桥梁。Spring AI Alibaba 作为阿里云与 Spring 社区联合推出的 Java AI 开发框架,深度集成了文本向量化与向量数据库能力,帮助开发者高效构建语义智能应用。以下从四个核心维度进行介绍:
1. 什么是向量?
在 AI 领域,向量(Vector)是一组有序的数值(通常为浮点数),用于表示数据的特征。例如,一个 1536 维的向量可以代表一句话的语义信息。
- 向量本身没有“文字”含义,但其数值分布隐含了语义。
- 语义相近的内容(如“猫”和“小狗”)在向量空间中距离较近;不相关的内容(如“火箭”和“香蕉”)则距离较远。
- 通过计算向量之间的相似度(如余弦相似度),可判断两段文本的语义相关性。
2. 文本向量化(Text Embedding)
文本向量化是指将自然语言文本(如句子、段落)转换为固定维度向量的过程,也称为 Embedding。
Spring AI Alibaba 提供了开箱即用的文本向量化能力:
- 集成阿里云 DashScope 嵌入模型:如
text-embedding-v1、text-embedding-v2,支持高质量中文语义理解。 - 统一 API 调用:通过
EmbeddingClient接口,一行代码即可完成向量化:java编辑
1List<Double> vector = embeddingClient.embed("Spring AI 很强大");- 批量处理:支持一次向量化多个文本,提升性能。
- 自动适配维度:不同模型输出不同维度(如 1024、1536),框架自动处理。
✅ 优势:无需训练模型,直接调用云端高性能嵌入服务,尤其适合中文场景。
3. 向量数据库(Vector Database)
向量数据库是专门用于存储、索引和检索高维向量的数据库系统。传统数据库无法高效处理“语义相似性”查询,而向量数据库可以。
Spring AI Alibaba 支持与多种向量数据库无缝集成:
- 阿里云产品:如 OpenSearch(向量版)、AnalyticDB for MySQL(向量引擎)
- 开源方案:如 Milvus、Qdrant、Weaviate(通过社区适配器)
- 核心功能:
-
- 快速插入向量(如文档分块后的 Embedding)
- 高效相似性搜索(Top-K 最近邻)
- 支持元数据过滤(如按时间、类别筛选后再做向量检索)
结合 Spring Data 风格,开发者可轻松构建“存向量 + 查相似”的业务逻辑。
4. 能干嘛?——典型应用场景
借助“文本 → 向量 → 向量库 → 语义检索”这一链路,Spring AI Alibaba 可支撑多种智能应用:
📌 智能知识库问答(RAG)
- 用户提问 → 向量化 → 在知识库向量中检索最相关段落 → 交给大模型生成答案。
- 避免大模型“胡说八道”,提升回答准确性。
📌 语义搜索
- 用户输入“怎么重置密码?” → 系统不再依赖关键词匹配,而是找到语义相关的帮助文档,即使文档中写的是“如何找回账户”。
📌 相似内容推荐
- 将商品描述、用户评论向量化,实现“看了又看”“猜你喜欢”等个性化推荐。
📌 文档去重与聚类
- 通过向量距离判断两篇文章是否重复,或自动对大量文本进行主题聚类。
5. Spring Boot 整合向量存储(基于 Redis-Stack)
引入依赖
本项目使用 spring-ai-alibaba 版本为 1.1.2.0。请注意,若你使用的版本与此不同,可能会出现依赖冲突。建议保持版本一致以确保兼容性。
向量存储相关的依赖如下(以 Redis 为例):
1<dependency>
2 <groupId>org.springframework.ai</groupId>
3 <artifactId>spring-ai-starter-vector-store-redis</artifactId>
4 <version>1.1.0</version>
5</dependency>说明:Spring AI 支持多种向量数据库(如 Pinecone、Milvus、PostgreSQL/pgvector 等),本文选择 Redis 作为向量存储后端。
使用 Redis Stack
Redis 本身并不原生支持向量搜索,因此我们采用其增强版 —— Redis Stack。Redis Stack 在标准 Redis 基础上集成了 RediSearch、RedisJSON、RedisGraph 等模块,其中 RediSearch 提供了高效的向量相似度搜索能力。
可通过以下 Docker 命令快速启动 Redis Stack 容器:
1docker run -d \
2 --name redis-stack \
3 -p 6379:6379 \
4 -p 8001:8001 \
5 -e REDIS_ARGS="--requirepass mypassword" \
6 redis/redis-stack:latest- 端口
6379:Redis 数据库服务 - 端口
8001:Redis Insight 可视化管理界面 - 设置了密码
mypassword,可根据实际需求调整
控制器示例:调用向量 AI 功能
以下是一个简单的 VectorController,演示如何生成文本嵌入(embedding)、写入向量库以及执行相似性检索。
1@RestController
2public class VectorController {
3
4 @Autowired
5 private EmbeddingModel embeddingModel;
6
7 @Autowired
8 private VectorStore vectorStore;
9
10 @Value("${spring.ai.dashscope.embedding.options.model}")
11 private String modelName;
12
13 /**
14 * 调用 AI 模型生成文本的向量表示
15 */
16 @GetMapping("/textEmbed")
17 public String textEmbed(@RequestParam("msg") String msg) {
18 EmbeddingResponse response = embeddingModel.call(
19 new EmbeddingRequest(
20 List.of(msg),
21 DashScopeEmbeddingOptions.builder().model(modelName).build()
22 )
23 );
24 float[] embedding = response.getResult().getOutput();
25 System.out.println(Arrays.toString(embedding));
26 return Arrays.toString(embedding);
27 }
28
29 /**
30 * 向 Redis Stack 中添加测试文档(自动计算并存储其向量)
31 */
32 @GetMapping("/add")
33 public void add() {
34 List<Document> documents = List.of(
35 new Document("I study LLM"),
36 new Document("I love Java")
37 );
38 vectorStore.add(documents);
39 }
40
41 /**
42 * 根据输入文本,在向量库中检索最相似的文档
43 */
44 @GetMapping("/get")
45 public List<Document> get(@RequestParam("msg") String msg) {
46 SearchRequest searchRequest = SearchRequest.builder()
47 .query(msg)
48 .topK(2) // 返回最相似的前 2 条结果
49 .build();
50
51 List<Document> results = vectorStore.similaritySearch(searchRequest);
52 System.out.println(results);
53 return results;
54 }
55}功能说明
/textEmbed:将输入文本转换为向量(用于调试或验证嵌入效果)/add:将示例文档存入 Redis 向量库(会自动调用 embedding 模型生成向量)/get:根据用户输入的查询文本,从向量库中检索语义最相近的文档
提示:确保 application.yml 或 application.properties 中已正确配置 DashScope(或其他)嵌入模型及 Redis 连接参数。
关于 Redis Stack 的补充说明
Redis Stack 并非 Redis 的简单发行版,而是一个集成了多个高级模块的增强型 Redis 发行包,专为现代应用(如 AI、实时分析、全文搜索等)设计。它在标准 Redis 的基础上,原生内置了以下关键组件:
- RediSearch:提供高性能的全文检索与向量相似度搜索能力。支持标量字段过滤、地理查询,并能对高维向量(如文本嵌入)执行高效的近似最近邻(ANN)搜索。
- RedisJSON:允许以原生 JSON 格式存储、索引和查询文档,非常适合处理半结构化数据。
- RedisTimeSeries:用于高效存储和查询时间序列数据。
- RedisGraph:基于图结构的内存数据库,支持 Cypher 查询语言。
- RedisBloom:提供概率性数据结构(如布隆过滤器、Top-K 等),适用于去重、频次统计等场景。
在向量检索场景中,RediSearch 是核心模块。它通过 FT.CREATE 命令创建索引时,可指定 VECTOR 字段类型,并配置距离度量方式(如余弦相似度、欧氏距离等)和索引算法(如 HNSW 或 FLAT)。Spring AI 的 spring-ai-starter-vector-store-redis 正是基于 RediSearch 的向量功能实现的自动集成。
此外,Redis Stack 还自带 Redis Insight(Web 可视化管理工具),可通过 http://localhost:8001 访问,方便开发者查看数据结构、执行命令、监控性能,极大提升了调试效率。
总结:Redis Stack = Redis + RediSearch(含向量)+ RedisJSON + ... + Redis Insight
对于希望快速搭建轻量级、一体化向量数据库的团队来说,Redis Stack 是一个简洁高效的选择。
总结
表格
|
模块 |
作用 |
Spring AI Alibaba 支持 |
|
向量 |
语义的数值表示 |
自动处理高维浮点数组 |
|
文本向量化 |
文本 → 向量 |
集成 DashScope,提供 |
|
向量数据库 |
存储与检索向量 |
兼容阿里云及主流开源向量库 |
|
能干嘛 |
构建语义智能应用 |
RAG、语义搜索、推荐、聚类等 |
10. RAG(检索增强生成)详解与 Spring Boot 实践
什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种融合信息检索(Information Retrieval)与大语言模型(LLM)生成能力的先进 AI 架构。其核心目标是弥补传统大语言模型在以下三方面的固有缺陷:
- 知识时效性差:LLM 的训练数据通常截止于某个固定时间点,无法获取最新信息;
- 幻觉问题(Hallucination):模型可能“自信地”生成看似合理但实际错误或虚构的内容;
- 领域知识不足:通用模型缺乏对特定行业、企业内部文档或私有数据的理解能力。
通过引入外部可信知识源,RAG 能显著提升回答的准确性、可靠性与时效性。
RAG 的工作原理
RAG 的执行流程可分为两个关键阶段:
1. 检索阶段(Retrieval)
当用户提出问题时,系统首先将问题文本转换为向量表示(embedding),然后在预构建的私有知识库(如企业文档、产品手册、数据库等)中执行相似性搜索,检索出与问题最相关的若干文本片段(称为“上下文”或“证据”)。
2. 生成阶段(Generation)
系统将原始问题与检索到的相关上下文拼接成一个增强型提示(prompt),并将其输入给大语言模型。LLM 基于这些真实、可信的外部信息生成最终回答,从而有效抑制幻觉,提升答案质量。
✅ 优势:既保留了 LLM 强大的语言生成能力,又通过外部知识注入增强了事实准确性。
Spring Boot 实践:构建 RAG 应用
以下是一个基于 Spring AI + Redis Stack 的 RAG 示例实现。
1. 依赖配置
在 pom.xml 中引入所需依赖:
1<dependencies>
2 <!-- Spring AI Redis 向量存储支持 -->
3 <dependency>
4 <groupId>org.springframework.ai</groupId>
5 <artifactId>spring-ai-starter-vector-store-redis</artifactId>
6 <version>1.1.0</version>
7 </dependency>
8 <!-- Hutool 工具库(用于 MD5 等工具方法) -->
9 <dependency>
10 <groupId>cn.hutool</groupId>
11 <artifactId>hutool-all</artifactId>
12 <version>5.8.2</version>
13 </dependency>
14</dependencies>2. 准备检索数据
在 src/main/resources/ 目录下创建文件 ops.txt,内容如下:
100000 系统正确执行后的返回
2A0001 用户端错误返回的错误码
3A0100 用户注册错误返回的错误码
4B1111 支付接口超时返回错误码
5C2222 Kafka消息解压严重该文件将作为私有知识库,用于向量化并支持后续检索。
3. 配置类
(1) AI 模型配置
1@Configuration
2public class AiConfig {
3
4 @Value("${spring.ai.dashscope.api-key}")
5 private String apiKey;
6
7 @Value("${spring.ai.dashscope.chat.options.model}")
8 private String modelName;
9
10 @Bean
11 public ChatClient chatModel() {
12 return ChatClient.builder(
13 DashScopeChatModel.builder()
14 .dashScopeApi(DashScopeApi.builder().apiKey(apiKey).build())
15 .build()
16 )
17 .defaultOptions(ChatOptions.builder().model(modelName).build())
18 .build();
19 }
20}使用阿里云通义千问(DashScope)作为 LLM 后端。
(2) Redis 配置
1@Configuration
2public class RedisConfig {
3
4 @Bean
5 public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
6 RedisTemplate<String, Object> template = new RedisTemplate<>();
7 template.setConnectionFactory(redisConnectionFactory);
8
9 // Key 使用字符串序列化
10 template.setKeySerializer(new StringRedisSerializer());
11 template.setHashKeySerializer(new StringRedisSerializer());
12
13 // Value 使用 JSON 序列化
14 template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
15 template.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
16
17 return template;
18 }
19}(3) 向量存储配置
1@Configuration
2public class VectorStoreConfig {
3
4 @Value("${spring.data.redis.host}")
5 private String redisHost;
6
7 @Value("${spring.data.redis.port}")
8 private int redisPort;
9
10 @Value("${spring.ai.vectorstore.redis.index-name:default-index}")
11 private String indexName;
12
13 @Value("${spring.ai.vectorstore.redis.prefix:ai-docs}")
14 private String prefix;
15
16 @Bean
17 public RedisVectorStore vectorStore(EmbeddingModel embeddingModel) {
18 JedisPooled jedis = new JedisPooled(redisHost, redisPort);
19 return RedisVectorStore.builder(jedis, embeddingModel)
20 .indexName(indexName)
21 .prefix(prefix)
22 .initializeSchema(true)
23 .build();
24 }
25}使用 Redis Stack 作为向量数据库,支持高效的相似性搜索。
(4) 初始化向量库(避免重复加载)
1@Configuration
2public class InitVectorConfig {
3
4 @Value("classpath:ops.txt")
5 private Resource resource;
6
7 @Autowired
8 private RedisTemplate<String, String> redisTemplate;
9
10 @Autowired
11 private VectorStore vectorStore;
12
13 @PostConstruct
14 public void init() throws IOException {
15 // 1. 读取文件内容
16 String content = new String(resource.getInputStream().readAllBytes(), StandardCharsets.UTF_8);
17
18 // 2. 计算内容 MD5(用于判断是否已加载)
19 String contentMd5 = DigestUtil.md5Hex(content);
20 String redisKey = "vector:zwz:" + contentMd5;
21
22 // 3. 若未加载过,则写入向量库
23 Boolean isNew = redisTemplate.opsForValue().setIfAbsent(redisKey, "1");
24 if (Boolean.TRUE.equals(isNew)) {
25 List<Document> documents = new TokenTextSplitter().transform(List.of(new Document(content)));
26 vectorStore.add(documents);
27 System.out.println("向量数据库已更新,新内容 MD5: " + contentMd5);
28 } else {
29 System.out.println("向量数据库已存在,内容未变化");
30 }
31 }
32}✅ 通过 MD5 校验避免重复加载相同内容,提升启动效率。
4. 控制器实现
1@RestController
2public class RagController {
3
4 @Autowired
5 private ChatClient chatModel;
6
7 @Autowired
8 private VectorStore vectorStore;
9
10 @GetMapping("/ai/rag")
11 public Flux<String> rag(@RequestParam("msg") String msg) {
12 String systemPrompt = "你是一名运维工程师,请根据提供的错误编码返回对应的说明信息。";
13
14 RetrievalAugmentationAdvisor advisor = RetrievalAugmentationAdvisor.builder()
15 .documentRetriever(
16 VectorStoreDocumentRetriever.builder()
17 .vectorStore(vectorStore)
18 .build()
19 )
20 .build();
21
22 return chatModel.prompt()
23 .system(systemPrompt)
24 .user(msg)
25 .advisors(advisor)
26 .stream()
27 .content();
28 }
29}用户请求如 /ai/rag?msg=A0100 将触发 RAG 流程:
- 从
ops.txt中检索“A0100”相关片段; - 将片段与问题一起送入 LLM;
- 返回结构化、准确的错误说明。
总结
通过 RAG 架构,我们成功将私有知识与大模型能力结合,构建了一个面向运维场景的智能问答系统。该方案具备以下优势:
- 动态更新知识库:支持通过文件变更自动刷新向量数据;
- 防止幻觉:回答严格基于检索到的真实文档;
- 低耦合、高扩展:可轻松替换 LLM 或向量数据库后端。
11. 工具调用(Tool Calling)
工具调用(Tool Calling) 是大语言模型(LLM)与外部系统交互的核心能力之一。它允许模型在理解用户意图后,主动调用开发者预定义的函数(即“工具”),以获取实时数据、执行业务逻辑或访问外部服务。例如,当用户询问“现在几点?”,模型可不再依赖训练数据中的静态知识,而是触发一个本地方法来获取准确的当前时间,并将结果自然地融入回复中。这种方式显著提升了 AI 应答的准确性、时效性与实用性。
在 Spring AI 框架中,通过 @Tool 注解标记 Java 方法,即可将其注册为可供模型调用的工具。以下示例展示了如何配置 DashScope 模型客户端,并实现一个简单的“获取当前时间”工具。
首先,通过 @Configuration 类加载 API 密钥与模型选项,构建 ChatClient Bean:
1@Configuration
2public class AiConfig {
3
4 @Value("${spring.ai.dashscope.api-key}")
5 private String apiKey;
6 @Value("${spring.ai.dashscope.chat.options.model}")
7 private String chatOptions;
8
9 @Bean
10 public ChatClient chatClient(){
11 return ChatClient
12 .builder(DashScopeChatModel.builder().dashScopeApi(DashScopeApi.builder().apiKey(apiKey).build()).build())
13 .defaultOptions(ChatOptions.builder().model(chatOptions).build())
14 .build();
15 }
16
17}接着,定义一个工具类 DateUtil,并使用 @Component 将其纳入 Spring 容器管理。其中的 getDate() 方法通过 @Tool 注解暴露给大模型,描述其功能为“获取当前时间”:
1@Component
2public class DateUtil {
3 @Tool(description = "获取当前时间",returnDirect = false)
4 public String getDate(){
5 return LocalDate.now().toString();
6 }
7}最后,在控制器中注入 ChatClient 与工具实例,并提供一个 HTTP 接口。当用户发送消息(如默认的“你是谁现在几点”)时,系统会启用工具调用机制,允许模型在生成响应过程中按需调用 DateUtil 中的方法:
1@RestController
2public class ToolController {
3
4 @Autowired
5 private ChatClient chatClient;
6
7 @Autowired
8 private DateUtil dateUtil;
9
10 @GetMapping("/ai/tool")
11 public Flux<String> getChatClient(@RequestParam(value = "msg",defaultValue = "你是谁现在几点")String msg){
12 return chatClient.prompt().user(msg).tools(dateUtil).stream().content();
13 }
14
15}通过上述配置,应用实现了基础但完整的工具调用流程:模型根据语义理解决定是否调用工具,后端执行对应方法并将结果反馈回对话流,最终生成结合实时信息的智能回复。
12. MCP
什么是 MCP(Model Context Protocol)?
MCP(Model Context Protocol) 是一种标准化协议,旨在统一 AI 模型与外部工具、数据源和服务之间的交互方式。它由 LangChain 和 LlamaIndex 等主流 LLM 应用框架的社区联合推动,目标是解决当前工具调用(Tool Calling)生态中接口碎片化、集成复杂、可移植性差等问题。
简单来说,MCP 定义了一套 通用的“语言”,让大模型能够以一致的方式发现、理解并调用各种外部能力——无论是查询数据库、获取实时天气、操作企业内部 API,还是执行自定义函数。
核心设计思想
- 标准化工具描述
MCP 要求每个工具通过结构化元数据(如名称、描述、输入/输出参数 schema)进行注册,使模型能准确理解其用途和调用方式。 - 协议无关的通信机制
工具可通过 HTTP、gRPC、WebSocket 或本地函数等多种方式暴露,MCP 关注的是调用语义而非传输细节。 - 上下文感知与状态管理
支持在多轮对话中维护工具调用的上下文(例如分页查询、事务操作),避免每次调用都从零开始。 - 安全与权限控制
提供鉴权、速率限制、审计日志等企业级能力,确保工具调用的安全可控。
MCP 的典型工作流程
- 工具注册:开发者将业务函数按 MCP 规范注册为“能力提供者”(Capability Provider)。
- 模型请求:LLM 在生成响应时,根据用户意图生成符合 MCP 格式的工具调用请求。
- 协议路由:MCP 运行时解析请求,路由到对应的工具实现并执行。
- 结果回填:工具返回结构化结果,由运行时注入对话上下文,供模型生成最终回复。
text
编辑
1用户 → LLM → [MCP Call: get_current_time()] → 工具执行 → 返回 "2026-02-05" → LLM → “现在是2026年2月5日”为什么需要 MCP?
在 MCP 出现之前,不同框架(如 OpenAI Function Calling、Anthropic Tools、Spring AI、LangChain Tools)各自定义了互不兼容的工具调用格式。这导致:
- 工具难以跨平台复用;
- 开发者需为不同模型重复封装同一功能;
- 企业无法构建统一的“AI 工具市场”。
MCP 的出现,正是为了打造一个 “一次编写,处处可用” 的工具生态,加速 AI 应用的开发与集成。

自定义一个MCP服务
引入依赖,最好不要和spring-boot-starter-web一起,容易引发冲突
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>3.5.10</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webflux</artifactId>
<version>1.1.0</version>
</dependency>
</dependencies>配置文件
server:
port: 8016
spring:
ai:
mcp:
server:
name: mcp-server
type: async
version: 1.0.0配置类配置服务
@Configuration
public class MCPConfig {
/**
* 将工具暴露给外部mcp client使用
* */
@Bean
public ToolCallbackProvider toolCallbackProvider(MCPService mcpService){
return MethodToolCallbackProvider
.builder()
.toolObjects(mcpService)
.build();
}
}服务了用来给ai来使用
@Service
public class MCPService {
@Tool(description = "获取城市天气预报")
public String getWeak(String city){
Map<String,String> map = Map.of(
"北京","多云,16度,",
"上海","下雨,10度,",
"天津","晴天,24度,"
);
return map.getOrDefault(city,"没有这个城市信息");
}
}调用自定义服务类
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.1.2.0</version>
</dependency>配置信息
server:
port: 8015
spring:
ai:
dashscope:
api-key: your-key
# 可选:指定模型
chat:
options:
model: deepseek-v3.2
mcp:
client:
type: async
request-timeout: 20s
toolcallback:
enabled: true
sse:
connections:
mcp-server1:
url: http://localhost:8016配置类
@Configuration
public class MPCConfig {
@Value("${spring.ai.dashscope.api-key}")
private String dashscopeApiKey;
@Value("${spring.ai.dashscope.chat.options.model}")
private String dashscopeChatOptions;
@Bean
public ChatClient chatClient(ToolCallbackProvider toolCallbackProvider){
return ChatClient
.builder(DashScopeChatModel.builder().dashScopeApi(DashScopeApi.builder().apiKey(dashscopeApiKey).build()).build())
.defaultOptions(DashScopeChatOptions.builder().model(dashscopeChatOptions).build())
.defaultToolCallbacks(toolCallbackProvider) //用来调用MCP
.build();
}
}controller测试类
@RestController
public class MCPClientController {
@Autowired
private ChatClient chatClient;
@GetMapping("/ai/mcp")
public Flux<String> mcp(@RequestParam(value = "msg",defaultValue = "北京")String msg){
return chatClient.prompt().user(msg).stream().content();
}
}俩个项目搭好以后需要先启动服务类不然客户端会报错
调用外部服务类基于百度地图
可以参考MCP服务调用网站https://mcp.so/zh
这边调用百度地图的MCP还需要使用python环境或者node.js环境,有需要的可以去下载一下,还需要去百度地图的控制台申请一个apikey
需要再resouce底下配置一下mcp-server.json,需要修改一下API-KEY,百度的教程json格式跟我的可能有点差异
{
"mcpServers": {
"baidu-map": {
"command": "cmd",
"args": [
"/c",
"npx",
"-y",
"@baidumap/mcp-server-baidu-map"
],
"env": {
"BAIDU_MAP_API_KEY": "xxx"
}
}
}
}server:
port: 8080
spring:
ai:
dashscope:
api-key: your-key
# 可选:指定模型
chat:
options:
model: deepseek-v3.2
mcp:
client:
request-timeout: 20s
toolcallback:
enabled: true
stdio:
servers-configuration: classpath:/mcp-server.json调用方法和之前一样,展示一下返回的结果
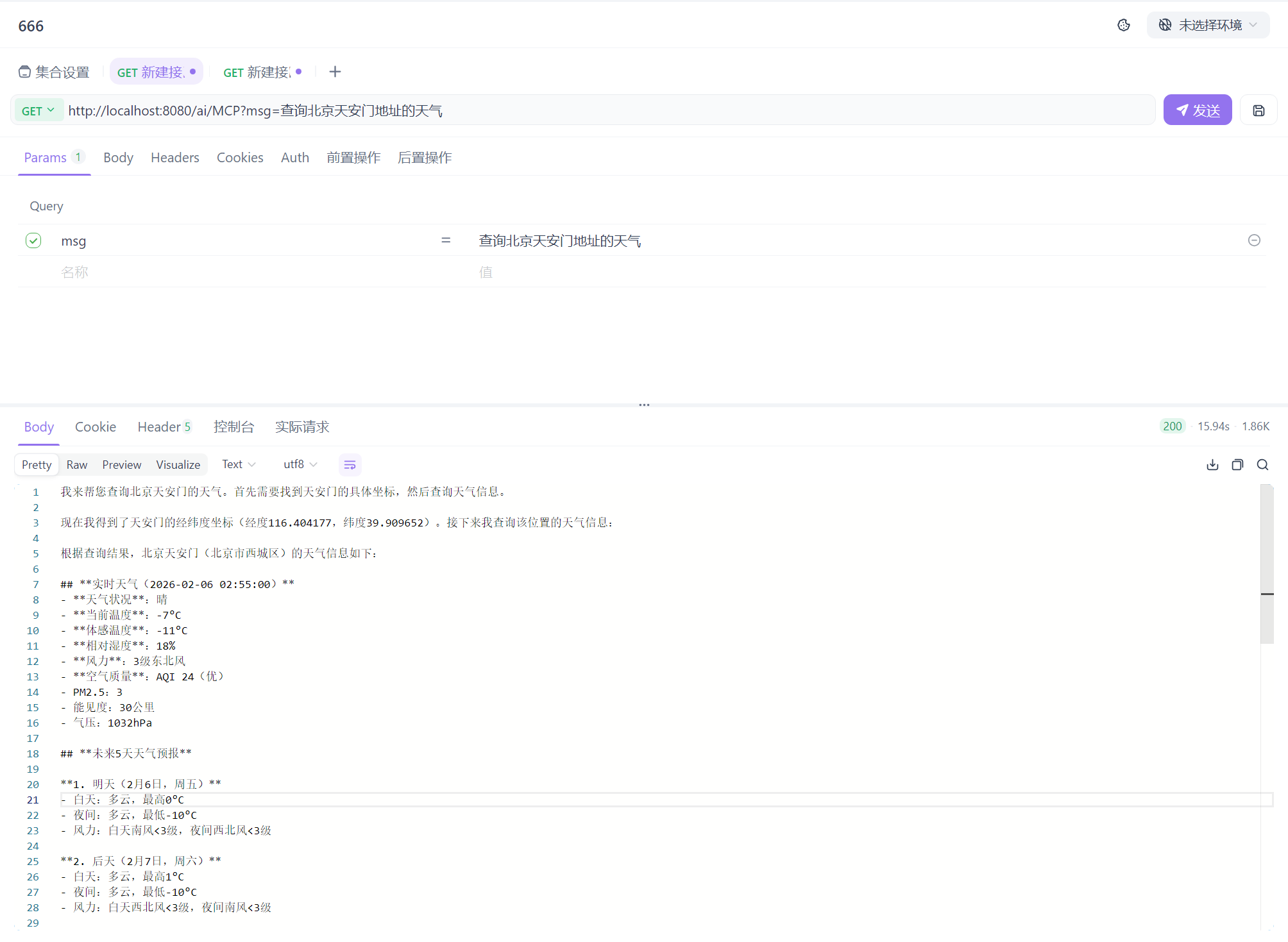
总结:我们学到了什么?
表格
|
模块 |
能力 |
技术价值 |
|
基础集成 |
DashScope + Spring Boot 快速接入 |
降低大模型使用门槛 |
|
交互设计 |
ChatClient / SSE / 多模型 |
构建高性能、可扩展 AI 接口 |
|
Prompt 工程 |
角色控制 + 模板化 + 外部化 |
提升回答准确性与可控性 |
|
记忆管理 |
Redis 持久化 + 用户隔离 |
支持真实连续对话场景 |
|
语义智能 |
向量化 + RAG + 向量库 |
打造企业私有知识问答系统 |
|
外部扩展 |
Tool Calling + MCP |
让 AI 调用现实世界能力 |
🎯 整体定位:Spring AI Alibaba 不仅是一个 SDK,更是一套 面向生产环境的 AI 应用开发框架,覆盖从模型调用、上下文管理、知识增强到工具集成的完整链路,特别适合构建 垂直领域智能助手、企业知识库问答、运维自动化等场景。
仓库地址

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)