大模型风向变了!CC之父:Opus4.6是我们最好的模型!为长时程Agent而生!实测玩疯了:一击必杀!超级可玩,连人物建模都更逼真了!
综合Anthropic官网和相关人士的测评,看一看出,Opus 4.6 在长上下文信息定位、基于信息的推理能力,以及专家级复杂推理留下了令人深刻的印象。凌晨2点,硅谷的两家AI龙头公司,又来一波火拼!因为是 Claude Opus 4.6 的发布的早一点,业界解读得比较多,测试体验的朋友也更多一些。再加上之前小编已经写了不少 Codex 的内容,今天就索性为大家详细拆解,写一下 Opus 4.6.
综合Anthropic官网和相关人士的测评,看一看出,Opus 4.6 在长上下文信息定位、基于信息的推理能力,以及专家级复杂推理留下了令人深刻的印象。
凌晨2点,硅谷的两家AI龙头公司,又来一波火拼!
因为是 Claude Opus 4.6 的发布的早一点,业界解读得比较多,测试体验的朋友也更多一些。
再加上之前小编已经写了不少 Codex 的内容,今天就索性为大家详细拆解,写一下 Opus 4.6.
综合Anthropic官网和相关人士的测评,看一看出,Opus 4.6 在长上下文信息定位、基于信息的推理能力,以及专家级复杂推理留下了令人深刻的印象。
已经用了一段时间的 ClaudeCode 之父 Boris 用了四个形容词来形容 Opus 4.6:更自主性、更智能、运行时间更长、更加细致全面。
知名科技评论者 Ganpathi 博士表示,首个百万 token 上下文的 Opus 级别模型。计划更加周密、能够更长时间维持 agentic 任务执行,并且在大型代码库中运行得更加稳定、可靠。
想在终端上运行 Opus 4.6?当然也是可以的。终端 Agent,同样也在 Opus 4.6的射程之内。有网友已经在 X 上晒出来了自己成功在 OpenClaw 上运行的截图。
所以,作为 Claude 体系中能力最强、定位最高的模型,不得不来仔细关注一番。
模型定位:为「长时程 agentic 任务」而生的前沿模型
先来看下定位。
与以往侧重“模型能力展示”不同,Opus 4.6 的整体升级方向非常明确:为长期、复杂、真实世界的知识工作与 agent 任务而设计。(注意:这里的落脚点是知识工作和 Agent。)
Opus 4.6 的核心定位不再是“更聪明的聊天模型”,而是转向了真实世界的 Agent 模型。
与以往的文理科、推理等能力基准相比,这次更多的叙事赛事变成了以下四点:
- 在复杂任务中自主判断重点
- 长时间保持上下文一致性
- 稳定运行 agentic 工作流
- 在真实代码库和企业级任务中可控、可靠地发挥能力
有图为证,不妨看一下,Anthropic 放出来的13项基准成绩,你就会发现有10项全都是Agentic 能力,其余三项分别是GPQA测试、视觉推理和跨语种理解能力。
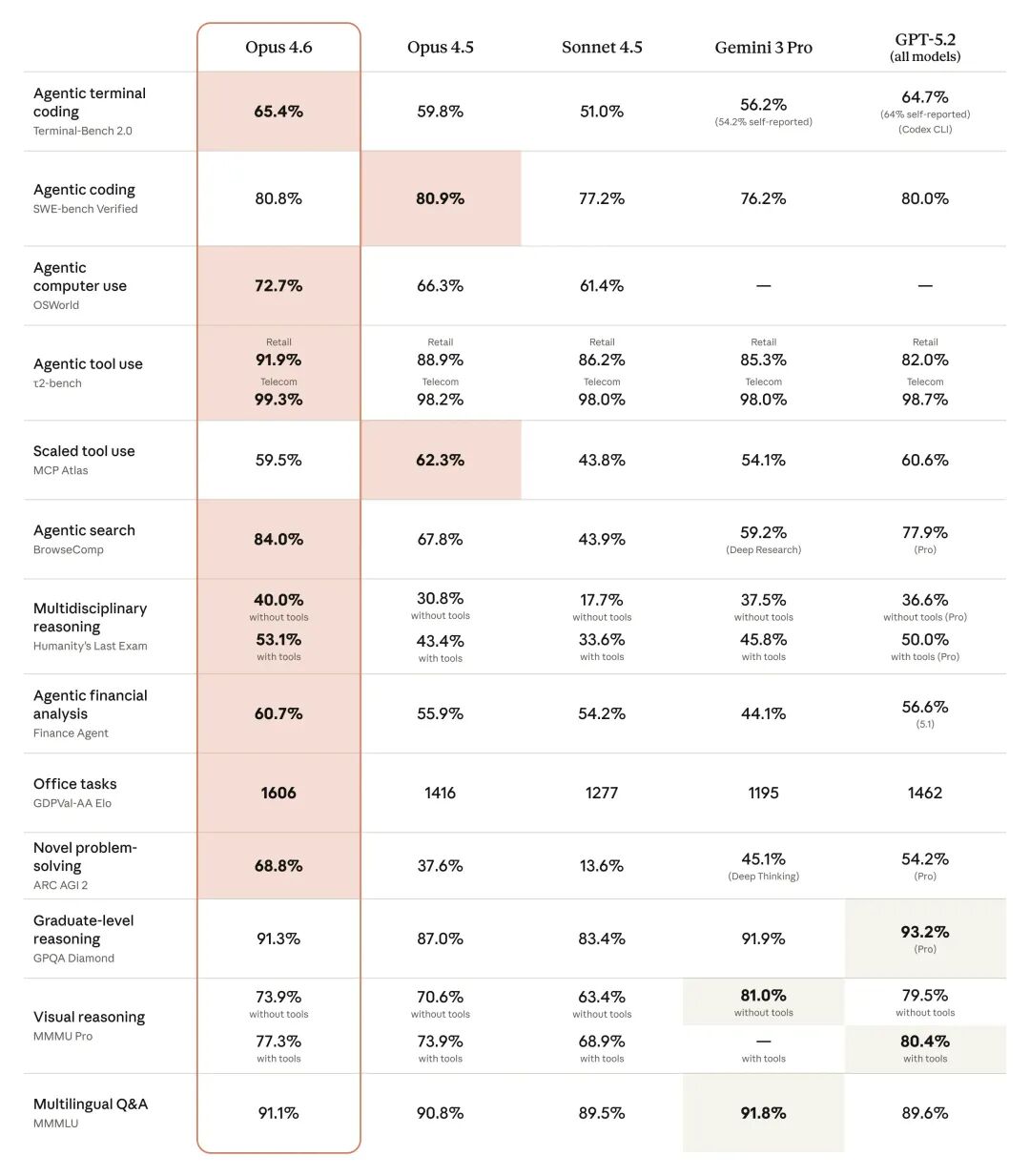
Benchmark table comparing Opus 4.6 to other models
Anthropic 还在官网表述中多次强调一个事实:
他们用 Claude 来构建 Claude。Opus 4.6 已经在内部工程、代码审查、研究和文档工作中经受了检验,其设计目标直接指向工程团队与知识工作者的日常使用场景。
三大主打改进方向
Opus 4.6 的能力提升集中在三个关键方向。
第一,Agentic 能力的系统性增强。
Opus 4.6 在规划、分解和执行任务方面更稳定,能够在无需频繁人工干预的情况下持续推进复杂工作。早期用户反馈显示,它更容易“自己把事干完”,而不是反复等待指令。
挪威央行投资管理公司AI 与机器学习负责人Stian Kirkeberg,就透露了自己盲测的一组数据:
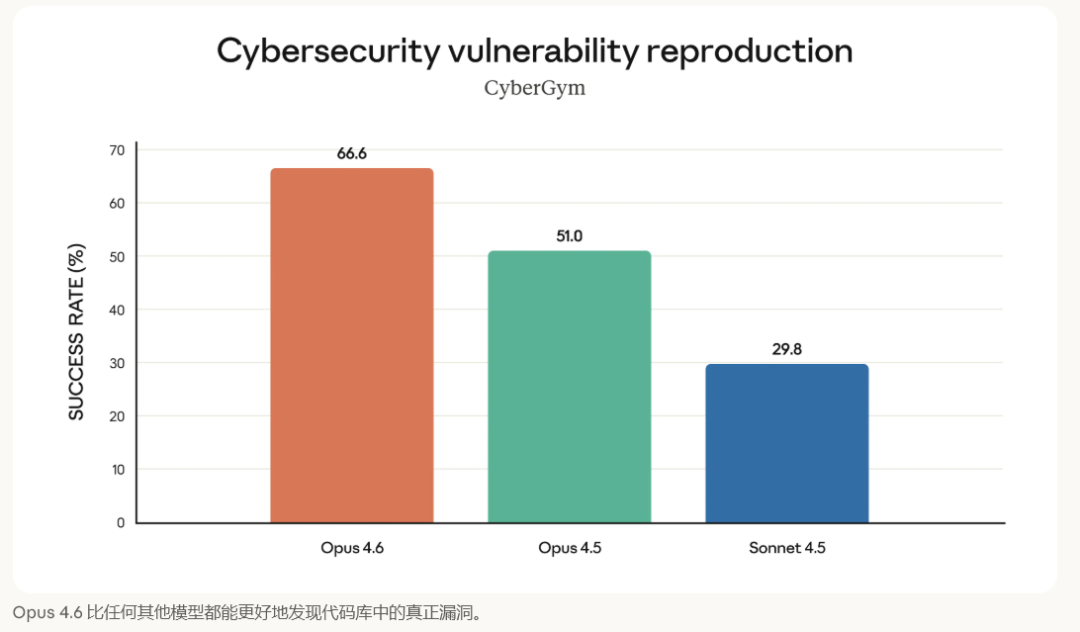
在 40 项网络安全调查中,Claude Opus 4.6 在与 Claude 4.5 的盲测对比中,有 38 次取得了最佳结果。所有模型都在相同的 Agent 测试框架下端到端运行,最多使用 9 个子代理,并进行了超过 100 次工具调用。
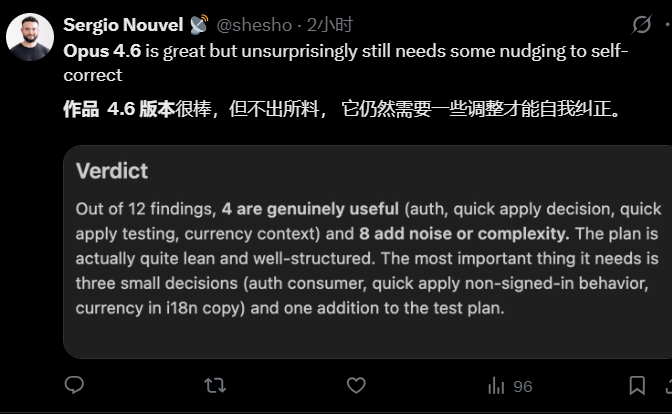
当然,也有网友实测反映:虽然自主性提升了一些,但依旧有待改进的空间。比如,一位网友分享了Claude Opus 4.6对12个发现的分析截图,其中4个真正有用,其余8个为噪声或复杂性,整体计划精简但需三项小决策和一项测试计划补充。
第二,长上下文的“可用性”发生质变。众所周知,光有如此大的上下文窗口,不能干更好的活只能是“技术花瓶”。但这次 Opus 4.6 的 100 万 token 上下文并非噱头。
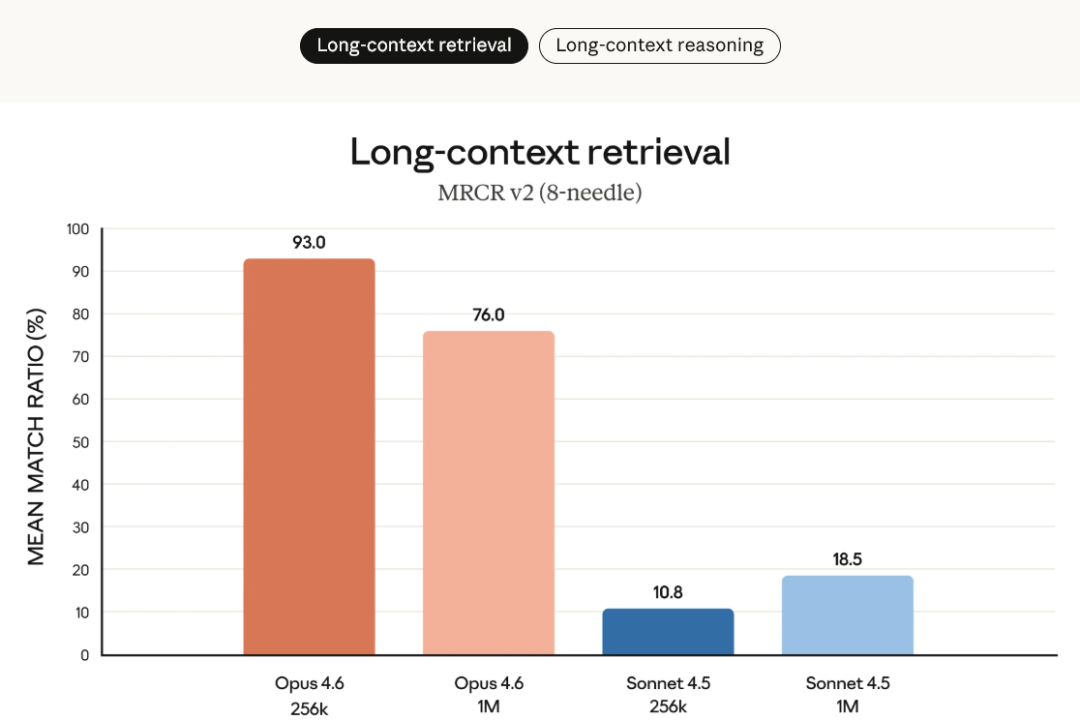
在 MRCR v2 的 8-needle / 1M 测试中,Opus 4.6 达到 76% 的检索准确率,而 Sonnet 4.5 仅为 18.5%。这意味着模型不仅能“装下”上下文,还能在极长对话中持续理解、追踪和调用关键信息,显著缓解长期被诟病的“上下文退化”问题。
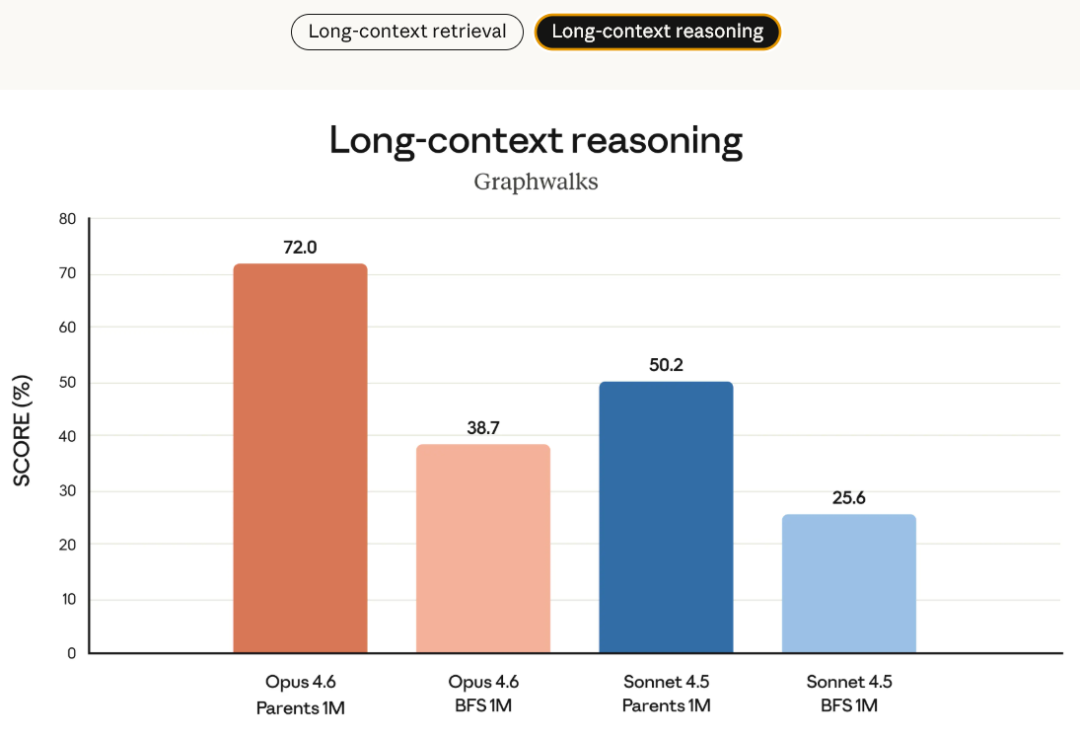
第三,推理方式从“强制展开”转向“按需使用”。通过 Adaptive Thinking + Effort 控制,Opus 4.6 能够根据任务复杂度决定是否使用深度推理。开发者不再只能在“全开或全关”之间二选一,而是可以在质量、速度和成本之间精细调节。
具体一些细节如下:
自适应思考:此前,开发者只能选择开启或关闭扩展推理。现在引入自适应思考后,Claude 可以自行判断何时需要更深层的推理。在默认的 high 强度下,模型会在必要时启用扩展推理;开发者也可以通过调整强度,让模型在使用深度推理时更加或更少克制。
Effort 控制新增四档推理强度选项:low、medium、high(默认)和 max。官方建议开发者根据具体任务进行尝试,以在质量、速度与成本之间取得平衡。
这一点,Boris 也在推文中说明了。如果我们使用 Claude API,Opus 4.6 模型已经可以做出自适应的复杂决策,这样可以更精确地调整模型思考量。
多项评测中的领先表现:Agentic编程表现第一
在官方披露的多项评测中,Opus 4.6 均达到或刷新当前前沿水平:
- Terminal-Bench 2.0:Agentic 编程评测第一
- Humanity’s Last Exam:多学科复杂推理领先所有前沿模型
- GDPval-AA:在金融、法律等高价值知识工作任务中
- 比 OpenAI GPT-5.2 高约 144 Elo
- 比 Opus 4.5 高 190 Elo
- BrowseComp:在线检索与信息定位能力第一
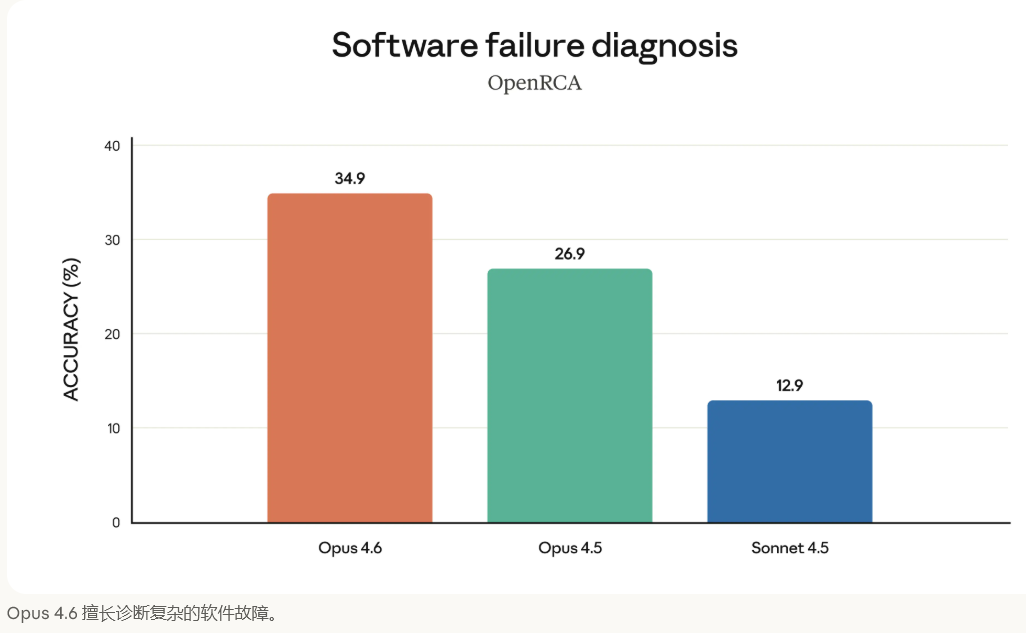
在能力维度上,Opus 4.6 在根因分析、多语言编程、长期一致性、网络安全和生命科学知识等方面均表现突出,尤其擅长诊断复杂软件故障。
AI 越来越接近“可用的同事”
很明显,Opus 4.6 的发布,跟前两年的叙事已经发生了很大的改变,少了模型参数和原有榜单的刷新,更多的还是在 Agent 方面做足了功夫。
其一,Agent 从“演示”走向“生产”。通过上下文压缩、128k 输出、agent 团队、长时间运行支持,Anthropic 明确将 Agent 视为一等公民,不再停留在去年的实验功能阶段。
当然,如果说 Opus 4.6 与 Codex 5.3 相比,还有哪些独特之处,就不得不说安全层面。
在能力大幅增强的同时,Opus 4.6 仍保持了与 Opus 4.5 相当甚至更优的对齐水平,并实现了 最低的过度拒答率。在网络安全能力增强的背景下,Anthropic 同步引入新的安全探针和防御性应用,强调“让防守方先用好 AI”。
总之,随着 2026 年序幕拉开,一个清晰的信号扑面而来:2026,全球的AI赛点渐变成真实任务的“持续Agentic工作能力”。
那么如何锚定这个能力呢?
Anthropic 给出了一些基本参考维度。从自适应推理、长上下文可用性,到办公工具深度集成。
Opus 4.6 传递出的信号非常明确:模型竞争正在从“单次回答多聪明”,转向“能否长期、稳定、可信地完成真实工作”。
而这也意味着,大模型正在从“工具”蜕变为“可协作的同事”。
实测:“可运行、可交互、可玩”的生成任务
最后,由于地缘限制,小编不能一手实测。但看了几个公开的视频实测吧,的确体验上非常惊艳。
在公开视频测试中,不少评测这对 Opus4.6 进行了多项高复杂度、零样本生成测试,涵盖舰船战斗模拟、空战游戏、虚拟架子鼓模拟,以及一个完全自包含、可直接编译运行的 C++ 滑板游戏。测试未依赖外部资源或手工修正,生成过程一次完成,重点考察模型在交互逻辑、物理一致性、可玩性与代码完整性上的综合能力。

其中,C++ 滑板游戏成为最突出的案例:模型一次性生成近 2000 行代码,角色动作、物理反馈、计分逻辑完整可运行,人物建模与动作表现也首次摆脱以往“抽象人形”的局限。
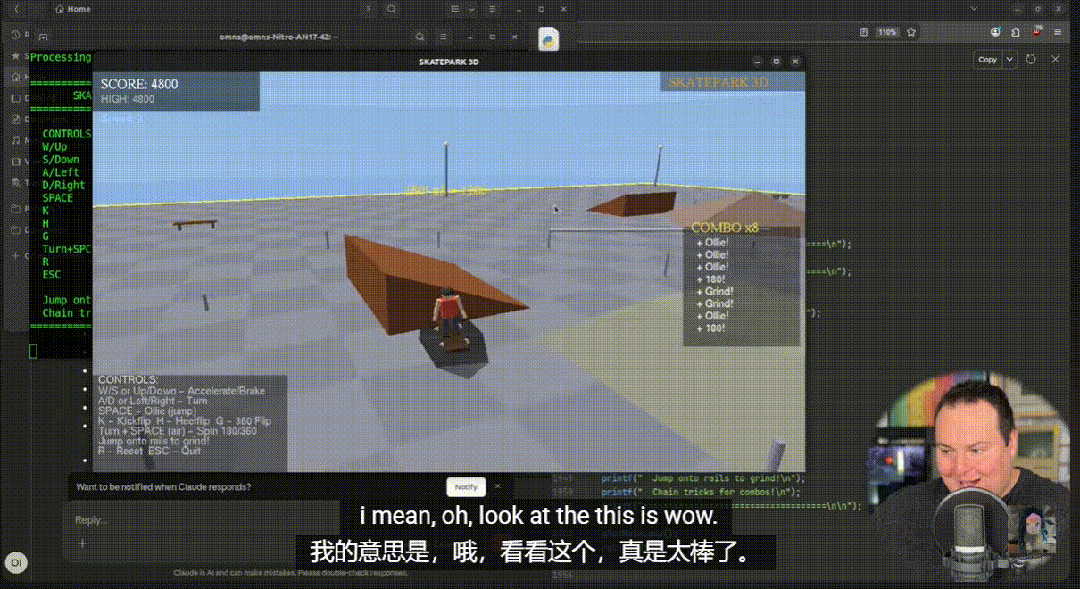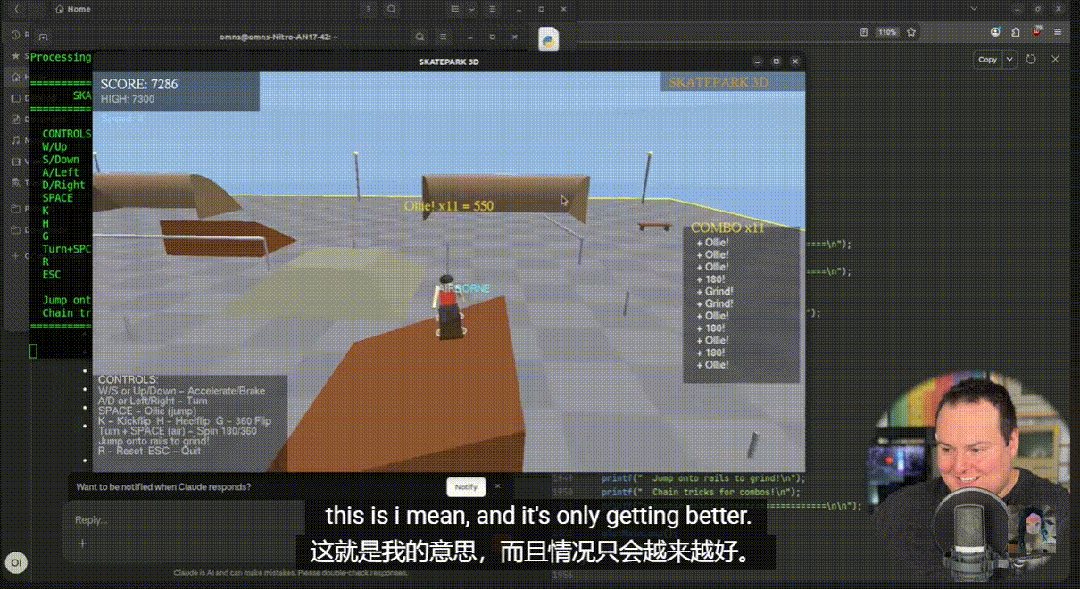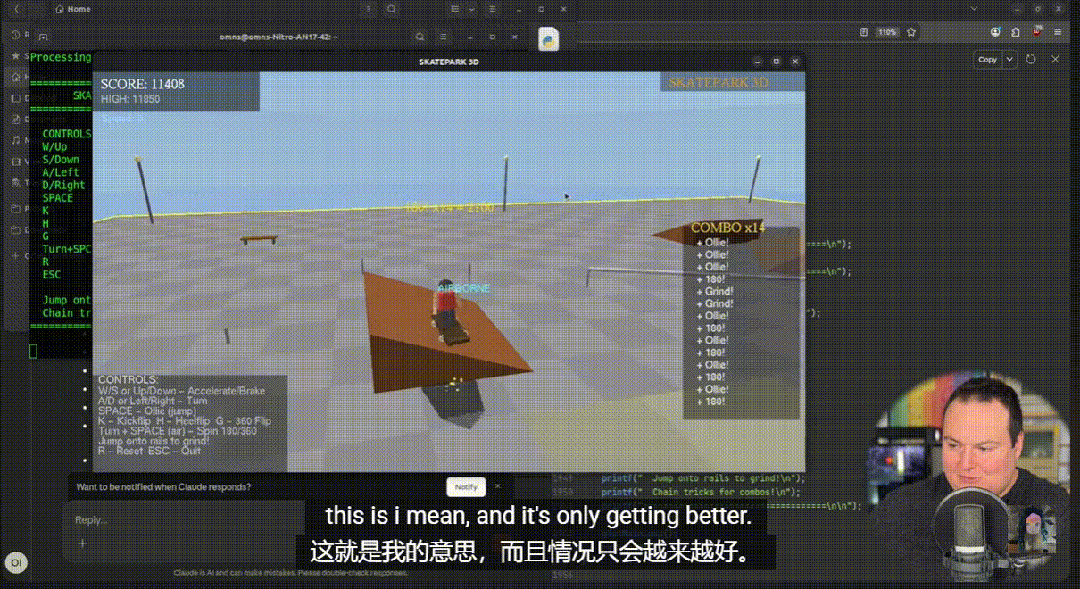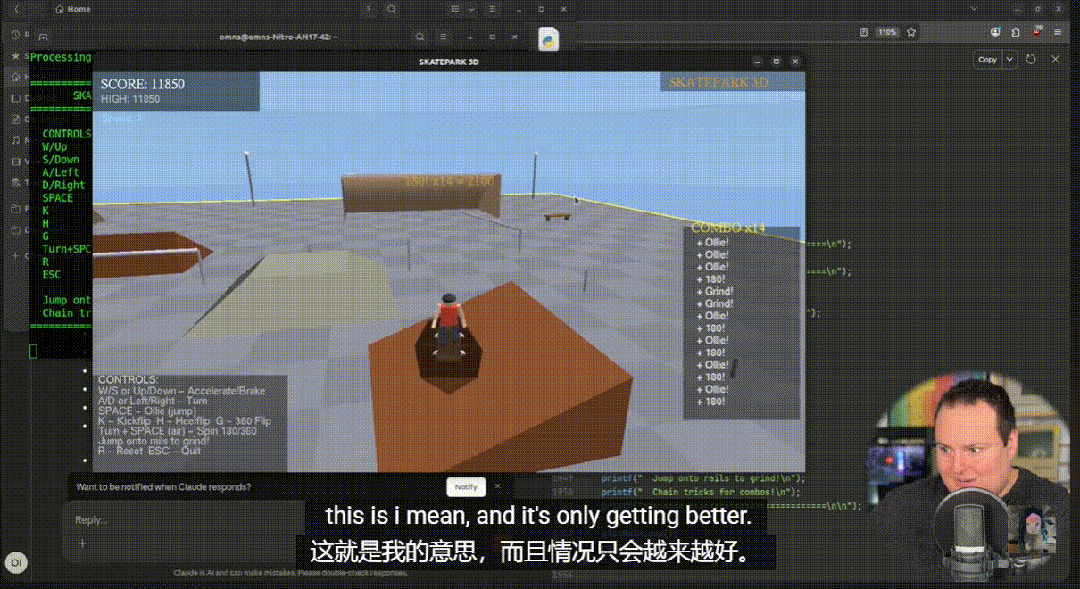
空战模拟在画面、敌机逻辑与音效引入上同样达到该测试体系中的最高水准。相对而言,从线框图生成网页的多模态测试表现平稳,但创作自由度受限。整体来看,Opus 4.6 已经在“可运行、可交互、可玩”的生成任务上,逼近以往仅在更高规格模型中才能看到的水平。

从实测结果看,Claude Opus 4.6 在复杂交互式生成任务上的稳定性和完成度明显提升。
就在刚刚,Anthropic 还同步放出了一个内部相当魔幻的“”例子:
“我们委托 Opus 4.6 使用agent teams 构建一个 C 编译器。然后我们(基本上)就放手不管了。两周后,它竟然能在 Linux 内核上运行了。它教会了我们关于自主软件开发未来的一些道理。”

只能说,大模型,真的要成“精”了!遍地 Agent 的时代已经开启!
参考链接:
https://www.youtube.com/watch?v=8brENzmq1pE

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献224条内容
已为社区贡献224条内容

所有评论(0)