测了一个9B开源模型,AI视频对话终于不像对讲机了
在同样的 RTX 4090 上测试,9B 的 MiniCPM-o 4.5,INT4 量化后解码速度能到 200 tokens/s 以上,首响时间稳定在 0.6 秒左右,显存占用只有 11GB。它在说的时候,眼睛还在跟着你笔尖走,发现你画出了头,就开始推测是什么小动物。你不用反复发指令,它只是在你往前走的时候,持续看着前面的情况,有变化再提醒你一声。它放在一起对比的,不是小模型,都是 Qwen3-O
最近尝试了一个叫「全双工」的新全模态模型。
我在等红绿灯的时候,对手机说了一句:等绿灯亮了提醒我一下。然后就低头刷小说去了。过了一会儿,绿灯亮了,手机里的 AI 准时开口:绿灯亮了。

整个过程,它一直在看着红绿灯,但没有打断我看小说。就像一个人坐在旁边,该说的时候才说。
这种体验,在我过去一年多的多模态模型试用经历里,是第一次出现。
再比如,我用微波炉热东西,对它说了一句:一会儿如果你听到微波炉响,提醒我一下。说完我就故意把话题带走,摄像头也不照着微波炉,改成对着水

它照常接话,聊得很自然。过了一会儿,微波炉“叮”了一声。它几乎是立刻把我们刚才的话题停住了,无缝衔接提醒我:该去取东西了。
那种感觉很像有人在旁边听着动静,听到响就顺嘴提醒你一句。它开口输出,并没有影响它继续听。
这个模型叫 MiniCPM-o 4.5,面壁刚刚开源的。参数只有 9B,但它做到了一件之前几乎所有多模态模型都没做好的事——
边看、边听、主动说。
直白一点讲,从这个模型开始,视频对话的体验终于不再像一个“回合制的对讲机”了。
它可以一边说话,一边继续听、继续看。也就是说,它不会因为自己在输出,就暂停对外界的感知。
我测了几轮,体感非常明显。
我在学简笔画,随手画了一只很潦草的小猫,然后把画面给它看,顺口让它描述两句、顺带点评下。

注意,这里我一直没有停笔。我一边画它一边输出,线条一直在变。
你用过别的模型就知道,这种时候很容易出现两种尴尬:要么它一开口就进入讲完一段才停的状态,你改了它也当没看见。要么它为了实时,变成碎碎念,讲两句就卡一下,体验很割裂。
MiniCPM-o 4.5 的表现更像一个人坐在旁边看你画画。它在说的时候,眼睛还在跟着你笔尖走,发现你画出了头,就开始推测是什么小动物。当我把身体画的圆一点,它就知道这是一个胖嘟嘟的小猫。
整个过程不需要你停下来重新拍一张、重新问一次。
为什么会这样?
因为传统的多模态模型,本质上是“单工”的——就像对讲机,只能一边说话,一边听不见。
当它开始输出回答的时候,外界的声音和画面对它来说就是关闭的。它必须说完这一轮,才能重新接收信息。所以你跟它的每一次对话,都被强制切成了一段一段的回合。
MiniCPM-o 4.5 的核心改变,是从“单工”变“全双工”。
“全双工”这个词在通信领域其实非常老了,但放到大模型上,差别反而挺实在。
它开口的时候,外界的声音和画面不会被关掉。
你说话不会打断它的感知,环境变化也不会被它拖到说完再处理。
而 MiniCPM-o 4.5 的状态,更接近一种持续在线。
说真的,仔细联想一下,我甚至觉得这和最近 Clawdbot 火起来的那种爽感有点像。
大家喜欢 Clawdbot,很大一部分原因是它不像传统工具那样你点一下它动一下,它会把目标放在那儿,自己盯着进度往前跑。
MiniCPM-o 4.5 给我的感觉也接近。不只是 agent 能主动,全模态模型同样可以把“等待”和“察觉变化”这件事做得更自然。
而且,我再往下一翻,它的参数居然仅为 9B。。。
如果你对现在的多模态模型有一点概念,就知道 9B 在今天这个尺度下,根本不算大。尤其是在全模态、语音、视频同时跑的场景里,9B 通常意味着妥协。大几率反应慢一点,实时性别想太多。
但你看这组 benchmark ,事情反过来了。
先看能力雷达图。
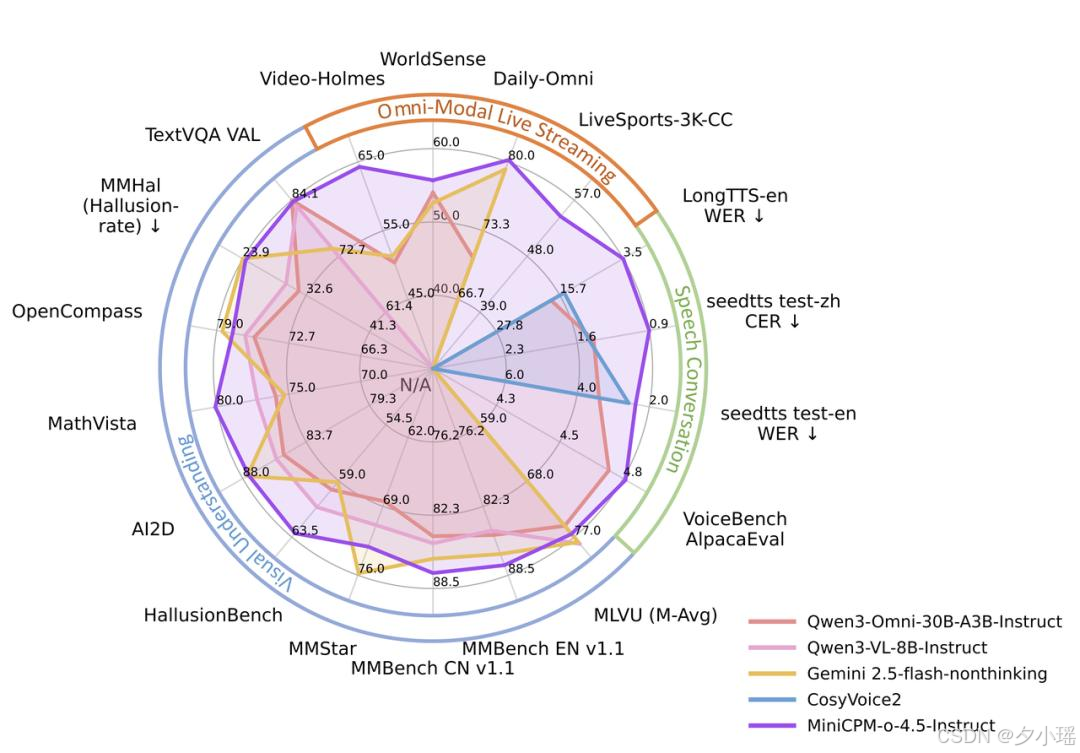
它放在一起对比的,不是小模型,都是 Qwen3-Omni 30B 这种量级的多模态模型,还有 Gemini Flash 这种以速度著称的方案。
你会发现一个非常反直觉的点。MiniCPM-o 4.5 在视频理解、视觉问答、文档解析、语音相关指标上,并没有明显退一步,甚至在一些实时场景下更稳定。
但真正决定体验的,其实是下面那张效率图。
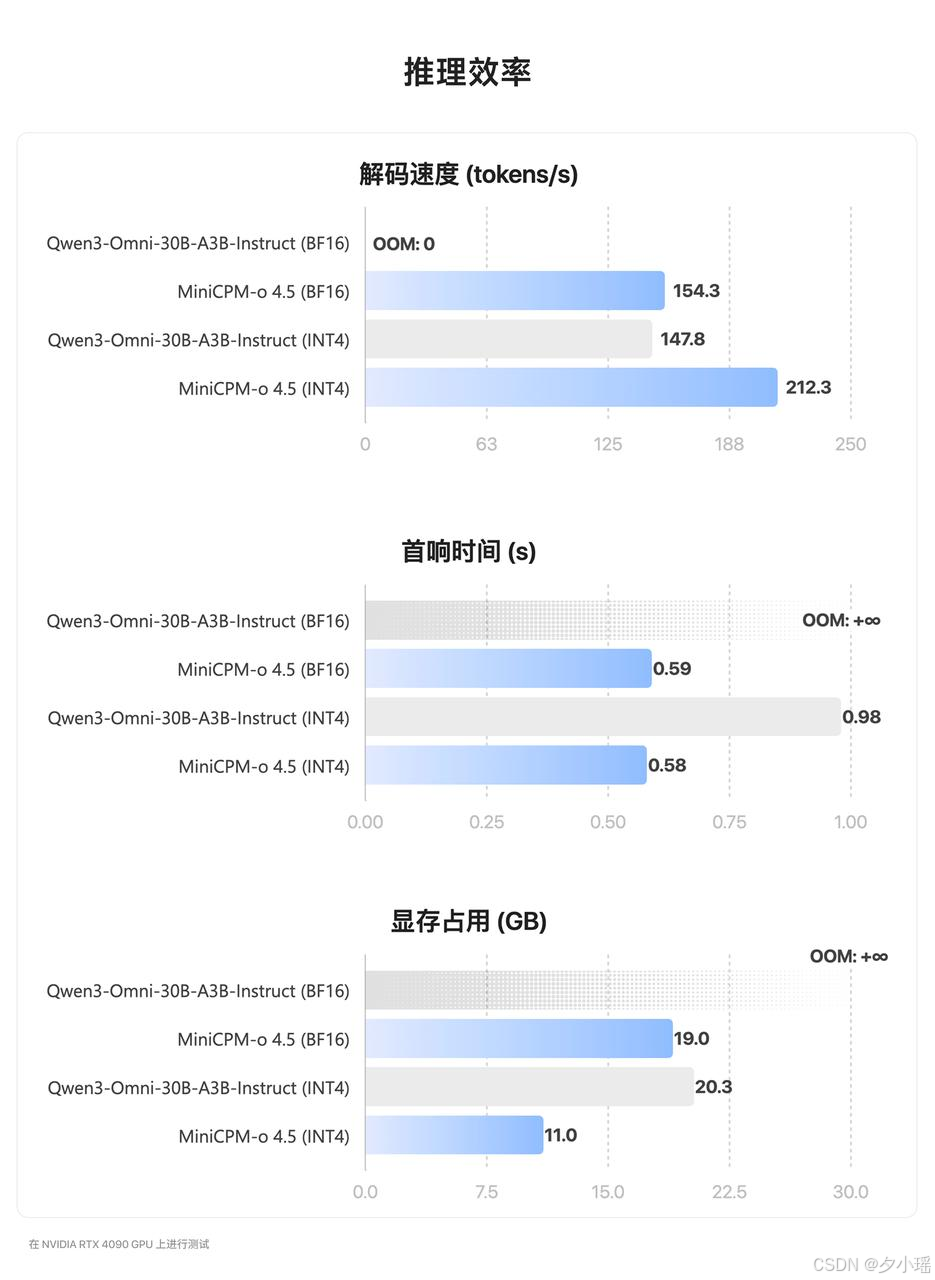
在同样的 RTX 4090 上测试,9B 的 MiniCPM-o 4.5,INT4 量化后解码速度能到 200 tokens/s 以上,首响时间稳定在 0.6 秒左右,显存占用只有 11GB。
而对比的 30B 级别 omni 模型,要么首响直接拉爆,要么显存占用不可控,根本谈不上持续在线。
全双工这件事,本身就是一场持续消耗算力的战争。你要一边说、一边听、一边看,还要不断做“要不要说”的决策。如果模型本身不够轻、不够省,那就只能退回到分阶段处理,用工程手段打补丁。
也正因为如此,过去你看到的所谓「伪双工」,几乎都发生在云端,用堆算力换体验。
而 MiniCPM-o 4.5 的特异之处在于,它用一个 9B 的体量,把这件事变成了默认状态。
你可能会问:它真的能自己判断时机吗?还是只是反应快一点而已?我又测了几轮更接近真实生活的场景。
比如对视力不太方便的朋友来说,它可以用来帮忙留意盲道上的障碍物。你不用反复发指令,它只是在你往前走的时候,持续看着前面的情况,有变化再提醒你一声。

那么,它在“等”的过程中,会不会把中间的信息弄丢?于是我顺手测了一下它的记忆力。
来一个记忆力大挑战试试,朋友们也可以玩一下:

规则其实不复杂,但要记的东西很多,看得我有点眼花缭乱。说实话,我第一遍我觉得是 4 个,还以为是它翻车了,又不服气地把过程倒回去重新对了一遍。
结果发现,是我错了。。
MiniCPM-o 4.5 给的答案是对的,而且对得挺干脆。有点东西。
然后我又顺手让它陪我下了一把井字棋。
它实时看到下棋子的位置,知道下一步下在哪里才能赢。
这些场景单独拎出来都不算惊艳,但连在一起,就会让你意识到一件事:
不只是 agent 能主动,全模态模型同样可以把“等待”和“察觉变化”这件事做得更自然。
这里还要提一下,面壁已经把 MiniCPM-o 4.5 开源了。
GitHub:
https://github.com/OpenBMB/MiniCPM-oHuggingFace:
https://huggingface.co/openbmb/MiniCPM-o-4_5
9B 的体量,因为足够小,可以被量化后部署在端侧设备上——手机、平板、智能眼镜、甚至智能音箱。
所以“边看、边听、主动说”的能力,不会只存在于云端,未来可以装进口袋里。因为开源,开发者可以基于它做各种定制和优化。
如果已经想要试试,可以去在线体验:
https://huggingface.co/spaces/openbmb/minicpm-omni

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献94条内容
已为社区贡献94条内容

所有评论(0)