WATERMARK ANYTHING WITH LOCALIZED MESSAGES论文阅读
论文介绍
在图片中隐藏人眼看不见的信息。传统的水印通常是给整张图打一个标签,而 WAM 可以给图片中的每一个像素、每一个特定物体打上不同的标签。即使你把图片剪碎、拼接或者修改,它依然能精准地指出“这一块区域是水印过的,隐藏信息是什么”。
现有痛点
现有的隐形水印技术存在几个主要问题:
无法应对“拼贴”:如果有人从一张有水印的图片里抠出一只猫,贴到另一张没水印的风景照上,传统技术通常会“懵圈”,无法检测出这只猫带着水印,因为它们是针对“整张图”做判断的 。
面积越小越难测:传统水印信号随着面积减小会变弱。如果水印区域只占图片的 10%,传统方法很难检测出来 。
定义模糊:如果一张图只有一小部分是 AI 生成的(带有水印),那整张图算不算有水印?传统方法只能给出一个“是”或“否”的全局答案,这不够精准,可能会误伤那些只用 AI 修补了一小块画面的艺术家 。
核心洞察
这篇论文最核心的突破在于重新定义了水印任务的范式。
从“分类”到“分割”的转变:传统水印技术通常对整张图片做一个全局判定。这导致当图片被裁剪、拼接或局部编辑时,传统方法往往失效 。WAM 将水印任务重新定义为语义分割任务。它不是预测整张图的一个标签,而是对每一个像素预测其是否包含水印以及对应的二进制编码 。
解耦信号强度与面积: 传统水印中,水印信号的检测强度通常随面积减小而衰减。WAM 的目标是将水印信号的强度与像素表面积解耦,即使在极小的区域(如图像的 10%)也能提取出完整信息 。
多水印共存: 由于采用了像素级预测,WAM 可以在同一张图片的不同区域嵌入和提取完全不同的消息。这对于检测合成图像(例如由多张 AI 生成图片拼接而成的拼贴画)至关重要,这是传统单一消息水印无法做到的 。
方法论
WATERMARK ANYTHING MODELS(WAM)。WAM分为水印嵌入器和水印提取器。
水印嵌入器
设计:一个轻量级的变分自编码器 (VAE) 架构,仅包含约 110 万参数,便于在用户端快速运行 。
流程:编码器将图像压缩到潜在空间;32位二进制消息通过查找表映射为张量并与图像特征拼接;解码器输出与原图同尺寸的水印信号δ。
叠加: 水印信号经过 Tanh 激活后,以残差形式叠加到原图上 。
水印提取器
设计: 一个较重的模型(约 9600 万参数,ViT-Base),采用类似 Segment Anything (SAM) 的架构 。
输出: 输出一个1 + n_bits通道的张量。第 1 个通道预测该像素是否含有水印(检测掩码),后 32 个通道预测该像素对应的二进制位(解码掩码)。
两阶段训练策略
为了平衡“鲁棒性”和“不可感知性”,作者采用了分阶段训练 :
阶段一:鲁棒性与定位:
目标: 不考虑画质,专注于让模型在极端攻击下也能定位和解码。
数据增强 (The Augmenter): 这是核心所在。训练中随机生成掩码(矩形、不规则笔触、物体轮廓),将“水印图”和“原图”拼接(Splicing)。随后应用剧烈的几何变换(裁剪、旋转)和像素变换(模糊、JPEG压缩)。
损失函数: 使用像素级交叉熵损失进行检测,仅在水印区域计算二元交叉熵损失进行解码 。ℓ(θ) = λdet · ℓdet(θ) + λdec · ℓdec(θ).
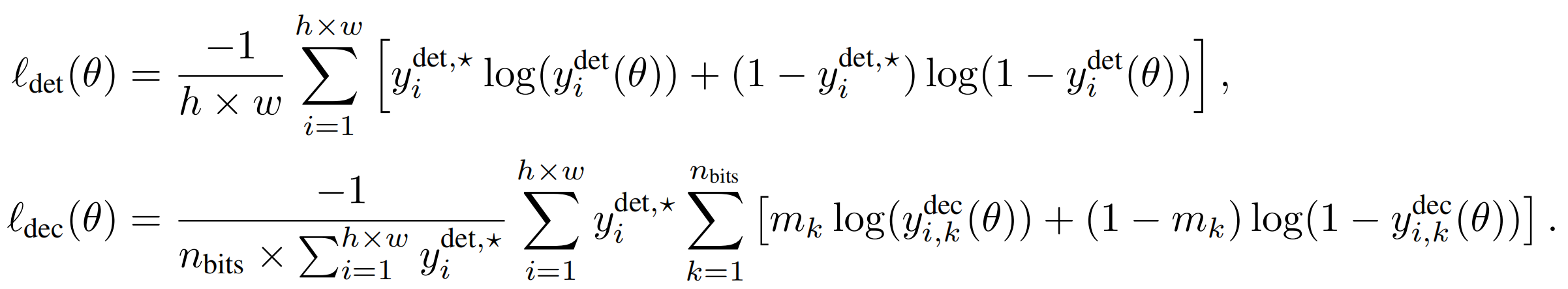
阶段二:隐形性与多水印:
引入 JND (最小可觉差): 利用人类视觉系统特性计算 JND 热力图。在纹理复杂区增强水印信号,在平滑区(如天空)抑制信号,从而实现视觉上的“隐形” 。
多水印训练: 随机在同一张图中嵌入 1 到 3 个不重叠的掩码,每个掩码对应不同的消息。这迫使提取器放弃利用全局上下文“猜”消息,而是必须逐像素地进行局部解码 。

左边为第一阶段,右边为第二阶段
DBSCAN 聚类算法
简单来说,提取器会对每个像素“喊出”它认为的一串密码(比如 32 位二进制码),而 DBSCAN 负责把这些嘈杂的声音归类,找出那几个最响亮、最一致的“合唱声音”作为最终的水印消息。
在 WAM 的设定中,一张图片可能包含多个水印,也可能只有部分区域有水印。提取器输出的是每一个像素对应的二进制字符串。这就带来了两个难题:
- 数量未知: 我们不知道图里藏了几个水印(是 1 个,3 个,还是 5 个?)。
- 噪声干扰: 并不是所有像素预测都是准的。有些像素(尤其是边缘或非水印区域)可能会预测出随机的乱码(噪声),需要被剔除 。
DBSCAN 完美解决了这两个问题:它不需要预设聚类数量,并且能自动识别并过滤噪声 。
DBSCAN 基于“密度”来聚类。它的核心逻辑是:如果一个点周围有很多“邻居”(密度大),它们就属于同一个聚类;如果一个点孤零零的(密度低),它就是噪声。它主要依赖两个参数 :
ε: 邻域半径。即两个点之间距离多少算“邻居”。
min_simple:最小样本数。即一个范围内至少要有几个点,才能形成一个核心聚类。
具体应用:
首先,只保留那些检测分数超过阈值(论文中设为 0.5)的像素。这些是被模型认为“有水印”的像素 。DBSCAN 需要计算点与点之间的距离。在 WAM 中,距离被定义为两个二进制消息之间的 比特差异 (Bit Difference) 。例如:消息 1010 和 1011 的距离是 1。算法遍历所有筛选出的像素消息:如果一群像素预测出的消息彼此之间的比特差异小于ε,且这群像素的数量超过 min_simple,它们就被归为一个“水印消息簇”。聚类完成后,算法会计算每个簇的中心点 (Centroid)。这个中心点就是最终解码出的二进制消息 。
实验结果
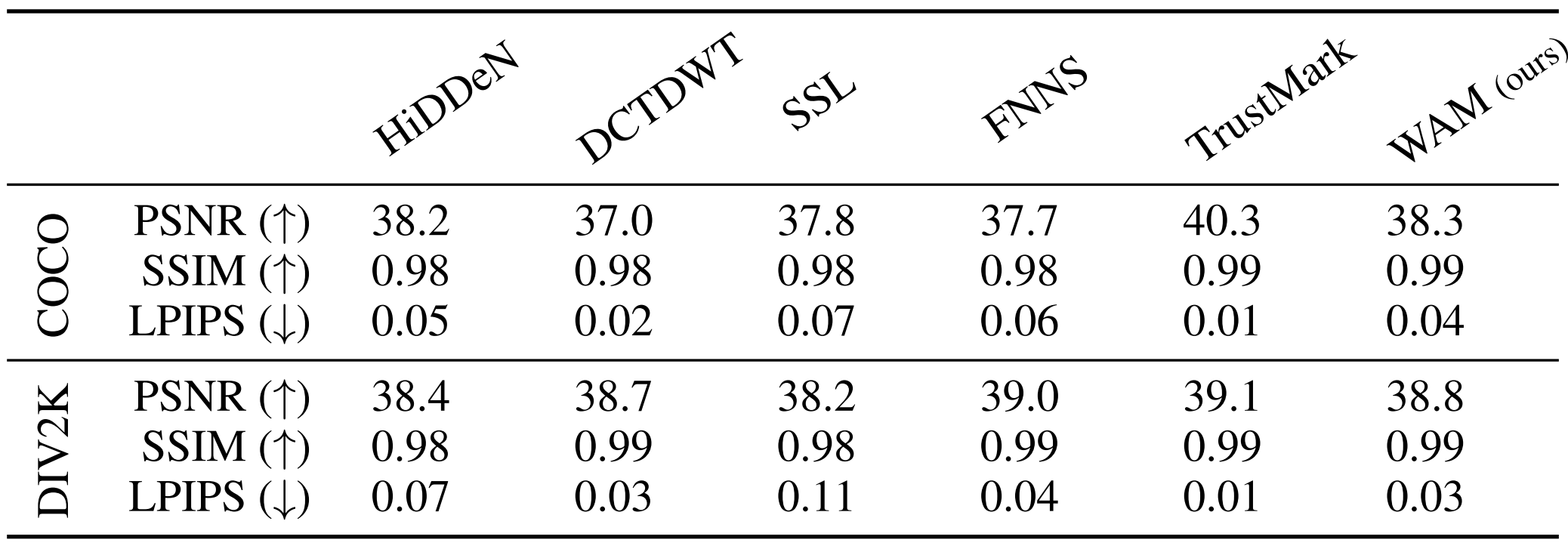
本文与HiDDeN、DCTDWT、SSL、FNNS、TrustMark进行对比。报 告 了 COCO(低 /中 分 辨 率 )和 DIV2k(高 分 辨 率 )的 水 印 图 像 和 原 始 图 像 之 间 的 PSNR, SSIM和 LPIPS。可以看到,与当前先进的水印方法并无明显差距。
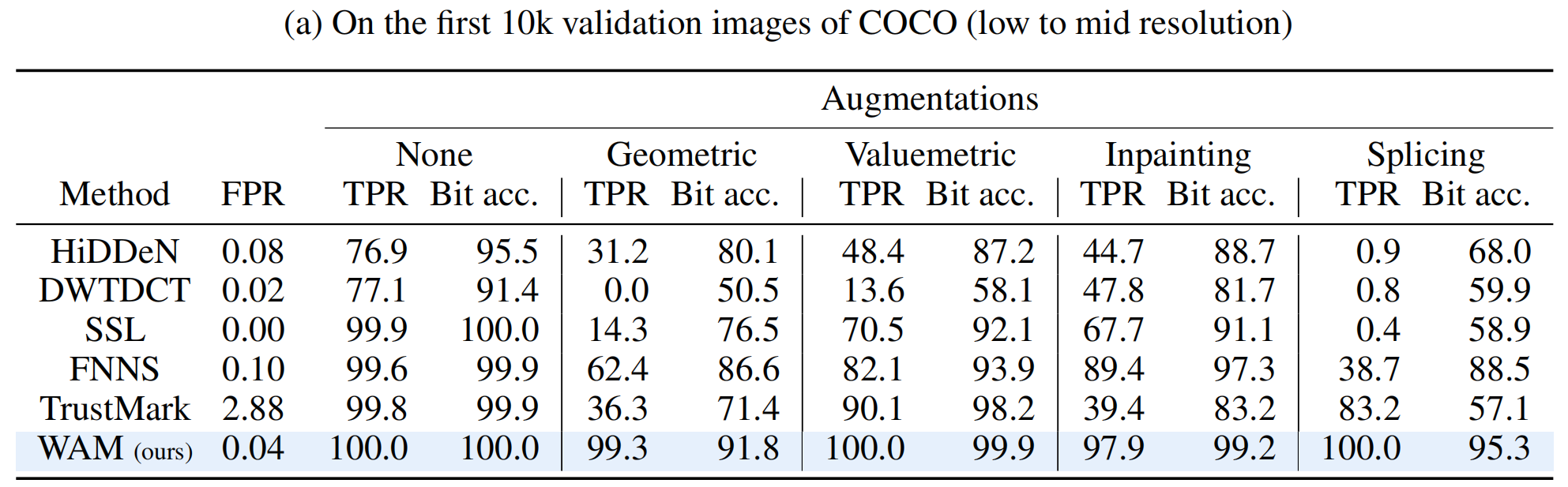
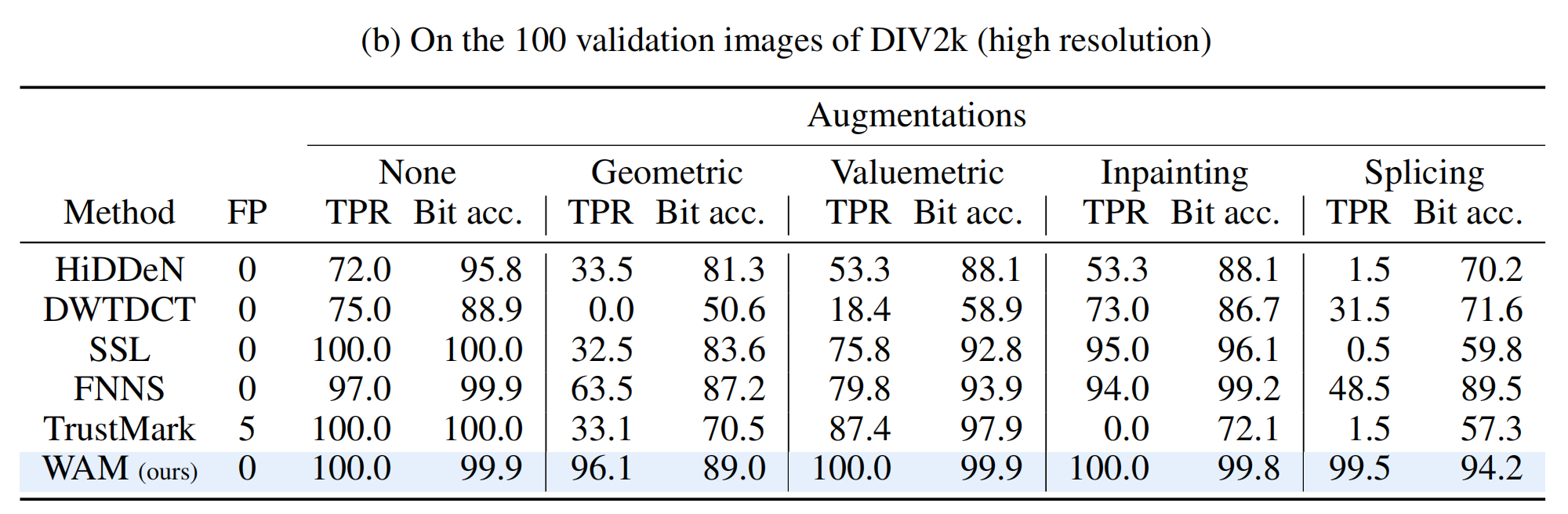
实验在 COCO 和 DIV2k 数据集上进行,重点评估了 WAM 在面对复杂现实攻击时的表现。这是 WAM 展现统治力的领域。传统的全局水印方法(如 HiDDeN, TrustMark)在面对局部操作时往往失效,而 WAM 表现出色 。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)