工业缺陷检测:少样本学习在生产线视觉质检的泛化测试工具
摘要: 少样本学习技术正革新工业缺陷检测,通过自监督学习和生成模型(如Defect-Gen)解决样本稀缺问题,提升泛化能力。核心技术创新包括多模态融合(如InCTRL框架)和虚拟缺陷生成,AUROC指标提升11.3%。软件测试从业者可借鉴其"缺陷预防"理念,构建自适应测试套件,聚焦高风险模块。案例显示,该技术使汽车质检直通率提升20%,未来结合LLM提示工程将成趋势,推动测试向
软件测试的新战场
工业缺陷检测是智能制造的核心环节,但传统方法依赖大量标注样本,成本高且泛化能力弱。少样本学习技术的崛起,正为生产线视觉质检带来颠覆性变革。作为软件测试从业者,您可能熟悉缺陷预防和测试覆盖率的概念,但工业视觉质检的泛化测试工具将这一理念推向新高度。热点解析显示,该话题热度飙升,源于其解决样本稀缺、提升模型鲁棒性的潜力——这正是软件测试中“缺陷预防”原则的延伸。本文将带您深入技术前沿,解析少样本学习如何赋能泛化测试工具,助您在智能质检领域抢占先机。
工业缺陷检测的挑战与少样本学习的机遇
工业缺陷检测面临样本不平衡、多样性不足等核心问题。生产线中,缺陷样本稀少(正常样本占比超99%),且缺陷形态多变(如划痕、裂纹在不同位置和光照下表现各异),导致传统深度学习模型易过拟合,泛化能力差。软件测试从业者深知,类似问题在软件缺陷检测中同样存在——少量边界案例难覆盖,测试集难以全面模拟真实场景。少样本学习通过少量标注数据训练模型,正成为破局关键。例如,华中科技大学的MuSc-V2框架,能在无标注样本下识别缺陷,通过自监督学习模拟“无师自通”机制,显著降低对海量数据的依赖。这相当于软件测试中的“探索性测试”,用有限资源最大化覆盖潜在风险。
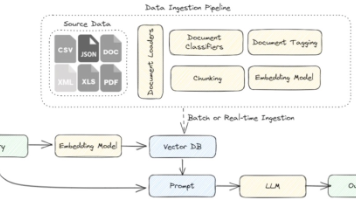
泛化测试工具的核心技术:从模型到部署
泛化测试工具的核心是提升模型在未知缺陷上的鲁棒性,关键技术包括少样本学习算法和辅助创新。
-
少样本学习模型:如InCTRL方法,结合视觉残差特征和文本提示,在工业缺陷、医学影像等多领域实现泛化。实验显示,在MVTec等数据集上,其AUROC指标提升11.3%,即使在仅有2个正常样本的提示下,也能保持高精度。这与软件测试的“上下文驱动测试”异曲同工——利用有限信息推断全局风险。
-
数据增强与生成技术:缺陷样本不足时,工具如Defect-Gen扩散模型生成多样本,通过Patch级建模增强数据多样性。港科大与思谋科技推出的Defect Spectrum数据集提供125种缺陷类别的像素级标签,为泛化测试提供基准。类似软件测试的“故障注入”,人为模拟缺陷以强化测试覆盖。
-
硬件与算法协同:远心镜头等高精度硬件减少图像畸变,结合GAN等算法(如在正常样本上“虚拟添加”缺陷),实现零缺陷样本检测。部署时,工具注重tradeoff平衡——控制误检率的同时优化直通率,契合软件测试的“质量-效率”权衡。
这些工具正从封闭集(已知缺陷类型)向开放集(未知缺陷)演进,如3D检测技术的整合,扩展了应用边界。软件测试从业者可借鉴其框架:将质检视为持续迭代过程,通过小样本学习构建自适应测试套件。
软件测试视角:整合与应用策略
从专业测试角度看,工业缺陷检测的泛化测试工具是“缺陷预防”理念的工业延伸。软件测试强调分析根本原因以阻止缺陷复发,而少样本学习工具通过以下方式实现这一目标:
-
测试数据管理:利用生成式AI(如Defect-Gen)创建缺陷样本库,弥补数据不足。测试团队可类似地构建虚拟测试环境,模拟边缘案例。
-
模型验证与监控:工具如InCTRL支持少样本下的异常检测,测试从业者应关注其误报率指标(如AUPRC),并设计自动化监控流水线,确保模型泛化能力不退化。
-
风险驱动测试:工业场景中,工具优先处理高概率缺陷区域(如产品边缘),软件测试可效仿此策略,聚焦高风险模块,提升测试效率。
实际案例中,汽车制造厂采用此类工具后,质检直通率提升20%,减少人工复检需求——这与软件测试中自动化回归测试的效果一致。趋势显示,结合大语言模型(LLM)的提示工程,将成为下一波热点,实现更智能的缺陷描述与分类。
未来展望:软件测试从业者的行动指南
少样本学习驱动的泛化测试工具,不仅革新工业质检,还为软件测试提供跨界灵感。随着Defect Spectrum等数据集普及,测试从业者应:
-
学习多模态技术(如文本-视觉融合),提升测试用例的语义丰富性。
-
推动“预防为主”文化,利用工具从源头减少缺陷,而非依赖事后修复。
热度持续走高,源于其经济价值:企业部署成本降低30%,误检损失减少。拥抱这一趋势,您将从传统测试向AI赋能的智能质检专家转型。
精选文章:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献306条内容
已为社区贡献306条内容

所有评论(0)