解决Spring AI聊天记录丢失:自定义Advisor实现持久化存储
一、数据消失原因
在 Spring AI 的默认设计中,我们通常使用 MessageWindowChatMemory来管理会话上下文。它的核心作用是限制发送给大模型的 Token 数量,防止上下文超长。
但需要注意的是,Spring AI 默认保存的只是短期记忆,即大模型上下文里的内容。
让我们直接查看 MessageWindowChatMemory.java的源码(位于 org.springframework.ai.chat.memory包下),重点关注 add方法:
1.1 源码分析:add 方法
@Override
public void add(String conversationId, List<Message> messages) {
Assert.hasText(conversationId, "conversationId cannot be null or empty");
Assert.notNull(messages, "messages cannot be null");
Assert.noNullElements(messages, "messages cannot contain null elements");
// 1. 从数据库(Repository)取出当前会话的所有消息
List<Message> memoryMessages = this.chatMemoryRepository.findByConversationId(conversationId);
// 2. 【关键点】调用 process 方法处理消息(合并新消息 + 截断)
List<Message> processedMessages = process(memoryMessages, messages);
// 3. 将处理后的结果"覆盖"回数据库
this.chatMemoryRepository.saveAll(conversationId, processedMessages);
}深度解读:
-
findByConversationId:从底层 Repository(如 MySQL)中取出当前会话的所有历史消息。假设数据库现有 50 条记录。 -
process:调用内部方法合并旧消息和新消息,并根据窗口大小进行处理。 -
saveAll:将处理后的结果全量覆盖回数据库。这是关键操作,如果process方法丢弃了某些消息,这些消息在数据库中也会被同步删除。
1.2 源码分析:process 方法(核心问题所在)
private List<Message> process(List<Message> memoryMessages, List<Message> newMessages) {
// ... 省略部分合并逻辑 ...
// 合并旧消息和新消息
processedMessages.addAll(newMessages);
// 如果总数没超过 maxMessages,直接返回
if (processedMessages.size() <= this.maxMessages) {
return processedMessages;
}
// 【致命逻辑】如果超过了 maxMessages,开始移除旧消息!
int messagesToRemove = processedMessages.size() - this.maxMessages;
List<Message> trimmedMessages = new ArrayList<>();
int removed = 0;
for (Message message : processedMessages) {
// 如果是 SystemMessage 或者 已经删够了数量,才保留
if (message instanceof SystemMessage || removed >= messagesToRemove) {
trimmedMessages.add(message);
}
else {
removed++; // 计数器+1,这条消息被丢弃了,不会加入 trimmedMessages
}
}
return trimmedMessages; // 返回的是"阉割"后的列表
}深度解读:
假设 maxMessages设置为 50,数据库已有 50 条历史消息,用户发送 1 条新消息:
-
全量聚合:
-
processedMessages.addAll(newMessages):新消息追加到旧消息列表 -
结果:
processedMessages共有 51 条消息(索引 0 ~ 50)
-
-
阈值检查:
-
if (processedMessages.size() <= this.maxMessages):51 > 50,条件不满足 -
触发"裁员"流程
-
-
计算移除数量:
-
int messagesToRemove = 51 - 50 = 1 -
需要移除 1 条最旧消息
-
-
滑动窗口筛选:
-
从头(最旧消息)开始遍历,配合
removed计数器 -
索引 0(最旧消息):
-
非 SystemMessage
-
removed(0) <messagesToRemove(1) -
结果:丢弃,
removed自增为 1
-
-
索引 1(次旧消息):
-
非 SystemMessage
-
removed(1) >=messagesToRemove(1) -
结果:保留
-
-
后续消息:全部保留
-
-
最终结果:
-
返回仅包含后 50 条消息的
trimmedMessages -
致命后果:最早 1 条历史记录被物理删除
-
流程闭环:add方法取出 50 条 → 合并 1 条新消息 → process删除第 1 条 → 返回后 50 条 → 存回数据库。
1.3 痛点总结
完整流程:
-
读:数据库 50 条记录
-
加:+1 条新消息 = 51 条
-
切:
process发现 51 > 50,删除第 1 条 -
存:
repository.saveAll覆盖为 50 条
结果:数据库永远只有最近 50 条,之前历史记录永久丢失。这对需要审计、回溯、数据分析的业务系统不可接受。
二、思路分析
2.1 官方文档的启示
Spring AI 官方文档隐晦提到:ChatMemory设计初衷不是持久化聊天记录方案。
这种方案的设计目的是管理模型上下文的短期记忆(Short-term Memory),而不是整个聊天记录(Chat History / Audit Log)。D
两种记忆概念:
-
短期记忆 (Short-term Memory):模型层面概念,存在于模型上下文中,受限于 LLM Context Window,必须截断
-
聊天记录 (Chat History):业务层面概念,要求全量保存、永久存储、不可丢失
结论:不应修改 ChatMemory源码,否则违背设计初衷,导致 Prompt 无限膨胀。
2.2 解决思路:AOP 与 Advisor
跳出 ChatMemory圈子,从大模型交互本质入手。
大模型本质是输入(Input)输出(Output)的函数工具。
Spring AI 使用 Advisor(增强器)模式,基于 AOP 思想。通过 Advisors 拦截请求和响应。
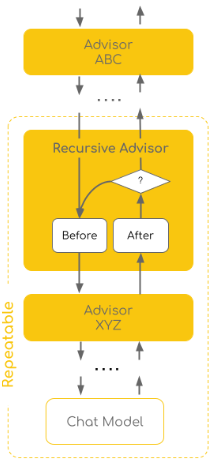
上图是 Spring AI 文档中对于 Advisors 的介绍。可以看到,Advisor 处于 ChatClient 和底层 ChatModel 之间,像关卡一样层层拦截递归执行。
核心思路:
编写自定义 Advisor,不修改 ChatMemory:
-
拦截请求:用户提问前保存到数据库
-
拦截响应:AI 回答后保存到数据库
"短期记忆管理"(截断)交给 ChatMemory,"长期历史记录"(落库)交给 Advisor,职责分离。
三、自定义 Advisor 实战
3.1 Advisor 接口详解
实现两个核心接口:
-
CallAdvisor:拦截同步调用,核心方法adviseCall -
StreamAdvisor:拦截流式调用,核心方法adviseStream
3.2 官方示例解读:SimpleLoggerAdvisor
SimpleLoggerAdvisor是模板,"打印日志"和"保存日志到数据库"逻辑相同。
public class SimpleLoggerAdvisor implements CallAdvisor, StreamAdvisor {
private static final Logger logger = LoggerFactory.getLogger(SimpleLoggerAdvisor.class);
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return 0;
}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
// 记录请求
logRequest(chatClientRequest);
// 执行后续调用
ChatClientResponse chatClientResponse = callAdvisorChain.nextCall(chatClientRequest);
// 记录响应
logResponse(chatClientResponse);
return chatClientResponse;
}
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain streamAdvisorChain) {
// 记录请求
logRequest(chatClientRequest);
// 执行流式请求
Flux<ChatClientResponse> chatClientResponses = streamAdvisorChain.nextStream(chatClientRequest);
// 聚合流式响应
return new ChatClientMessageAggregator().aggregateChatClientResponse(chatClientResponses, this::logResponse);
}
// ... 省略具体实现 ...
}深度解析:
-
getOrder():控制执行顺序 -
adviseCall:环绕通知,可获取请求前后数据 -
adviseStream与MessageAggregator:流式响应聚合,获取完整文本
四、核心实现:ChatHistoryRecordAdvisor
目标:拦截对话,将"用户提问"和"AI 回答"持久化到 MySQL 的 spring_ai_chat_message_log表。
4.1 完整代码
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClientMessageAggregator;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.CallAdvisor;
import org.springframework.ai.chat.client.advisor.api.CallAdvisorChain;
import org.springframework.ai.chat.client.advisor.api.StreamAdvisor;
import org.springframework.ai.chat.client.advisor.api.StreamAdvisorChain;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.MessageType;
import org.springframework.core.Ordered;
import org.springframework.stereotype.Component;
import reactor.core.publisher.Flux;
import java.time.LocalDateTime;
/**
* 聊天历史记录增强器
* 用于拦截 ChatClient 的请求和响应,并将对话记录持久化到数据库中。
*/
@Component
@RequiredArgsConstructor
@Slf4j
public class ChatHistoryRecordAdvisor implements CallAdvisor, StreamAdvisor {
private final ISpringAiChatMessageLogService messageLogService;
private final ISpringAiChatRecordService chatRecordService;
@Override
public String getName() {
return this.getClass().getSimpleName();
}
/**
* 设置最高优先级 (HIGHEST_PRECEDENCE)
* 目的:确保在其他 Advisor(如 RAG 的 QuestionAnswerAdvisor)之前执行。
* 这样我们可以获取到用户最原始的 Prompt,而不是被 RAG 修改/拼接后的 Prompt。
*/
@Override
public int getOrder() {
return Ordered.HIGHEST_PRECEDENCE;
}
/**
* 拦截非流式调用
*/
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
// 1. 提取原始的用户请求文本(在 RAG 修改之前)
String originalUserText = extractUserText(chatClientRequest);
// 2. 放行请求,继续执行后续的 Advisor 链和 AI 调用
ChatClientResponse response = callAdvisorChain.nextCall(chatClientRequest);
// 3. AI 响应回来后,记录日志(包括用户问题和 AI 回答)
saveLog(chatClientRequest, response, originalUserText);
return response;
}
/**
* 拦截流式调用
*/
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain streamAdvisorChain) {
// 1. 同样先提取原始用户文本
String originalUserText = extractUserText(chatClientRequest);
// 2. 执行流式请求
Flux<ChatClientResponse> responseFlux = streamAdvisorChain.nextStream(chatClientRequest);
// 3. 聚合流式响应,以便获取完整的 AI 回答内容进行存储
// 注意:这里不会阻塞流的返回,而是利用 Reactor 的副作用进行异步记录
return new ChatClientMessageAggregator().aggregateChatClientResponse(responseFlux, aggregatedResponse -> {
saveLog(chatClientRequest, aggregatedResponse, originalUserText);
});
}
/**
* 从请求中提取最后一条用户消息的内容
*/
private String extractUserText(ChatClientRequest request) {
try {
return request.prompt().getInstructions().stream()
.filter(m -> m.getMessageType() == MessageType.USER)
.reduce((first, second) -> second) // 获取最后一条,通常是当前用户的提问
.map(Message::getText)
.orElse("");
} catch (Exception e) {
log.warn("Failed to extract user text", e);
return "";
}
}
/**
* 保存聊天日志到数据库
*
* @param request 请求对象,包含上下文信息(如 sessionId)
* @param response 响应对象,包含 AI 的回答
* @param userText 提取出的用户原始问题
*/
private void saveLog(ChatClientRequest request, ChatClientResponse response, String userText) {
try {
// 1. 获取会话 ID
String sessionId = (String) request.context().get(ChatMemory.CONVERSATION_ID);
if (sessionId == null) {
return;
}
// 2. 尝试获取用户 ID (从 ChatRecord 表中查找)
Long userId = null;
SpringAiChatRecord chatRecord = chatRecordService.getById(sessionId);
if (chatRecord != null && chatRecord.getUserId() != null) {
try {
userId = Long.parseLong(chatRecord.getUserId());
} catch (NumberFormatException e) {
log.warn("Invalid user ID format: {}", chatRecord.getUserId());
}
}
// 3. 保存用户提问日志
if (userText != null && !userText.isEmpty()) {
SpringAiChatMessageLog userLog = new SpringAiChatMessageLog()
.setSessionId(sessionId)
.setUserId(userId)
.setMessageType("USER")
.setContent(userText)
.setCreateTime(LocalDateTime.now());
messageLogService.save(userLog);
}
// 4. 保存 AI 回复日志
if (response.chatResponse() != null &&
response.chatResponse().getResult() != null &&
response.chatResponse().getResult().getOutput() != null) {
String assistantContent = response.chatResponse().getResult().getOutput().getText();
SpringAiChatMessageLog assistantLog = new SpringAiChatMessageLog()
.setSessionId(sessionId)
.setUserId(userId)
.setMessageType("ASSISTANT")
.setContent(assistantContent)
.setCreateTime(LocalDateTime.now());
messageLogService.save(assistantLog);
}
} catch (Exception e) {
log.error("Error saving chat history log", e);
}
}
}4.2 深度代码解析
1. 最高优先级设置
@Override
public int getOrder() {
return Ordered.HIGHEST_PRECEDENCE;
}关键原因:确保在 RAG Advisor 修改 Prompt 前执行,获取用户原始问题。
2. 用户文本提取逻辑
request.prompt().getInstructions().stream()
.filter(m -> m.getMessageType() == MessageType.USER)
.reduce((first, second) -> second)-
筛选用户消息
-
取最后一条(当前最新提问)
3. 流式响应聚合
return new ChatClientMessageAggregator().aggregateChatClientResponse(responseFlux, aggregatedResponse -> {
saveLog(chatClientRequest, aggregatedResponse, originalUserText);
});-
不影响首字延迟
-
异步记录完整回复
注意:未实现 Function Calling 存储逻辑,可根据业务扩展。
五、数据库设计与配置
5.1 数据库表结构
-- 用户聊天记录日志表
create table spring_ai_chat_message_log
(
id bigint auto_increment comment '主键ID'
primary key,
session_id varchar(50) not null comment '会话ID,对应 ChatMemory 中的 conversationId',
user_id bigint unsigned null comment '用户ID,用于关联业务用户',
message_type varchar(20) not null comment '消息类型: USER (提问), ASSISTANT (回答)',
content longtext null comment '消息内容,使用 LongText 防止长文本截断',
tool_calls longtext null comment '工具调用信息(JSON),预留字段',
create_time timestamp default CURRENT_TIMESTAMP not null comment '创建时间'
)
comment '用户聊天记录日志表';
-- 建立索引,加速查询
create index idx_session_id on spring_ai_chat_message_log (session_id);
create index idx_user_id on spring_ai_chat_message_log (user_id);设计要点:
-
session_id:关联上下文核心,必须有索引 -
content:使用longtext防止长文本截断 -
tool_calls:预留 Function Calling 存储字段
5.2 配置 ChatClient
@Configuration
public class ChatConfig {
@Bean
public ChatClient serviceChatClient(AlibabaOpenAiChatModel model,
ChatMemory chatMemory,
VectorStore vectorStore,
ChatHistoryRecordAdvisor chatHistoryRecordAdvisor) {
return ChatClient.builder(model)
.defaultAdvisors(
// 1. 日志 Advisor (官方)
SimpleLoggerAdvisor.builder().build(),
// 2. 【核心】历史记录 Advisor
chatHistoryRecordAdvisor,
// 3. 上下文记忆 Advisor (负责短期记忆截断)
MessageChatMemoryAdvisor.builder(chatMemory).build(),
// 4. RAG 检索增强 Advisor
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder().similarityThreshold(0.5d).topK(1).build())
.build()
)
.defaultSystem("你是一个智能助手...")
.build();
}
}配置详解:
-
ChatHistoryRecordAdvisor:负责全量记录,不做删除 -
MessageChatMemoryAdvisor:负责滑动窗口截断 -
两者配合,既保证大模型不溢出,又保证数据库永久记录
六、总结
纠正常见误区:不要用 ChatMemory做持久化业务日志。
-
ChatMemory (短期记忆):给大模型看,必须截断
-
Advisor (长期日志):给人看,全量保存
这种读写分离架构解决"数据消失"问题,解耦业务逻辑与 AI 框架逻辑,是生产级 AI 应用的最佳实践。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)