02—langchain Model
本文介绍了LangChain框架中模型调用的核心概念和实现方式。主要内容包括: 模型调用流程:分为Format(输入格式化)、Predict(模型预测)、Parse(输出解析)三个步骤。 环境配置:介绍了如何设置环境变量和使用dotenv包管理API密钥。 模型分类: 非对话模型(LLMs):适合单次文本生成任务 对话模型(Chat Models):支持多轮对话,是主要调用方式 嵌入模型:将文本转
Model

- Format(格式化):即指代 Prompts Template,通过模板管理大模型的输入。将原始数据格式化成模型可以处理的形式,插入到一个模板问题中,然后送入模型进行处理。
- Predict(预测):即指代 Models,使用通用接口调用不同的大语言模型。接受被送进来的问题,然后基于这个问题进行预测或生成回答。
- Parse(生成):即指代 Output Parser 部分,用来从模型的推理中提取信息,并按照预先设定好的模版来规范化输出。比如,格式化成一个结构化的 JSON 对象。
简单来说,就是输⼊、模型处理、输出这三个步骤
环境变量
- 在项目新建
.env文件,并添加以下内容:
OPENAI_API_KEY=xxx
OPENAI_BASE_URL=xxx
- 安装
dotenv包
uv pip install dotenv
- 使用变量
import dotenv
dotenv.load_dotenv()
print(os.getenv("OPENAI_API_KEY"))
print(os.getenv("OPENAI_BASE_URL"))
模型调用的分类
按照模型功能的不同
- 非对话模型:LLMs、Text Model
- 对话模型:Chat Models
- 嵌入模型:Embedding Models
非对话模型(LLMs)
LLMs,也叫 Text Model、非对话模型,是许多语言模型应用程序的支柱。主要特点如下:
- 输入:接受 文本字符串 或 PromptValue 对象
- 输出:总是返回 文本字符串

- 适用场景:仅需单次文本生成任务(如摘要生成、翻译、代码生成、单次问答)或对接不支持消息结构的旧模型(如部分本地部署模型)(言外之意,优先推荐 ChatModel)
- 不支持多轮对话上下文:每次调用独立处理输入,无法自动关联历史对话(需手动拼接历史文本)。
- 局限性:无法处理角色分工或复杂对话逻辑。
import os
import dotenv
from langchain_openai import OpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
llm = OpenAI()
str = llm.invoke("写一首关于春天的诗")
print(str)
对话模型(Chat Models)
ChatModels,也叫聊天模型、对话模型,底层使用 LLMs。大语言模型调用,以 ChatModel 为主!
主要特点如下:
- 输入:接收消息列表
List[BaseMessage]或PromptValue,每条消息需指定角色(如 SystemMessage、HumanMessage、AIMessage) - 输出:总是返回带角色的 消息对象(
BaseMessage子类),通常是AIMessage

- 原生支持多轮对话:通过消息列表维护上下文(例如:
[SystemMessage, HumanMessage, AIMessage, ...]),模型可基于完整对话历史生成回复。 - 适用场景:对话系统(如客服机器人、长期交互的 AI 助手)
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
import os
import dotenv
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
messages = [
SystemMessage(content="我是人工智能助手,我叫小智"),
HumanMessage(content="你好,我是小明,很高兴认识你")
]
response = chat_model.invoke(messages)
print(type(response)) # <class 'langchain_core.messages.ai.AIMessage'>
print(response.content)
嵌入模型(Embedding Model)
Embedding Model:也叫文本嵌入模型,这些模型将 文本 作为输入并返回 浮点数列表 ,也就是
Embedding。
import os
import dotenv
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
embeddings_model = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
res = embeddings_model.embed_query('我是文档中的数据')
print(res)
对话模型中 message 的使用
聊天模型,除了将字符串作为输入外,还可以使用 聊天消息 作为输入,并返回 聊天消息 作为输出。
LangChain 有一些内置的消息类型:
- 🔥
SystemMessage:设定 AI 行为规则或背景信息。比如设定 AI 的初始状态、行为模式或对话的总体目标。比如“作为一个代码专家”,或者“返回 json 格式”。通常作为输入消息序列中的第一个传递。 - 🔥
HumanMessage:表示来自用户输入。比如“实现一个快速排序方法” - 🔥
AIMessage:存储 AI 回复的内容。这可以是文本,也可以是调用工具的请求 ChatMessage:可以自定义角色的通用消息类型FunctionMessage/ToolMessage:函数调用/工具消息,用于函数调用结果的消息类型
注意:
FunctionMessage和ToolMessage分别是在函数调用和工具调用场景下才会使用的特殊消息类型,HumanMessage、AIMessage和SystemMessage才是最常用的消息类型。
invoke()的输入可以是多种类型的,例如:字符串类型、消息列表invoke()的输出是一个消息对象,通常为 AIMessage(BaseMessage 的子类)`)。
invoke() 字符串类型
from langchain_ollama import ChatOllama
chat_model = ChatOllama(
model="qwen3:0.6b"
)
response = chat_model.invoke('你好')
print(response)
openai 的可以安装
langchain_openai包
invoke() 消息列表类型
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_ollama import ChatOllama
chat_model = ChatOllama(
model="qwen3:0.6b"
)
messages = [
SystemMessage("你是一位乐于助人的智能小助手wifi歪f"),
HumanMessage(content="你好,请你介绍一下你自己")
]
response = chat_model.invoke(messages)
print(response.content)
# 你好!我是您的智能助手WiFi歪f,很高兴为您提供帮助!有什么可以帮助您的吗?
多轮对话和上下文记忆
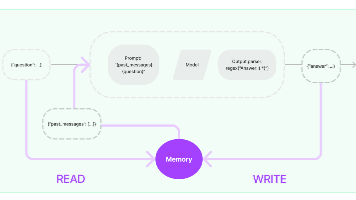
多轮对话和上下文记忆,是指模型在处理多轮对话时,能够记住上一轮的对话内容,并基于这些内容生成下一轮的回复。对话大模型原生支持多轮对话。
大模型本身是不具备上下文记忆能力的
例如:下面的代码,response2 就没有记住 response 的内容
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_ollama import ChatOllama
chat_model = ChatOllama(
model="qwen3:0.6b"
)
messages = [
SystemMessage("你是一位乐于助人的智能小助手wifi歪f", additional_kwargs={"chat": chat_model}),
HumanMessage(content="你好,请你介绍一下你自己")
]
response = chat_model.invoke(messages)
response2 = chat_model.invoke("你叫什么名字")
print(response2.content)
模型调用的方法
为了尽可能简化自定义链的创建,我们实现了一个Runnable 协议。许多 LangChain 组件实现了 Runnable 协议,包括聊天模型、提示词模板、输出解析器、检索器、代理(智能体)等。
Runnable 定义的公共的调用方法如下:
invoke:处理单条输入,等待 LLM 完全推理完成后再返回调用结果stream:流式响应,逐字输出 LLM 的响应结果batch:处理批量输入
这些也有相应的异步方法,应该与 asyncio 的 await 语法一起使用以实现并发:
astream:异步流式响应ainvoke:异步处理单条输入abatch:异步处理批量输入astream_log:异步流式返回中间步骤,以及最终响应astream_events:异步流式返回链中发生的事件
invoke() 之前说过了,略
stream() 方法
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_ollama import ChatOllama
from langchain_openai import ChatOpenAI
chat_model = ChatOllama(
model="qwen3:0.6b",
)
chat_model_openai = ChatOpenAI(
model="gpt-4o-mini",
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL"),
streaming=True,
)
messages = [
SystemMessage("你是一位乐于助人的智能小助手wifi歪f", additional_kwargs={"chat": chat_model}),
HumanMessage(content="你好,请你介绍一下你自己")
]
for chunk in chat_model.stream("你叫什么名字"):
print(chunk.content)
这里需要注意一下 ollama 是没有
streaming参数的,只需要调用stream()方法即可
Output Parsers 输出解析器
语言模型返回的内容通常都是字符串的格式(文本格式),但在实际 AI 应用开发过程中,往往希望 model 可以返回更直观、更格式化的内容,以确保应用能够顺利进行后续的逻辑处理。此时,LangChain 提供的输出解析器就派上用场了。
输出解析器(Output Parser)负责获取 LLM 的输出并将其转换为更合适的格式。这在应用开发中及其重要。
输出解析器的分类
LangChain 有许多不同类型的输出解析器
- StrOutputParser:字符串解析器
- JsonOutputParser:JSON 解析器,确保输出符合特定 JSON 对象格式
- XMLOutputParser:XML 解析器,允许以流行的 XML 格式从 LLM 获取结果
- CommaSeparatedListOutputParser:CSV 解析器,模型的输出以逗号分隔,以列表形式返回输出
- DatetimeOutputParser:日期时间解析器,可用于将 LLM 输出解析为日期时间格式
除了上述常用的输出解析器之外,还有:
- EnumOutputParser:枚举解析器,将 LLM 的输出,解析为预定义的枚举值
- StructuredOutputParser:将非结构化文本转换为预定义格式的结构化数据(如字典)
- OutputFixingParser:输出修复解析器,用于自动修复格式错误的解析器,比如将返回的不符合预期格式的输出,尝试修正为正确的结构化数据(如 JSON)
- RetryOutputParser:重试解析器,当主解析器(如 JSONOutputParser)因格式错误无法解析 LLM 的输出时,通过调用另一个 LLM 自动修正错误,并重新尝试解析
StrOutputParser 字符串解析器
StrOutputParser 简单地将任何输入转换为字符串。它是一个简单的解析器,从结果中提取 content 字段。
from langchain_core.output_parsers import StrOutputParser
from langchain_ollama import ChatOllama
chat_model = ChatOllama(
model="qwen3:0.6b"
)
response = chat_model.invoke('你好')
parser = StrOutputParser()
res_str = parser.invoke(response) # 也可以通过response.content来获得
print(res_str) # 你好!有什么可以帮助你的吗?
JsonOutputParser JSON 解析器
JsonOutputParser,即 JSON 输出解析器,是一种用于将大模型的 自由文本输出 转换为 结构化 JSON 数据 的工具。
适合场景:
特别适用于需要严格结构化输出的场景,比如 API 调用、数据存储或下游任务处理。
实现方式:
- 方式 1:用户自己通过提示词指明返回 Json 格式
- 方式 2:借助 JsonOutputParser 的
get_format_instructions(),生成格式说明,指导模型输出 JSON 结构
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_ollama import ChatOllama
chat_model = ChatOllama(
model="qwen3:0.6b"
)
prompt = PromptTemplate(
template="请严格按照 JSON 格式回答问题,只返回 JSON 字符串,不要有其他文字。问题:{question}",
input_variables=["question"],
)
response = chat_model.invoke(prompt.invoke({"question": "你好,请介绍一下自己"}))
parser = JsonOutputParser()
res_str = parser.invoke(response)
print(res_str) # {'userQuestion': '你好,请介绍一下自己', 'response': '我是AI助手,能够为您提供帮助。'}
这里需要注意的是,需要在提示词中指定按照 json 格式输出,告诉大模型输出 json,否则会报错。
如果在提示词中不指明输出 json,可以看如下示例:
parser = JsonOutputParser()
res = parser.get_format_instructions()
print(res) # Return a JSON object.
parser.get_format_instructions()输出就是一段提示词描述,把这个内容拼接到用户的提示词中,大模型就会按照 json 格式输出。
知识拓展:
在上面的代码中,不管是大模型,还是 prompt、parser 都会调用invoke方法,这时候可以改写成chain链的形式,来简化代码。
简化前:
parser = JsonOutputParser()
prompt = chat_prompt_template.invoke(input=xxx)
response = chat_model.invoke(prompt)
json_result = parser.invoke(response)
print(json_result)
简化后:
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_ollama import ChatOllama
chat_model = ChatOllama(
model="qwen3:0.6b"
)
parser = JsonOutputParser()
prompt_template = PromptTemplate(
template="请严格按照 JSON 格式回答问题,只返回 JSON 字符串,不要有其他文字。问题:{question}",
input_variables=["question"],
)
# 简化后
chain = prompt_template | chat_model | parser
response = chain.invoke(input={"question": "你好"})
print(response)
XMLOutputParser XML 解析器
XMLOutputParser,将模型的自由文本输出转换为可编程处理的 XML 数据。
如何实现:在 PromptTemplate 中指定 XML 格式要求,让模型返回 <tag>content</tag> 形式的数据。
注意:XMLOutputParser 不会直接将模型的输出保持为原始 XML 字符串,而是会解析 XML 并转换成 Python 字典(或类似结构化的数据)。目的是为了方便程序后续处理数据,而不是单纯保留 XML 格式。
from langchain_core.output_parsers import XMLOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_ollama import ChatOllama
chat_model = ChatOllama(
model="qwen3:0.6b"
)
parser = XMLOutputParser()
prompt_template = PromptTemplate.from_template(
template="用户的问题是:{question}\n使用的格式是:{format_instructions}",
).partial(format_instructions=parser.get_format_instructions())
chain = prompt_template | chat_model
response = chain.invoke(input={"question": "生成汤姆·汉克斯的简要信息"})
print(response.content) # 输出xml格式的数据
parser_xml = parser.invoke(response)
print(parser_xml) # 输出为python的字典格式,和json类似
langchain 1.x 结构化输出(Pydantic Schema)
通过 llm.with_structured_output 方法
"""
LCEL 格式化输出案例:
输入一段文本 → 返回结构化结果(情感分类 + 主题 + 总结)
"""
from typing import Literal
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 1. 定义输出 Schema
class AnalysisResult(BaseModel):
sentiment: Literal["积极", "中性", "消极"] = Field(..., description="文本的情感极性")
topic: str = Field(..., description="主要主题")
summary: str = Field(..., description="简要总结")
# 2. 定义模型
llm = ChatOpenAI(
model="gpt-4o-mini",
base_url="xxx",
api_key="xxx",
temperature=0)
# 3. 构建 LCEL 链:Prompt | LLM | StructuredOutput
analysis_chain = (
ChatPromptTemplate.from_template("请分析以下文本,并提取关键信息:{text}")
| llm.with_structured_output(AnalysisResult)
)
# 4. 执行
if __name__ == "__main__":
result: AnalysisResult = analysis_chain.invoke(
{"text": "今天股市大涨,我对未来的投资充满信心!"}
)
print(result.dict())
langchain 1.x 中间件
这段代码实现了一个智能模型选择的中间件功能,核心作用是:根据对话的轮次(消息数量)自动为 AI 代理(agent)切换不同的模型 —— 短对话用轻量的基础模型,长对话用更强大的进阶模型,以此平衡响应速度和对话质量。
@wrap_model_call
def dynamic_model_selection(request: ModelRequest, handler) -> ModelResponse:
"""Choose model based on conversation complexity."""
message_count = len(request.state["messages"])
if message_count > 10:
model = advanced_model
else:
model = basic_model
request.model = model
return handler(request)
agent = create_agent(
model=basic_model, # Default model
tools=[search, get_weather],
middleware=[dynamic_model_selection]
)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)