深度解码:构建高可扩展多智能体系统的四大基石
本文探讨了从单体Prompt到多智能体系统的范式转移,提出下一代AI应用需要采用分层架构设计。系统核心特性包括:1)插件扩展机制,通过微内核架构实现功能动态加载;2)可视化编排,将代码逻辑转化为DAG图提升可维护性;3)多智能体协作,模拟人类团队分工完成复杂任务。文章还介绍了多源工具集成实践,强调需平衡灵活性与确定性。未来展望指出智能体将向自主演化方向发展,开发者角色将转变为组织架构师。
目录
前言:从单体Prompt到智能体系统的范式转移
在大型语言模型(LLM)发展的初期,开发者往往沉迷于“提示词工程”(Prompt Engineering),试图通过一段精妙的文字让模型完成所有任务。然而,随着业务复杂度的提升,单体Prompt的局限性愈发明显:上下文窗口的限制、幻觉问题的不可控以及对外部工具调用的乏力,使得我们必须思考如何从“使用模型”转向“构建系统”。下一代多智能体(Multi-Agent)系统不再仅仅是模型的包装器,而是一套复杂的工程化框架,它通过模拟人类社会的组织架构,将复杂任务拆解为可管理的子任务,由具备不同能力的智能体协作完成。这种从“单兵作战”到“团队协作”的演进,正是当前AI应用开发的核心趋势。
架构总览:分层设计与工程化解耦
一个成熟的多智能体系统必须遵循软件工程中的“高内聚、低耦合”原则。在首席架构师的视角下,系统通常被划分为四个核心层级。底层是模型抽象层,它屏蔽了不同供应商API的差异,实现如GPT-4、Claude 3.5或本地Llama模型的无缝切换。往上是编排逻辑层,负责定义智能体之间的通信协议、任务分发机制以及状态持久化。再往上是工具与插件层,这是系统能力的延伸,通过标准化的接口集成搜索引擎、数据库或企业私有API。最顶层则是交互与展示层,为用户提供可视化操作界面或API接入点。
这种分层设计的核心价值在于工程化能力的释放。例如,LangChain 通过标准化的组件接口,让开发者能够像搭积木一样组合不同的功能模块。而 AutoGen 则更进一步,通过分层的API设计(如Core API与AgentChat API),既满足了快速原型的需求,又为复杂分布式运行环境提供了底层支持。只有实现彻底的解耦,系统才能在面对瞬息万变的技术栈时保持长久的生命力。
核心特性一:插件扩展机制——微内核与动态加载
插件机制是多智能体系统的“手脚”。在传统的开发模式中,每增加一个功能都需要修改核心代码,这在大型系统中是灾难性的。现代MAS架构采用微内核(Micro-kernel)架构,核心引擎只负责消息路由和状态管理,具体的功能逻辑全部封装在插件中。
插件扩展的核心在于“契约化设计”。每一个插件都必须遵循统一的接口规范,包括输入参数的JSON Schema定义、输出格式的标准化以及异常处理机制。通过这种方式,系统可以在运行时动态加载(Hot-swapping)新功能,而无需重启服务。以下是一个典型的插件注册与调用逻辑示例:
class BaseTool:
"""插件基类,定义统一契约"""
def __init__(self, name, description):
self.name = name
self.description = description
async def execute(self, **kwargs):
raise NotImplementedError
class WeatherPlugin(BaseTool):
"""具体插件实现:天气查询"""
async def execute(self, city: str):
# 模拟调用外部API
return f"{city} 的天气晴朗,气温25度"
# 插件注册中心
class PluginRegistry:
def __init__(self):
self._plugins = {}
def register(self, tool: BaseTool):
self._plugins[tool.name] = tool
print(f"Plugin {tool.name} registered successfully.")
def get_tool(self, name):
return self._plugins.get(name)在实际应用中,如 Semantic Kernel 提供的企业级组件,允许开发者将复杂的业务逻辑封装为“技能”(Skills),通过简单的配置即可被智能体调用。这种机制不仅降低了开发门槛,更重要的是它建立了一个可扩展的生态系统,让非AI专业的业务开发人员也能通过编写简单的插件来增强智能体的能力。
核心特性二:可视化编排——从代码定义到DAG逻辑映射
对于复杂的业务流程,纯代码定义往往会导致逻辑碎片化,难以维护和审计。可视化编排(Visual Orchestration)的出现,将抽象的代码逻辑转化为直观的有向无环图(DAG)。在可视化界面中,每一个节点代表一个智能体、一个工具或一个逻辑判断,而连线则代表了数据的流转方向。

可视化编排不仅仅是“好看”,它解决了逻辑透明度的问题。通过 Flowise 或 Dify 这样的平台,架构师可以清晰地看到任务是如何从“需求分析节点”流转到“代码生成节点”,再到“自动化测试节点”的。这种低代码的交互方式,极大地缩短了从业务构思到生产落地的距离。在底层实现上,系统会将前端生成的JSON拓扑结构解析为执行引擎可识别的图结构,利用拓扑排序算法确保任务按序执行,并处理循环、分支等复杂逻辑。
核心特性三:多智能体协作——SOP驱动的角色博弈与状态同步
如果说单智能体是“全才”,那么多智能体系统追求的是“专才的协作”。在处理软件开发、法律审计或金融分析等复杂任务时,单一模型往往顾此失彼。多智能体协作的核心哲学是 SOP(标准作业程序)驱动。
MetaGPT 提出了一个极具启发性的观点:Code = SOP(Team)。它将软件公司的运作逻辑搬到了智能体世界,通过定义产品经理、架构师、工程师等角色,并为每个角色设定严格的输出规范(如PRD、系统设计文档、单元测试),实现了极高成功率的代码生成。
在协作过程中,状态同步与冲突解决是最大的技术挑战。当多个智能体共享同一个上下文空间时,如何防止信息覆盖?我们通常采用“黑板模式”(Blackboard Pattern)或“消息总线”机制。每个智能体只关注与其角色相关的消息,并通过全局状态机(State Machine)来控制任务的接力。
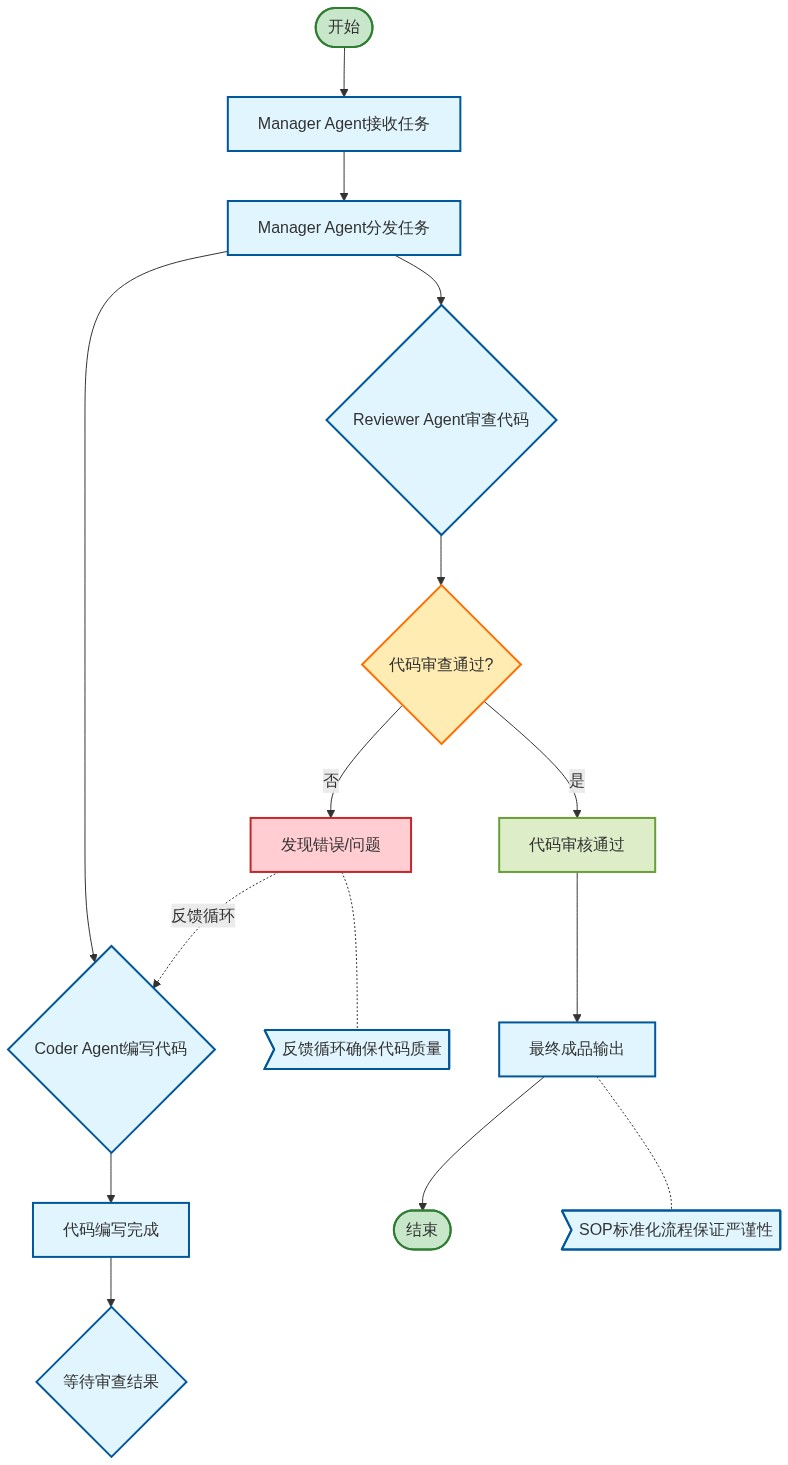
这种协作模式不仅提升了任务完成的质量,更引入了自我纠错机制。例如,一个“评论家智能体”可以专门负责审核“生成智能体”的内容,通过多轮博弈(Debate)消除幻觉,确保输出的严谨性。
进阶实践:多源工具集成与复杂场景落地
在真实的生产环境中,智能体必须能够处理来自多源的数据。这包括结构化的SQL数据库、非结构化的PDF文档,以及实时变动的Web API。多源工具集成的难点在于“上下文注入”的精准度。
为了解决这一问题,Dify 等平台引入了原生的 MCP(Model Context Protocol)集成。MCP 协议标准化了模型与外部数据源的连接方式,使得智能体可以像人类操作浏览器一样,在不同的工具间自由切换。在安全性方面,成熟的系统会采用沙箱化执行环境,确保智能体生成的代码或调用的脚本不会对宿主系统造成破坏。
以下是一个集成搜索引擎与本地数据库的复杂任务处理范式:
async def complex_task_handler(query):
# 1. 意图识别:判断需要哪些工具
intent = await planner_agent.analyze(query)
results = []
if "search" in intent.tools:
# 调用搜索插件
web_data = await search_tool.run(query)
results.append(web_data)
if "database" in intent.tools:
# 调用数据库插件,执行安全查询
db_data = await db_tool.query(intent.sql_params)
results.append(db_data)
# 2. 知识融合:将多源数据喂给总结智能体
final_report = await summarizer_agent.generate(results)
return final_report在落地过程中,我们还需要关注可观测性(Observability)。通过集成如 LangSmith 的追踪工具,架构师可以监控每一个 Token 的消耗、每一层调用的延迟以及智能体决策的路径。没有监控的智能体系统就像一个黑盒,无法在企业级场景中大规模部署。
总结与未来展望:迈向自主演化的智能体时代
构建一个高可扩展的多智能体系统,本质上是在灵活性与确定性之间寻找平衡。通过插件机制保障灵活性,通过可视化编排提升确定性,通过多智能体协作模拟人类智慧,再通过多源工具集成打破数据孤岛。
展望未来,我们正在进入“自主演化智能体”的时代。智能体将不再仅仅被动地执行预设的SOP,而是能够根据环境反馈,自主学习新工具的使用方法,甚至自主优化协作流程。作为开发者,我们的角色将从“程序员”转变为“组织架构师”,负责设计更公平的博弈规则和更高效的通信协议。在这个AI重塑软件工程的浪潮中,掌握多智能体系统的架构设计,将是通往未来的入场券。
本文部分图片来源于网络,版权归原作者所有,如有疑问请联系删除。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)