《C++ 搜索二叉树》深入理解 C++ 搜索二叉树:特性、实现与应用
二叉搜索树常简写为BST,提高代码可读性(SBT不好听),二叉搜索树也叫搜索二叉树代码语言:javascriptAI代码解释K _key;
·
一、理解二叉搜索树
1.1 二叉搜索树的概念
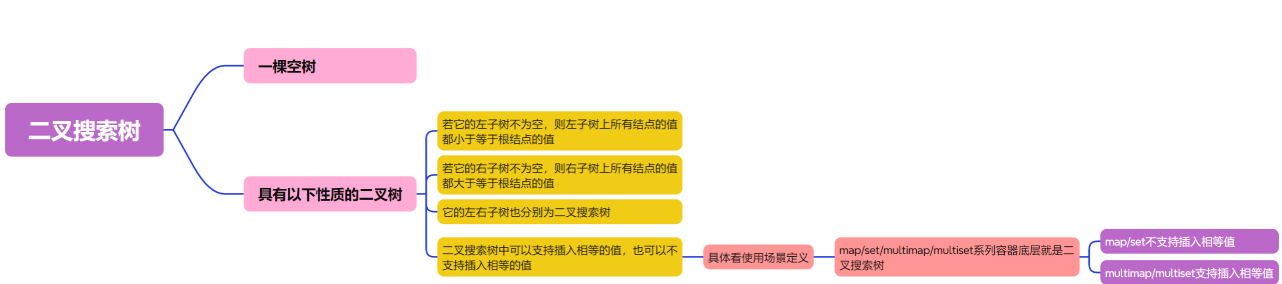
- 若它的左子树不为空,则左子树上所有结点的值都小于等于根结点的值;
- 若它的右子树不为空,则右子树上所有结点的值都大于等于根结点的值;
- 它的左右子树也分别为二叉搜索树;
- 二叉搜索树中可以支持插入相等的值,也可以不支持插入相等的值,具体看使用场景定义
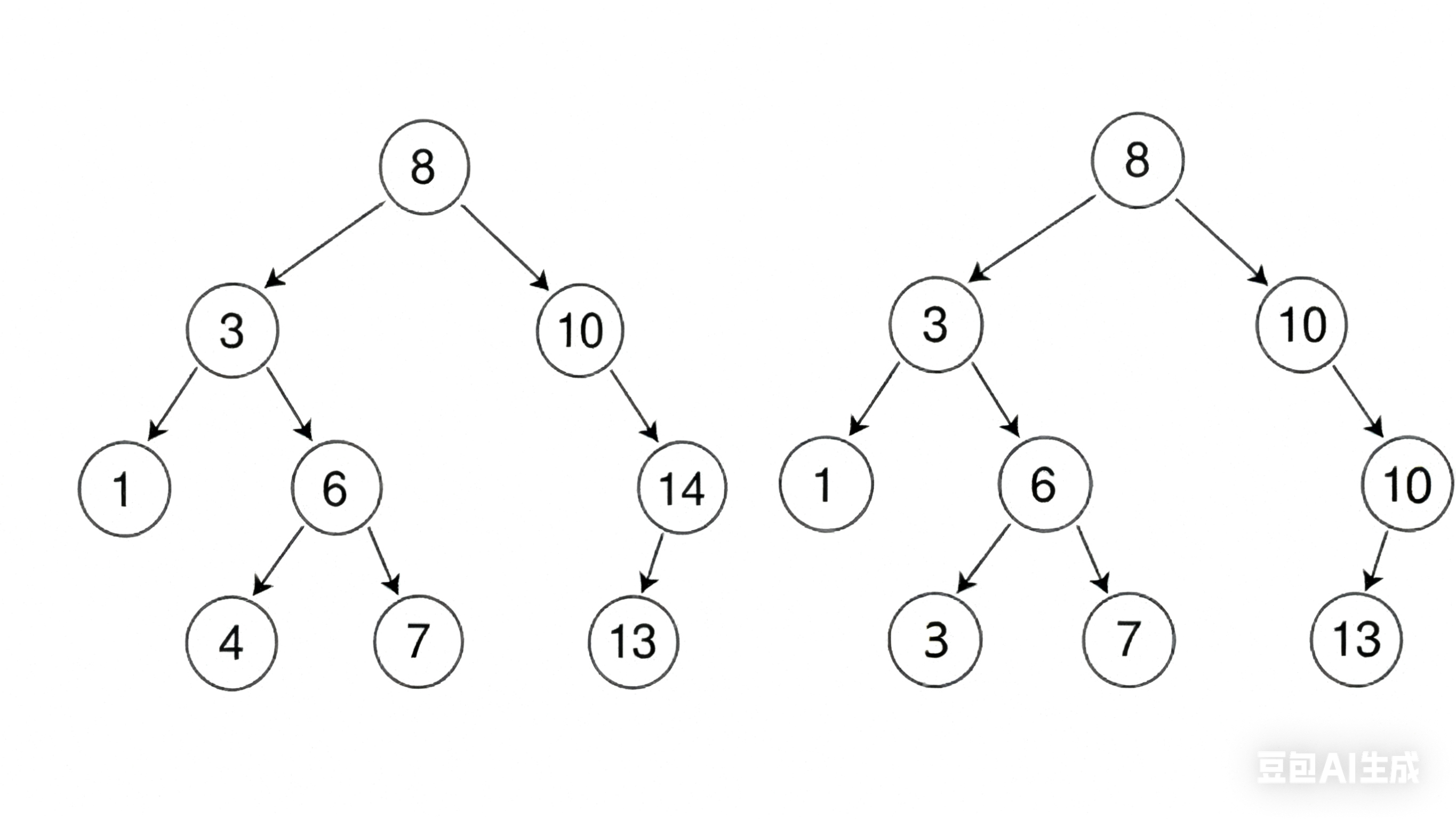
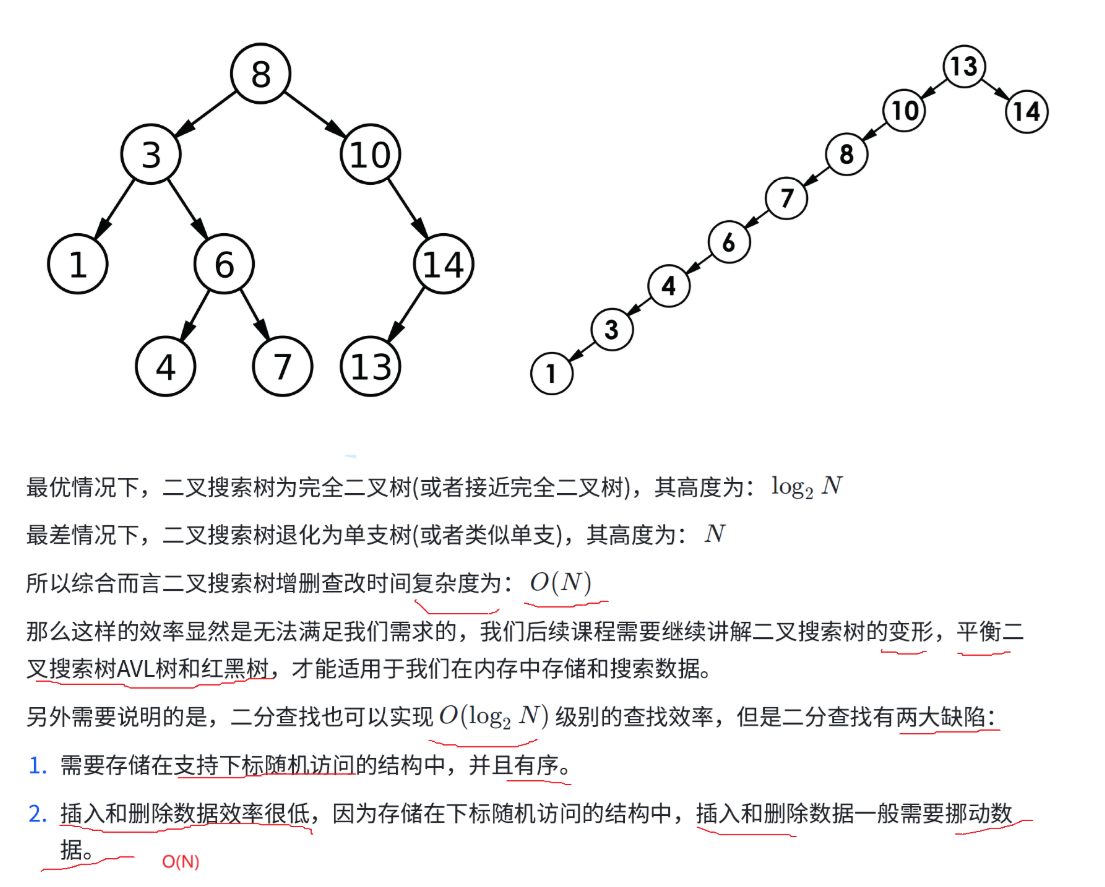
如下图所示就是两个搜索二叉树
1.2 核心特性
1.2.1 多元化的结构: 灵活的数据结构
BST支持动态数据集合的高效操作,适合频繁插入、删除和查找的场景
1.2.2 天然的搜索优势:擅长搜索的数据结构
利用二叉树的分支特性,BST在平均情况下能实现O(logn)的搜索效率
二、二叉搜索树性能分析
2.1 时间复杂度分析
- 最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),其高度为:logN;
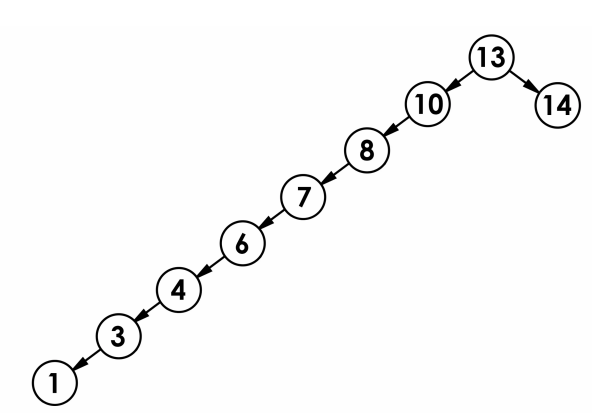
- 最差情况下,二叉搜索树退化为单支树(或者类似单支),其高度为:N;
注意:时间复杂度指的是最差情况下,所以时间复杂度为O(N)

最差情况如图:
那么这样的效率显然是无法满足我们需求的,因此后面博主会介绍二叉搜索树的变形——平衡二叉搜索树AVL树和红黑树,才能适用于我们在内存中存储和搜索数据
2.2 二分查找的局限性
另外需要说明的是,二分查找也可以实现O(logN)级别的查找效率,但是二分查找有两大缺陷
- 需要存储在支持下标随机访问的结构中,并且有序
- 插入和删除数据效率很低,因为存储在下标随机访问的结构中,插入和删除数据一般需要挪动数据
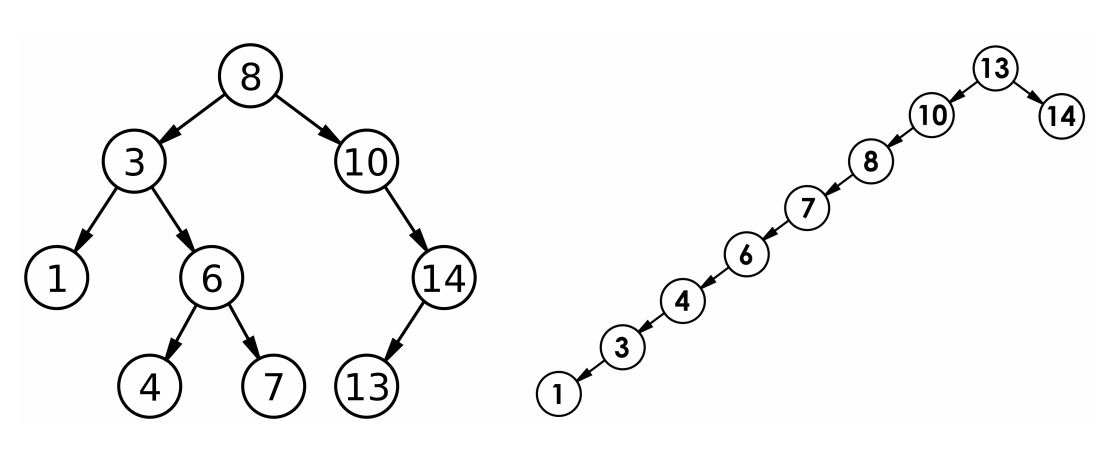
如右图所示:数据越有序,插入结果越坏——高度高、递归深、效率低 如左图所示:插入越无序的数据,左右会平衡一点,结果反而越好
三、实现二叉搜索树的定义
3.1 命名规范
二叉搜索树常简写为BST,提高代码可读性(SBT不好听),二叉搜索树也叫搜索二叉树
3.2 定义节点
代码语言:javascript
AI代码解释
template<class K>
struct BSTreeNode
{
BSTreeNode<K>* _left;
BSTreeNode<K>* _right;
K _key;
BSTreeNode(const K& key)
:_left(nullptr)
, _right(nullptr)
, _key(key)
{
}
};3.3 实践:完整的类定义
提供插入、查找、删除等基本操作的接口设计如下:
四、二叉树搜索的插入操作详解

4.1 插入算法流程
从根节点开始,根据键值大小选择左子树或右子树,直到找到空位置插入新节点。
插入分成以下三种情况:
- 树为空,则直接新增结点,赋值给root指针
- 树不空,按二叉搜索树性质,插入值比当前结点大就往右走,插入值比当前结点小就往左走,找到空位置,插入新结点
- 如果支持插入相等的值,插入值跟当前结点相等的值可以往右走,也可以往左走,找到空位置,插入新结点(要注意保持逻辑一致性,插入相等的值不要一会往右走,一会又往左走)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)