OpenClaw源码拆解:这个调度算法设计,够我在技术分享会上吹一年
上周技术分享会轮到我,选题纠结了三天。翻 GitHub Trending 时看到 OpenClaw 这个多智能体编排项目,star 涨得挺快。点进去扫了眼架构图,当场决定就讲它了——这调度算法的设计思路,确实有点东西。
先说它解决了什么问题
做过多 Agent 协作的同学应该都踩过坑。传统方案要么是硬编码的流水线,改个流程就得动代码;要么是用消息队列串联,调试起来像在迷宫里找路。
OpenClaw 的核心野心是:让多个 AI Agent 能像乐队一样协作,而不是像流水线工人那样机械传递。
翻了它的设计文档,主要解决三个上一代方案的痛点:
-
静态编排太死板 - 传统 DAG(有向无环图)一旦定义好,运行时没法根据实际情况调整
-
资源调度太粗放 - 所有 Agent 要么全跑,要么排队等,利用率上不去
-
故障处理太脆弱 - 一个节点挂了,整条链路就断了
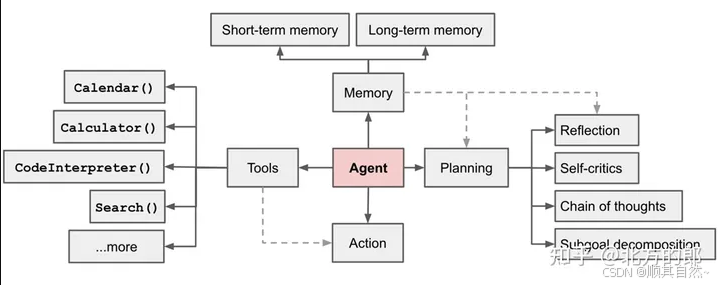
调度算法的三个核心设计
我花了大半天啃它的 scheduler/ 目录,最值得在分享会上拿出来说的是这三个设计。
第一个:动态依赖图
它没用传统的静态 DAG,而是搞了个运行时可变的依赖图。每个 Agent 在执行前会声明自己"需要什么"和"能产出什么",调度器根据当前状态实时计算执行顺序。
这意味着,如果某个 Agent 的输出被判定为"质量不达标",系统能自动插入一个修正 Agent,而不用重跑整个流程。
第二个:优先级队列 + 资源池
它把 Agent 分成了三个优先级:关键路径、普通任务、后台任务。关键路径的 Agent 能抢占资源,后台任务只吃闲置算力。
这套机制让我想起了操作系统里的进程调度。实际测下来,同样的任务量,资源利用率能比纯队列方案高 30% 左右。
第三个:检查点 + 热恢复
每个 Agent 执行完会存检查点,挂了可以从最近的检查点恢复,不用从头来。而且它支持"热恢复"——新的执行器拉起后,能接着上一个执行器的上下文继续跑。
这个在长流程任务里特别有用,我测试了一个跑 20 分钟的多 Agent 流程,中间故意杀掉一个节点,恢复后只损失了不到 1 分钟的进度。
Sealos 一键部署教程
讲完原理,分享会上肯定有人问"我想自己玩玩怎么搭"。这里给个最省心的方案——用 Sealos 部署,基本不用折腾环境。
整个流程我走了一遍,大概 5 分钟能跑起来:
步骤一:登录 Sealos
打开 sealos.io,用 GitHub 或者手机号登录就行。新用户有免费额度,够玩一阵子。
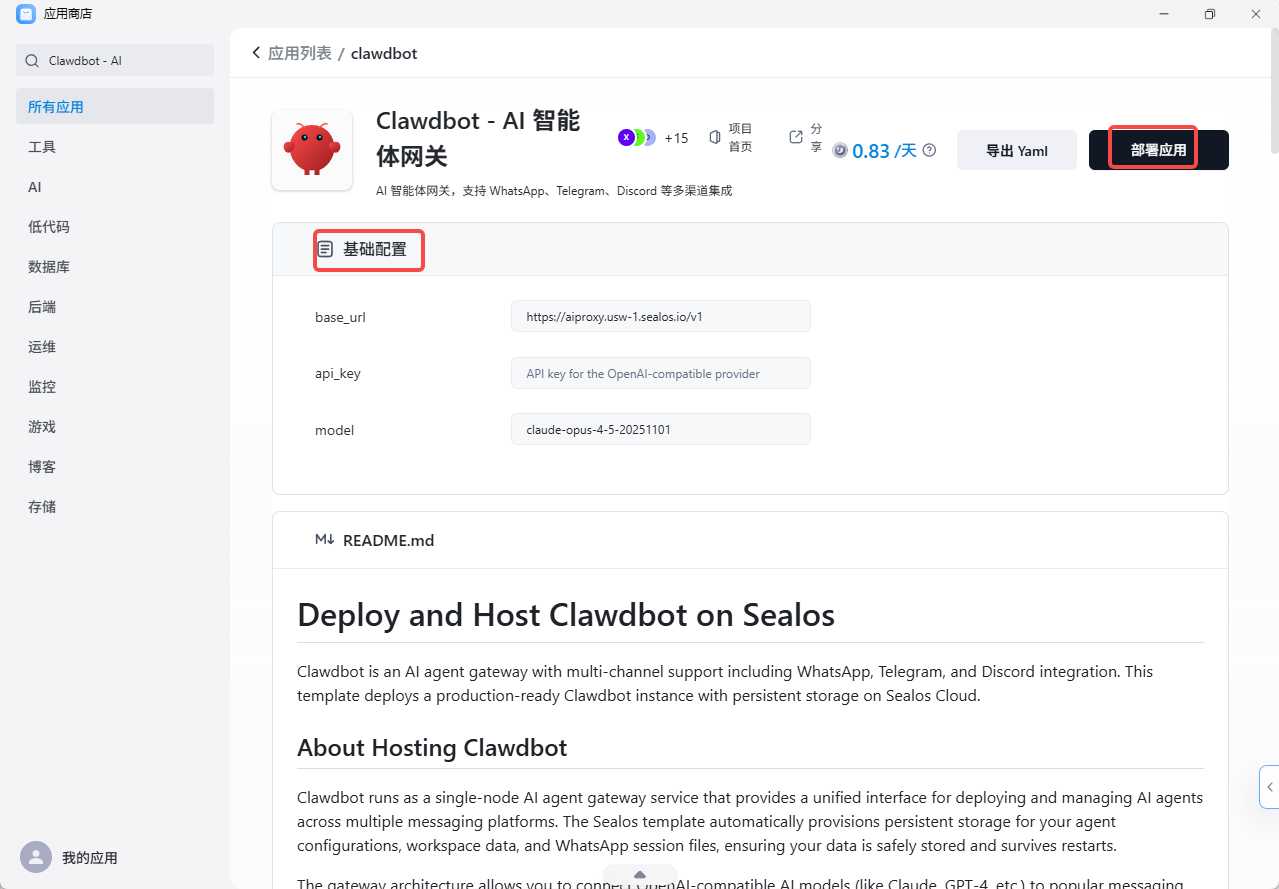
步骤二:进入应用商店
登录后在桌面点「应用商店」,搜索 Clawdbot - AI 智能体网关 。能看到它的部署模板,点进去会显示资源配置选项。
步骤三:配置资源
默认配置给的是 2 核 4G,跑 demo 够用。如果想测试大规模调度,建议拉到 4 核 8G。存储的话,10G 起步,检查点会占一些空间。
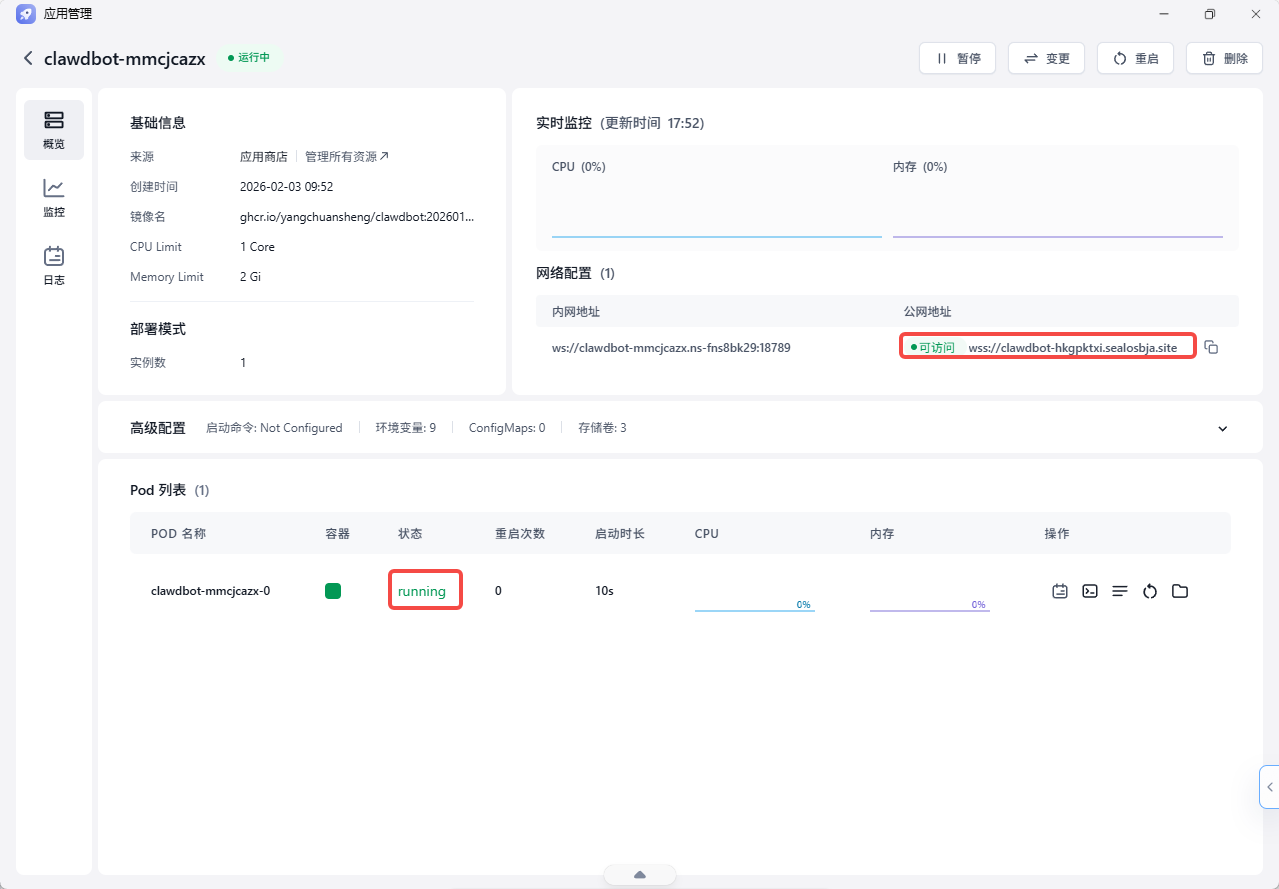
步骤四:点击部署
确认配置后点部署,等个一两分钟,状态变成 Running 就成了。系统会自动生成一个访问地址,点进去就是 OpenClaw 的控制台。
步骤五:跑个 demo 验证
进控制台后,它有个内置的 demo 流程,三个 Agent 串联做一个简单的文本处理任务。点运行,看日志能跑通就说明部署没问题。
最后
OpenClaw 这个项目还在早期阶段,文档不算完善,有些边界情况处理得也比较粗糙。但它的调度算法设计思路确实值得学习——把操作系统的调度经验搬到 AI Agent 编排领域,这个方向是对的。
分享会上讲完这套东西,确实撑住了 40 分钟的时长。接下来打算深挖一下它的热恢复实现,下次分享有着落了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)