AI Agent开发实战:Java工程师的高效转型策略
本文深入探讨AI Agent的构建模式与应用场景。首先通过旅行规划示例说明AI Agent具备自主调研、推理、执行和适应能力,区别于传统LLM的线性工作流。文章对比了Agent与工作流的区别:工作流适合确定性任务,而Agent更擅长处理复杂、动态的任务。AI Agent的核心组件包括LLM(决策大脑)、工具(能力扩展)和记忆(上下文保持)。文中介绍了ReACT框架和多Agent系统等构建模式,强调
目录:
- 什么是AI Agent(含示例)
- Agent与工作流的区别
- 何时使用Agent
- AI Agent的核心组件(LLM、工具、记忆)
- ReACT框架
- Agent框架介绍
- 工作流模式(链式、路由、并行、编排)与Agent模式(ReACT、反思、工具、多Agent)
- 多Agent模式详解
本文重点在于Agent的构建模式。模式是构建工作流、单 Agent 系统和多 Agent 架构的常用方法——有的追求控制和可预测性,有的强调自主性和动态决策。理解这些权衡有助于为特定问题选择合适的架构。
读完本文,你将对Agent工作流、具备记忆能力的 Agent 和多 Agent 系统形成实用的思维模型,知道何时使用这些技术、如何组合,以及哪里容易踩坑。
- 什么是 AI Agent
在直接给出定义之前,先通过一个例子来理解 AI Agent。
假如,春节要去趟迪拜旅游,现在需要做一下旅游规划,这份规划需要考虑哪些内容?

图 1: 家庭旅行规划
旅行规划清单包括:
- 交通(航班)
- 住宿(酒店)
- 餐饮(餐厅)
- 行程规划(每天去哪里)
- 当地交通(租车、公交、地铁等)
- 预算控制
- 签证办理
列出这些后,就得行动了:订航班、酒店,办签证等。
整个规划是怎么思考的?
你不会只搜一次"迪拜"。实际流程包括:
- 调研:浏览多个网站比较航班价格并预订;同样地,选择靠近景点且评价良好的酒店。
- 推理:如果凌晨 4 点抵达,需要预订允许提前入住的酒店。
- 执行:预订航班(完成支付),然后用预订信息预订酒店,再用酒店确认信息预订租车。
- 适应:如果航班取消,需要重新调整所有预订,包括酒店、晚餐预约等。
用传统 LLM,就像拿本"旅行手册"。问"迪拜最好的酒店有哪些?",它给你列个单子。但具体订房、协调时间、处理问题——全得自己来。
而 AI Agent 就像一个"数字旅行助手",能调研、推理、适应、执行,还能记住每个步骤。
给它一个目标:“50000 元预算内给家庭订 5 天迪拜之旅。” Agent 会自主完成上面说的全部规划和执行。
这就是常说的 Agentic AI。希望这个例子说清楚了 Agent 是什么。但这只是皮毛。
在 Andrew Ng 的 Agentic AI 课程中,他提出了一个问题:
人类实际的工作方式与 LLM 有何不同?
大多数当前的 LLM 应用采用线性的一次性工作流(prompt → output)。对于涉及多个步骤的复杂应用而言,这种方式既低效也不现实。
人类很少能在单次尝试中创建出完美的最终产品。工作通常遵循非线性流程(有时也可以是线性的),就像写论文时需要头脑风暴、调研、起草、编辑和精炼;或者在预算范围内寻找航班、寻找靠近景点且评价良好的酒店等。
线性与非线性步骤的区别:
线性步骤:工作按直线流程进行——完成步骤 1,然后步骤 2,再步骤 3,很少需要回退。示例:预订航班 → 付款 → 获得确认(完成)。
非线性步骤:工作在步骤间循环往复,因为每个决策都会改变约束条件。需要不断重新审视 earlier choices 直到所有条件都满足。示例:航班时间影响酒店入住 → 酒店位置影响行程 → 行程影响预算 → 预算迫使重新选择航班/酒店。
因此,旅行规划主要是非线性的,因为某一部分的变化(航班成本、时间、取消、评分)会迫使其他部分更新,这是一个迭代循环,而非一次性流水线。
应用可以只是简单的 AI Agent工作流,也可以涉及真正的 AI Agent。
- Agent vs 工作流
这引出了工作流和 Agent 的定义:
根据 Google 的定义:
- Agent工作流:工作流更具确定性,更专注于预定义的当前任务。
- AI Agent:AI Agent 具备主体性(agency),能够做出决策以完成目标或结果,意味着其高度自主,能够访问工具进行复杂任务自动化,从环境中学习并保留记忆。
Anthropic 的定义:

图 2: Anthropic 对 Agent vs 工作流的定义
要注意的是,构建Agent Agent 时,对其决策的控制力会降低——Agent 在特定情况下可能不会做出和人类一样的选择。
而在Agent工作流中,把人放进循环、让流程按确定性的方式走,某些情况下更靠谱。
因此,高主体性和高控制是光谱的两端。
Agent Agent vs Agent工作流的优缺点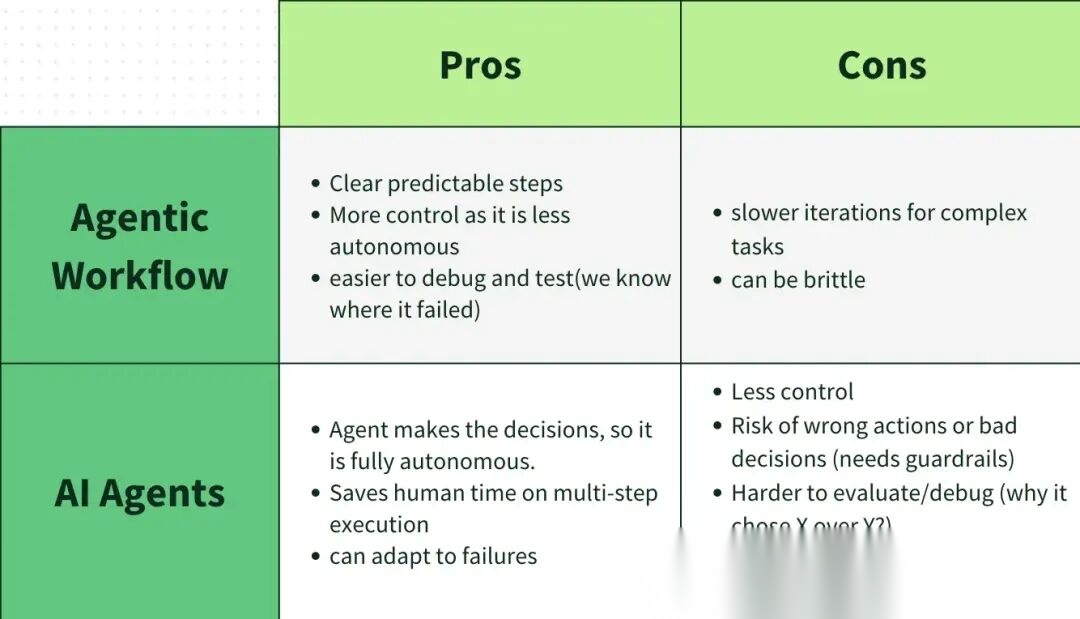
Agent 的控制或自主水平称为"主体性"(agency)。
- 主体性越低,Agent 创造的价值越低,但控制力越高
- 主体性越高,Agent 创造的价值越高,但控制力越低

图 5: 主体性级别
- 何时使用(以及何时不使用)Agent
什么时候该用工作流,什么时候该用 AI Agent?
- 如果是步骤明确的任务,用简单的Agent工作流更合适。
- Agent 适合处理复杂、模糊、动态的任务,能减少人工干预,但代价是延迟更高、计算成本更贵,还引入了不可预测性和潜在错误。所以Agent系统必须有完善的错误日志、评估策略、异常处理和重试机制。
- 步骤清晰、追求可预测性和一致性——用工作流。
- 需要灵活性、适应性、让模型来做决策——用 Agent。
- AI Agent 的构建模块
AI Agent 的基本构件是一个增强版的 LLM。
- LLM:Agent 的大脑,负责决策
- 工具:Agent 的武器,扩展能力边界,类似于外部函数或 API
- 记忆:Agent 的"笔记本"(短期 + 长期),存着用户偏好、过往对话、关键信息,让 LLM 能跨步骤、跨会话保持一致性
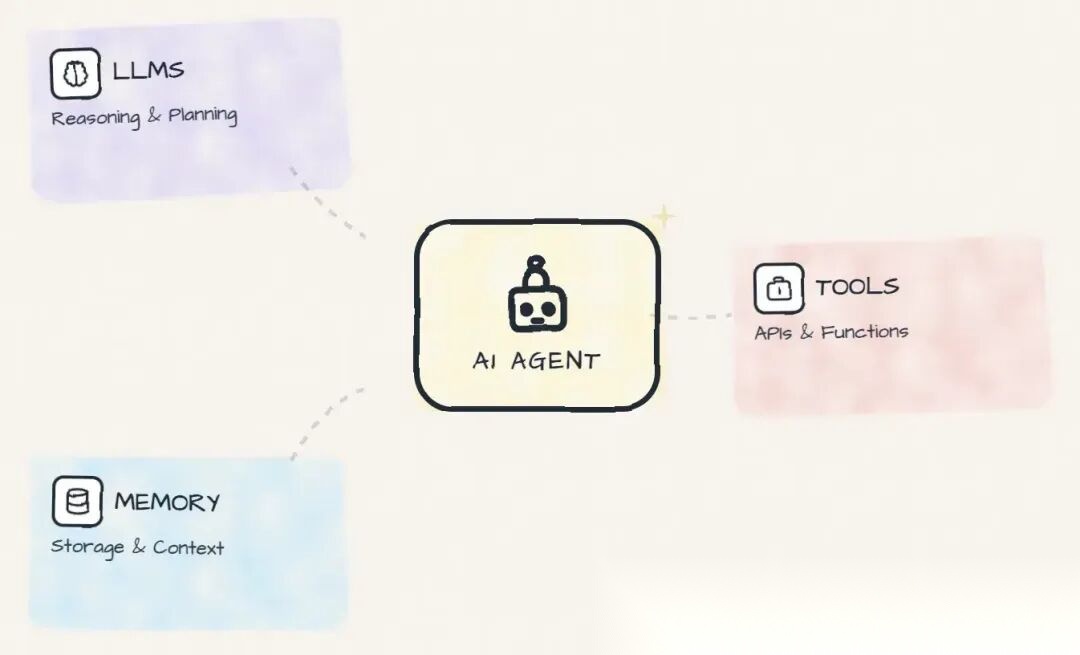
图 6: AI Agent 的构建模块
4.1 LLM
单独来看,大型语言模型(LLM)只能读取和生成文本,无法直接访问互联网、API、数据库或其他外部系统。
其知识仅限于训练数据。LLM 无法知道训练截止时间之后发生的事件,也无法了解 LLM 未训练过的内部数据。
但市面上有大量 LLM 模型,该如何选择?
选 LLM 要聪明点,不是每个任务都需要最猛的模型。任务简单,就用小模型。按需选型,成本更优。
下面看看这些"下一个词预测器"怎么通过工具获得超能力。
4.2 工具
在 AI Agent 的世界中,工具类似于武器,扩展 Agent 执行额外任务的能力。
工具可以有多种形式,例如:
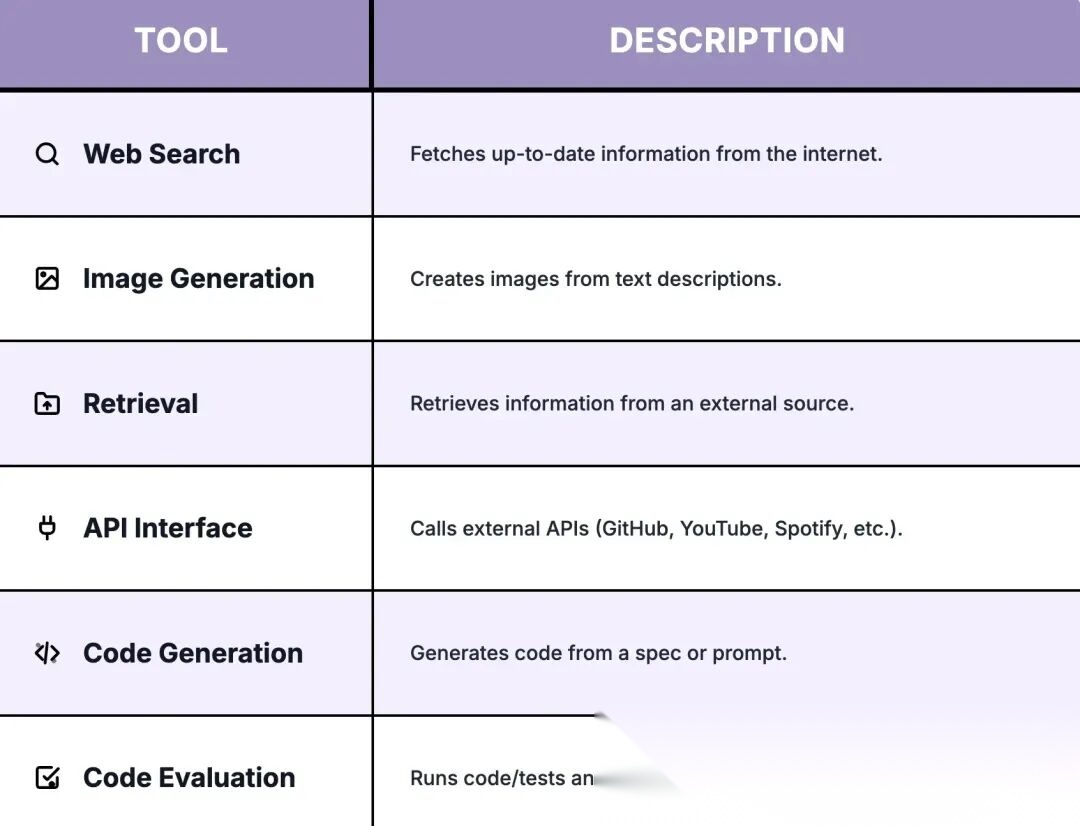
图 7: 不同类型的工具
如果某个工具不存在,可以构建自定义工具(函数或 API 包装器)。可以通过 MCP 等标准暴露这些工具,也可以添加 检索工具用于 RAG(搜索内部文档/向量数据库),使 Agent 能够获取基于上下文的 grounding context。
如何将"工具"传递给 LLM?
通过 Prompt 实现。由于 LLM 只能理解文本,输入文本即可获得输出。
例如,如果提供一个工具来从互联网查询某个位置的天气,然后询问 LLM 迪拜的天气,LLM 会识别出这是使用"天气"工具的机会。LLM 不会直接检索天气数据,而是生成代表工具调用的文本,例如调用 weather_tool(‘Dubai’)。
Agent 读取此响应,识别需要工具调用,代表 LLM 执行该工具,并检索实际的天气数据。
这些工具调用步骤通常不会展示给用户,因为框架已经对其进行了抽象。Agent 将函数调用的结果作为新消息追加,然后将更新后的对话传递给 LLM。
LLM 处理这些额外的上下文,为用户生成听起来自然的响应。从用户的角度看,似乎是 LLM 直接与工具交互,但实际上是 Agent 在后台处理整个执行过程。
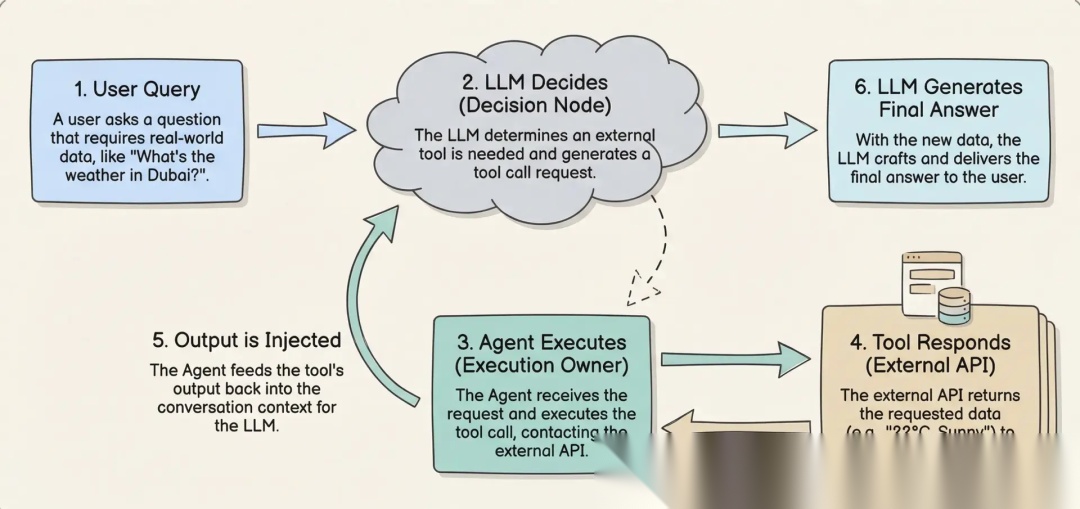
图 8: 工具调用
提示词格式化示例:

图 9: 工具提示词
4.2.1 工具注册表模式
在实际的 Agent 中,开发者需要将工具组织到注册表或"工具箱"中。
const toolbox = new ToolRegistry();
toolbox.register(weatherTool);
toolbox.register(calculatorTool);
const agent = new Agent({ tools: toolbox });
何时为 LLM 提供工具:
- 如果 LLM 不擅长数学运算,则提供计算器。
- 如果 LLM 无法获取最新信息,提供网络搜索工具。
- 如果基础 LLM 难以查询天气,提供天气 API。
4.3 Agent 中的记忆
LLM 是大脑,工具是手,记忆就是第二大脑。
没有记忆,Agent 每次都得从头来,之前聊的上下文全丢了。没上下文,就没法个性化。
想象一下招了个顶级厨师,但他一出厨房就忘光——食谱、顾客喜好、甚至五分钟前做了什么菜。每次点菜都得重新解释一遍。这就是现在大多数 Agent 的样子:挺强,但没状态。
LLM 一次只能看有限的信息,这个空间叫上下文窗口,本质上是为下一个回答准备的短期工作区。
所以不能啥都往 prompt 里塞。上下文太少,模型漏掉关键信息;太多(或不相关)又会增加成本、拖慢响应,甚至因为噪音或矛盾降低质量。
目标就是传恰到好处的信息给下一步——不多不少。这叫上下文工程(Context Engineering),后面再细聊。
这就是记忆的用处:把重要信息存到上下文窗口外面(过往对话、偏好、决策、笔记),需要的时候再捞出来塞回去。
有了记忆,Agent 能记住之前聊过什么,并基于这些上下文行动,回答就会更详细、更连贯。
记忆带来深度个性化、连续性、复杂推理能力和效率提升。
记忆是框架的基础,向量数据库(Pinecone、Weaviate、Chroma 等)为任务数据提供靠谱的存取机制。

图 10: 有记忆 vs 无记忆
因为 LLM 没有记忆,得在架构里加上。有两种方式:
4.3.1 短期记忆(STM)
短期记忆就在上下文窗口里,存接下来几步要用的临时信息(最新消息、工具输出、运行摘要等)。会话结束就清掉,或者慢慢压缩。
from langchain.memory import ConversationBufferWindowMemory
# 短期记忆:保留最后 K 条消息(窗口缓冲区)
memory = ConversationBufferWindowMemory(
k=5, # 保留最近 5 次交互
return_messages=True
)
# 跟踪会话对话(示例结构)
conversation = [
{"user": "Hi", "assistant": "Hey! How can I help?"},
{"user": "What's the weather in Tokyo?", "assistant": "Let me check..."},
]
for turn in conversation:
memory.save_context(
{"input": turn["user"]},
{"output": turn["assistant"]}
)
# 获取会话历史(消息对象列表)
history = memory.chat_memory.messages
print(history)
4.3.2 长期记忆(LTM)
长期记忆放在 LLM 外面,通常用向量数据库存。它让 Agent 能记住跨天、跨周甚至跨会话的信息,实现真正的个性化和连续性。Agent 需要的时候,通过语义搜索把最相关的记忆捞出来,塞进上下文窗口给当前步骤用。
from langchain_openai import OpenAIEmbeddings
from langchain_postgres import PGVector
from langchain.schema import Document
# 向量数据库长期记忆(语义)
conn = "postgresql+psycopg://user:pass@localhost/db"
collection = "agent_memory"
vectorstore = PGVector(
connection=conn,
collection_name=collection,
embeddings=OpenAIEmbeddings()
)
# 写入记忆
vectorstore.add_documents([
Document(page_content="User prefers concise answers", metadata={"type": "preference", "user_id": "user_123"})
])
# 读取记忆(语义检索)
memories = vectorstore.similarity_search(
"What style of answers does the user like?",
k=3,
filter={"user_id": "user_123"}
)
print(memories)
长期记忆可以分为 3 种类型:

图 11: Agent 记忆类型
现在已经了解了短期记忆(上下文窗口)和长期记忆(外部存储),下一个问题是:
如何在不添加噪音或浪费 token 的情况下管理两者?
AI Agent 中的记忆管理意味着:
- 在 LLM 的上下文窗口中保留哪些信息
- 在 LLM 外部(长期记忆)存储哪些信息
- 如何在正确的时间在它们之间移动正确的信息
4.3.3 管理上下文窗口中的记忆
目标就是只留对后续步骤有用的信息。如果上下文窗口里有错误、不相关或矛盾的内容,模型会懵。
另外,对话越长,prompt 越大(token 越多),成本越高、响应越慢,甚至可能撑爆上下文窗口。Andrej Karpathy 在这条推文里总结得很好。
避免这个问题,可以这么管理对话历史:
- 删掉旧的、不再相关的消息
- 或者把早期的内容摘要,只留摘要,扔掉原文
这就是管理短期记忆(上下文窗口)的方式。下面看看 Agent 怎么更新长期记忆——也就是怎么写入记忆。
那么 Agent 实际上是如何写入外部长期记忆的?
LLM 自己写不了数据库,它只会生成文本。所以"写入"是这么实现的:Agent 系统(应用)给 LLM 提供记忆工具(比如 save_memory()),LLM 决定用不用。触发工具时,系统把记忆存到外部存储(向量数据库/键值数据库/SQL),之后需要时再捞出来塞回上下文窗口。
4.3.3.1 显式记忆 / 热路径写入
Agent 在对话过程中识别出某些内容很重要并立即使用工具调用保存(例如:“用户偏好 Python” → save_memory())。这立即更新长期记忆,因此可以在下一轮使用。
4.3.3.2 隐式记忆 / 后台写入
Agent 先响应,后台进程稍后总结/提取有用事实并写入长期记忆。这避免了延迟,但记忆可能无法在下一条消息中立即使用。

图 12: 记忆更新优缺点
但 Agent 如何知道什么内容"足够重要"需要在热路径中保存?
方案:需要给Agent 提供记忆策略——一套简单规则,告诉它什么该存、什么绝对不能存。再给模型配记忆工具(比如 save_memory(text, type, confidence))。如果当前消息符合策略,模型就触发工具调用,应用把它写到外部存储。
实践中,Agent 用这几个简单信号判断:
- 稳定性:下周还成立吗?(偏好、个人资料、决策)
- 可重用性:对以后的回答或任务有用吗?
- 影响:会改变 Agent 下次怎么响应吗?
- 确认:用户明确承诺了吗?(“从现在开始…”、“总是…”、“我们决定…”)
经验法则:如果某条信息不太可能在以后的会话里用到,就别存。
记忆策略示例:
SYSTEM_PROMPT = f"""
你是一个 AI Agent。
记忆策略:
只保存稳定、可重用的信息(偏好、关键个人资料事实、进行中的项目详情、已确认的决策)。
绝不保存临时闲聊、原始转录或敏感数据(密码、OTP、token、私钥)。
如果不确定,不要保存。
如果某些内容应该保存,调用:save_memory(text, type, confidence)
"""
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_message},
]
result = llm.chat(messages=messages, tools=[save_memory])
说完了 LLM 如何使用工具,下面聊聊 LLM 怎么学习、做决策,以及怎么跟环境和记忆交互。
- ReACT 框架
"Re"是推理(Reasoning),"Act"是行动(Action)。这个框架帮 Agent 跟外部环境交互,辅助规划和推理。
核心是把 LLM 的推理能力和工具使用放进一个连贯的循环里。
要理解为什么需要 ReAct,先回顾一下思维链(Chain-of-Thought, CoT)提示。
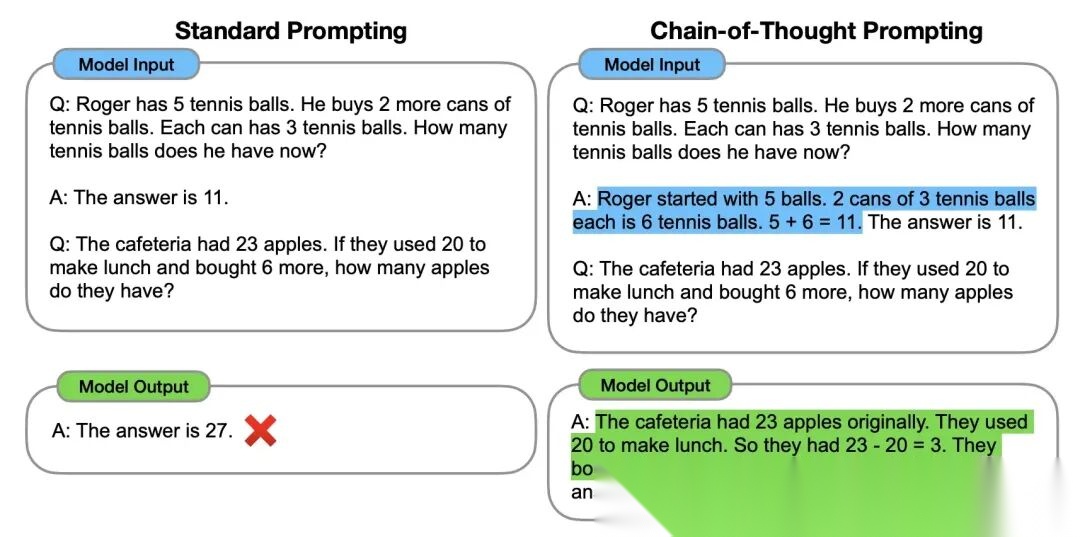
图 13: 工具调用
对比标准提示和 CoT 提示。左边是标准提示,模型直接给答案;右边是 CoT 提示,模型一步步展示推理过程,最后给出正确答案。
事实证明,写思维链——一系列中间推理步骤——能帮模型输出正确答案。Wei et al. (2022) 的研究表明,引导模型完成中间推理步骤,能显著提升数学解题、逻辑推理、多跳问答等任务的表现。
但 CoT 有局限:它接触不到外部世界,所以没法行动。这就是 ReAct 登场的地方。
ReAct 通过 TAO 原则实现:
Thought -> Action -> Observation -> 重复
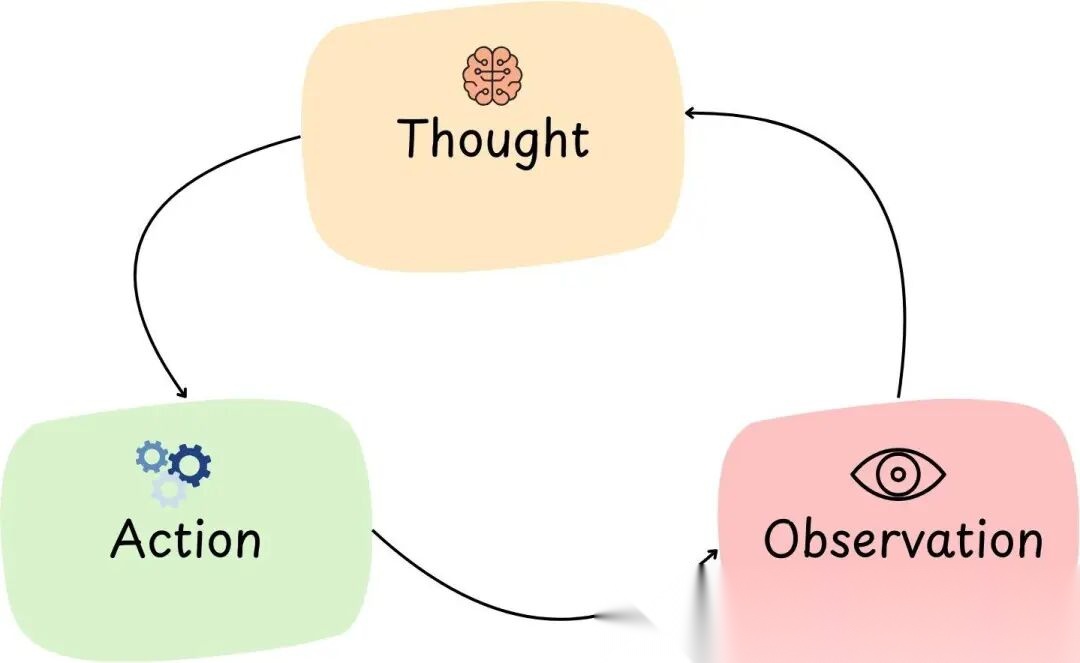
图 14: AI Agent 中的 TAO
思维-行动-观察(TAO)循环是 ReAct Agent 的核心。
这是一个让 Agent 迭代逼近答案的循环。分解一下各阶段:
- 思维(Thought):LLM "思考"下一步做什么。推理步骤,比如规划或分析问题状态。例如:“嗯,要回答这个问题,可能需要数据 X;该用工具 Y 去拿。”
- 行动(Action):基于思维,Agent 调用工具行动。例如:调用搜索工具,查"数据 X"。
- 观察(Observation):Agent 拿到行动的结果——工具返回的新信息。例如:搜索结果返回了相关片段,Agent 观察到并纳入考虑。
找到最终答案,循环才结束。
这本质上是问题求解的反馈循环。过程中如果出问题或出现新要求,就思考、观察、行动,随时调整方向。
示例代码:
# 创建 ReAct 模板
react_template = """Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}"""
prompt = PromptTemplate(
template=react_template,
input_variables=["tools", "tool_names", "input", "agent_scratchpad"]
)
这套机制要跑起来,记忆很关键——得记录循环里的先前交互。没记忆,Agent 会忘记之前发生了什么。所以根据用例选对记忆方案很重要。
- Agent框架
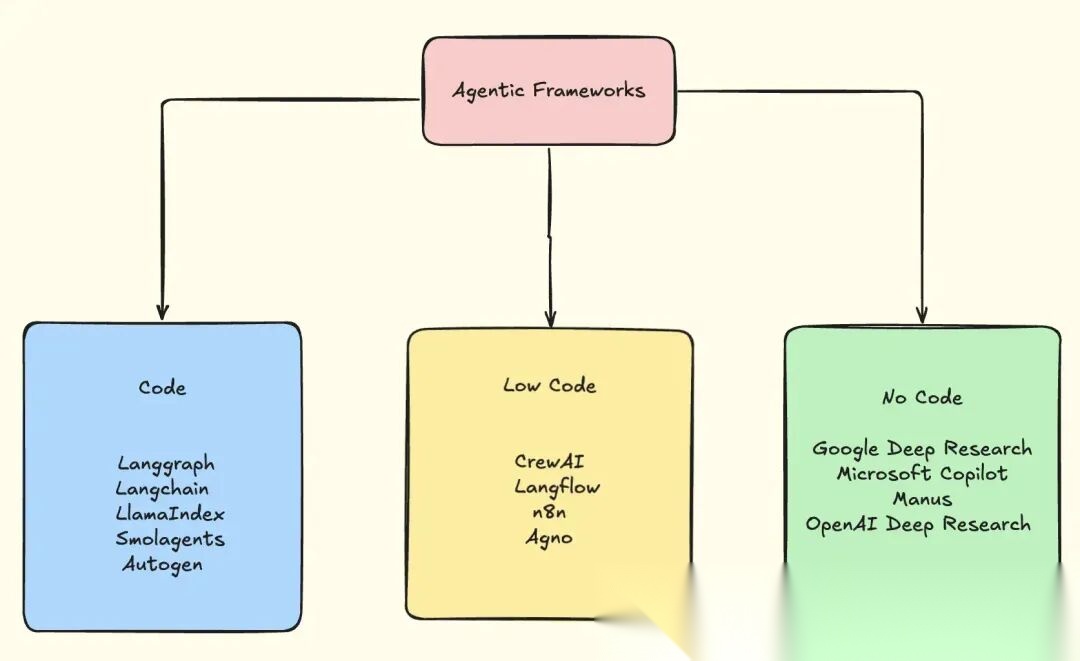
图 15: Agent框架
| 类别 | 框架 | 关键特性与详情 |
|---|---|---|
| 代码 | LangChain | • LLM 应用和 Agent 的基础工具包 • 模块化原语:prompt、工具、记忆、检索器 • 适合需要自行连接一切的场景 |
| 代码 | LangGraph | • 基于 LangChain 的图编排 • 支持分支、循环、重试和条件逻辑 • 比经典 Agent 循环更具确定性 |
| 代码 | LlamaIndex | • 专为 RAG + 外部数据设计 • 索引文档、数据库、向量存储 • 最适合 Agent 需要了解基础模型之外知识的场景 |
| 代码 | SmolAgents | • Hugging Face 的极简 Agent 框架 • Agent 编写并执行 Python 代码作为行动 • 步骤更少、token 更少、开销更低 |
| 代码 | AutoGen | • 多 Agent 对话(规划者、编码者、审阅者等) • 内置代码执行(本地、Docker、Jupyter) • 适合 AI 结对编程和研究工作流 |
| 低代码 | LangFlow | • LangChain 的拖放 UI • 可视化 prompt、工具、记忆、链 • 适合实验和演示 |
| 低代码 | CrewAI | • Agent 组织为 crew 中的角色 • 内置规划、记忆、任务协调 • 适合自然分解为子任务的工作流 |
| 低代码 | n8n | • 可视化工作流自动化 + AI Agent • 触发器、分支逻辑、集成 • Agent 运行于更广泛的业务工作流中 |
| 低代码 | Agno | • 性能优先的全栈多 Agent 系统 • 模型无关、快速启动、最小内存 • 仍在发展中,但非常有前景 |
| 无代码 | Manus AI | • 完全自主、长期运行的 Agent • 规划、执行、反思、持续直至完成 • 内部使用工具、浏览、代码执行 |
| 无代码 | Deep Research (OpenAI & Gemini) | • 目标驱动的研究 Agent,收集、综合并报告 • 无需编排 |
- 工作流模式与Agent模式
软件工程离不开"模式"和"协议"。模式提供了一种结构化、经过验证的思考和设计系统的方式,能帮你避开常见的设计坑。
模式推广最佳实践,也让开发者之间好沟通。
7.1 工作流模式
7.1.1 提示链(Prompt Chaining)
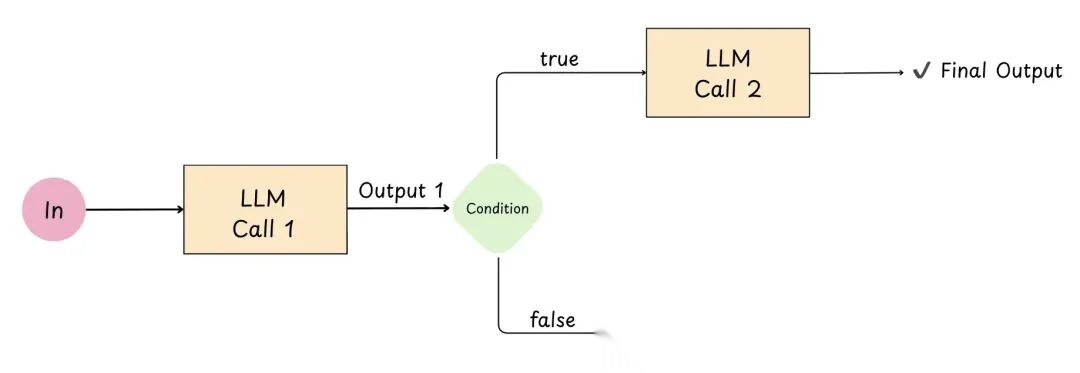
图 16: 提示链
提示链就是把大问题拆成多次 LLM 调用,顺序执行,前一次的输出作为后一次的输入。
好处:
- 每个步骤更简单 → 通常更准确
- 中间步骤可以用特定条件做决策,确保流程不跑偏
import os
from openai import OpenAI
client = OpenAI() # 从环境读取 OPENAI_API_KEY
# --- 步骤 1:总结文本 ---
original_text = (
"Edge computing moves data processing closer to where it's generated-like sensors, phones, or factory machines. "
"This reduces latency, saves bandwidth, and can improve privacy, but it also adds challenges like distributed "
"monitoring, updates at scale, and handling inconsistent connectivity."
)
prompt1 = f"Summarize the following text in one sentence: {original_text}"
resp1 = client.responses.create(
model="gpt-5.2",
input=prompt1
)
summary = resp1.output_text.strip()
print(f"Summary: {summary}")
# --- 步骤 2:将摘要翻译成 Kannada ---
prompt2 = (
"Translate the following summary into Kannada. "
"Only return the translation, no other text:\n"
f"{summary}"
)
resp2 = client.responses.create(
model="gpt-5.2",
input=prompt2
)
translation = resp2.output_text.strip()
print(f"Kannada Translation: {translation}")
7.1.2 路由(Routing)
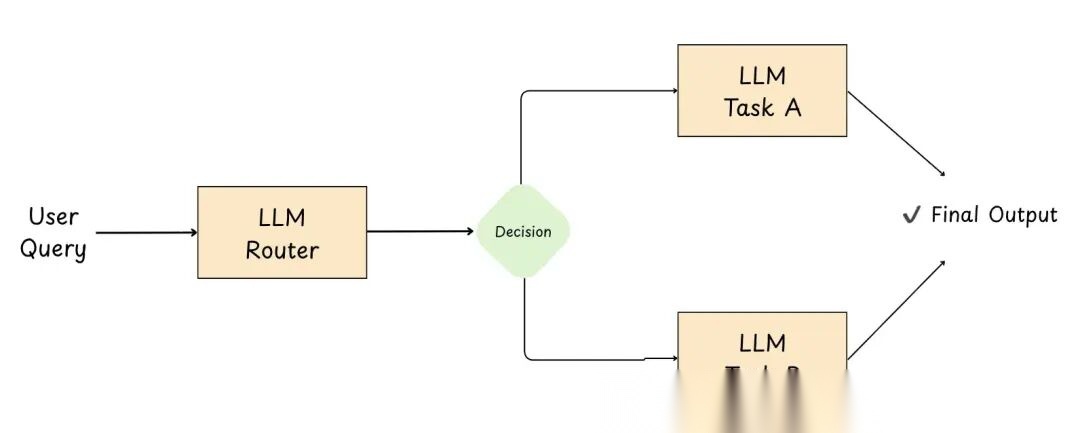
图 17: 路由
路由就是让初始 LLM 当调度员:它把用户输入分类(意图/领域/复杂度),然后发到最合适的工作流、提示、工具或模型去处理。
好处:
- 关注点分离:每个路由可以独立优化(prompt、工具、逻辑)
- 效率和成本更优:简单请求用小模型,复杂请求用大模型
- 客户支持场景:把查询分到专门处理账单、技术支持或产品信息的 Agent
- 行为更可靠:不同类型的输入走专门建的流程
import enum
from pydantic import BaseModel
from openai import OpenAI
client = OpenAI()
class Category(str, enum.Enum): # 定义路由模式
TRAVEL = "travel"
CODING = "coding"
OTHER = "other"
class RoutingDecision(BaseModel):
category: Category
reasoning: str
# -----------------------------
# 2) 路由步骤(结构化输出)
# -----------------------------
user_query = "Plan a 2-day itinerary for Barcelona with food + museums."
# user_query = "Why is my Python list comprehension returning None?"
# user_query = "Write a LinkedIn post about learning distributed systems."
router_system = """
You are a dispatcher for an assistant.
Pick EXACTLY ONE category:
- travel: itineraries, places to visit, logistics, packing, budget, local tips
- coding: debugging, writing code, explaining errors, architecture
- other: anything else or unclear
Return JSON matching:
{ "category": "...", "reasoning": "..." }
Keep reasoning to one short sentence.
"""
# 这就是路由发生的地方:小型/快速模型对请求进行分类
router_resp = client.responses.parse(
model="gpt-4o-mini",
input=[
{"role": "system", "content": router_system},
{"role": "user", "content": f"Query: {user_query}"},
],
text_format=RoutingDecision,
)
decision: RoutingDecision = router_resp.output_parsed
print(f"Routing Decision: category={decision.category}, reasoning={decision.reasoning}")
# -----------------------------
# 3) 交接(专门下游)
# -----------------------------
final_text = ""
if decision.category == Category.TRAVEL:
travel_system = """
You are a travel planner.
Produce a practical plan with time blocks, map-friendly neighborhoods, and food suggestions.
Ask 1 quick question only if needed; otherwise make reasonable assumptions.
"""
travel_prompt = f"Create a helpful response for: {user_query}"
travel_resp = client.responses.create(
model="gpt-4o",
input=[
{"role": "system", "content": travel_system},
{"role": "user", "content": travel_prompt},
],
)
final_text = travel_resp.output_text
elif decision.category == Category.CODING:
coding_system = """
You are a senior software engineer.
Ask for the missing details (language/runtime/error message) only if required.
Give a minimal repro idea + fix + short explanation.
"""
coding_resp = client.responses.create(
model="gpt-5.2",
input=[
{"role": "system", "content": coding_system},
{"role": "user", "content": user_query},
],
)
final_text = coding_resp.output_text
else:
other_system = """
You are a general assistant.
Clarify the user's goal if ambiguous; otherwise respond directly, concise and helpful.
"""
other_resp = client.responses.create(
model="gpt-4o",
input=[
{"role": "system", "content": other_system},
{"role": "user", "content": user_query},
],
)
final_text = other_resp.output_text
print("\nFinal Response:\n", final_text.strip())
7.1.3 并行化(Parallelization)
并行化就是把任务拆成独立的子任务,同时丢给多个 LLM 调用。
所有分支跑完后,收集输出,要么代码合并,要么丢给"聚合器"LLM 综合出最佳答案。
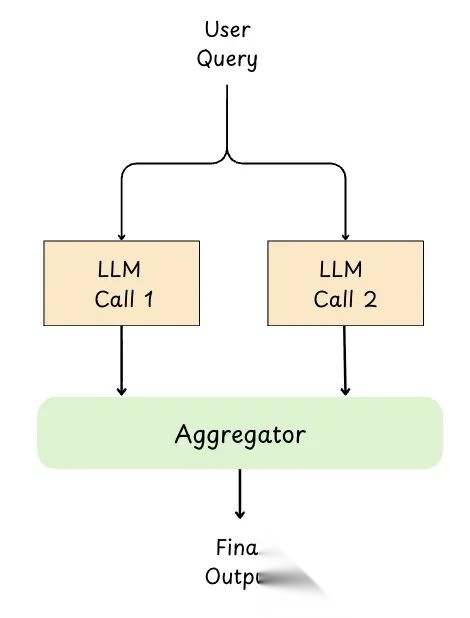
图 18: 并行化
# pip install -U openai
import asyncio
import time
from openai import AsyncOpenAI
# 期望从环境获取 OPENAI_API_KEY
# mac/linux: export OPENAI_API_KEY="..."
# windows (powershell): setx OPENAI_API_KEY "..."
client = AsyncOpenAI()
async def generate_text(prompt: str, model: str = "gpt-4o-mini") -> str:
"""单次异步 LLM 调用(用于并行分支)。"""
resp = await client.responses.create(
model=model,
input=prompt,
)
return resp.output_text.strip()
async def parallelization_workflow() -> str:
# --- 定义独立的并行任务(相同模型,不同提示词) ---
theme = "a curious astronaut discovering an underwater city"
prompts = [
f"Pitch a *hopeful* short story idea about: {theme}. Keep it to 3-4 sentences.",
f"Pitch a *thriller* short story idea about: {theme}. Keep it to 3-4 sentences.",
f"Pitch a *heartfelt* short story idea about: {theme}. Keep it to 3-4 sentences.",
]
start = time.time()
tasks = [generate_text(p, model="gpt-4o-mini") for p in prompts] # 并发调用
ideas = await asyncio.gather(*tasks)
elapsed = time.time() - start
print(f"Time taken (parallel): {elapsed:.2f} seconds\n")
print("--- Individual Results ---")
for idx, idea in enumerate(ideas, 1):
print(f"Idea {idx}:\n{idea}\n")
# --- 聚合步骤(单次综合器调用) ---
joined = "\n".join([f"Idea {i+1}: {txt}" for i, txt in enumerate(ideas)])
aggregator_prompt = (
"You are an editor. Merge the three ideas below into ONE cohesive story premise.\n"
"Constraints:\n"
"- 1 paragraph\n"
"- Keep the best elements from each idea\n"
"- Preserve the original theme\n\n"
f"{joined}"
)
aggregation_resp = await client.responses.create(
model="gpt-5.2", # 用于综合的更强模型(可选)
input=aggregator_prompt,
)
return aggregation_resp.output_text.strip()
def main():
result = asyncio.run(parallelization_workflow())
print("\n--- Aggregated Summary ---")
print(result)
if __name__ == "__main__":
main()
好处:
- 端到端延迟更低:独立子任务并发跑,不用一步步等
- 质量更好:能生成多个视角再合并,或投票减少错误
- 批处理扩展性好:总结多部分/多文档,或在多个输入上重复同样推理
- 综合阶段更清晰:结果能验证、去重,再组合成连贯输出
7.1.4 协调器-工作者(Orchestrator-Workers)
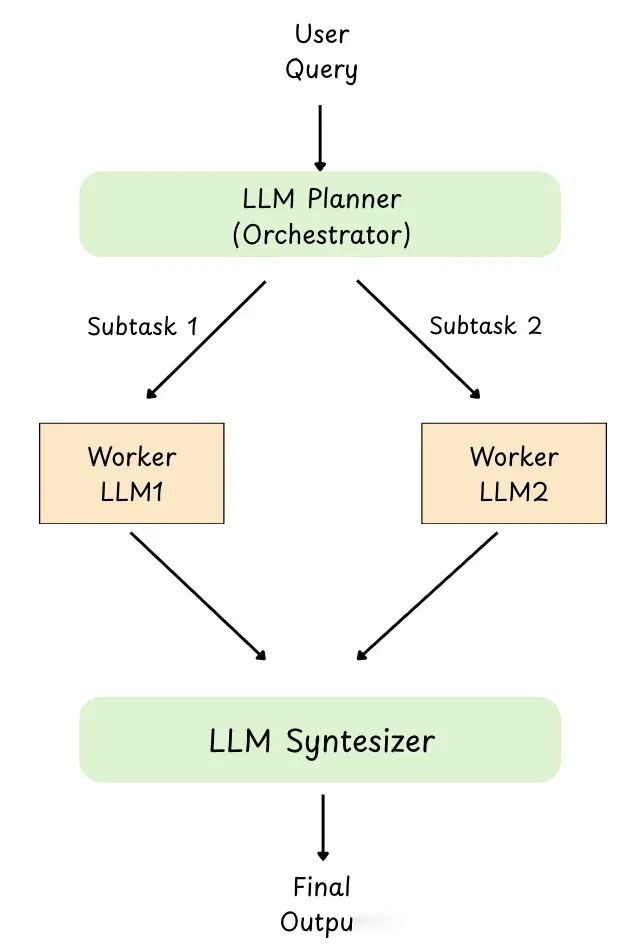
图 19: 协调器工作者
协调器-工作者模式是中心 LLM(协调器)读用户请求,动态拆成子任务,每个子任务分配给专门的 worker LLM,最后把 worker 的输出组合成最终响应。
跟并行化不同,子任务不是 predefined,协调器看具体输入决定该干什么。
用途:
- 处理不可预测的复杂度:协调器可以即时决定需要哪些子任务
- 分工:worker 可以基于角色(规划者、研究员、编码者、审阅者)拥有专门的提示词/工具
- 更具扩展性的系统:可以添加或交换 worker 而无需更改整个工作流
- 更好的最终质量:协调器可以验证、调和冲突并综合连贯的输出
- 示例:扫描仓库,找到入口点(main.py/app.py),列出路由/依赖,返回关于需要更改哪些文件的简短 JSON 摘要。协调器首先将此扫描子任务委托给 worker,以便动态决定下一个子任务(编辑哪些文件、接下来调用哪些 worker),因为这些信息事先无法获知。
# pip install -U openai pydantic
from typing import List
from pydantic import BaseModel, Field
from openai import OpenAI
client = OpenAI()
# -----------------------------
# 模式:计划 + 任务
# -----------------------------
class Task(BaseModel):
task_id: int
description: str
assigned_to: str = Field(description="Worker type: Researcher or Writer")
class Plan(BaseModel):
goal: str
steps: List[Task]
# -----------------------------
# Worker 实现
# -----------------------------
def researcher_worker(goal: str) -> str:
prompt = f"""
You are a Researcher.
Goal: {goal}
Produce:
- 5 punchy bullet points (benefits of AI agents)
- 2 real-world examples (generic, no web browsing)
Keep it concise.
"""
resp = client.responses.create(model="gpt-4o-mini", input=prompt)
return resp.output_text.strip()
def writer_worker(goal: str, notes: str) -> str:
prompt = f"""
You are a Writer.
Write a short blog post (~250-350 words) for a general tech audience.
Goal: {goal}
Use these notes (don't invent new facts beyond them):
{notes}
Structure:
- Hook (1-2 lines)
- 3 benefit sections with short headings
- Closing takeaway
"""
resp = client.responses.create(model="gpt-4o", input=prompt)
return resp.output_text.strip()
# -----------------------------
# 协调器:计划 -> 委派 -> 综合
# -----------------------------
user_goal = "Write a short blog post about why AI agents are useful in real products."
planner_prompt = f"""
You are an orchestrator. Create a minimal plan to achieve the goal.
Use ONLY these worker types: Researcher, Writer.
Return JSON with:
- goal
- steps: list of {{task_id, description, assigned_to}}
Goal: {user_goal}
"""
# 步骤 1:生成动态计划(结构化输出)
plan_resp = client.responses.parse(
model="gpt-4o", # 强力规划器
input=planner_prompt,
text_format=Plan,
)
plan: Plan = plan_resp.output_parsed
print(f"Goal: {plan.goal}\n")
for step in plan.steps:
print(f"Step {step.task_id}: {step.description} (Assignee: {step.assigned_to})")
# 步骤 2:执行计划(worker)
notes = ""
final_post = ""
for step in plan.steps:
if step.assigned_to.lower() == "researcher":
notes = researcher_worker(plan.goal)
elif step.assigned_to.lower() == "writer":
final_post = writer_worker(plan.goal, notes)
else:
# 回退:如果规划器输出意外内容
resp = client.responses.create(
model="gpt-4o-mini",
input=f"Goal: {plan.goal}\nTask: {step.description}\nWrite a helpful output."
)
final_post = resp.output_text.strip()
print("\n--- Research Notes ---\n", notes)
print("\n--- Final Blog Post ---\n", final_post)
7.2 AI Agent 模式
7.2.1 ReACT 模式
前文讨论的 ReAct 模式也属于Agent模式之一。
7.2.2 评估-优化器(Evaluator-Optimizer,反射)
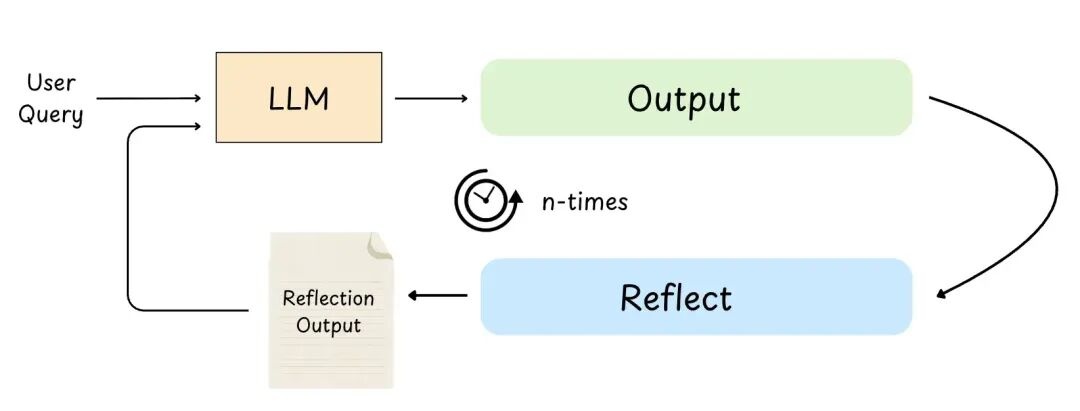
图 20: 评估-优化器
评估-优化器(也叫反射)是 Agent 先出个草稿,然后跑评估步骤,按标准(清晰度、准确性、语气、约束)打分,再用反馈迭代优化,直到满意或达到最大迭代次数。
好处:
- 质量更高:定稿前就能发现错误、漏掉的要求和薄弱的推理
- 输出更可靠:评估器充当审阅者,把关准确性、清晰度、安全性、风格
- 适合主观任务:写作、调语气、调整结构、"是否符合评分标准?"这类任务特别受益
- 示例:Agent 写函数
is_valid_email(),跑单元测试,挂了,反思边界情况,重写,直到测试通过
# pip install -U openai pydantic
import enum
from pydantic import BaseModel
from openai import OpenAI
client = OpenAI()
# -----------------------------
# 结构化评估模式
# -----------------------------
class EvaluationStatus(str, enum.Enum):
PASS = "PASS"
FAIL = "FAIL"
class Evaluation(BaseModel):
evaluation: EvaluationStatus
feedback: str
reasoning: str
# -----------------------------
# 1) 初始生成(编写代码)
# -----------------------------
def generate_function(feedback: str | None = None) -> str:
prompt = """
Write a Python function `is_palindrome(s: str) -> bool`.
Rules:
- Case-insensitive
- Ignore spaces and punctuation (keep only alphanumeric)
- Return True if palindrome, else False
- Output ONLY python code (no markdown, no explanation)
"""
if feedback:
prompt += f"\nFix based on this feedback:\n{feedback}\n"
resp = client.responses.create(
model="gpt-4o-mini",
input=prompt,
)
code = resp.output_text.strip()
print(f"\nGenerated Code:\n{code}")
return code
# -----------------------------
# 2) 评估(审阅 + 单元测试)
# -----------------------------
def evaluate(code: str) -> Evaluation:
print("\n--- Evaluating Code ---")
critique_prompt = f"""
You are a strict code reviewer + test author.
Check the code for:
1) Correctness vs rules
2) Edge cases
3) Whether it will pass the unit tests you would write
Return JSON with:
- evaluation: PASS or FAIL
- feedback: specific fixes needed
- reasoning: 1 short sentence
Code:
{code}
These unit tests must pass:
- is_palindrome("Racecar") == True
- is_palindrome("A man, a plan, a canal: Panama!") == True
- is_palindrome("No lemon, no melon") == True
- is_palindrome("hello") == False
- is_palindrome("") == True
- is_palindrome("12321") == True
- is_palindrome("123ab321") == False
"""
critique_resp = client.responses.parse(
model="gpt-4o-mini",
input=critique_prompt,
text_format=Evaluation,
)
result: Evaluation = critique_resp.output_parsed
print(f"Evaluation Status: {result.evaluation}")
print(f"Feedback: {result.feedback}")
print(f"Reasoning: {result.reasoning}")
return result
# -----------------------------
# 反射循环(评估-优化器)
# -----------------------------
max_iterations = 3
# 从故意"错误"的实现开始,演示 FAIL -> 反馈 -> 改进
current_code = "def is_palindrome(s: str) -> bool:\n return s == s[::-1]\n"
for i in range(1, max_iterations + 1):
print(f"\n=== Iteration {i} ===")
evaluation = evaluate(current_code)
if evaluation.evaluation == EvaluationStatus.PASS:
print("\n Final Code (PASS):")
print(current_code)
break
else:
current_code = generate_function(feedback=evaluation.feedback)
if i == max_iterations:
print("\n Max iterations reached. Last attempt:")
print(current_code)
7.2.3 工具使用模式
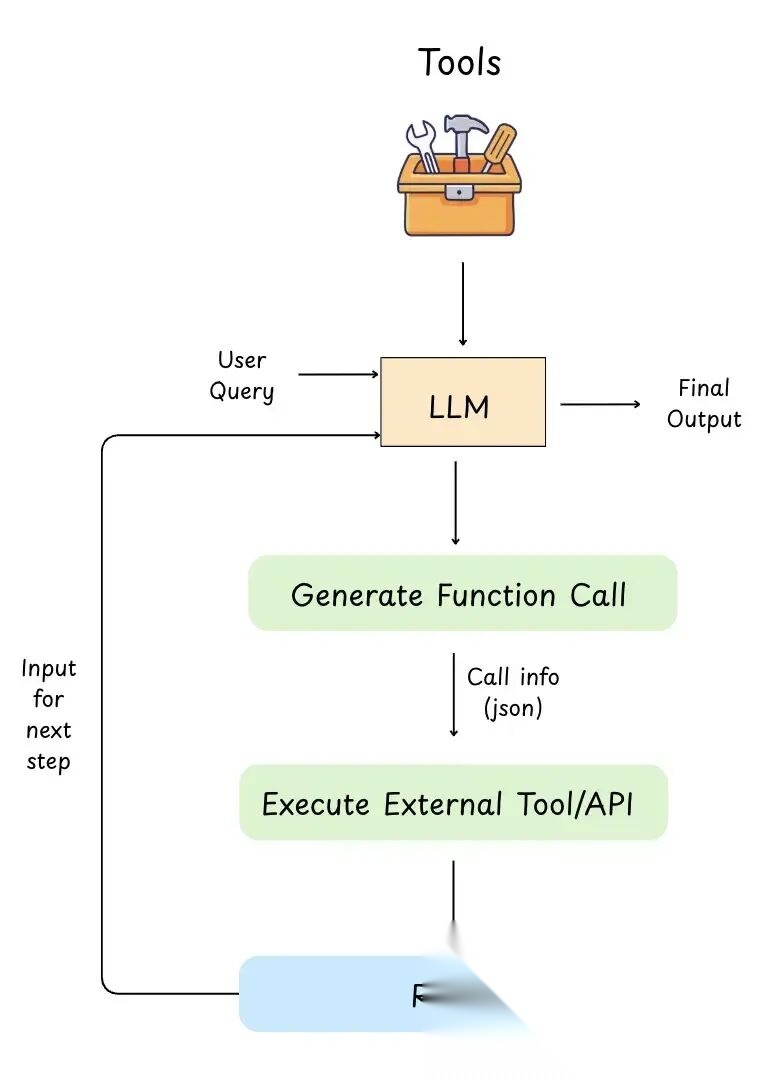
图 21: 工具使用模式
如前所述,LLM 只能读取和写入文本。实际上无法查找实时数据、运行代码或自行预订。
在工具使用模式中,开发者需要为 LLM 提供工具访问权限(函数/API),如前文讨论的(表格图片展示了工具示例)。同时需要告知 LLM 每个工具的形态:
- 工具名称
- 功能描述
- 所需输入(模式)
工作原理(逐步):
- 用户提问:“预订明天的会议"或"特斯拉股价是多少?”
- LLM 决定需要工具:因为它无法可靠地从记忆中完成这些操作
- LLM 输出结构化的"函数调用"(通常是 JSON):示例:
{"name":"get_stock_price","arguments":{"ticker":"TSLA"}} - 应用运行工具:LLM 不运行它,后端执行 API/函数
- 工具返回结果:示例:
{"price":245.30} - LLM 使用该结果撰写最终答案:“TSLA 当前交易价格为 $245.30。”
此模式通常通过函数调用实现,使 LLM 能够执行实际操作并使用实时数据,远超其在训练期间学到的内容。
常见用例:
- 预订预约(日历 API)
- 获取实时股价(金融 API)
- 使用嵌入搜索文档(RAG/向量数据库)
- 控制智能设备(IoT 工具)
- 运行代码或单元测试
经典工具使用的局限性:
- 工具硬编码在应用中
- LLM 只知道显式定义的工具
- 添加新工具需要代码更改 + 重新部署
- 工具与单个模型或框架紧密耦合
这导致了 MCP 的诞生。
工具使用模式定义了模型如何使用工具,MCP 定义了工具如何被描述、发现和调用
使用 MCP:
- 工具存在于外部工具服务器中
- 工具可以动态发现
- 工具通过标准化模式自我描述
- 模型和应用与工具实现解耦
- 相同工具可以被多个模型和客户端复用
从概念上讲,交互循环保持不变。
7.2.4 多 Agent 模式
多 Agent 模式是建 AI 系统最复杂的方式。
不靠单个 Agent 包打天下,而是多个专门 Agent 协作完成共同目标。
用自主或半自主 Agent。每个 Agent 专精特定任务,有专门的知识或特定工具。
Agent 之间可以交互、协作、协调(用协调器/管理器,或用交接逻辑)。交接逻辑就是一个 Agent 把控制权交给另一个 Agent。
示例:旅行助手 Agent 的例子,一个 Agent 专门找航班,找到后酒店 Agent 负责订房。
关键特征:
- 并行执行:子任务能同时处理
- 委派:主管理 Agent 按子任务派活给其他 Agent
- 分布式上下文:每个 Agent 有自己的上下文,是总信息的子集。(群体类型交接逻辑的多 Agent 设置里,通常有统一上下文。)
以下是协调器/管理器方法的图片:
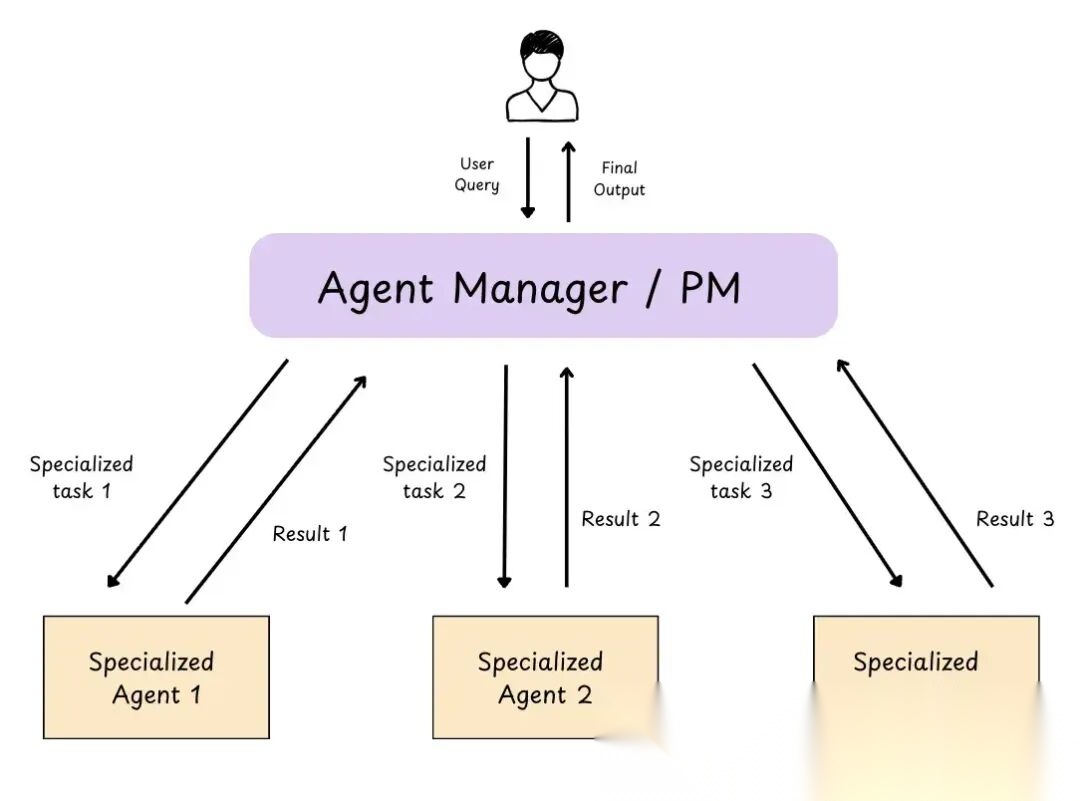
图 22: 协调器模式多 Agent
以下是基于交接的多 Agent 协作图片:
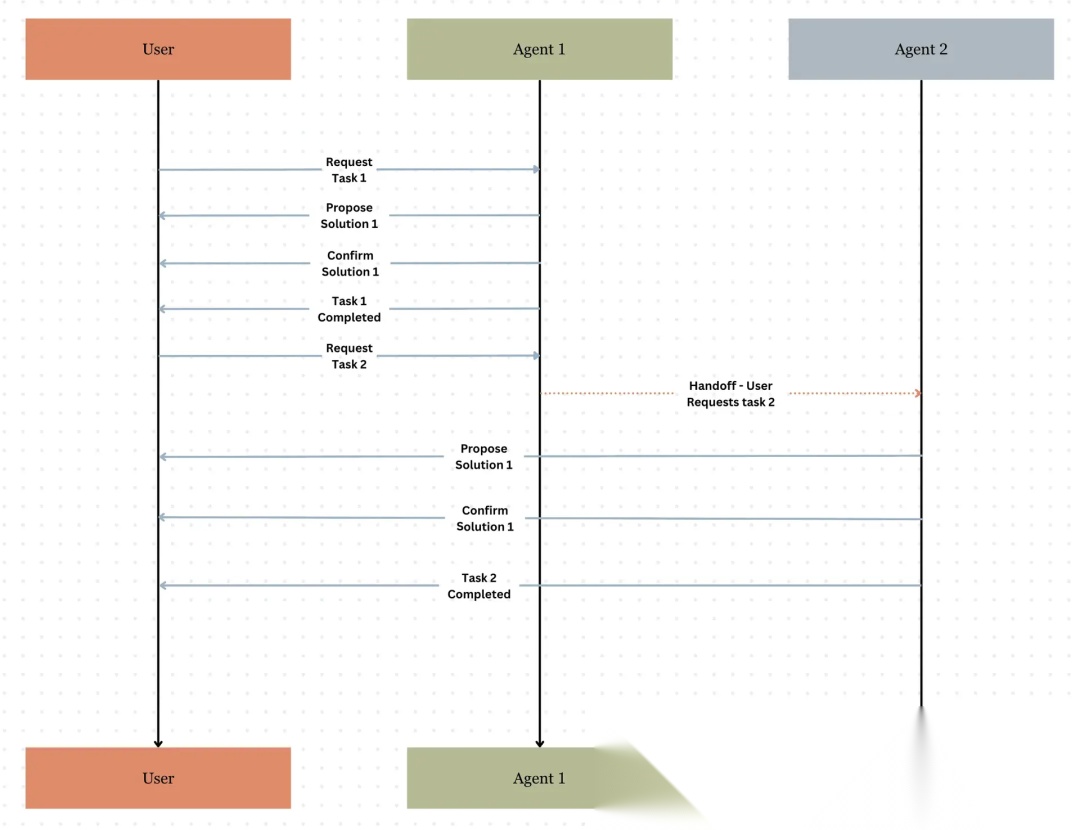
图 23: 协调器模式多 Agent
下一节将更详细地讨论这些多 Agent 系统,包括它们如何共享信息和上下文、如何调用其他 Agent、一个 Agent 如何知道需要调用另一个等。
- 多 Agent 模式
8.1 子 Agent:集中式编排 / Agent 即工具
子 Agent 是为单个、明确定义的任务专门建的专用 Agent。通常跟主协调器 Agent 配合,主 Agent 派活给子 Agent。子 Agent 有自己的上下文窗口。子 Agent 是无状态的(不记每次请求的上下文,每个请求都是全新的。)
Claude Code 在会话开始时加载子 Agent 列表,但只在需要时才运行。
这架构提供集中控制,所有路由走主 Agent,可以并行调用多个子 Agent。
唯一 trade-off 是多了一跳子 Agent,每次请求得先过主 Agent,再到子 Agent,返回也一样。模型跳转多了,token 用得更多,成本更高,延迟也更长。
Deep Agents 提供了开箱即用的实现,只需几行代码即可添加子 Agent。(如需要将复杂子任务委派给专门的子 Agent。)
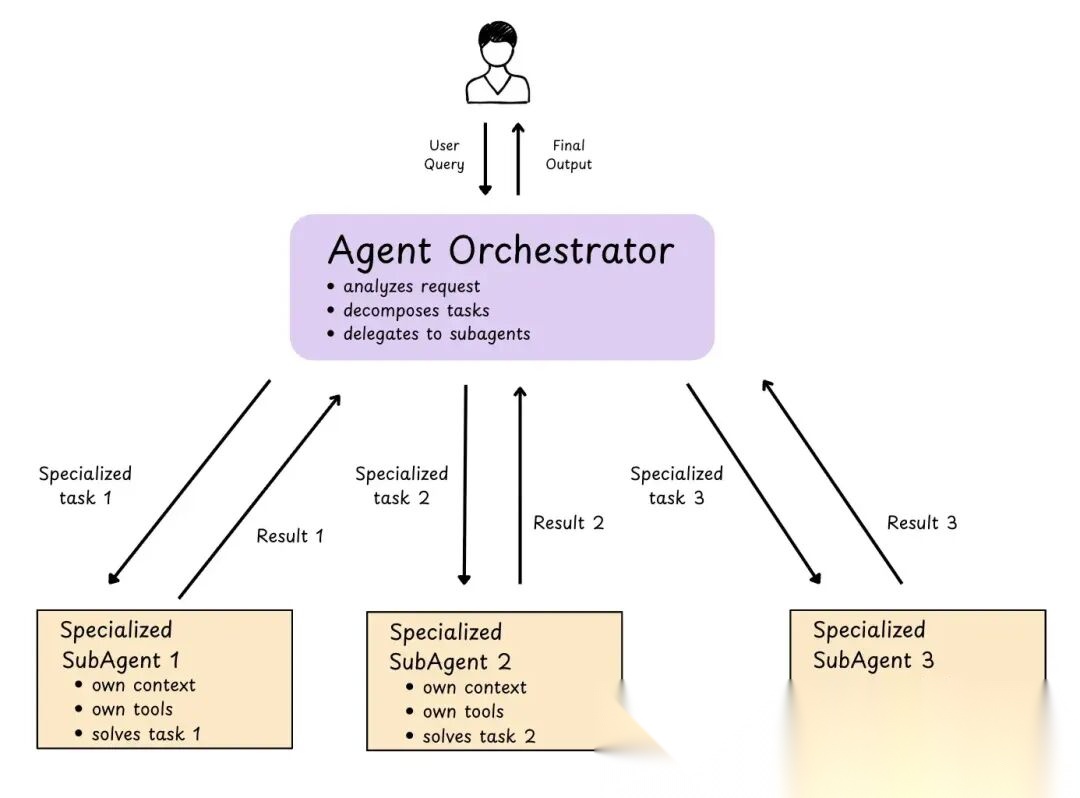
图 24: 子 Agent 模式
Agent 即工具是 OpenAI 为此模式提供的名称。OpenAI 文档和Claude Code 文档
此模式可以通过多种方式使用:
并行运行:可以并行调用多个子 Agent 同时工作。当两个子 Agent 的任务独立时,这种模式很合适。
链式子 Agent:在此模式下,子 Agent 按顺序运行——一个子 Agent 完成任务并返回主协调器,后者再返回并发送给下一个子 Agent。
8.2 技能模式
这模式里,Agent 只在需要时按需加载提示和知识。也叫渐进式披露。先看图,再分析原理。
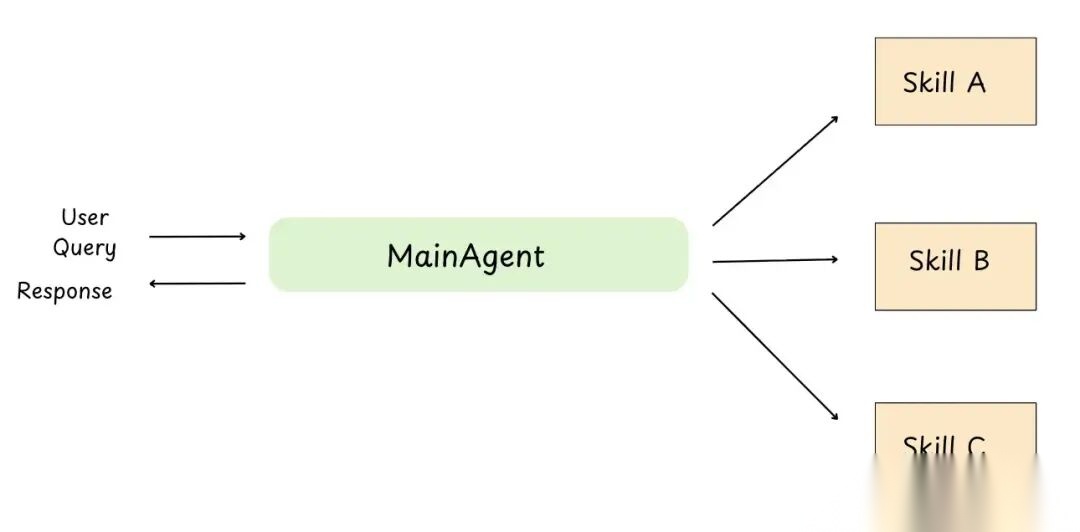
图 25: 技能模式
图上只有一个主 Agent,怎么会是多 Agent 模式?
关键在于让主 Agent 看起来精通多种技能,需要时才加载对应技能的上下文。
每个技能像一本小"剧本":
- 提示(怎么思考/怎么回)
- 规则(该做啥/不该做啥)
- 示例/知识(防止幻觉)
- 有时带脚本/工具(能跑的命令)
核心理念:Agent 不会一直把所有技能记在"脑子里"。需要时才加载技能上下文。
所以感觉像多 Agent 系统,因为同一个 Agent 能在"模式"间切换(SQL 模式、支付模式、调试模式等)。但技术上还是单个 Agent,只是按需加载上下文。
8.3 交接(handoff)模式
这模式里,一个主 Agent 跟用户对话。
当主 Agent 发现某个请求不在自己职责范围内,它会说:“这我不管,但另一个 Agent 能处理……转接过去。”
然后任务传给对应的 Agent(专家 Agent),那个 Agent 变成活跃状态开始处理。
专家 Agent 完成后,主 Agent 把最终答案展示给用户(或者专家 Agent 直接回,看系统怎么建)。
跟上文多 Agent 模式部分的图一样。
8.4 路由模式
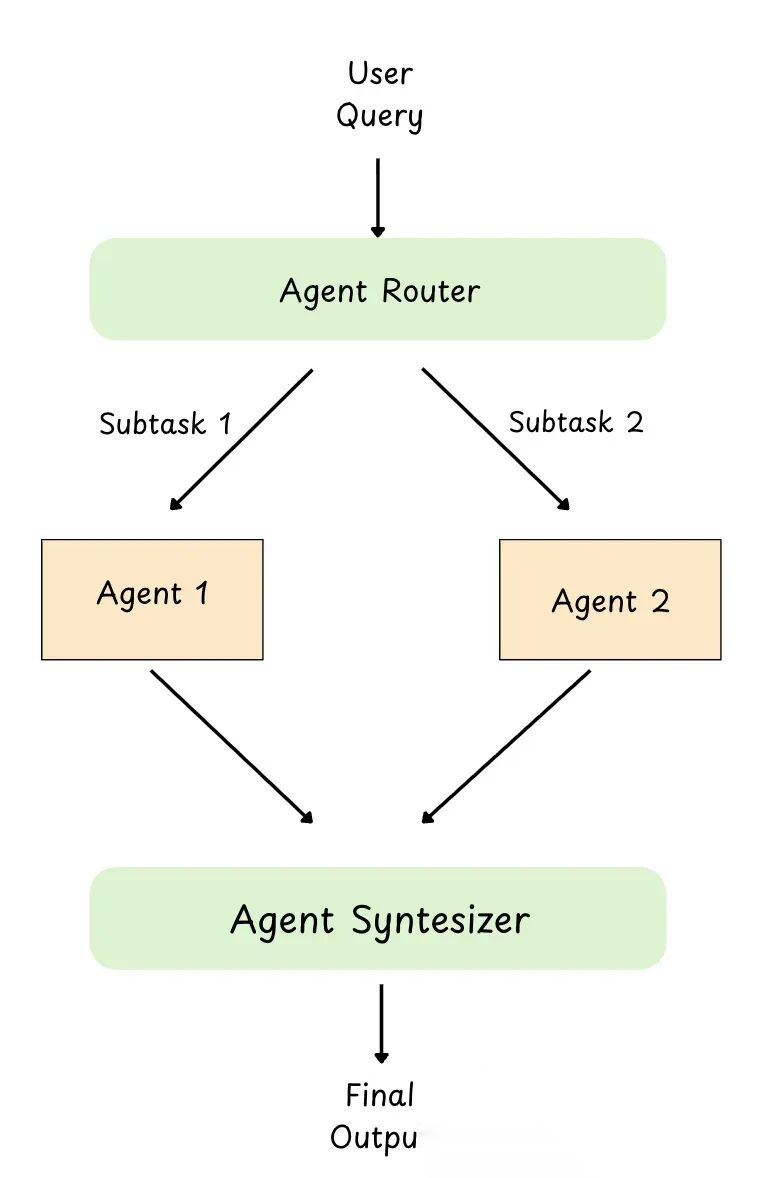
图 26: 路由 Agent 模式
这模式跟之前看的"Agent + 工具"很像。唯一区别:不是路由到工具,而是路由到 Agent。
这么理解:
- 工具模式:Agent 决定调哪个工具
- 路由模式:路由器决定调哪个 Agent(退款 Agent、预订 Agent、调试 Agent 等)
路由器的工作很简单:读用户请求,选最合适的 Agent,把任务转发过去。
Langchain 制作了这张精美的表格。

图 27: 多 Agent 使用表
注意:在这些多 Agent 模式中,Agent 之间的调用是同步的,因此如果需要这些多 Agent 的事件驱动分布式系统
AI时代,未来的就业机会在哪里?
答案就藏在大模型的浪潮里。从ChatGPT、DeepSeek等日常工具,到自然语言处理、计算机视觉、多模态等核心领域,技术普惠化、应用垂直化与生态开源化正催生Prompt工程师、自然语言处理、计算机视觉工程师、大模型算法工程师、AI应用产品经理等AI岗位。
掌握大模型技能,就是把握高薪未来。
那么,普通人如何抓住大模型风口?
AI技术的普及对个人能力提出了新的要求,在AI时代,持续学习和适应新技术变得尤为重要。无论是企业还是个人,都需要不断更新知识体系,提升与AI协作的能力,以适应不断变化的工作环境。
因此,这里给大家整理了一份《2026最新大模型全套学习资源》,包括2026最新大模型学习路线、大模型书籍、视频教程、项目实战、最新行业报告、面试题、AI产品经理入门到精通等,带你从零基础入门到精通,快速掌握大模型技术!
由于篇幅有限,有需要的小伙伴可以扫码获取!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
5. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

为什么大家都在学AI大模型?
随着AI技术的发展,企业对人才的需求从“单一技术”转向 “AI+行业”双背景。企业对人才的需求从“单一技术”转向 “AI+行业”双背景。金融+AI、制造+AI、医疗+AI等跨界岗位薪资涨幅达30%-50%。
同时很多人面临优化裁员,近期科技巨头英特尔裁员2万人,传统岗位不断缩减,因此转行AI势在必行!

这些资料有用吗?
这份资料由我们和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


大模型全套学习资料已整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献636条内容
已为社区贡献636条内容

所有评论(0)