YOLO26最新创新改进系列:史诗级更新!隆重推出YOLO算法与K折交叉验证的集成方案。这一组合充分利用K折交叉验证的稳定性优势,对YOLO模型进行极致优化与科学验证!!!
YOLO26最新改进系列推出YOLO算法与K折交叉验证的集成方案,通过将数据分为K份进行轮换验证,显著提升模型泛化能力。该方案特别针对目标检测任务优化,确保图片标注完整性,提供详细操作步骤和代码示例(如KfoldsTrain.py)。研究显示该方法能获得更稳定的mAP评估结果(如0.740±0.025),并指导最终模型训练。作者提供B站教程源码和45+改进组合,强调该方法可减少数据偏差但计算成本较
YOLO26最新创新改进系列:史诗级更新!隆重推出YOLO算法与K折交叉验证的集成方案。这一组合充分利用K折交叉验证的稳定性优势,对YOLO模型进行极致优化与科学验证,能显著提升研究成果的泛化能力和说服力,让研究结论无懈可击。
购买相关资料后畅享一对一答疑!
畅享超多免费持续更新且可大幅度提升文章档次的纯干货工具!见文末!
购买相关资料后畅享一对一答疑!
截止到发稿时,B站YOLO26最新改进系列的源码包,已更新了45+种!!!
自己排列组合2-4种后,考虑位置不同后可排列组合上千万种!!专注AI学术,关注B站博主:Ai学术叫叫兽!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
1. 什么是K折交叉验证?
核心思想:将原始数据集随机、均匀地划分为K个互斥的子集(称为“折”,folds)。然后,依次将其中1个折作为验证集,剩下的K-1个折作为训练集,进行K次模型的训练和验证。最终,将K次验证结果的平均值作为模型性能的估计。
目的:
- 充分利用数据:在数据量有限的情况下,让每一个样本都有机会被用于训练和验证,从而得到对模型性能更可靠、更稳定的评估。
- 防止过拟合:避免因为某一次特定的训练集-验证集划分(如随机划分)而带来的偶然性结果,更能反映模型的泛化能力。
2. 目标检测中的特殊考量
与普通的分类任务不同,目标检测的标注数据是图片+边界框(Bounding Box)+类别。因此,在划分数据时,我们是以图片为单位进行划分,而不是以单个边界框。
关键点:要确保同一张图片的所有标注(多个边界框)必须同时出现在训练集或验证集中,不能拆分到两个集合里。同时,划分时应尽量保持每一折中各个类别的分布与整体数据集相似(分层采样)。
3. 详细步骤与示例
我们以一个非常简单的数据集为例,假设我们有一个包含10张图片的数据集,我们进行 5折交叉验证(即K=5)。
步骤 1:数据准备与划分
- 原始数据集 D = {Image_1, Image_2, …, Image_10}
- 将 D 随机打乱,然后均匀分成 5 个折(Folds):
- Fold 1: {Image_1, Image_2}
- Fold 2: {Image_3, Image_4}
- Fold 3: {Image_5, Image_6}
- Fold 4: {Image_7, Image_8}
- Fold 5: {Image_9, Image_10}
这个过程可以用下图直观表示:
步骤 2:进行K次训练与验证
现在,我们进行5次循环。每次选择一个不同的折作为验证集,其余4个折作为训练集。
| 实验轮次 | 训练集(K-1=4个折) | 验证集(1个折) |
|---|---|---|
| 第 1 轮 | Fold 2, Fold 3, Fold 4, Fold 5 | Fold 1 |
| 第 2 轮 | Fold 1, Fold 3, Fold 4, Fold 5 | Fold 2 |
| 第 3 轮 | Fold 1, Fold 2, Fold 4, Fold 5 | Fold 3 |
| 第 4 轮 | Fold 1, Fold 2, Fold 3, Fold 5 | Fold 4 |
| 第 5 轮 | Fold 1, Fold 2, Fold 3, Fold 4 | Fold 5 |
这个过程可以通过下图清晰地展示:
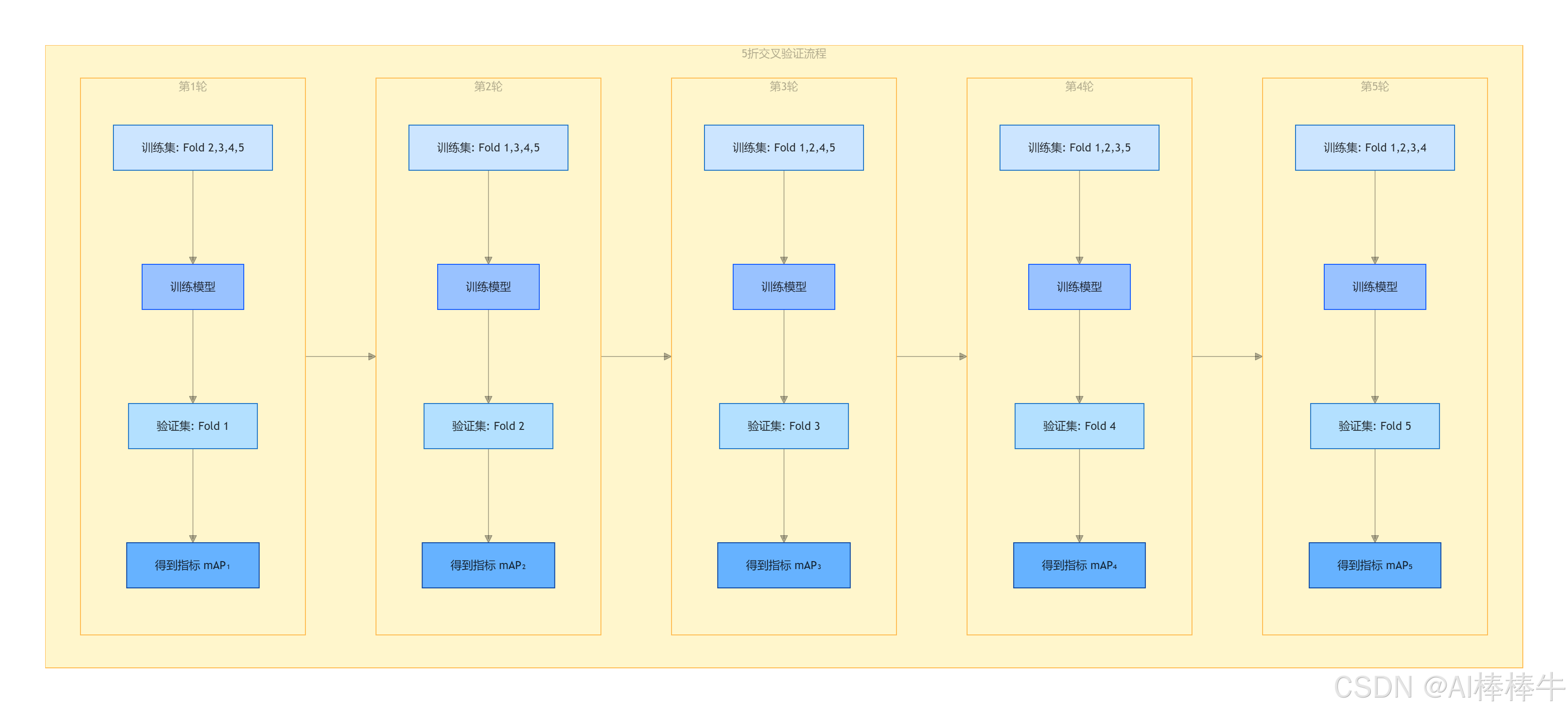
步骤 3:性能评估与最终结果
目标检测最常用的评估指标是mAP(mean Average Precision)。假设我们经过5轮实验,得到了5个mAP值:
- 第1轮 mAP₁ = 0.72
- 第2轮 mAP₂ = 0.75
- 第3轮 mAP₃ = 0.71
- 第4轮 mAP₄ = 0.78
- 第5轮 mAP₅ = 0.74
最终的性能评估是这K个结果的算术平均值。
公式:
在CSDN中可直接使用的公式格式(采用Markdown的LaTeX语法,用$$包裹块级公式)如下:
以下是从内容中提取的所有公式(保持原LaTeX格式,可直接复制使用):

最终报告:模型在该数据集上的性能为 ( mAP = 0.740 \pm 0.025 )。这个结果比单次随机划分得到的评估要可靠得多。
4. 最终模型的获取
需要注意的是,K折交叉验证的主要目的是评估模型性能,而不是直接产生一个用于部署的最终模型。
当我们通过K折交叉验证确定了一个满意的模型架构和超参数后,为了得到最终的模型,常见的做法是:
用全部的数据(即所有K个折)重新训练一次模型。这样得到的模型利用了所有可用的数据,通常具有最好的泛化能力。
5. 代码获取及使用指令(一键操作)
5.1 代码获取
5.2 运行指令
5.2.1 从头开始训练(使用模型配置)
python KfoldsTrain.py --data datasets/coco128/data.yaml --model ultralytics/cfg//models/26/yolo26.yaml
5.2.2 迁移学习(使用预训练权重)
python KfoldsTrain.py --data datasets/coco128/data.yaml
--weights yolo26.pt
5.2.3 同时使用模型配置和预训练权重(不推荐,有点脱裤子放屁了)
python KfoldsTrain.py --data datasets/coco128/data.yaml --model models/yolov8n.yaml --weights yolov8n.pt
总结
| 方面 | 描述 |
|---|---|
| 核心 | 将数据分K份,轮流做验证集,平均K次结果作为性能估计。 |
| 目标检测应用 | 按图片划分,保持图片内标注的完整性。 |
| 优点 | 1. 数据利用充分,评估结果稳定可靠。 2. 减少因数据划分不当而引起的评估偏差。 |
| 缺点 | 1. 计算成本高,需要训练K个模型。 2. 流程相对复杂。 |
| 结果 | 最终性能 = K次验证结果的均值 ± 标准差。 |
| 最终模型 | 使用全部数据重新训练一个模型。 |
通过以上详细的步骤、示例、公式和图表的说明,叫叫兽最亲爱的家人们应该对目标检测中的K折交叉验证有了一个全面而深入的理解。
写在最后
学术因方向、个人实验和写作能力以及具体创新内容的不同而无法做到一通百通,所以本文作者即B站Up主:Ai学术叫叫兽
在所有B站资料中留下联系方式以便在科研之余为家人们答疑解惑,本up主获得过国奖,发表多篇SCI,擅长目标检测领域,拥有多项竞赛经历,拥有软件著作权,核心期刊等经历。
因为经历过所以更懂小白的痛苦!
因为经历过所以更具有指向性的指导!
祝所有科研工作者都能够在自己的领域上更上一层楼!
所有科研参考资料均可点击此链接,合适的才是最好的,希望我的能力配上你的努力刚好合适!
以下为给大家庭小伙伴们免费更新过的绘图代码,均配有详细教程,超小白也可一键操作! 后续更多提升文章档次的资料的更新请大家庭的小伙伴关注我B站及抖音:Ai学术叫叫兽!
所有科研参考资料均可点击此链接,合适的才是最好的,希望我的能力配上你的努力刚好合适!



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)