黑客松冠军配置!老金拆解8大核心思路,值得反复品味
本文介绍了一套完整的ClaudeCode工作流方法论,基于GitHub高星项目everything-claude-code。核心内容包括:1)用CLI+Skills替代MCP降低Token消耗;2)5阶段Agent编排模式确保工作流系统化;3)针对不同任务选择Haiku/Sonnet/Opus模型的优化策略;4)验证循环和并行化策略提升效率;5)记忆持久化方案作为补充。这套经过实战验证的方法论不仅
老金我之前写过3篇AI记忆方案的文章:claude-mem(轻量)、mcp-memory-service(重量)、openclaw三层架构(概念性)。
今天讲的第四种方案,不只是记忆。
它是一套完整的Claude Code工作流方法论。
包括Token优化、Agent编排、并行化、验证循环、复合效应。
四种方案的详细对比,文末有专门一节。先往下看。
周末刷GitHub的时候,老金我发现了这个神仓库。
28.8k星,3.4k Fork。
名字叫everything-claude-code。
点进去一看,卧槽,这不就是我一直想要的东西吗?
作者是个叫Affaan Mustafa的哥们。
他和队友在Anthropic x Forum Ventures黑客松上,用Claude Code 8小时做了个产品叫zenith.chat。
直接拿下冠军,赢了15000美元API credits。
关键是,他把10个月积累的Claude Code配置和方法论全开源了。
老金我研究了一晚上,今天给你们拆解一下这个神器到底神在哪。
核心思路一:用CLI+Skills替代MCP
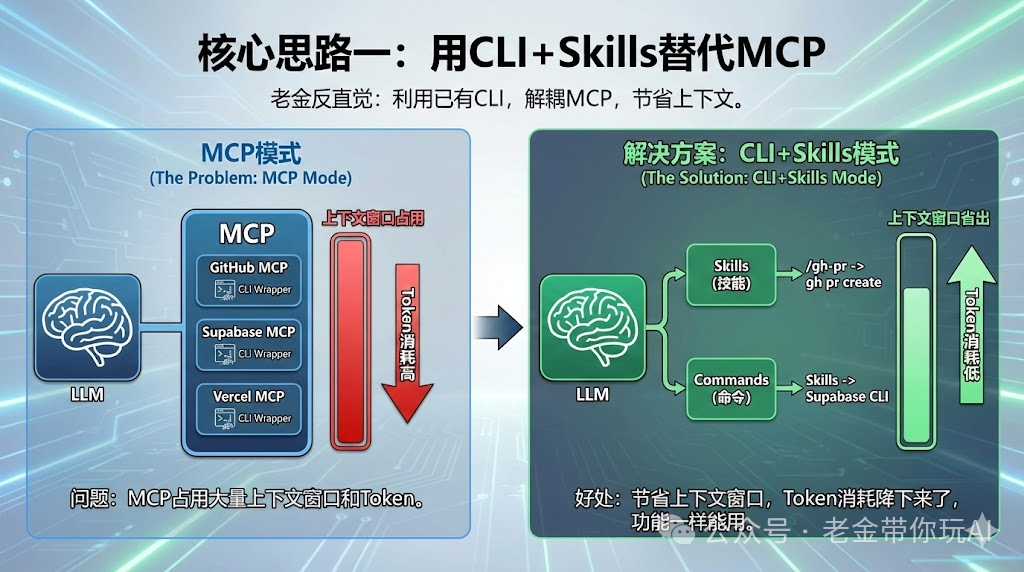
这是老金我觉得最反直觉的部分。
作者说,很多MCP其实是可以替代的。
比如GitHub MCP、Supabase MCP、Vercel MCP。
这些平台本身就有很强的CLI,MCP只是在外面包了一层。
问题是什么?
MCP会占用上下文窗口,会消耗更多token。
作者的解决方案
把MCP的功能拆成Skills和Commands。
比如不用GitHub MCP,而是创建一个 /gh-pr命令,直接调用 gh pr create。
不用Supabase MCP,而是创建Skills直接调用Supabase CLI。
这样做的好处
上下文窗口省出来了。
Token消耗降下来了。
功能一样能用。
老金我试了一下,确实有效。
把几个不常用的MCP换成CLI+Skills后,token消耗降了不少。
核心思路二:Agent顺序阶段编排
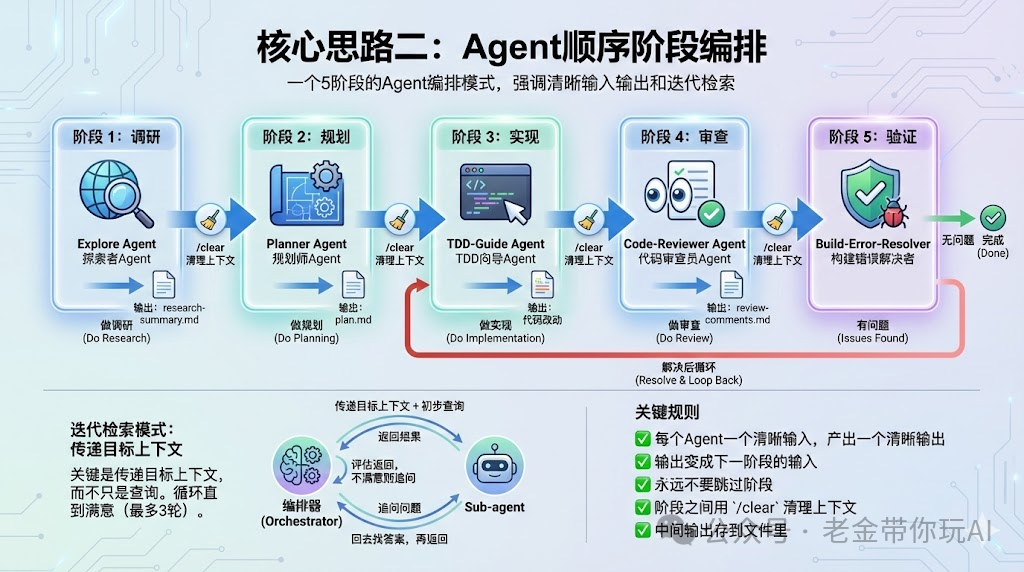
这是老金我觉得最值得学习的部分。
作者提出了一个5阶段的Agent编排模式。
Phase 1: RESEARCH
用Explore agent做调研,输出research-summary.md。
Phase 2: PLAN
用planner agent做规划,输出plan.md。
Phase 3: IMPLEMENT
用tdd-guide agent做实现,输出代码改动。
Phase 4: REVIEW
用code-reviewer agent做审查,输出review-comments.md。
Phase 5: VERIFY
如果有问题,用build-error-resolver解决,然后循环回去。
关键规则
每个Agent只有一个清晰的输入,产出一个清晰的输出。
输出变成下一阶段的输入。
永远不要跳过阶段。
阶段之间用 /clear清理上下文。
中间输出存到文件里。
为什么这样做?
Sub-agent有个问题:它只知道字面查询,不知道背后的目的。
所以需要迭代检索模式。
编排器评估每个sub-agent的返回。
在接受之前先问follow-up问题。
Sub-agent回去找答案,再返回。
循环直到满意,最多3轮。
关键是传递目标上下文,而不只是查询。
核心思路三:Token优化策略
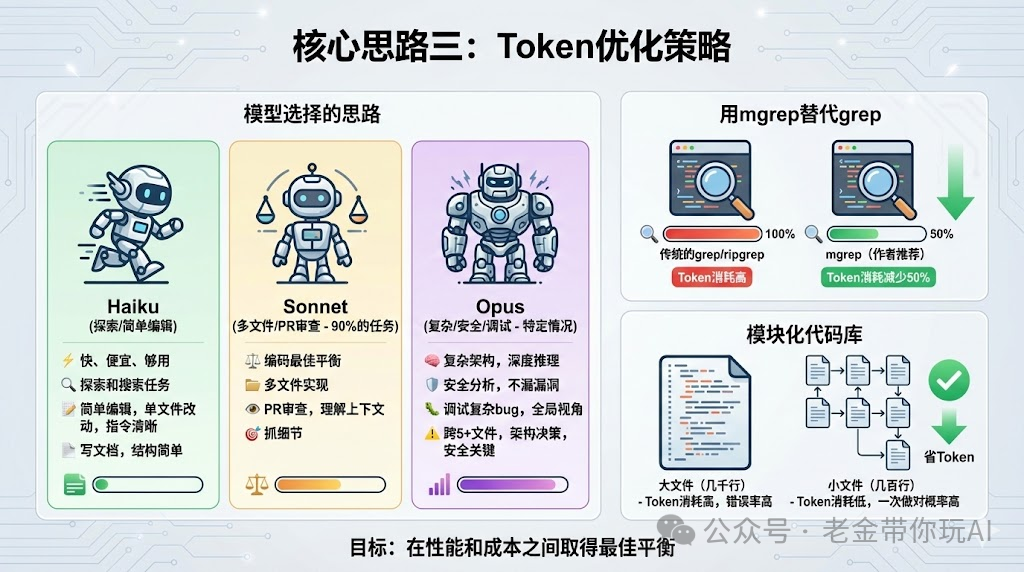
用Claude Code最头疼的就是token消耗。
作者给了一套完整的优化方案。
模型选择的思路
作者的建议是:90%的编码任务用Sonnet。
只有在特定情况下才升级到Opus。
什么情况用Haiku?
探索和搜索任务,快、便宜、够用。
简单编辑,单文件改动,指令清晰。
写文档,结构简单。
什么情况用Sonnet?
多文件实现,编码最佳平衡。
PR审查,理解上下文,抓细节。
什么情况用Opus?
复杂架构,需要深度推理。
安全分析,不能漏掉漏洞。
调试复杂bug,需要全局视角。
第一次尝试失败、任务跨5个以上文件、涉及架构决策、或者安全关键代码。
用mgrep替代grep
作者推荐用mgrep替代传统的grep或ripgrep。
根据他的测试,token消耗平均减少50%。
模块化代码库
作者强调,把主文件控制在几百行而不是几千行。
这样不仅省token,而且任务一次做对的概率更高。
核心思路四:验证循环
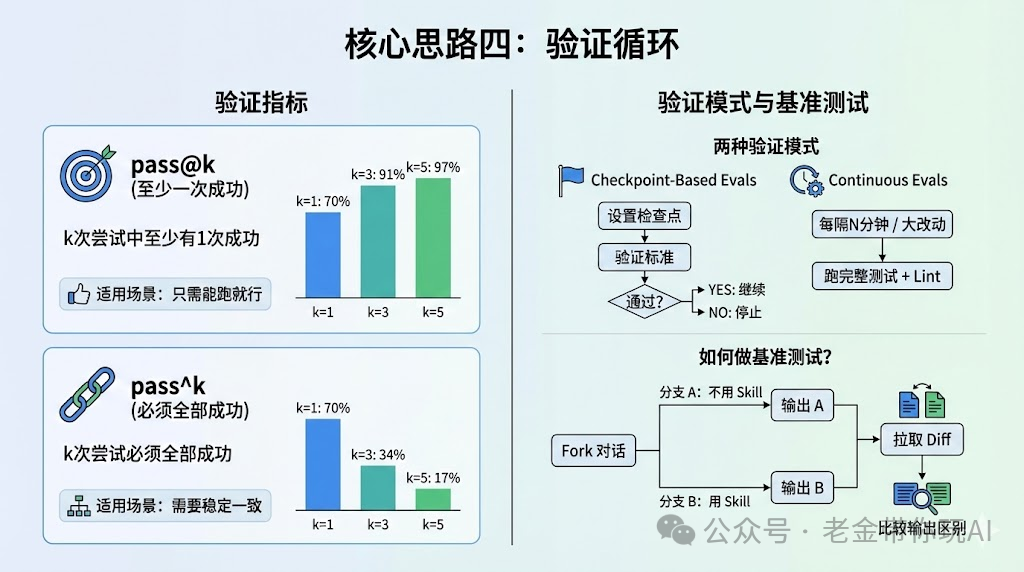
作者在指南里提到了两个重要指标。
pass@k
k次尝试中至少有1次成功。
k=1时70%,k=3时91%,k=5时97%。
pass^k
k次尝试必须全部成功。
k=1时70%,k=3时34%,k=5时17%。
什么时候用哪个?
如果只需要能跑就行,用pass@k。
如果需要稳定一致,用pass^k。
两种验证模式
Checkpoint-Based Evals
设置明确的检查点,验证是否符合标准,不过不继续。
Continuous Evals
每隔N分钟或者大改动后,跑完整测试套件加lint。
怎么做基准测试?
Fork对话,在一个分支里不用Skill,在另一个分支里用Skill。
最后拉个diff,看看输出有什么区别。
核心思路五:并行化策略
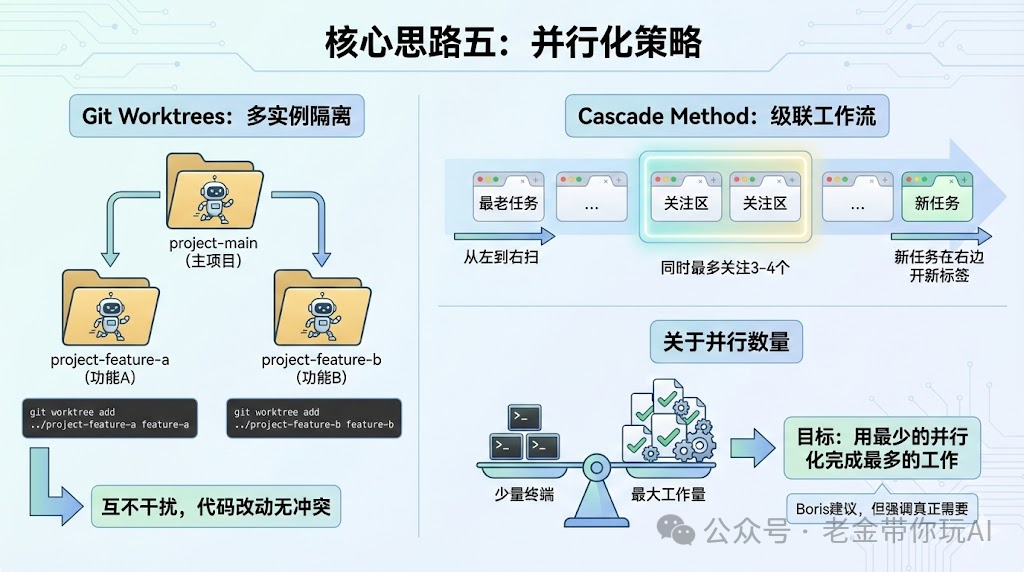
这部分老金我觉得特别实用,和之前老金讲的claude code联合创始人的做法相同。
Git Worktrees
如果你要同时跑多个Claude实例处理不同任务,作者强烈建议用Git Worktrees。
# 创建工作树
git worktree add ../project-feature-a feature-a
git worktree add ../project-feature-b feature-b
# 每个工作树跑一个Claude实例
cd ../project-feature-a && claude这样多个Claude实例不会互相干扰,代码改动也不会冲突。
Cascade Method
作者的并行工作流是这样的:
新任务在右边开新标签页。
从左到右扫,最老的在最左边。
同时最多关注3-4个任务。
关于并行数量
作者引用了Anthropic的Boris的建议,但他自己的观点是:
不要设置任意数量的终端。
增加终端应该是出于真正的需要。
目标是:用最少的并行化完成最多的工作。
核心思路六:Two-Instance Kickoff Pattern
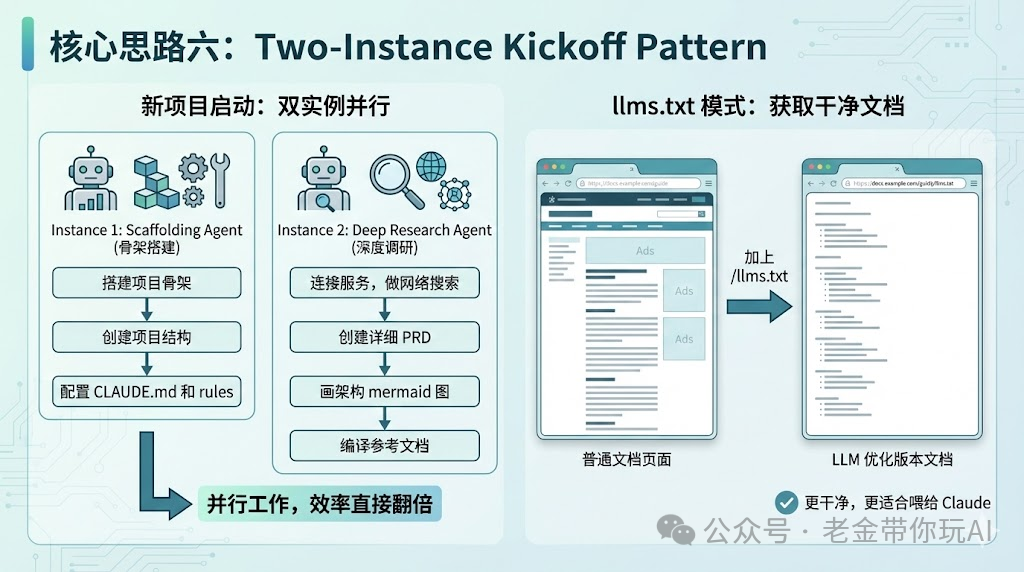
开新项目的时候,作者会开两个Claude实例。
Instance 1: Scaffolding Agent
负责搭建项目骨架。
创建项目结构。
配置CLAUDE.md和rules。
Instance 2: Deep Research Agent
连接各种服务,做网络搜索。
创建详细的PRD。
画架构mermaid图。
编译参考文档。
两个实例并行工作,效率直接翻倍。
llms.txt模式
作者提到一个技巧:很多文档网站有 /llms.txt。
访问文档页面后加上 /llms.txt,就能获得LLM优化版本的文档。
更干净,更适合喂给Claude。
如果对你有帮助,记得关注一波~
核心思路七:记忆持久化
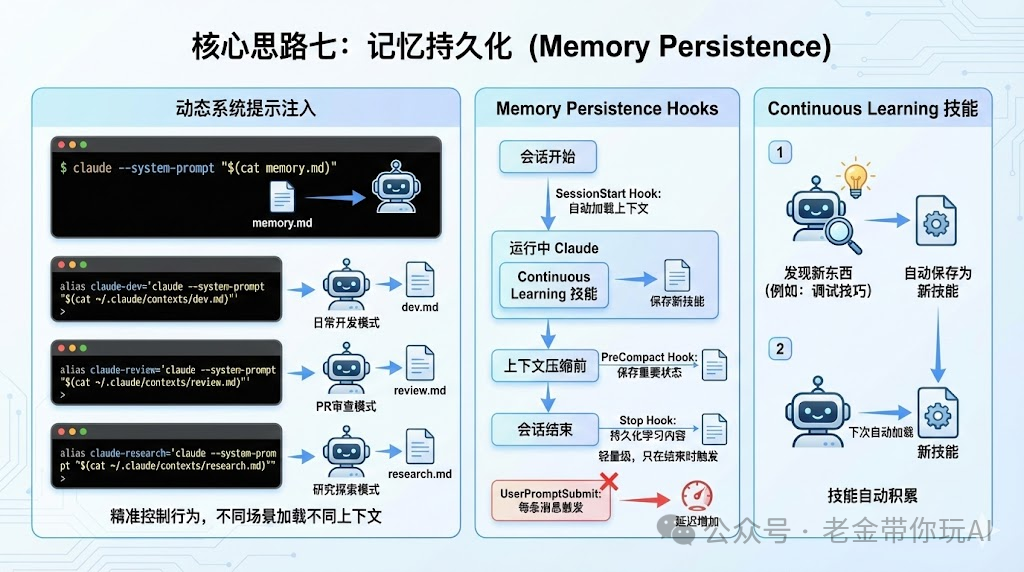
这部分是记忆相关的,但只是整个方法论的一小部分。
动态系统提示注入
作者不是把所有东西都塞进CLAUDE.md,而是用CLI参数动态注入。
claude --system-prompt "$(cat memory.md)"然后他设置了几个alias:
# 日常开发模式
alias claude-dev='claude --system-prompt "$(cat ~/.claude/contexts/dev.md)"'
# PR审查模式
alias claude-review='claude --system-prompt "$(cat ~/.claude/contexts/review.md)"'
# 研究探索模式
alias claude-research='claude --system-prompt "$(cat ~/.claude/contexts/research.md)"'不同场景加载不同上下文,精准控制Claude的行为。
Memory Persistence Hooks
作者搞了一套Memory Persistence Hooks,用三个钩子解决记忆问题。
PreCompact Hook
在上下文压缩之前,自动把重要状态保存到文件。
Stop Hook
会话结束时,自动把学到的东西持久化。
SessionStart Hook
新会话开始时,自动加载之前的上下文。
为什么用Stop Hook而不是UserPromptSubmit?
UserPromptSubmit每条消息都会触发,增加延迟。
Stop只在会话结束时触发一次,轻量级,不会拖慢你。
Continuous Learning技能
当Claude发现了什么新东西,比如一个调试技巧、一个workaround,它会自动保存成新技能。
下次遇到类似问题,技能自动加载。
核心思路八:复合效应哲学
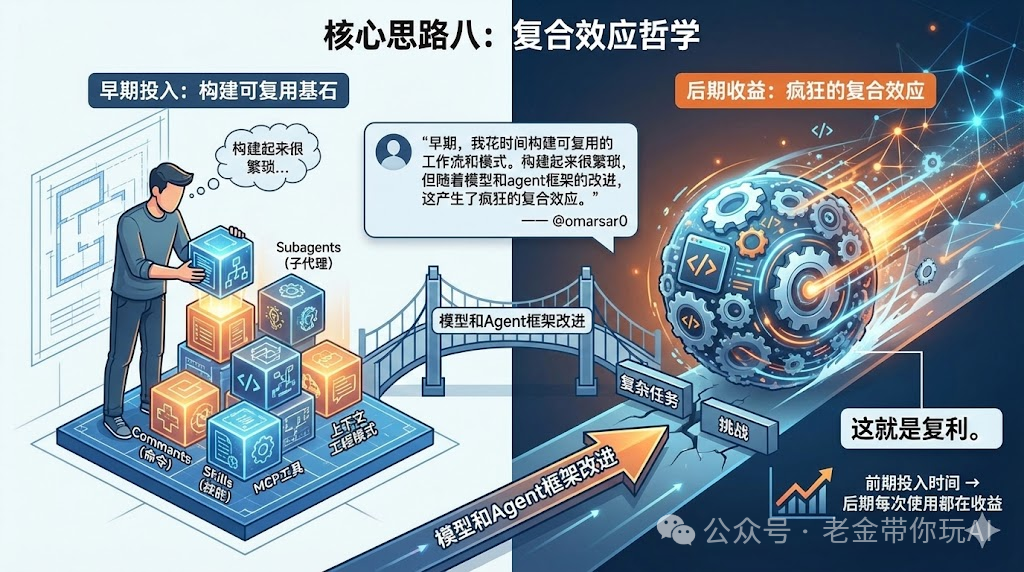
作者引用了@omarsar0的话:
"早期,我花时间构建可复用的工作流和模式。构建起来很繁琐,但随着模型和agent框架的改进,这产生了疯狂的复合效应。"
应该投资什么?
Subagents
Skills
Commands
规划模式
MCP工具
上下文工程模式
这就是复利。
前期投入时间构建可复用的东西。
后期每次使用都在收益。
怎么用?手把手教你
安装有两种方式,老金我推荐用插件方式,2分钟搞定。
方法一:作为插件安装(推荐)
第一步:安装插件
直接在claude code中输入
# 添加市场
/plugin marketplace add affaan-m/everything-claude-code
# 安装插件
/plugin install everything-claude-code@everything-claude-code第二步:安装规则(必需)
⚠️ 重要:插件无法自动分发rules,需要手动安装。
建议在claude全局目录直接进行。
# 首先克隆仓库
git clone https://github.com/affaan-m/everything-claude-code.git
# 复制规则到用户级(应用于所有项目)
cp -r everything-claude-code/rules/* ~/.claude/rules/
# 或者复制到项目级(仅当前项目)
mkdir -p .claude/rules
cp -r everything-claude-code/rules/* .claude/rules/第三步:开始使用
# 尝试一个命令
/plan "添加用户认证"
# 查看可用命令
/plugin list everything-claude-code@everything-claude-code✨ 完成!你现在可以使用15+代理、30+技能和20+命令。
方法二:手动安装(推荐老手)
如果你希望对安装的内容有完全控制:
# 克隆仓库
git clone https://github.com/affaan-m/everything-claude-code.git
# 复制代理
cp everything-claude-code/agents/*.md ~/.claude/agents/
# 复制命令
cp everything-claude-code/commands/*.md ~/.claude/commands/
# 复制技能
cp -r everything-claude-code/skills/* ~/.claude/skills/配置hooks和MCP需要手动编辑settings.json和claude.json,详见仓库README。
目录结构:
everything-claude-code/
|-- .claude-plugin/ # 插件和市场清单
| |-- plugin.json # 插件元数据和组件路径
| |-- marketplace.json # /plugin marketplace add 的市场目录
|
|-- agents/ # 用于委托的专业子代理
| |-- planner.md # 功能实现规划
| |-- architect.md # 系统设计决策
| |-- tdd-guide.md # 测试驱动开发
| |-- code-reviewer.md # 质量和安全审查
| |-- security-reviewer.md # 漏洞分析
| |-- build-error-resolver.md
| |-- e2e-runner.md # Playwright E2E 测试
| |-- refactor-cleaner.md # 死代码清理
| |-- doc-updater.md # 文档同步
| |-- go-reviewer.md # Go 代码审查(新增)
| |-- go-build-resolver.md # Go 构建错误解决(新增)
|
|-- skills/ # 工作流定义和领域知识
| |-- coding-standards/ # 语言最佳实践
| |-- backend-patterns/ # API、数据库、缓存模式
| |-- frontend-patterns/ # React、Next.js 模式
| |-- continuous-learning/ # 从会话中自动提取模式(详细指南)
| |-- continuous-learning-v2/ # 基于直觉的学习与置信度评分
| |-- iterative-retrieval/ # 子代理的渐进式上下文细化
| |-- strategic-compact/ # 手动压缩建议(详细指南)
| |-- tdd-workflow/ # TDD 方法论
| |-- security-review/ # 安全检查清单
| |-- eval-harness/ # 验证循环评估(详细指南)
| |-- verification-loop/ # 持续验证(详细指南)
| |-- golang-patterns/ # Go 惯用语和最佳实践(新增)
| |-- golang-testing/ # Go 测试模式、TDD、基准测试(新增)
|
|-- commands/ # 用于快速执行的斜杠命令
| |-- tdd.md # /tdd - 测试驱动开发
| |-- plan.md # /plan - 实现规划
| |-- e2e.md # /e2e - E2E 测试生成
| |-- code-review.md # /code-review - 质量审查
| |-- build-fix.md # /build-fix - 修复构建错误
| |-- refactor-clean.md # /refactor-clean - 死代码移除
| |-- learn.md # /learn - 会话中提取模式(详细指南)
| |-- checkpoint.md # /checkpoint - 保存验证状态(详细指南)
| |-- verify.md # /verify - 运行验证循环(详细指南)
| |-- setup-pm.md # /setup-pm - 配置包管理器
| |-- go-review.md # /go-review - Go 代码审查(新增)
| |-- go-test.md # /go-test - Go TDD 工作流(新增)
| |-- go-build.md # /go-build - 修复 Go 构建错误(新增)
| |-- skill-create.md # /skill-create - 从 git 历史生成技能(新增)
| |-- instinct-status.md # /instinct-status - 查看学习的直觉(新增)
| |-- instinct-import.md # /instinct-import - 导入直觉(新增)
| |-- instinct-export.md # /instinct-export - 导出直觉(新增)
| |-- evolve.md # /evolve - 将直觉聚类到技能中(新增)
|
|-- rules/ # 始终遵循的指南(复制到 ~/.claude/rules/)
| |-- security.md # 强制性安全检查
| |-- coding-style.md # 不可变性、文件组织
| |-- testing.md # TDD、80% 覆盖率要求
| |-- git-workflow.md # 提交格式、PR 流程
| |-- agents.md # 何时委托给子代理
| |-- performance.md # 模型选择、上下文管理
|
|-- hooks/ # 基于触发器的自动化
| |-- hooks.json # 所有钩子配置(PreToolUse、PostToolUse、Stop 等)
| |-- memory-persistence/ # 会话生命周期钩子(详细指南)
| |-- strategic-compact/ # 压缩建议(详细指南)
|
|-- scripts/ # 跨平台 Node.js 脚本(新增)
| |-- lib/ # 共享工具
| | |-- utils.js # 跨平台文件/路径/系统工具
| | |-- package-manager.js # 包管理器检测和选择
| |-- hooks/ # 钩子实现
| | |-- session-start.js # 会话开始时加载上下文
| | |-- session-end.js # 会话结束时保存状态
| | |-- pre-compact.js # 压缩前状态保存
| | |-- suggest-compact.js # 战略性压缩建议
| | |-- evaluate-session.js # 从会话中提取模式
| |-- setup-package-manager.js # 交互式 PM 设置
|
|-- tests/ # 测试套件(新增)
| |-- lib/ # 库测试
| |-- hooks/ # 钩子测试
| |-- run-all.js # 运行所有测试
|
|-- contexts/ # 动态系统提示注入上下文(详细指南)
| |-- dev.md # 开发模式上下文
| |-- review.md # 代码审查模式上下文
| |-- research.md # 研究/探索模式上下文
|
|-- examples/ # 示例配置和会话
| |-- CLAUDE.md # 示例项目级配置
| |-- user-CLAUDE.md # 示例用户级配置
|
|-- mcp-configs/ # MCP 服务器配置
| |-- mcp-servers.json # GitHub、Supabase、Vercel、Railway 等
|
|-- marketplace.json # 自托管市场配置(用于 /plugin marketplace add)这个仓库有多少东西?

两个新增的生态系统工具
技能创建器
两种方式从你的仓库生成Claude Code技能:
本地分析:用 /skill-create命令
GitHub应用:高级功能、自动PR、团队共享
持续学习v2
基于直觉的学习系统:
/instinct-status - 查看学习的直觉
/instinct-import - 导入他人的直觉
/instinct-export - 导出你的直觉
/evolve - 将相关直觉聚类到技能中
老金我建议先读the-shortform-guide.md,把基础配置搞定。
然后再读the-longform-guide.md,学习进阶技巧。
老金实测效果
老金我用了一周,说说真实感受。
Token消耗降了
按照作者的模型选择建议,简单任务用Haiku,复杂任务才用Opus。
把几个MCP换成CLI+Skills。
老金我统计了一下,token消耗大概降了30%。
开发效率提升
用了Two-Instance Kickoff Pattern开新项目。
以前搭建项目骨架要半天,现在两个小时搞定。
代码质量上去了
有了5阶段Agent编排,很多问题在早期就被发现了。
返工率从30%降到了10%左右。
Context Rot问题缓解了
Memory Persistence Hooks真的有用。
之前20轮就开始"失忆",现在50轮还能记住。
需要注意的地方
有学习成本
这套东西功能很全,但刚上手需要花时间理解。
老金我建议先从Token优化开始,这个见效最快。
需要根据项目调整
作者的配置是通用的,但每个项目情况不同。
比如模型选择、Agent编排,你得根据自己的任务类型调整。
复合效应需要时间
前期投入时间构建Skills、Commands、Agents。
后期才能享受复利。
不要期望立竿见影。
为什么这个仓库能火?
老金我分析了一下,28.8k星不是白来的。
解决真痛点
Token消耗高、Context Rot、效率低,这些是Claude Code用户的普遍问题。
这个仓库提供了一套系统性的解决方案。
实战验证
这不是作者拍脑袋想出来的配置,而是10个月实际使用、不断迭代的结果。
黑客松冠军本身就是最好的背书。
方法论完整
不只是给你配置文件,还告诉你为什么这样做。
从Token优化到Agent编排到复合效应,形成闭环。
文档写得好
作者写了两份指南,shortform和longform。
从入门到进阶,覆盖完整。
老金我读完longform guide,学到了很多之前不知道的技巧。
四种记忆方案怎么选?
老金我之前介绍过3个记忆方案,这里统一对比一下。
方案1:claude-mem(轻量工具)
两行命令安装,自动捕获对话存到本地数据库。
只支持Claude Code,简单省事。
适合只想解决记忆问题、不想折腾的人。
方案2:mcp-memory-service(重量工具)
支持13+个AI客户端,有混合存储、智能分类、团队协作。
功能强大,但配置复杂。
适合跨多个AI工具用、有团队协作需求的人。
方案3:openclaw三层架构(概念性)
知识图谱+每日笔记+隐性知识,是一种记忆设计思路。
适合理解记忆系统的原理,但需要自己实现。
方案4:everything-claude-code(本文介绍)
不只是记忆,是一套完整的Claude Code工作流方法论。
包括Token优化、Agent编排、并行化、验证循环、复合效应。
记忆只是其中一小部分,用Hooks实现。
适合想要系统性提升Claude Code使用效率的人。
怎么选?
只想解决记忆问题,选claude-mem,最简单。
想跨多个AI工具用,选mcp-memory-service,最强大。
想要完整的Claude Code方法论,选everything-claude-code,本文介绍的。
这些方案可以组合使用,不冲突。
前3篇文章地址:
- claude-mem:Claude Code开始失忆了?两大记忆神器帮你选
- mcp-memory-service:烦透了每次给Claude重复背景?手把手教你装这个神器,终极记忆神器
- openclaw三层架构:蹭上150k Star的热点,从clawdbot学会了给AI加自动记忆!
老金建议
如果你每天都在用Claude Code写代码,这个仓库值得花时间研究。
第一步:先读the-shortform-guide.md,把基础配置搞定。
第二步:学习Token优化策略,调整模型选择,用mgrep替代grep。
第三步:尝试5阶段Agent编排,让工作流更系统化。
第四步:把常用的MCP换成CLI+Skills,节省上下文和token。
第五步:投资可复用的模式,享受复合效应。
老金我最近在把这套方法论融合到自己的项目里。
等用一段时间,再给你们写个深度测评。
有问题随时问老金我,一起交流!
往期推荐:
AI编程教程列表
提示词工工程(Prompt Engineering)
LLMOPS(大语言模运维平台)
AI绘画教程列表
WX机器人教程列表
每次我都想提醒一下,这不是凡尔赛,是希望有想法的人勇敢冲。
我不会代码,我英语也不好,但是我做出来了很多东西,在文末的开源知识库可见。
我真心希望能影响更多的人来尝试新的技巧,迎接新的时代。
谢谢你读我的文章。
如果觉得不错,随手点个赞、在看、转发三连吧🙂
如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章。
开源知识库地址:
https://tffyvtlai4.feishu.cn/wiki/OhQ8wqntFihcI1kWVDlcNdpznFf

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)