AReaL 团队开源 ASearcher 项目,解锁搜索智能体领域的最新突破
ASearcher 项目通过完全异步 RL 训练以及高质量的构造数据,让 agent 通过 RL 训练学会复杂的搜索行为,这伴随着工具使用次数以及输出长度的提升。目前 ASearcher 聚焦于 agentic RL 训练,未来仍有多个方向值得继续探究:多工具接入:ASearcher 目前只使用了两个基本的搜索和网页浏览工具,未来可以接入更多的工具进行RL训练,提升 agent 在复杂任务下的性能
AReaL 团队开源 Agentic RL(reinforcement learning,强化学习)方面的开源项目——ASearcher,大规模异步 RL 解锁 Agent 长程工具使用能力。
-
项目地址:https://github.com/inclusionAI/ASearcher
-
论文:https://arxiv.org/abs/2508.07976
在大模型智能体(LLM Agent)的发展中,工具使用正成为解决复杂问题的关键能力。其中,搜索引擎作为连接外部世界的核心工具,其使用效果直接影响 agent 的问题解决深度。要真正驾驭搜索工具,agent 需要学会精准查询,深度探索,动态验证,以及长程策略规划。然而,当前的开源强化学习方案却面临两个根本性挑战:
1. 轮次限制:现有 online RL 训练限制交互轮次(≤10 轮),阻碍 agent 进行深度探索。
2. 数据不足:现有开源 RL 数据规模小、复杂度低,难以激发 agent 的复杂搜索行为。
ASearcher 主要有两项核心贡献:
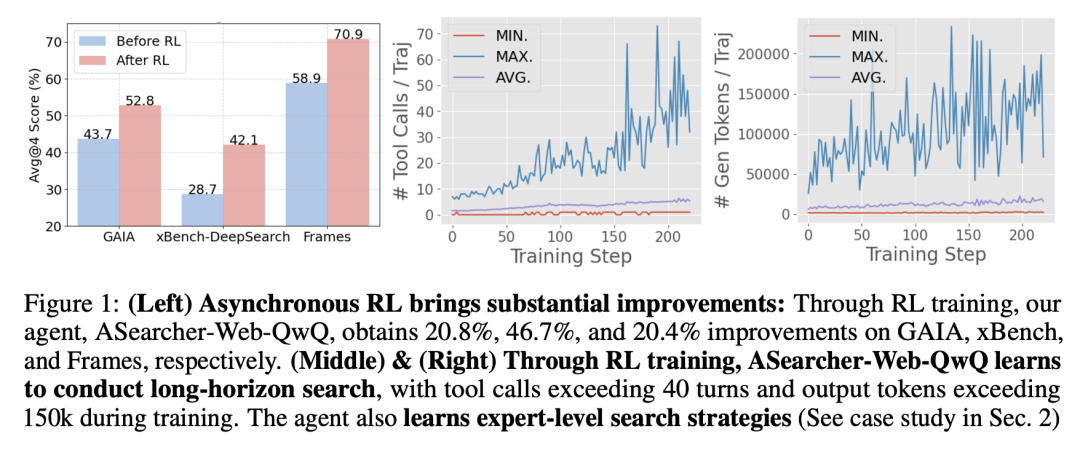
1. 使用完全异步 RL 训练(Fully Async RL)在训练高效的同时让 agent 学会长程工具使用(Long-Horizon Tool Use)。训练过程中,基于 QwQ-32B 的 agent 能够自然地学会更多的工具使用轮次和更多输出 token,在 200 步之后学会高达 40 轮次的 tool use,并且生成 token 达到了 150k+。
2. 我们开源了一个用于构造高质量&高难度数据的 agent。Agent 通过注入外部事实(Fact Injection)以及对题目模糊化(fuzz)来合成问题,同时在每一步合成都进行了非常严格的检验来保证 quality & difficulty 检验。
完全异步 RL 训练+高质量数据的训练效果显著,ASearcher-Web-QwQ 在 GAIA x Bench-DeepSearch 和 Frames 三个高难度 benchmark 上分别得到了 +20.8%,+46.7%,+20.4% 的提升。同时,我们进行了细致的 case study,发现 agent 学会了人类专家级别的搜索策略(如跨文档对比推理,主动检验结论等等)。
在使用了单 agent 并且不借助任何外部 LLM 的情况下,ASearcher-Web-QwQ 实现了非常不错的效果,超越了一系列纯开源模型方案。
ASearcher
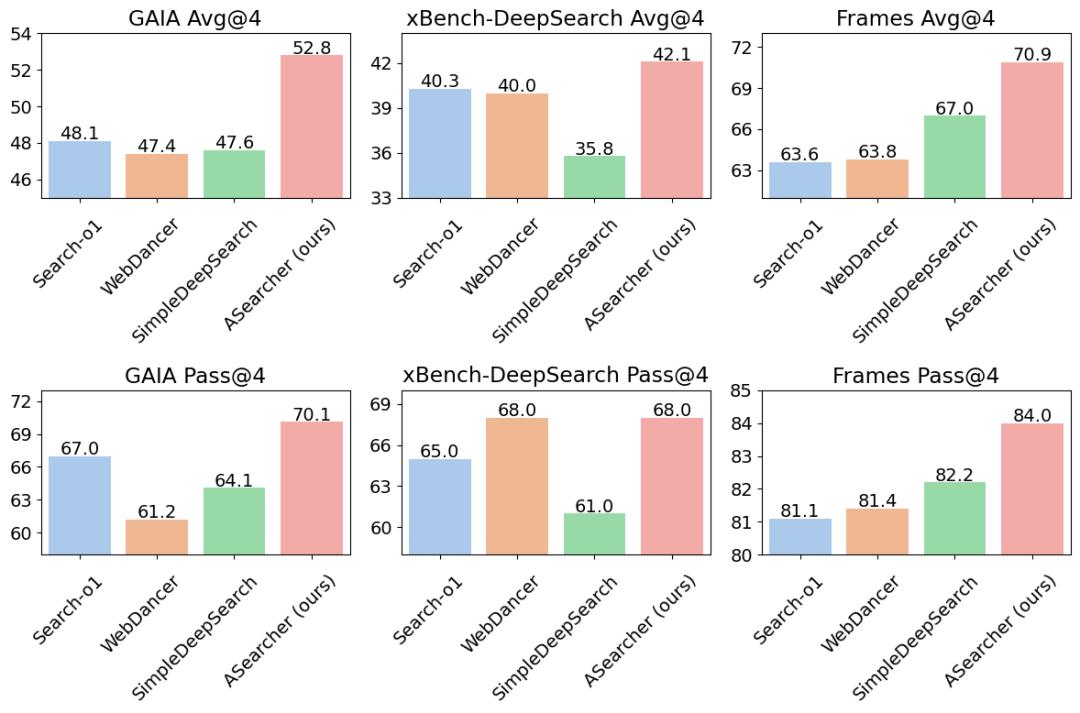
在 ASearcher 中,我们关注的核心问题是:如何使用 Online RL 有效的激发 LLM agent 使用工具解决复杂问题的能力?
ASearcher 采用 single agent design,其中 agent 可以使用基本的 search&browsing 两种工具,并且不借助任何外部 LLM。值得注意的是,我们不仅仅是让 agent 进行分析,也让 agent 对网页内容进行总结。在 RL 训练中,reasoning 和 summarization 两种能力都是使用端到端训练进行优化的。
长程工具使用(Long-Horizon Tool Use)
在介绍 ASearcher 具体是怎么做的之前,有两个概念需要理清:
1. 什么是“复杂问题”?这里指的是涉及多个网页,具有高度不确定性,且 agent 需要进行多轮工具调用才能做对的问题。
2. 我们期望看到什么样的能力?举个简单的例子,比如提问“中国在某年奥运会的最后奖牌数量”,由于药检奖牌递补一类的原因,网络上实际上有几种不同的答案。一个 expert-level agent 应该能够辨别不同的信息,仔细分析导致有冲突答案的原因,最终到定位正确的答案。
为什么长程工具使用很重要? 因为面对复杂问题,agent 需要更多的工具调用轮次来动态地进行深度探索,获取大量信息,以及进行反复确认。
下面看一个更复杂的例子,其中包括 4 个不同的未知信息,只有找全这些未知信息才能确定最后的答案。

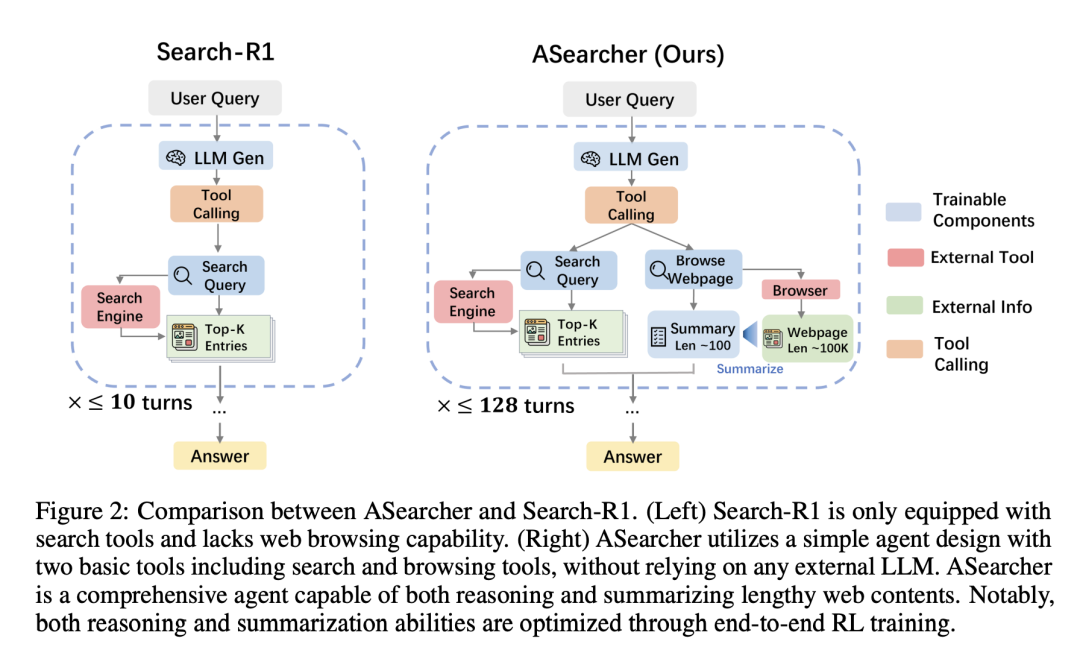
首先,我们分析了轮数限制比较小的 online RL+ 开源数据训练出的 agent(Search-R1-32B):
-
无法有效拆解问题,直接把含有 3 个未知信息的查询输入给搜索引擎
-
幻觉(Hallucination)严重,模型会生成出搜索结果里没看到的信息
-
实际执行轮次很少,没法对错误结论进行有效验证
另外,我们也分析了一个基于 QwQ-32B 的 pompt-based agent (Search-o1(QwQ)):
-
Search-o1 每次搜索后会使用外部LLM分析搜索结果中每个网页的内容,通过大量网页浏览可以成功确定题目中的中间信息
-
然而,Search-o1 在提取网页信息时有丢失关键信息的风险,导致错误的结果
-
最后,在给出最后结论前没有进行更进一步的搜索来确定结论正确性,导致最终只能给出错误的结论。
最后,通过完全异步 RL+ 构造数据,ASearcher-Web-QwQ 学会了:
-
Uncertainty-Aware Analysis: agent 在浏览网页时会记录下所有可能的答案并且进行详细的分析
-
Cross-Document Inference:在没有找到直接指向答案的信息时,会对比不同文档中的相关信息进行合理推断
-
Grounded Verification: 在找到正确答案后,agent 没有立刻返回结果,而是进行了多轮的工具调用来确认题目中的所有信息,保证答案正确性。
数据构造 Agent(Data Synthesis Agent)
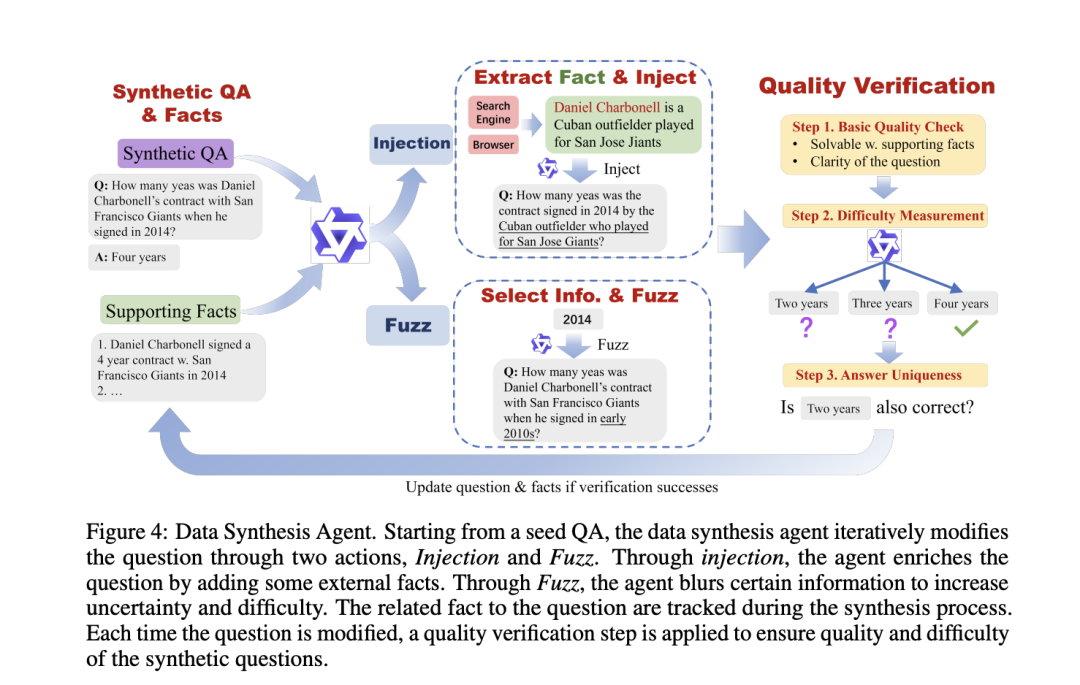
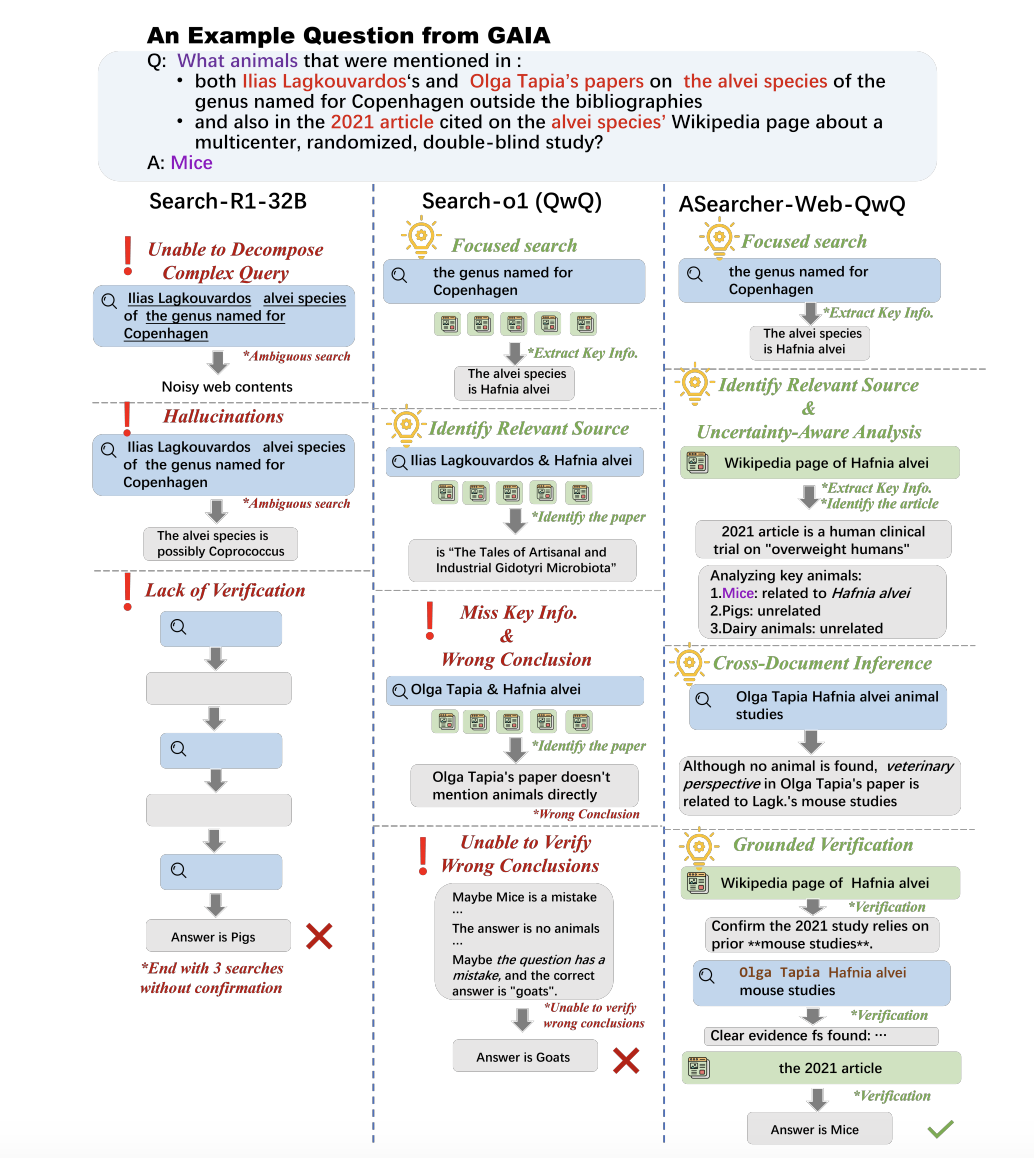
为了能够自动化的构造大规模的有难度的数据,我们开发了一个数据构造 agent。从一个基本的 QA pair 出发,agent 每次会从两个 action 中选择一个来进行问题增强:
1. 事实注入(Injection):agent 使用工具获取到外部相关信息,并且把信息注入到题面中,使题目信息更加复杂。
2. 题面模糊化(Fuzz):选取题目中的一些关键信息并且把信息进行模糊化处理,从而增加题目不确定程度。
在合成问题的过程中,所有 Injection 操作注入的事实都会保存在一个列表内保证所用到的信息都可以溯源。在每次修改题目后,使用一个严格的质量检测过程来保证合成问题的质量,其中包括检验问题的基本层面(如问题是否可以通过保存的事实解出来),使用模型直接生成答案来衡量问题难度,以及判断答案唯一性。
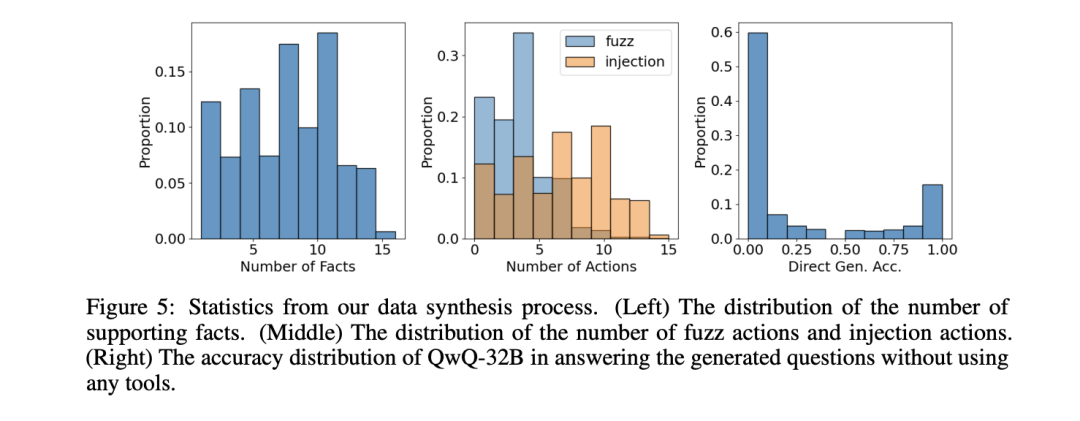
我们在 Wikipedia 2018 corpus 上面进行了数据合成,并且挑选了模型在不使用工具的情况下无法做对的题目用来训练,最后得到了 25.6k 高质量的构造数据作为 RL 训练数据。
完全异步 RL(Fully Async RL)
在设定更大的轮数限制时,我们采用了完全异步 RL训练(Fully Async RL),大大提升了训练效率。
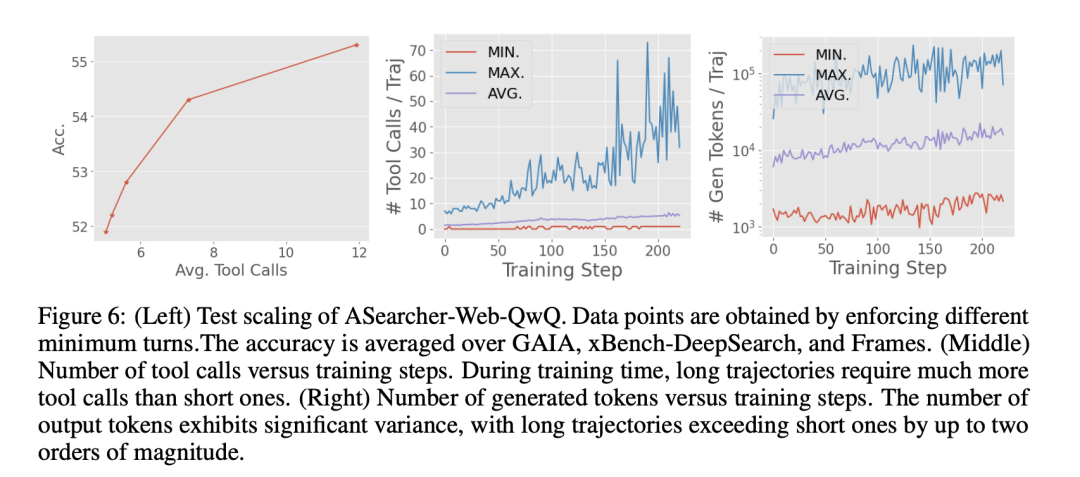
上图可以看到,在实际训练过程中,随着训练过程进行,agent 学会进行更多轮次的工具使用,每个 trajectory 的总输出 token 数也会上升,但同时,工具调用次数和输出 token 数量的方差也在逐渐增大,这意味着,实际生成的轨迹耗时方差巨大,有的很快有的很慢。
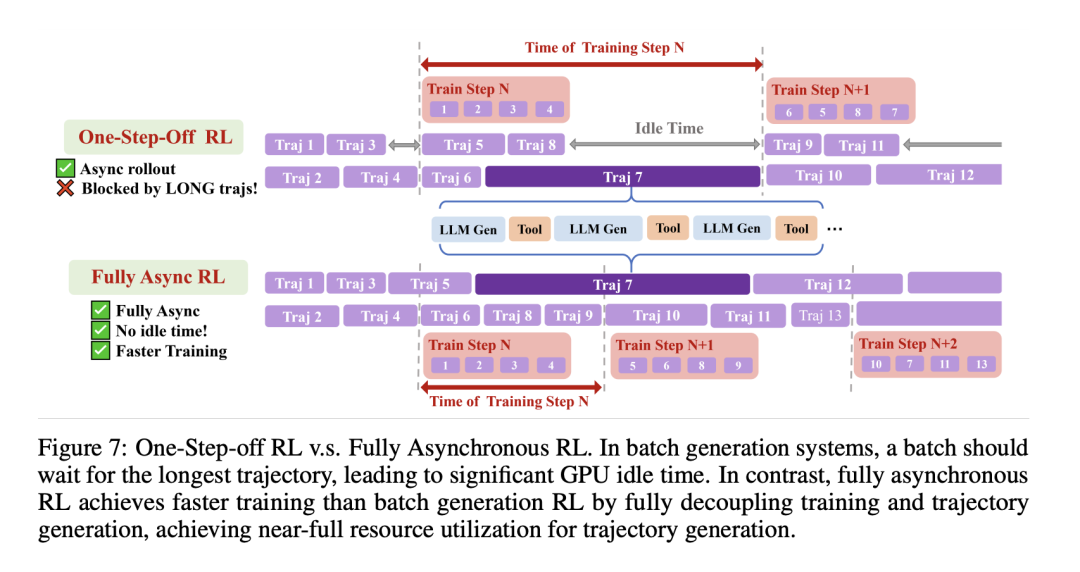
此前工作如 Search-R1 采用的是 batch generation RL 系统,在这类系统中,一个批次的轨迹会同时被采集,等该批次数据采集完之后才会进行 RL 训练。下图中 One-Step-Off RL 也是一种目前最先进的 batch generation RL 系统之一,采用了相邻训练推理步重叠的方式,提高 GPU 利用率。然而,即使在 One-Step-Off RL 系统中,过长的轨迹仍会使整个批次陷入长时间的等待,造成大量的 idle time 以及 GPU 低利用率。
于是我们使用了基于 AReaL 的完全异步 RL 训练系统。如图所示,完全异步 RL 训练中,所有轨迹的采集是并行进行的,在采集数据时不需要等待一个 batch 的轨迹收集完再进行训练,于是避免了由于长轨迹带来的等待时间。这使得完全异步 RL 可以在生成部分达到近乎满 GPU 利用率。
实验结果
我们在三类 Benchmark 上验证了训练 pipeline:
1. Single-Hop QA 任务: Natural Question, TriviaQA, and PopQA
2. Multi-Hop QA 任务: HotpotQA, 2WikiMultiHopQA, MuSiQue, and Bamboogle.
3. 深度搜索任务:包括GAIA, xBench-DeepSearch,和Frames
使用了两种训练设定:
1. 从 Qwen2.5-7B/14B base 直接开始训练:分别进行两类工具的实验,包括使用本地知识库的 RAG 作为搜索工具,以及使用在线搜索工具
2. 对一个基于 QwQ-32B 的 prompt-based LLM agent 进行微调:在该训练设定下,我们只使用在线搜索工具
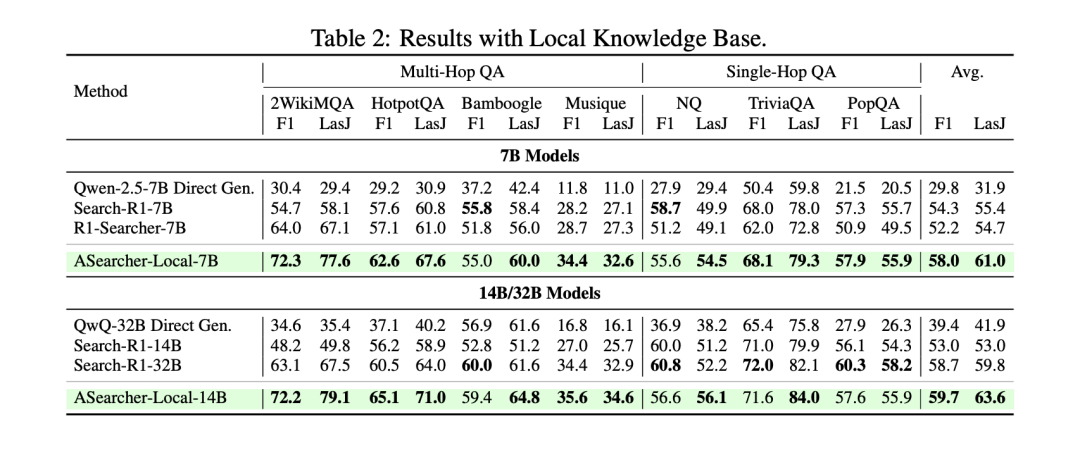
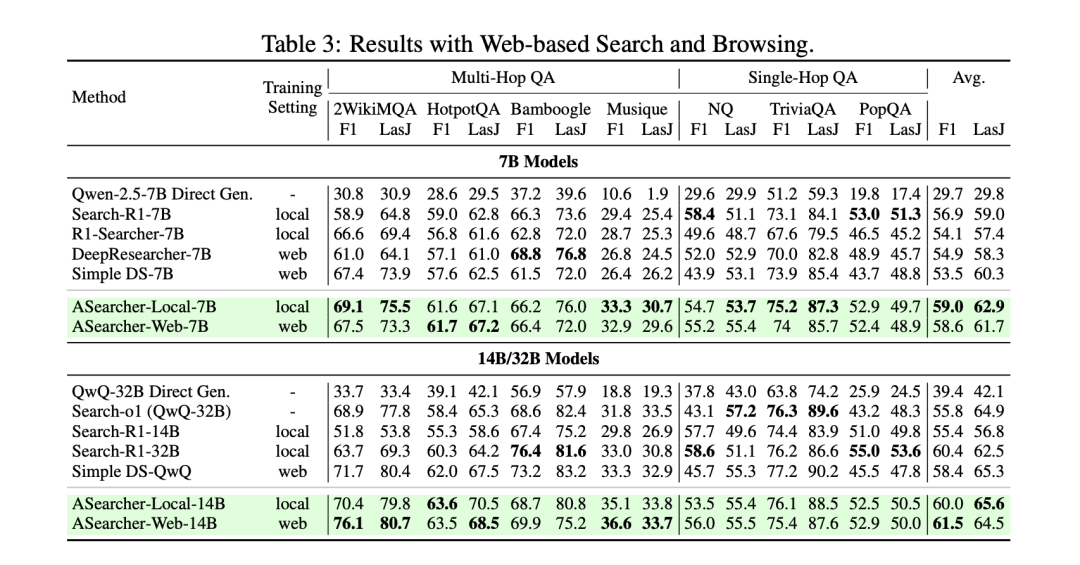
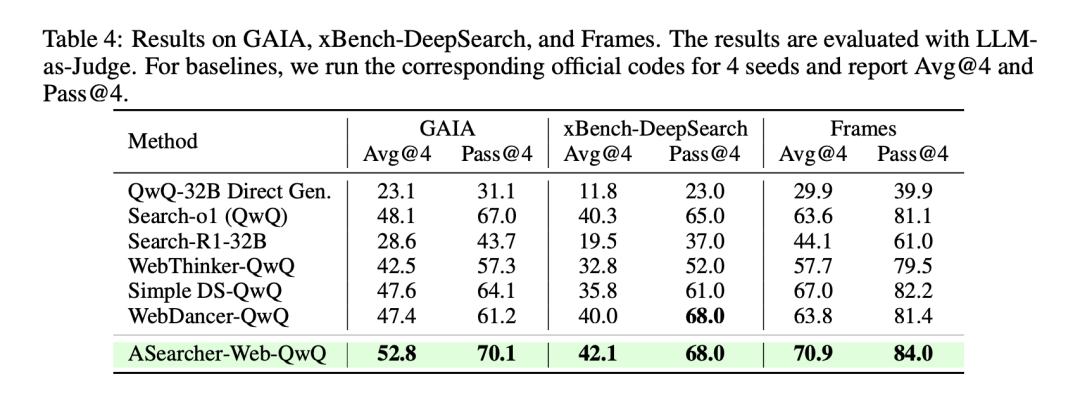
实验结果显示:
-
ASearcher-Local/Web-7B/14B 在 Single-Hop 和 Multi-Hop QA 任务中取得非常好的效果,其中 ASearcher 在 14B 尺度上可以达到甚至超越 32B 模型。
-
基于 QwQ-32B 训练的 ASearcher-Web-QwQ 也比此前的开源方案训练得到的 agent 在深度搜索任务上展现出更强的性能。
-
在 Pass@4 指标上,ASearcher-Web-QwQ 可以在 GAIA/xBench-DeepSearch/Frames 上达到 70.1/68.0/84.0
Why ASearcher?
写在最后,和大家分享我们为什么要做 ASearcher 以及为什么觉得 ASearcher 非常重要。
在今年 6 月份,AReaL 团队发布了 AReaL-boba^2,第一个采用完全异步的 RL 训练系统,在非常具有挑战性的 LiveCodeBench/Codeforces 等 coding benchmark 上基于 Qwen3-8B/14B 做了实验验证,同期也发布了 AReaL 异步系统的论文,表明异步系统可以在成倍提速的情况下无损地进行RL训练。
其实 AReaL 的异步 RL 系统在设计之初就是为了 agent 设计的。在 LLM agent 大规模地火起来之前,我们团队就一直在各种游戏上做大规模并行的 RL agent 训练(这里指基于 mlp/rnn policy 的 agent,当时还没做 LLM 训练),当时发现最大的问题是在于环境会有各种奇怪的问题,比如游戏引擎帧率太低效果很差或者连接超时会断掉导致轨迹无法使用。我们深刻地理解到,要让 agent 应用在真实的场景里,大规模的异步 RL 会起到关键性作用。
在 AReaL-boba^2 发布之后,异步 RL 系统基本 ready,我们开始找更适合验证异步 RL 训练的场景。当时 Search task 上开始有一系列工作出现,如 WebSailor, Search-R1,R1-Searcher, WebThinker,我们觉得还是有一些做的不太够的地方:
1. 之前的 online RL 方法通常会设置非常小的轮数限制(e.g. <=10 per traj),然而,过小的轮数限制会大幅限制 agent 学习工具使用(Tool Use),特别是在困难任务上,agent 几乎不太可能去探索出一个正确的解题路径。然而现有 RL 框架训练中使用更大的轮数限制容易因为等待最慢的 trajectory 而训得很慢。
2. 在 fine-tune 比较复杂的 LLM-based Agent 时,通常都是采用 offline RL 的方法,比如WebThinker,SimpleDeepSearcher,其实大家还缺少一个真正能够对复杂的 prompt-based LLM Agent 进行有效 online RL 训练的开源框架。
3. 缺少大量的能够有效激发 agent tool use 能力的训练数据。之前的一些工作通常采用一些比较旧的开源数据(e.g. HotpotQA),或者是只开源了相当小一部分训练数据(100~1k左右)。
那么, 基于这些观察,我们开始了一个多月的在 search agent 上的尝试,最后也是成功的对一个基于 QwQ-32B 的 promt-based agent 进行了有效的 online RL 训练,并且观察到复杂搜索行为的出现。
ASearcher 意味着什么?
-
一个支持 long-horizon tool use 的 online RL 开源训练框架。要让 tool-use agent 真正的能够处理复杂任务,RL 框架需要做到在训练时就支持足够大的轮数限制,让 agent 可以进行更多的自由探索。
-
结果表明,高质量的训练数据可以由 tool-use agent 构造。当然,这需要搭配严格的质量检测,保证数据真实性和可靠性。我们也期望看到未来更多这方面的尝试,在 problem-solving agent 越来越强的同时,也希望能够看到能自动提供高质量训练数据的 problem-synthesis agent,实现真正的 AI agent 自动进化。
总结与展望
ASearcher 项目通过完全异步 RL 训练以及高质量的构造数据,让 agent 通过 RL 训练学会复杂的搜索行为,这伴随着工具使用次数以及输出长度的提升。目前 ASearcher 聚焦于 agentic RL 训练,未来仍有多个方向值得继续探究:
-
多工具接入:ASearcher 目前只使用了两个基本的搜索和网页浏览工具,未来可以接入更多的工具进行RL训练,提升 agent 在复杂任务下的性能。
-
更先进的 agent 设计:ASearcher 采用了 single agent 设计,即可通过 RL 训练在深度搜索任务上达到了相当不错的性能。未来随着需要解决的任务更加复杂,可以探索更适用于 RL 训练的 agent 设计,在保持训练效率的情况下最大化 agent RL 训练效果。
-
数据构造 Agent:ASearcher 中采用了 prompt-based LLM agent 来构造数据,未来可以探索更加通用的数据构造 agent,可以高效地构造出更通用以及更具有挑战性的问题来进行 agentic RL 训练。
这几个月也有非常多很棒的 search agent 方面的工作出现,包括通义的 WebAgent 系列(WebSailor/WebShaper),以及最近 ARPO、MiroMindAI 的工作,都从算法、数据、工具等不同维度进行了有效的探索。希望 ASearcher 可以为未来 agentic RL 工作提供一些有价值的 insight,也欢迎大家来基于 AReaL fully async RL 高效率地训练自己的 LLM/VLM agent!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)