C++ 内存避坑指南:如何用移动语义和智能指针解决“深拷贝”与“内存泄漏”
本文深度剖析了 C++ 与 Java 在内存管理上的本质差异。从函数传参的“值语义”陷阱切入,详细阐述了 C++ 为何默认进行深拷贝及其性能代价。文章重点讲解了核心机制 RAII 如何替代 GC 实现确定的资源管理,通过图解“移动语义”与“右值引用”揭示了高性能零拷贝的奥秘,并系统介绍了 unique_ptr 等智能指针的最佳实践与循环引用避坑指南,帮助开发者重塑内存思维模型。
1. 函数传参
在 Java 中,当我们把一个「对象」传给函数时,其实不需要思考太多:传过去的是引用的拷贝,函数里修改的对象的内容也会反应到外面。
但在 C++ 中情况可能不太一样,一般来说我们有三个选择:
1.1. 值传递 (Pass-by-Value):默认的「深拷贝」
这是 C++ 和 Java 最大的直觉冲突点。在 C++ 中,如果没有任何修饰符,编译器会把整个对象完整地克隆一份。 我们看下面的例子:
#include <vector>
#include <iostream>
// 这里会触发 std::vector 的拷贝构造函数
void modify(std::vector<int> v) {
v.push_back(999);
std::cout << "modify内vector的长度为: " << v.size() << std::endl;
// 函数结束,局部变量 v 被销毁,999 也随之消失
// 外部的 list 毫发无损
}
int main() {
// 假设这是一个包含 100 万个元素的列表
std::vector<int> bigList(1000000, 1);
// 调用时发生 Deep Copy,性能开销极大
modify(bigList);
std::cout << "main函数内vector的长度为: " << bigList.size() << std::endl;
return 0;
}
运行结果为:
modify内vector的长度为: 1000001
main函数内vector的长度为: 1000000
对比一下Java代码:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class Main {
// Java 总是按值传递,但对于对象,传递的是“引用的值”
public static void modify(List<Integer> v) {
v.add(999);
System.out.println("modify内List的长度为: " + v.size());
}
public static void main(String[] args) {
// 创建包含 100 万个元素的列表
List<Integer> bigList = new ArrayList<>(Collections.nCopies(1000000, 1));
// 这里传递的是引用,没有深拷贝,性能开销极小
modify(bigList);
// 注意:这里的长度会变成 1000001
System.out.println("main中List的长度为: " + bigList.size());
}
}
运行结果为:
modify内List的长度为: 1000001
main中List的长度为: 1000001
由此我们可以得出以下的结论:
- Java:函数调用时传递的是引用值。Java 永远不会隐式地把整个堆上的大对象复制一遍。
- C++:是“值语义”。函数里的
v是bigList的完全独立副本。你在副本上做的任何修改,都不会影响本体。
1.2. C++的引用传递 (Pass-by-Reference):&
为了既能修改外部对象,又避免昂贵的拷贝,C++ 提供了 引用(Reference)。
在类型后面加一个 &,变量就变成了外部对象的别名(Alias)。我们看下面的代码:
#include <vector>
#include <iostream>
// 引用传递
void modify(std::vector<int>& v) {
v.push_back(999);
// 直接操作内存中的同一份数据
std::cout << "modify内vector的长度为: " << v.size() << std::endl;
}
int main() {
std::vector<int> bigList(1000000, 1);
modify(bigList);
std::cout << "main函数内vector的长度为: " << bigList.size() << std::endl;
return 0;
}
运行结果为:
modify内vector的长度为: 1000001
main函数内vector的长度为: 1000001
特点:
- 零拷贝:无论 List 有多大,这里只传递一个绑定的关系(底层通常是指针实现)。
- 非空保证:引用必须绑定到一个存在的对象上,不存在
null引用。这比 Java 安全。 - 语法透明:在函数内部,你不需要像指针那样解引用,像操作普通变量一样操作它即可。
1.3. 指针传递 (Pass-by-Pointer):经典的“地址”传递 *
这其实是最接近 Java 底层实现的方式。如果需要传递大对象,或者对象可能是空的(nullptr),我们就传递它的内存地址。
#include <vector>
#include <iostream>
// 指针传递
void modify(std::vector<int>* v) {
// 判断是否为空,防止 Crash
if (v != nullptr) {
// 语法变化:用 '->' 来访问成员
v->push_back(999);
std::cout << "modify内vector的长度为: " << v->size() << std::endl;
}
}
int main() {
std::vector<int> bigList(1000000, 1);
// 调用变化:必须显式取出地址 (&) 传进去
modify(&bigList);
std::cout << "main函数内vector的长度为: " << bigList.size() << std::endl;
return 0;
}
运行结果为:
modify内vector的长度为: 1000001
main函数内vector的长度为: 1000001
-
对比 Java:Java 的引用其实就是“受限的指针”。
-
Java:
modify(list)隐式传递了地址。 -
C++:
modify(&list)显式传递了地址。 -
使用场景:通常用于兼容 C 语言接口,或者当参数是“可选的”(可以传
nullptr表示忽略)时。
1.4. 三种方式对比总结
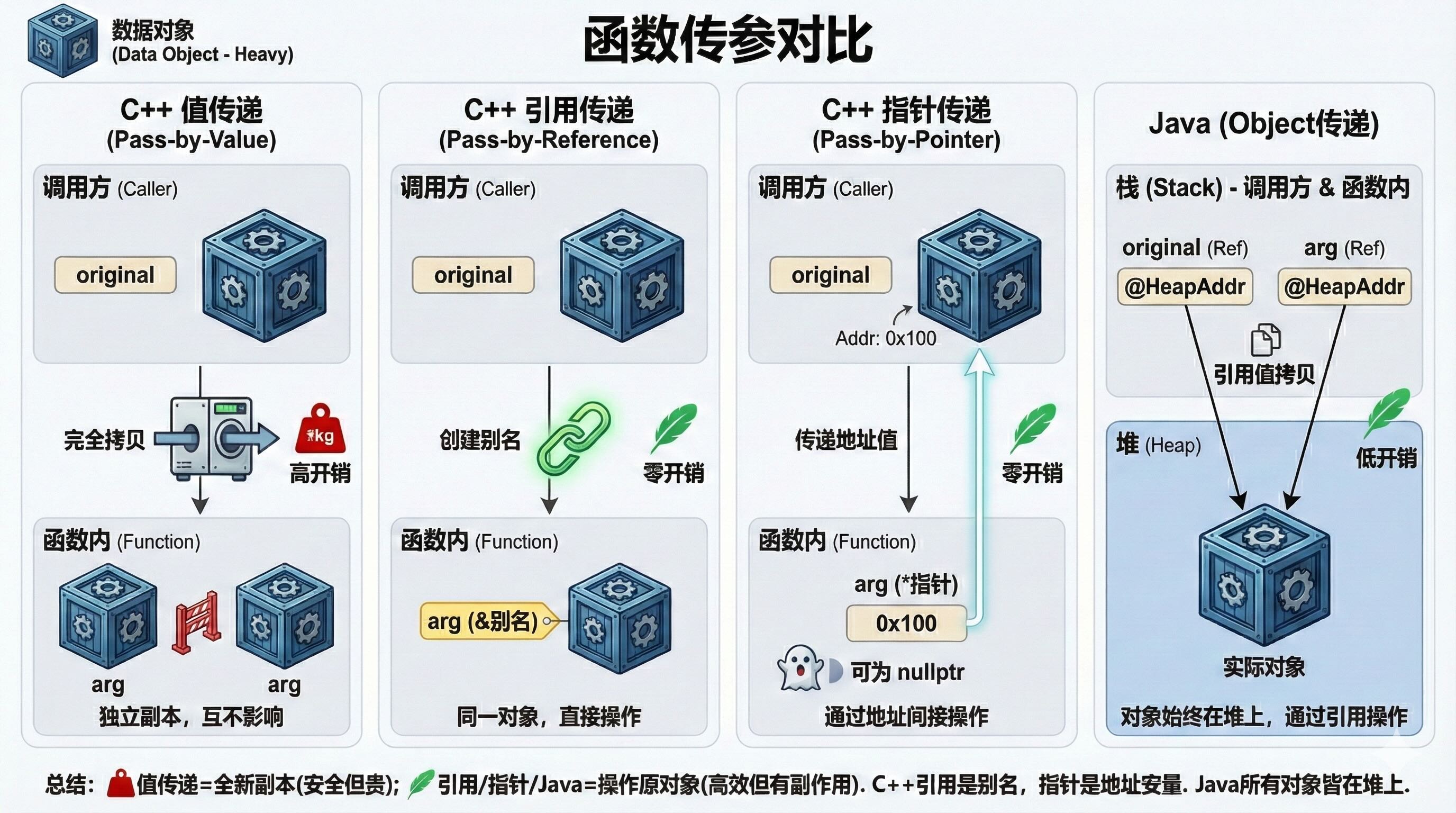
| 特性 | 值传递 (T) | 引用传递 (T&) | 指针传递 (T)* | Java (Object) |
|---|---|---|---|---|
| 内存行为 | 深拷贝 (Deep Copy) | 零拷贝 (别名) | 零拷贝 (传递地址) | 浅拷贝 (复制引用) |
| 修改外部? | ❌ 不能 | ✅ 能 | ✅ 能 | ✅ 能 |
| 能否为 Null | ❌ 不涉及 | ❌ 不能 (必须绑定对象) | ✅ 能 (nullptr) |
✅ 能 |
| 语法复杂度 | 简单 | 简单 | 繁琐 (*, &, ->) |
简单 |
| 适用场景 | int, bool 等小类型 |
首选方案 (非空对象) | 兼容 C | 默认行为 |
2. 对象的生命周期:从手动管理到 RAII 与移动语义
在第一章我们看到:C++ 默认的“值传递”会导致性能问题(深拷贝),而“指针传递”虽然快,但会导致所有权模糊。
这一章我们深入探讨如何既解决安全问题(内存泄漏),又解决性能问题(拷贝开销)。
2.1. 痛点:裸指针带来的“内存泄漏”危机
当我们传递一个指针(或者从函数返回一个指针)时,编译器只负责传递地址。这就带来了一个灵魂拷问:谁负责 delete 这个对象?
看下面这个看似正常的例子:
#include <iostream>
class Enemy {
public:
Enemy() { std::cout << "Enemy Created" << std::endl; }
~Enemy() { std::cout << "Enemy Destroyed" << std::endl; }
void attack() { std::cout << "Enemy attacks!" << std::endl; }
};
// 工厂函数:在堆上创建一个对象,并返回指针
Enemy* createEnemy() {
// 危险的源头:new 出来的内存,必须有人 delete
return new Enemy();
}
void gameLogic() {
// 获取指针
Enemy* boss = createEnemy();
boss->attack();
// 假设这里有一段复杂的逻辑
if (true) {
std::cout << "Player died, game over early." << std::endl;
// 致命问题:函数直接返回了,但 boss 指向的内存没释放!
return;
}
// 只有代码走到这里,内存才会被释放
delete boss;
}
后果:只要你在 delete 之前写了一个 return,或者抛出了一个异常(Exception),这块内存就永远丢了。Java 程序员可能对此毫无感觉 (JVM有GC机制),但在长时间运行的C++服务器程序(如数据库)中,这会导致内存耗尽(OOM)并崩溃。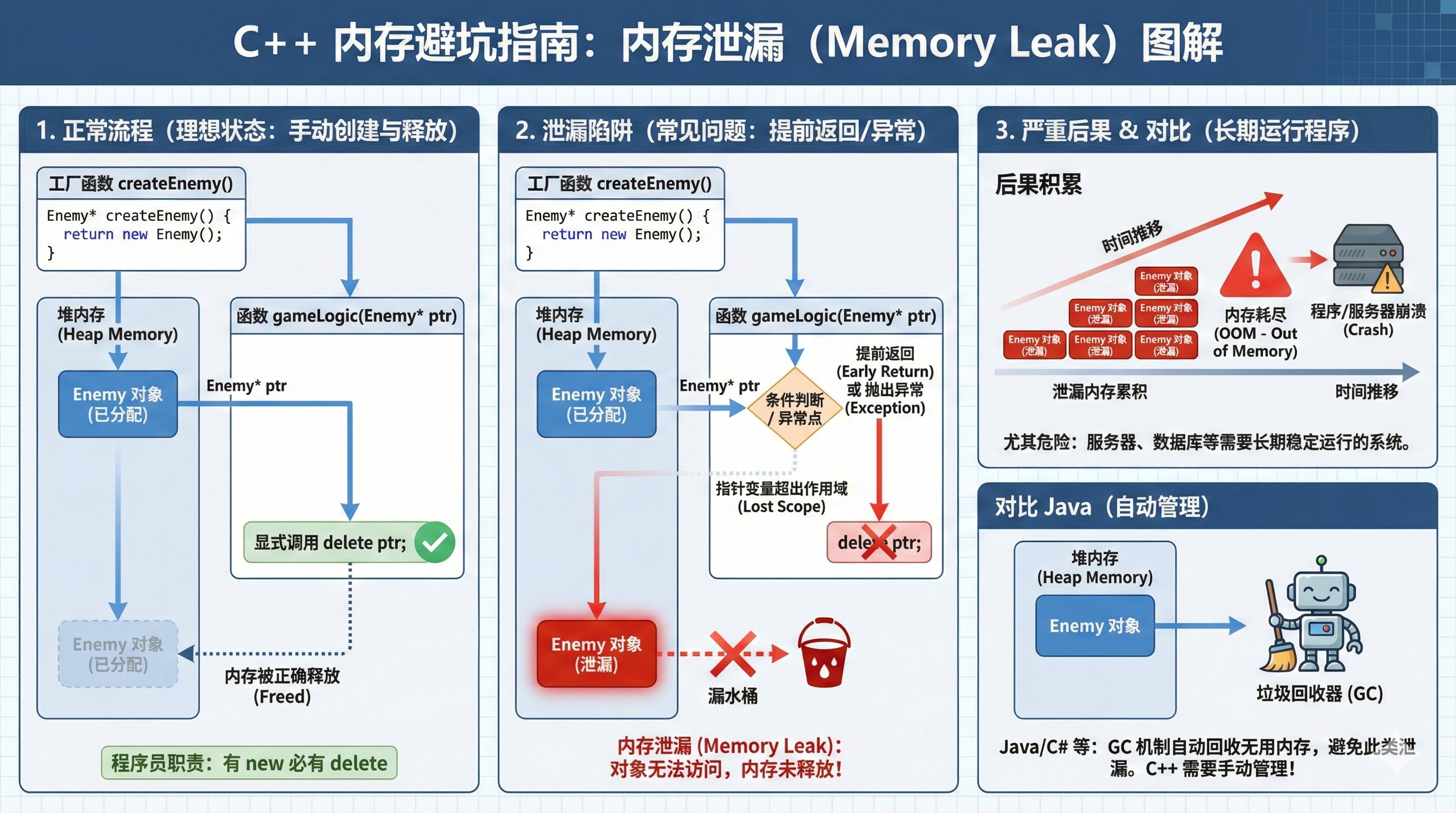
2.2. 解决方案:GC vs. RAII
为了解决这个问题,Java 和 C++ 是走了两条完全不同的路。
2.2.1. Java 的做法:垃圾回收 (GC)
Java 认为:程序员不应该操心内存释放,交给虚拟机(JVM)。
- 机制:JVM 运行后台线程,定期扫描,发现没人引用的对象就回收。
- 代价:不确定性(你不知道它什么时候回收)和 STW (Stop The World)(GC 工作时可能会暂停程序)。
2.2.2. C++ 的做法:RAII (资源获取即初始化)
C++ 认为:性能和确定性第一。我不要后台线程,我要利用“栈”的特性来自动管理堆内存。
RAII (Resource Acquisition Is Initialization) 的核心原理是将堆内存绑定到栈对象上:
- 栈对象的铁律:栈对象(局部变量)一旦离开它的作用域(即大括号
{}结束),编译器一定会自动调用它的析构函数(Destructor)。无论是因为正常执行完、还是中间return了、还是抛异常了,必死无疑。 - RAII 的策略:
- 构造时:在构造函数里
new内存。 - 析构时:在析构函数里
delete内存。
看下面的代码:我们写一个包装类 EnemyWrapper:
#include <iostream>
class Enemy {
public:
Enemy() { std::cout << "Enemy Created" << std::endl; }
~Enemy() { std::cout << "Enemy Destroyed" << std::endl; }
void attack() { std::cout << "Enemy attacks!" << std::endl; }
};
// 工厂函数:在堆上创建一个对象,并返回指针
Enemy* createEnemy() {
// 危险的源头:new 出来的内存,必须有人 delete
return new Enemy();
}
class EnemyWrapper {
private:
// 持有原始指针
Enemy* ptr;
public:
// 【构造函数】:获取资源
EnemyWrapper() {
ptr = new Enemy();
}
// 【析构函数】:释放资源 (这是 RAII 的灵魂)
~EnemyWrapper() {
if (ptr != nullptr) {
delete ptr; // 只要 Wrapper 被销毁,ptr 指向的内存必被释放
std::cout << "Wrapper triggered delete!" << std::endl;
}
}
// 模拟指针操作
void attack() { ptr->attack(); }
};
void gameLogicSafe() {
// 这是一个栈对象
EnemyWrapper boss;
boss.attack();
if (true) {
std::cout << "Game over early." << std::endl;
// 即使这里 return,栈变量 boss 也会弹出
return;
// 编译器自动插入代码:call boss.~EnemyWrapper() -> delete ptr
}
}
int main() {
gameLogicSafe();
return 0;
}
运行结果:
Enemy Created
Enemy attacks!
Game over early.
Enemy Destroyed
Wrapper triggered delete!
结论:不管你怎么写逻辑,内存永远不会泄漏。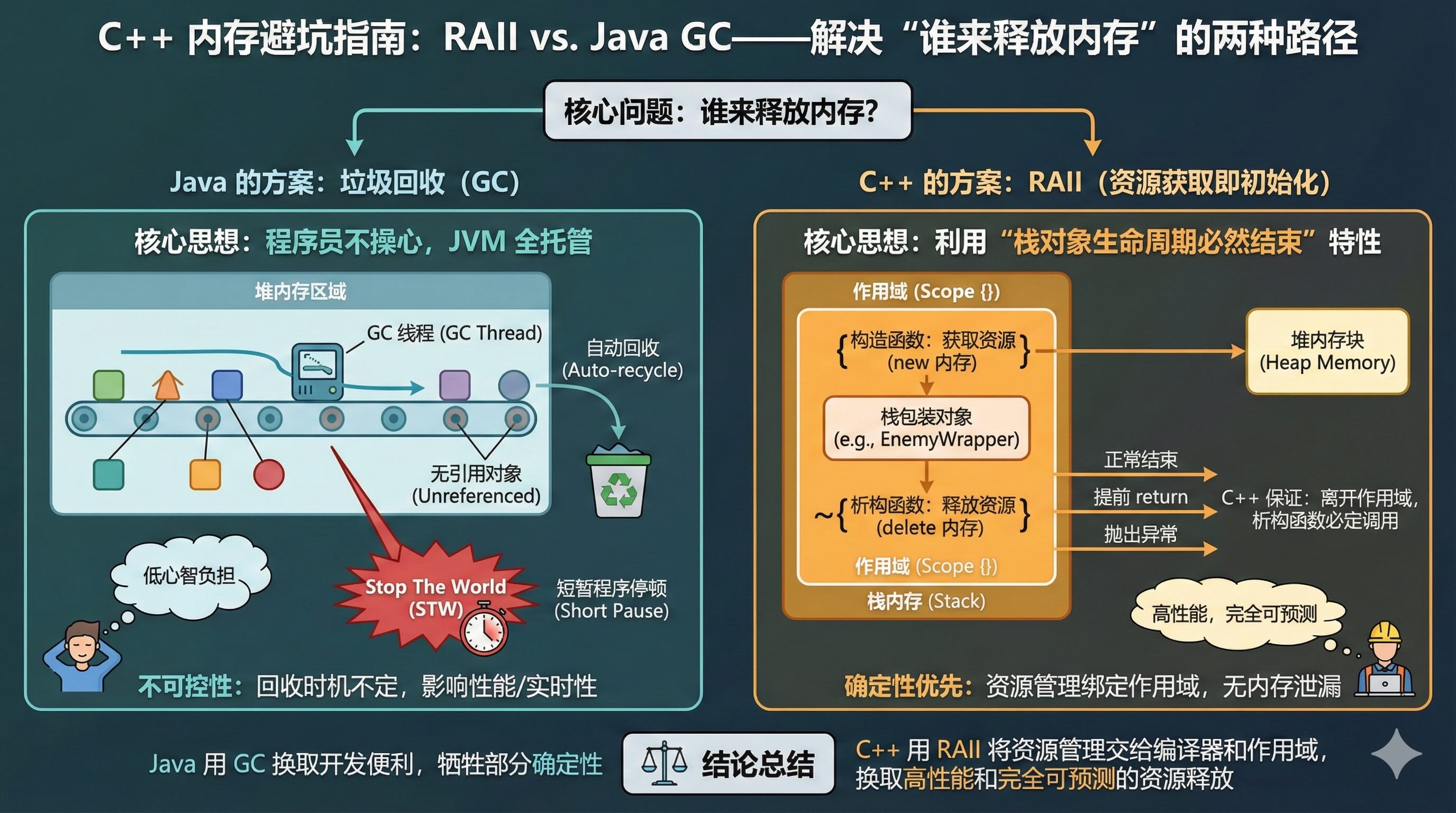
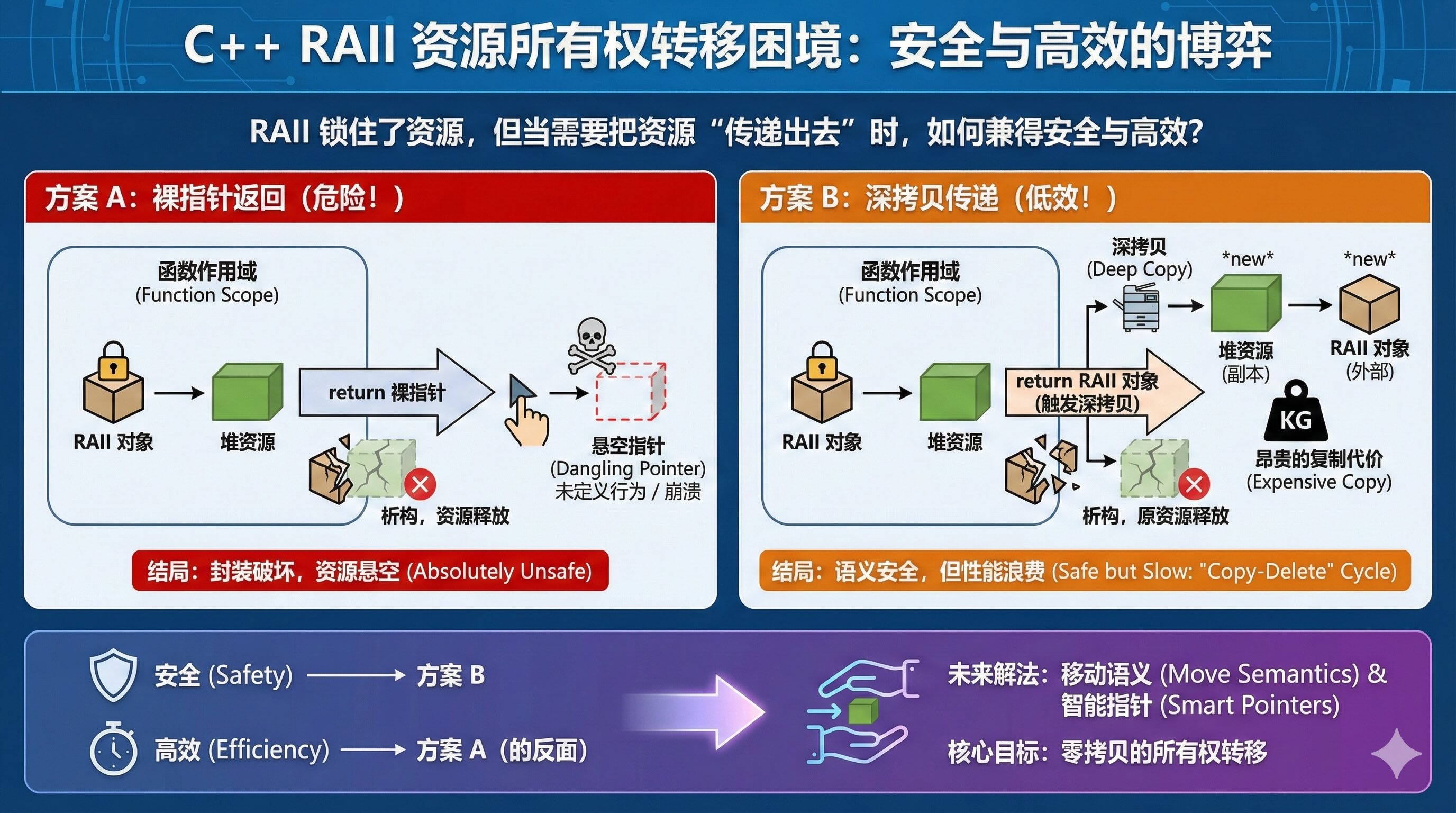
2.3. RAII 的新问题
现在 RAII 解决了内存泄漏问题。但是,当我们想把这个对象传递出去(比如从函数返回)时,就又有问题了:
2.3.1. 方案 A:直接传内部指针(破坏封装,回到解放前)
如果把 RAII 对象里的指针拿出来传递,那就不再受 RAII 保护了。我们看下面的代码:
Enemy* getBoss() {
// 栈对象
EnemyWrapper wrapper;
// 极其危险!
return wrapper.ptr;
} // 函数结束 -> wrapper 析构 -> wrapper.ptr 被 delete
void main() {
Enemy* p = getBoss();
// 崩溃!p 指向的内存已经被 wrapper 删掉了(悬空指针)
p->attack();
}
结论:绝对不能把 RAII 管理的裸指针泄露出去,否则 RAII 就白做了。
2.3.2. 方案 B:拷贝 RAII 对象(安全但极慢)
既然不能传裸指针,那我们只能传 EnemyWrapper 这个对象本身。在 C++11 之前,这意味着深拷贝。我们看下面的代码:
#include <iostream>
// 模拟一个“昂贵”的资源
class Enemy {
public:
Enemy() { std::cout << " [堆资源] Enemy 被 new 出来了 (耗时操作...)" << std::endl; }
~Enemy() { std::cout << " [堆资源] Enemy 被 delete 掉了" << std::endl; }
};
// RAII 包装类
class EnemyWrapper {
private:
Enemy* ptr;
public:
// 【构造函数】:获取资源
EnemyWrapper() {
std::cout << "[Wrapper] 普通构造" << std::endl;
ptr = new Enemy();
}
// 【析构函数】:释放资源
~EnemyWrapper() {
if (ptr != nullptr) {
delete ptr;
std::cout << "[Wrapper] 析构,释放资源" << std::endl;
}
}
// ==========================================
// 【拷贝构造函数】(Deep Copy) -> 性能瓶颈在这里!
// ==========================================
// 当我们需要复制这个对象时(比如函数返回),必须调用这个函数
EnemyWrapper(const EnemyWrapper& other) {
std::cout << "[Wrapper] ⚠️ 触发深拷贝!必须分配新内存..." << std::endl;
// 笨重的深拷贝:
// A. 必须 new 一个新的 Enemy (不能共用指针,否则会 double free)
ptr = new Enemy();
// B. (如果有数据) 还要把 other.ptr 里的数据复制过来
// *ptr = *(other.ptr);
}
};
// 触发拷贝的函数
EnemyWrapper createBoss() {
std::cout << "--- 进入函数 ---" << std::endl;
// Step 1: temp 创建,new Enemy (地址 A)
EnemyWrapper temp;
std::cout << "--- 准备返回 ---" << std::endl;
// Step 2: return 时,因为要传值给外面,必须【拷贝】temp
// 这意味着:调用拷贝构造函数 -> new Enemy (地址 B) -> 复制数据
return temp;
// Step 3: 函数结束,temp 离开作用域,delete A
// (结果:我们为了得到 B,申请了 A,复制给 B,然后删了 A。A 只是个中间商。)
}
int main() {
std::cout << "=== 演示开始 ===" << std::endl;
EnemyWrapper boss = createBoss();
std::cout << "=== 演示结束 ===" << std::endl;
return 0;
}
注意,运行上面的代码需要关闭RVO(返回值优化),需要在编译命令上加-fno-elide-constructors参数,例如:g++ example.cpp -fno-elide-constructors -o example。
所谓的RVO正现代 C++ 编译器最“聪明”的地方之一,本来按照 C++ 的语法规则:
createBoss里创建temp。return时,应该把temp拷贝 给main里的boss。- 销毁
temp。
但是编译器觉得这样太蠢了,所以它**“作弊”了:
它根本没有在 createBoss 里创建 temp,而是直接在 main 函数里 boss 的内存地址上**执行了构造函数。
结果就是:0 次拷贝,0 次移动,直接构造。
虽然编译器能优化 return,但也存很多在编译器无法优化的场景(比如 vector.push_back 或者复杂的赋值)。
上述例子禁用优化之后的运行结果为:
=== 演示开始 ===
--- 进入函数 ---
[Wrapper] 普通构造
[堆资源] Enemy 被 new 出来了 (耗时操作...)
--- 准备返回 ---
[Wrapper] ⚠️ 触发深拷贝!必须分配新内存...
[堆资源] Enemy 被 new 出来了 (耗时操作...)
[堆资源] Enemy 被 delete 掉了
[Wrapper] 析构,释放资源
=== 演示结束 ===
[堆资源] Enemy 被 delete 掉了
[Wrapper] 析构,释放资源
这里的痛点:
我们陷入了死循环:
- 想快?用指针 -> 不安全(内存泄漏或悬空指针)。
- 想安全?用 RAII -> 慢(必须深拷贝,因为不能让两个 RAII 对象同时拥有同一个指针,否则会 double free)。
我们需要一种机制:既能保留 RAII 的壳子(安全),又能像指针一样只传递地址(快)。
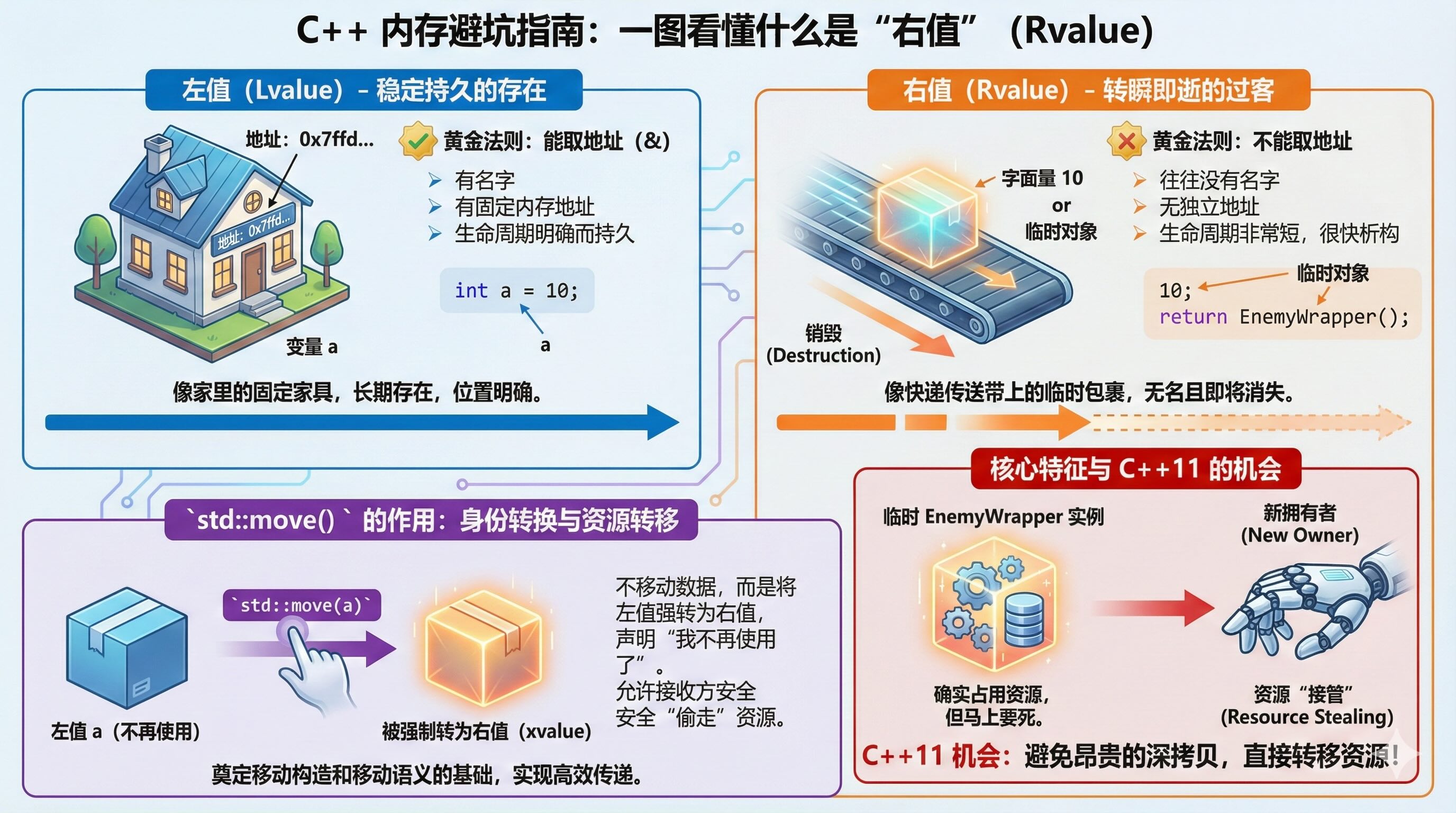
2.4. 什么是右值 (Rvalue)?
为了打破这个僵局,C++11 引入了 右值引用 (&&)。但首先,我们要搞清楚什么是“右值”。
作为开发者,不需要背诵复杂的定义,只需要掌握一个黄金法则:
能对它取地址 (
&) 的,就是左值 (Lvalue)。
不能对它取地址的,就是右值 (Rvalue)。
2.4.1. 谁是左值?谁是右值?
我们通过几行简单的代码来分辨:
int a = 10;
-
a是左值: -
为什么? 因为你可以写
&a,能拿到它的内存地址。它在栈上有一个固定的家。 -
生命周期:持久,直到大括号
}结束。 -
10是右值: -
为什么? 它是字面量。你试着写
int* p = &10;,编译器会直接报错。它没有地址,它只是代码里的一个数字。
2.4.2. 隐藏的右值(临时对象)
对于对象来说,右值往往是一个**“无名无姓的幽灵对象”**。这是最容易被忽视的场景。
EnemyWrapper getBoss() {
// 返回一个新创建的对象
return EnemyWrapper();
}
void main() {
EnemyWrapper boss = getBoss();
}
问题:getBoss() 执行完的那一瞬间,发生了什么?
- 函数内部创建了一个
EnemyWrapper对象。 - 函数返回时,这个对象被扔了出来。
- 在它被赋值给变量
boss之前,它漂浮在虚空中。
这个漂浮在虚空中的对象,就是 右值。
- 特征:它存在,占用了内存,但没有名字。
- 命运:它马上就要死了。一旦赋值语句结束,这个临时对象就会析构。
2.4.3. std::move() 到底做了什么?
你经常会看到 std::move(x)。很多人误以为它会移动数据,其实它什么都没移动。它的作用只有一个:身份欺诈。
// a 是左值,活得好好的
EnemyWrapper a;
// 强行把 a 标记为右值
EnemyWrapper b = std::move(a);
a本来是左值。std::move(a)相当于给a贴了个条子:“这辆车我不想要了,当废品处理”。- 于是,
a被强制转换成了 右值。 b看到这个条子,就会认为a是个将死之物,从而直接“偷走”它的资源。
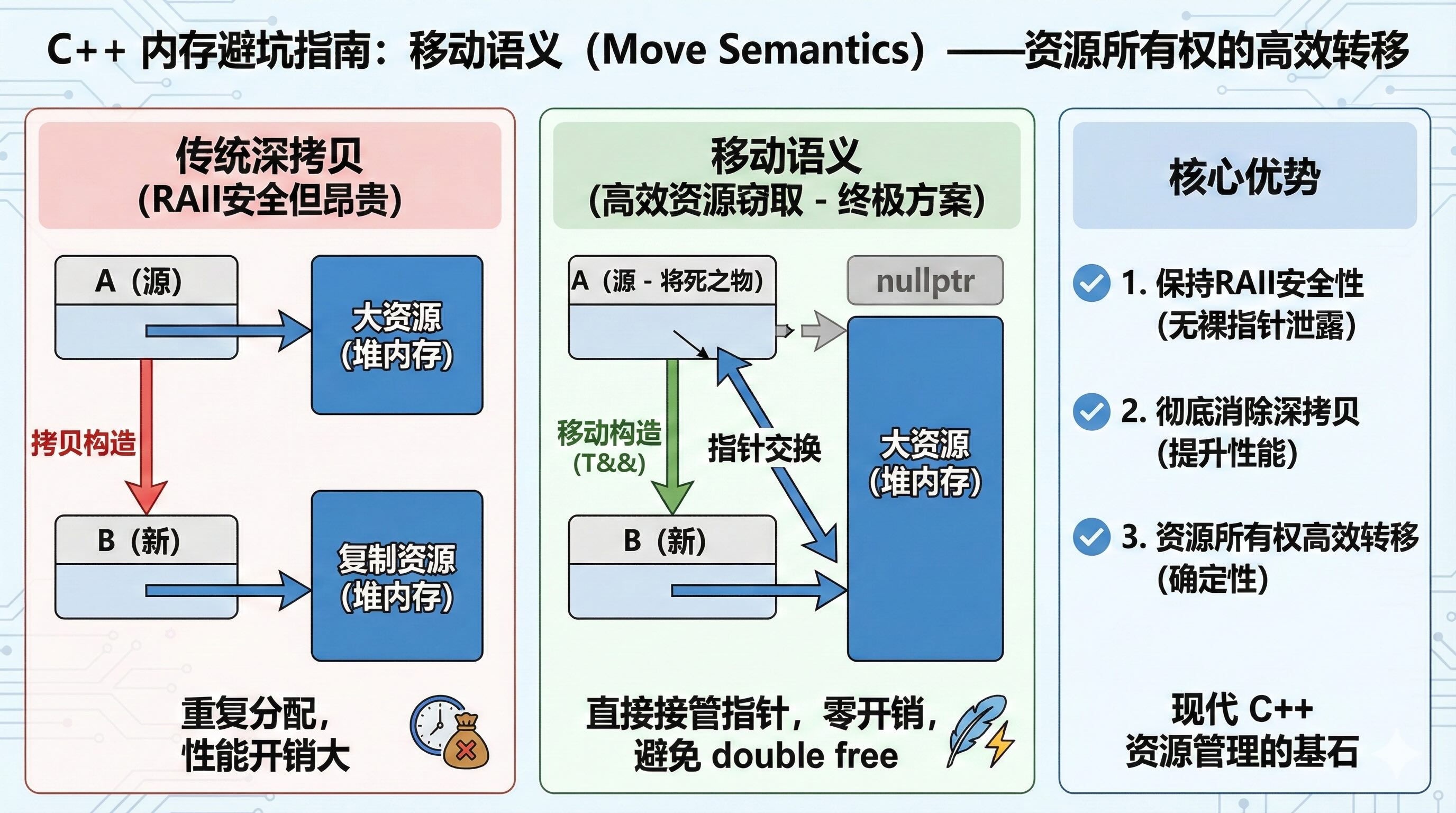
2.5. 终极方案:移动语义 (Move Semantics)
既然我们能识别出右值(将死之物),我们就可以利用这一点来优化 RAII。
我们在 EnemyWrapper 里加一个特殊的构造函数——移动构造函数。它专门接收右值引用 (&&)。
移动的本质就是:合法的窃取。
#include <iostream>
// 模拟一个“昂贵”的资源
class Enemy {
public:
Enemy() { std::cout << " [堆资源] Enemy 被 new 出来了 (耗时操作...)" << std::endl; }
~Enemy() { std::cout << " [堆资源] Enemy 被 delete 掉了" << std::endl; }
};
// RAII 包装类
class EnemyWrapper {
private:
Enemy* ptr;
public:
// 【构造函数】:获取资源
EnemyWrapper() {
std::cout << "[Wrapper] 普通构造" << std::endl;
ptr = new Enemy();
}
// 【析构函数】:释放资源
~EnemyWrapper() {
if (ptr != nullptr) {
delete ptr;
std::cout << "[Wrapper] 析构,释放资源" << std::endl;
}
}
// ==========================================
// 【拷贝构造函数】(Deep Copy) -> 性能瓶颈在这里!
// ==========================================
// 当我们需要复制这个对象时(比如函数返回),必须调用这个函数
EnemyWrapper(const EnemyWrapper& other) {
std::cout << "[Wrapper] ⚠️ 触发深拷贝!必须分配新内存..." << std::endl;
// 笨重的深拷贝:
// A. 必须 new 一个新的 Enemy (不能共用指针,否则会 double free)
ptr = new Enemy();
// B. (如果有数据) 还要把 other.ptr 里的数据复制过来
// *ptr = *(other.ptr);
}
// 【移动构造】(Move) - C++11 的新方案
// 参数是 &&,表示对方是“将死之物”
EnemyWrapper(EnemyWrapper&& other) noexcept {
// 1. 偷梁换柱:把对方的指针拿过来
this->ptr = other.ptr;
// 2. 毁灭证据:把对方的指针设为 nullptr
// 这一步至关重要!
// 当 other 析构时,它会 delete nullptr (什么也不做)
// 从而避免了资源被误删
other.ptr = nullptr;
std::cout << "Move: Ownership transferred!" << std::endl;
}
};
// 触发移动构造函数
EnemyWrapper createBoss() {
// 这一行代码做了两件事:
// 1. 在【栈】上分配了 EnemyWrapper 这个壳子的内存(非常快,不需要 new)
// 2. 自动调用了它的构造函数
EnemyWrapper temp;
// temp 是局部变量,返回时被视为右值
return temp;
}
int main() {
// 1. createBoss 返回临时对象(右值)
// 2. 触发【移动构造函数】
// 3. main 里的 boss 直接接管了 temp 里的指针
// 4. temp 变成空壳被销毁
EnemyWrapper boss = createBoss();
// 结果:
// - 没有发生 Deep Copy (省了 new/copy)
// - 没有传递裸指针 (全程都在 RAII 包装下,非常安全)
}
运行结果:
[Wrapper] 普通构造
[堆资源] Enemy 被 new 出来了 (耗时操作...)
Move: Ownership transferred!
[堆资源] Enemy 被 delete 掉了
[Wrapper] 析构,释放资源
可以看到,现在没有深拷贝操作了。但看到这里,可能大家还有有几个问题:
2.5.1 问题 1:为什么不能在拷贝构造函数中“掠夺”资源?
你可能会想:“能不能别搞什么移动构造函数了,直接改写拷贝构造函数,把 const 去掉,然后在里面偷指针?”
答案是:语法上行得通,但在逻辑上是“灾难”。
2.5.1.1. 理由 A:契约精神 (语义混淆)
在编程世界里,“拷贝 (Copy)”这个词是有明确定义的:制作副本,原件不受影响。
如果我写 b = a;,按照人类的直觉,a 应该还在那里,完好无损。
如果你在拷贝函数里搞“掠夺”,就会出现这种恐怖场景:
// 假设这是“魔改版”的拷贝构造函数 (没有 const)
EnemyWrapper(EnemyWrapper& other) {
this->ptr = other.ptr;
other.ptr = nullptr; // 偷偷把原件毁了!
}
void logicalDisaster() {
EnemyWrapper a; // a 有资源
// 我只想做一个备份
EnemyWrapper b = a;
// 灾难发生:a 变成空壳了!
// 后面的代码如果继续用 a,程序直接崩溃。
a.attack(); // Crash!
}
结论:如果拷贝会破坏原件,那就不能叫“拷贝”,那叫“抢劫”。程序员无法通过代码一眼看出 b = a 到底安全不安全。为了区分“复制”和“转移”,我们需要两个不同的函数。
2.5.1.2. 理由 B:语法限制 (Const Correctness)
标准的拷贝构造函数签名是 const EnemyWrapper& other。
- 那个
const是铁律。它向调用者保证:“你放心传给我,我绝不动你的一根毫毛”。 - 因为有
const,编译器禁止你写other.ptr = nullptr;。 - 如果你强行去掉
const,它就无法接受临时对象(因为临时对象通常绑定到 const 引用),导致通用性大打折扣。
2.5.2 问题 2:编译器是如何区分调用“拷贝”还是“移动”的?
这是一个非常精彩的**“函数重载决议” (Overload Resolution)** 过程。
编译器并不是通过“猜”你的意图来决定的,它是通过参数类型匹配来决定的。
2.5.2.1. 两个函数的签名对比
- 拷贝构造:
EnemyWrapper(const EnemyWrapper&)-> 接收 左值 (和右值,作为备胎)。 - 移动构造:
EnemyWrapper(EnemyWrapper&&)-> 专门接收 右值。
2.5.2.2. createBoss 里的决策过程
当你在 return temp; 时(假设 RVO 被禁用,必须发生传递):
- 判定
temp的状态:
虽然temp在函数里定义时是个左值,但因为它马上要被 return 了,即将销毁,C++ 编译器会自动把它视为 xvalue (将亡值),也就是一种右值。 - 开始匹配构造函数:
编译器看着main函数里正在等待接收的boss对象,问:“我手里有一个右值,我该调用哪个构造函数来初始化boss?”
- 选手 A (拷贝):我要
const &。可以接收右值吗?可以(const 引用能接万物),但只是“兼容”。 - 选手 B (移动):我要
&&。可以接收右值吗?完美匹配!
- 择优录取:
编译器发现选手 B 是精确匹配 (Exact Match),所以毫不犹豫地选择了移动构造函数。
2.5.2.3. 只有拷贝构造函数时会怎样?
如果你没写移动构造函数(C++98 的情况):
- 编译器手里拿着右值,发现没有
&&的构造函数。 - 它会退而求其次,发现
const &(拷贝构造)也能接收右值。 - 于是含泪调用了拷贝构造函数(深拷贝)。
2.5.3. 总结
| 场景 | 传递给构造函数的参数 | 优先匹配 | 备选匹配 | 结果 |
|---|---|---|---|---|
EnemyWrapper b = a; |
左值 (a 还要接着用) | (const T&) 拷贝 |
无 | 深拷贝 |
return temp; |
右值 (temp 马上死) | (T&&) 移动 |
(const T&) 拷贝 |
移动 (偷) |
b = std::move(a); |
右值 (强转的) | (T&&) 移动 |
(const T&) 拷贝 |
移动 (偷) |
一句话总结:编译器看“参数类型”。如果是“将死之物(右值)”,优先匹配 && 版(移动);如果是“普通对象(左值)”,只能匹配 const & 版(拷贝)。
2.6. 避坑指南:return 时千万别用 move
那在 createBoss 函数里,需要写 return std::move(temp); 吗?
答案是:不要!
EnemyWrapper createBoss() {
EnemyWrapper temp;
// 正确写法:编译器会自动优化 (RVO)
// 编译器会直接在外部变量的内存地址上构造 temp,连“移动”都不需要做!
// 成本 = 0
return temp;
// 错误写法:画蛇添足
// return std::move(temp);
// 这会强行打断编译器的 RVO 优化,强制执行一次“移动构造”。
// 成本 > 0 (虽然也很低,但是属于“负优化”)
}
那 std::move 到底用在哪里?
用在你需要显式转移一个左值的所有权时:
int main() {
// 1. RVO 自动优化,这里没有拷贝,也没有移动
EnemyWrapper boss1 = createBoss();
// 2. 假设你想把 boss1 转给 boss2
// EnemyWrapper boss2 = boss1; // 编译报错(假设禁用了拷贝)或深拷贝(慢)
// 3. 这里必须用 std::move!
// 因为 boss1 是个活着的左值,编译器不敢自动动它。
// 你必须手动签署“放弃所有权书”。
EnemyWrapper boss2 = std::move(boss1);
// 此刻:boss2 拿到了指针,boss1 变成了空壳。
}
2.7. 移动语义的本质:所有权转移 (Ownership Transfer)
很多从 Java/Python 转过来的开发者,在理解“移动”时容易陷入误区,认为数据真的在内存里“搬家”了。
移动语义的本质,并不是移动数据,而是“所有权的交接”。
2.7.1. 核心思想:唯一责任制 (Sole Ownership)
在 Java 中,对象的所有权是共享的(Shared)。
- 你有一个
List,传给函数 A,传给函数 B,大家都拿着引用的副本。 - 谁负责销毁它?谁都不负责。GC 负责。
- 这种模式很省心,但在资源敏感(如文件句柄、网络连接、互斥锁)或高性能场景下,会导致资源释放的不可控。
在现代 C++(RAII + Move)中,我们强调独占所有权(Exclusive Ownership)。
- 原则:对于某一块堆内存资源,在任何时刻,只能有一个对象对它负责。
- 推论:既然只有一个主人,那么当这个主人被销毁时,资源必须被销毁。
2.7.2. 移动的物理动作:浅拷贝 + 抹除原主 (Shallow Copy + Nullify)
既然资源只能有一个主人,那么当我们需要把资源传给别人时,就不能是“分享”(Copy),只能是“过户”(Move)。
移动语义在汇编层面的本质只有两步:
- 窃取指针(Shallow Copy):
- 新主人(
dest)把旧主人(src)手里的指针值(地址)复制过来。 - 此刻,两个人都指向了同一个资源(危险状态!)。
- 抹除旧主(Nullify):
- 最关键的一步:把旧主人(
src)手里的指针设为nullptr。 - 结果,旧主人失去了对资源的控制权,变成了空壳。
2.7.3. 现实世界的类比
为了理解“拷贝”和“移动”的区别,我们可以用 “房产证” 做比喻:
- 资源(Resource):房子(不动产,很贵,搬不动)。
- 指针(Pointer):房产证(一张纸,很轻)。
场景 A:深拷贝 (Deep Copy) —— C++98 的做法
- 操作:你想把房子给你的儿子。
- C++98:你必须在隔壁盖一栋一模一样的新房子(
new),然后把新房子的房产证给儿子。 - 代价:极度浪费钱和时间。
场景 B:移动语义 (Move Semantics) —— C++11 的做法
- 操作:你想把房子给你的儿子。
- C++11:你把手里的房产证直接交给儿子,然后把你自己的名字从房管局注销。
- 代价:房子根本没动,只是持有人变了。
2.7.4. 为什么说这是“所有权”的体现?
回到我们之前的 EnemyWrapper 代码:
EnemyWrapper(EnemyWrapper&& other) noexcept {
// 1. 接过房产证
this->ptr = other.ptr;
// 2. 原主注销,从此这房子和你无关了
other.ptr = nullptr;
}
这里体现了 C++ 最硬核的契约精神:
“我移动了你,你就不再拥有它。后续的清理工作由我负责,你只需安静地离开。”
这解决了 C++ 长期以来的**“双重释放” (Double Free)** 问题:因为原主变成了 nullptr,它的析构函数 delete nullptr 不会产生任何副作用。
2.8. 总结
- 裸指针:虽快,但无法保证内存一定会释放(容易泄漏)。
- RAII:通过包装类保证了内存一定释放,但在 C++98 中,为了保证安全(防止多次释放),传递对象时必须进行深拷贝,导致性能低下。
- 右值 (Rvalue):指那些没有名字、即将销毁的临时对象(不能取地址)。
- 移动语义 (Move):是完美的折中方案。它允许 RAII 对象在“交接班”时,通过识别右值,直接把内部的指针所有权转移给对方,既保留了 RAII 的外壳(安全),又只传递了指针(高效)。
3. 智能指针与 Java GC
在前两章节中,我们已经掌握了 RAII(利用栈管理堆) 和 移动语义(所有权转移)。如果仔细观察,会发现我们手写的 EnemyWrapper 其实就是一个简陋的“智能指针”。
C++ 标准库把这种模式标准化了,提供了三个现成的工具,统称为 智能指针 (Smart Pointers)。它们彻底终结了手动写 delete 的历史。
3.1. 什么是智能指针?
智能指针不是指针,它是一个 C++ 类(Class)。
- 它在栈上(像个普通变量)。
- 它里面藏着一个裸指针(指向堆)。
- 它利用 RAII,在析构函数里自动
delete那个裸指针。 - 它重载了
*和->运算符,让你用起来感觉像个指针。
C++ 提供了三种智能指针,分别对应三种所有权模式:
std::unique_ptr:你是我的唯一(独占所有权)。std::shared_ptr:我们共享它(共享所有权)。std::weak_ptr:我就静静地看着你(弱引用,不增加计数)。
3.2. std::unique_ptr (独占)
这是 C++ 中最推荐、最常用的智能指针。90% 的场景都应该用它。
3.2.1. 核心特性
- 独占性:同一时间,只能有一个
unique_ptr指向那个对象。 - 不可拷贝:你不能复制它(否则会有两个主人,这就是我们之前手动禁用的拷贝构造)。
- 可移动:你可以把所有权移交给别人(利用移动语义)。
- 零开销:它的性能和裸指针完全一样。它只是多了一层编译期的检查,运行时没有任何额外负担。
3.2.2. 代码示例
#include <iostream>
#include <memory> // 必须包含这个头文件
// 模拟一个“昂贵”的资源
class Enemy {
public:
Enemy() { std::cout << " [堆资源] Enemy 被 new 出来了 (耗时操作...)" << std::endl; }
~Enemy() { std::cout << " [堆资源] Enemy 被 delete 掉了" << std::endl; }
void attack() { std::cout << "Enemy attacks!" << std::endl; }
};
void uniqueDemo() {
// 1. 创建 (推荐用 make_unique,不要直接 new)
std::unique_ptr<Enemy> boss = std::make_unique<Enemy>();
boss->attack(); // 用起来像指针
// 2. 禁止拷贝!
// std::unique_ptr<Enemy> boss2 = boss; // ❌ 编译报错!
// 3. 可以移动!
// 这里的 move 就像我们在 Part 2 学的那样,把所有权转给 p2
std::unique_ptr<Enemy> boss2 = std::move(boss);
// 此时:
// boss 变成了 nullptr (空)
// boss2 拥有了对象
} // 函数结束 -> boss2 析构 -> 自动 delete Enemy
int main() {
uniqueDemo();
return 0;
}
运行结果如下:
[堆资源] Enemy 被 new 出来了 (耗时操作...)
Enemy attacks!
[堆资源] Enemy 被 delete 掉了

3.3. std::shared_ptr (共享)
这货看起来最像 Java 的引用。它允许多个指针指向同一个对象。
3.3.1. 核心特性
-
引用计数 (Reference Counting):它内部维护一个计数器。
-
每多一个人指向它,计数 +1。
-
每有一个人销毁或不再指向它,计数 -1。
-
当计数变成 0 时,自动
delete对象。 -
有开销:为了维护这个计数器(而且要保证多线程安全),它比
unique_ptr慢一点点,内存也多一点(因为要存计数器)。
3.3.2. 代码示例
#include <iostream>
#include <memory> // 必须包含这个头文件
// 模拟一个“昂贵”的资源
class Enemy {
public:
Enemy() { std::cout << " [堆资源] Enemy 被 new 出来了 (耗时操作...)" << std::endl; }
~Enemy() { std::cout << " [堆资源] Enemy 被 delete 掉了" << std::endl; }
void attack() { std::cout << "Enemy attacks!" << std::endl; }
};
void sharedDemo() {
// 1. 创建 (引用计数 = 1)
std::shared_ptr<Enemy> p1 = std::make_shared<Enemy>();
{
// 2. 拷贝 (引用计数 = 2)
// 注意:这里是可以直接 "=" 赋值的,因为它是共享的
std::shared_ptr<Enemy> p2 = p1;
p2->attack();
std::cout << "当前引用数: " << p1.use_count() << std::endl; // 输出 2
}
// p2 离开作用域,引用计数 -1 (变回 1)。对象还活着!
p1->attack();
} // 函数结束,p1 离开,引用计数 -1 (变成 0) -> delete Enemy
int main() {
sharedDemo();
return 0;
}
运行结果如下:
[堆资源] Enemy 被 new 出来了 (耗时操作...)
Enemy attacks!
当前引用数: 2
Enemy attacks!
[堆资源] Enemy 被 delete 掉了
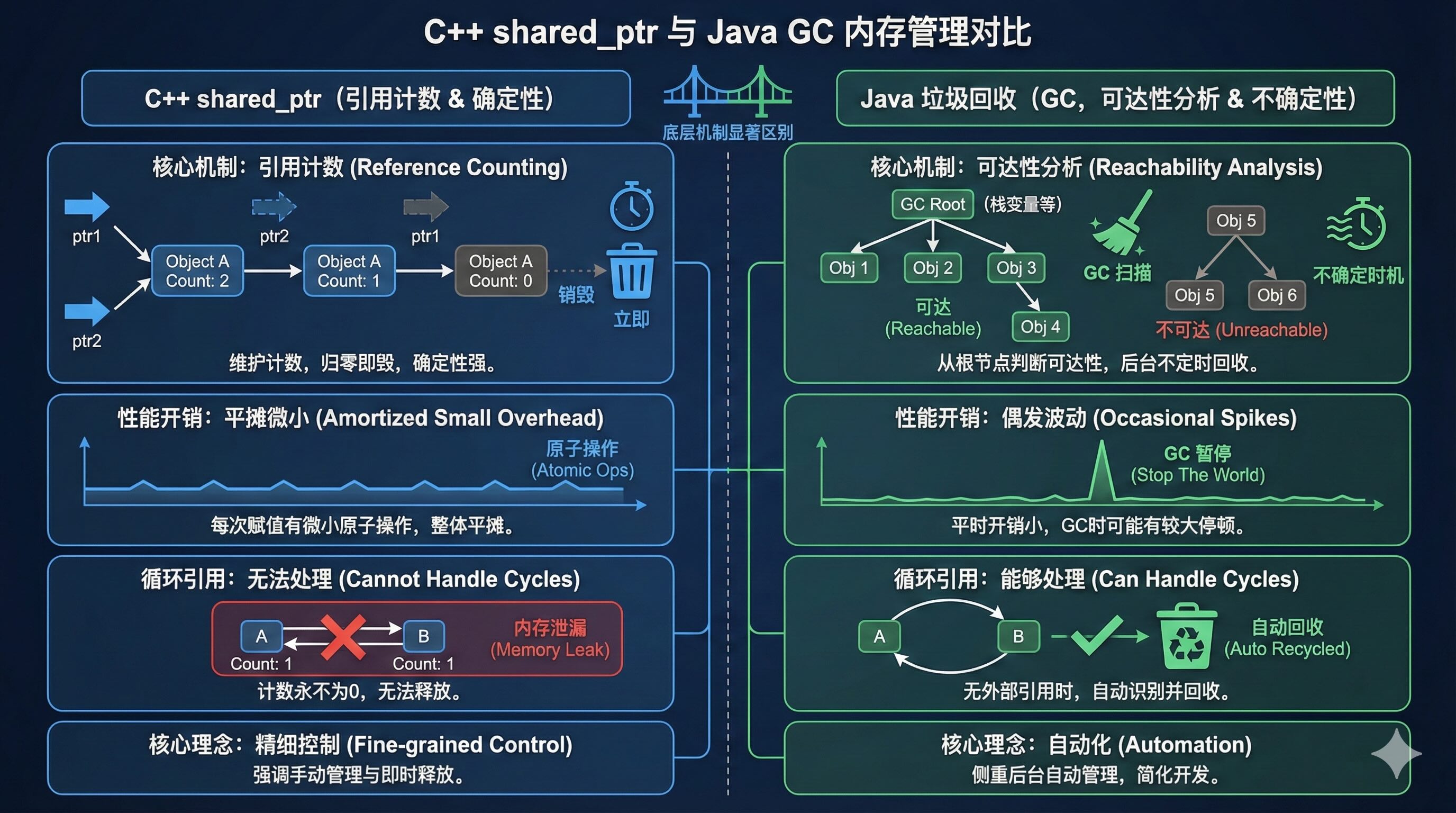
3.4. C++ shared_ptr vs Java GC
这是面试和架构设计中的核心考点。C++ 的 shared_ptr 和 Java 的引用看起来很像,但底层逻辑完全不同。
3.4.1. 机制对比:引用计数 vs 可达性分析
| 特性 | C++ (shared_ptr) |
Java (Garbage Collection) |
|---|---|---|
| 核心算法 | 引用计数 (Reference Counting) | 可达性分析 (Tracing / Reachability) |
| 判定死亡 | 只要计数器归零,立刻死亡。 | 从 GC Roots (如栈变量) 出发,找不到的对象才算死。 |
| 释放时机 | 确定性 (Deterministic)。最后一个指针销毁的那一瞬间,对象必死。 | 不确定性。看 GC 心情,可能几秒后,可能内存不够时。 |
| 性能开销 | 平摊。每次赋值都有微小的原子操作开销。 | 集中。平时很快,但 GC 运行时可能导致 “Stop The World” (卡顿)。 |
| 循环引用 | 无法处理。A 指向 B,B 指向 A,两人计数都是 1,永远不归零 -> 内存泄漏。 | 完美处理。GC 发现这俩货虽然互相指,但外面没人指它们,直接一锅端。 |
3.4.2. 场景演示:循环引用 (C++ 的阿喀琉斯之踵)
这是 C++ shared_ptr 最大的坑。
#include <iostream>
#include <memory>
// 前置声明:因为 A 里面要用 B,B 里面要用 A,必须先告诉编译器 B 是个类
class B;
class A {
public:
// A 持有 B 的强引用 (shared_ptr)
std::shared_ptr<B> ptrB;
A() { std::cout << "A Created (构造)" << std::endl; }
~A() { std::cout << "A Destroyed (析构) <--- 如果看到这句话,说明没泄露" << std::endl; }
};
class B {
public:
// B 持有 A 的强引用 (shared_ptr) -> 导致死锁
std::shared_ptr<A> ptrA;
B() { std::cout << "B Created (构造)" << std::endl; }
~B() { std::cout << "B Destroyed (析构) <--- 如果看到这句话,说明没泄露" << std::endl; }
};
int main() {
std::cout << "=== 进入作用域 ===" << std::endl;
{
// 1. 创建对象
// 此时 A 的计数 = 1 (只有变量 a 指向它)
// 此时 B 的计数 = 1 (只有变量 b 指向它)
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
std::cout << "1. 初始引用计数:" << std::endl;
std::cout << " A counts: " << a.use_count() << std::endl;
std::cout << " B counts: " << b.use_count() << std::endl;
// 2. 建立循环引用 (互相锁死)
std::cout << "2. 建立循环引用 (a->ptrB = b; b->ptrA = a;)" << std::endl;
a->ptrB = b; // B 的计数 +1 -> 变成 2 (b 变量 + a.ptrB)
b->ptrA = a; // A 的计数 +1 -> 变成 2 (a 变量 + b.ptrA)
std::cout << " A counts: " << a.use_count() << std::endl;
std::cout << " B counts: " << b.use_count() << std::endl;
std::cout << "--- 准备离开作用域 ---" << std::endl;
} // 3. 这里!离开作用域!
// 正常逻辑:
// - 栈变量 a 销毁 -> A 计数减 1 (2 -> 1) -> 不为 0,A 不死!
// - 栈变量 b 销毁 -> B 计数减 1 (2 -> 1) -> 不为 0,B 不死!
// 结果:A 拿着 B,B 拿着 A,谁也撒不开手。堆内存永远无法释放。
std::cout << "=== 离开作用域 (main 结束) ===" << std::endl;
std::cout << "警告:你没有看到析构函数的日志,说明发生了内存泄漏!" << std::endl;
return 0;
}
运行结果如下:
=== 进入作用域 ===
A Created (构造)
B Created (构造)
1. 初始引用计数:
A counts: 1
B counts: 1
2. 建立循环引用 (a->ptrB = b; b->ptrA = a;)
A counts: 2
B counts: 2
--- 准备离开作用域 ---
=== 离开作用域 (main 结束) ===
警告:你没有看到析构函数的日志,说明发生了内存泄漏!
而Java 对此表示毫无压力:Java GC 由于有GC Root,会发现 A 和 B 这一坨东西和外界断开了联系,直接把它俩都回收了。
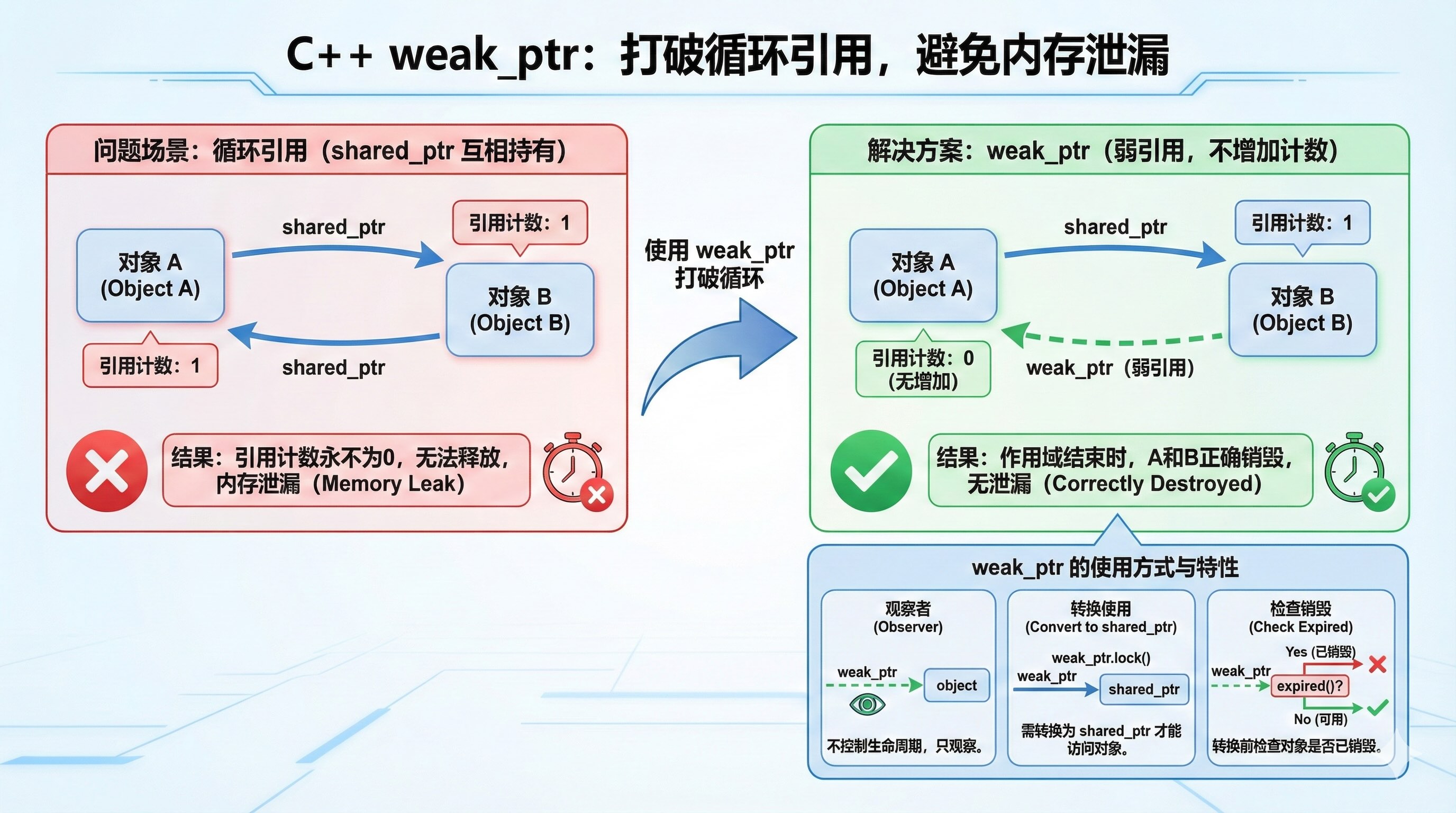
3.5. std::weak_ptr (打破循环的救星)
为了解决上面的循环引用问题,C++ 引入了 weak_ptr。
- 弱引用:它指向
shared_ptr管理的对象,但是不增加引用计数。 - 旁观者:它只是看着对象,不能直接用。如果要用,必须先“升级”为
shared_ptr(并通过升级结果判断对象是否已经死了)。
修复上面的代码:
我们只需要把 B 里面的指针改成 weak_ptr:
#include <iostream>
#include <memory>
class B; // 前置声明
class A {
public:
// A 持有 B 的【强引用】(shared_ptr)
// 意味着:只要 A 活着,B 就不能死
std::shared_ptr<B> ptrB;
A() { std::cout << "A Created (构造)" << std::endl; }
~A() { std::cout << "A Destroyed (析构)" << std::endl; }
};
class B {
public:
// 关键修改:B 持有 A 的【弱引用】(weak_ptr)
// 意味着:B 只是看着 A,但 B 不决定 A 的生死。
// weak_ptr 不会增加 shared_ptr 的引用计数!
std::weak_ptr<A> ptrA;
B() { std::cout << "B Created (构造)" << std::endl; }
~B() { std::cout << "B Destroyed (析构)" << std::endl; }
};
int main() {
std::cout << "=== 进入作用域 ===" << std::endl;
{
// 1. 创建对象
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
// 2. 建立引用
std::cout << "--- 建立连接 ---" << std::endl;
a->ptrB = b; // A 强引用 B。B 的计数 = 2 (main里的b + A里的ptrB)
b->ptrA = a; // B 弱引用 A。A 的计数 = 1 (只有main里的a) !!!
std::cout << "当前引用计数 (关键点):" << std::endl;
// A 的计数只有 1,因为 weak_ptr 不算数
std::cout << " A counts: " << a.use_count() << " (只有 main 持有它)" << std::endl;
// B 的计数是 2,因为 A 强引用着它
std::cout << " B counts: " << b.use_count() << " (main 和 A 都持有它)" << std::endl;
std::cout << "--- 准备离开作用域 ---" << std::endl;
}
// 3. 离开作用域的过程:
// Step 1: 变量 'a' 销毁。
// A 的引用计数从 1 变成 0。
// -> A 死了!打印 "A Destroyed"。
// -> A 析构时,会自动销毁它的成员 ptrB。
// Step 2: A 的成员 ptrB 被销毁。
// B 的引用计数从 2 减为 1。
// Step 3: 变量 'b' 销毁。
// B 的引用计数从 1 变成 0。
// -> B 死了!打印 "B Destroyed"。
std::cout << "=== 离开作用域 (main 结束) ===" << std::endl;
return 0;
}
运行结果如下(可以看到清晰的析构日志,证明没有内存泄漏:):
=== 进入作用域 ===
A Created (构造)
B Created (构造)
--- 建立连接 ---
当前引用计数 (关键点):
A counts: 1 (只有 main 持有它)
B counts: 2 (main 和 A 都持有它)
--- 准备离开作用域 ---
A Destroyed (析构)
B Destroyed (析构)
=== 离开作用域 (main 结束) ===
3.6. 总结与最佳实践
3.6.1. 对比总结
- C++ RAII / 智能指针:
- 优点:即时释放(不用等 GC),资源利用率极高,无 STW 卡顿。非常适合做实时系统、游戏引擎、高频交易。
- 缺点:有思维负担,需要手动处理循环引用(
weak_ptr)。
- Java GC:
- 优点:开发效率高,不用关心循环引用,只要不瞎搞很难内存泄漏。
- 缺点:释放时机不可控,GC 运行时有性能波动,内存占用通常比 C++ 高。
关于开销的真相:
很多人认为 C++ 一定比 Java 快,但在内存分配上,Java 其实往往更快。Java 的new只是指针后移(Pointer Bump),极其廉价;而 C++ 的malloc/new需要去空闲链表中寻找合适的内存块。
C++ 的优势在于运行时期的平稳:它没有 GC 那个不定时触发的“大扫除”,因此非常适合对延迟 (Latency) 极度敏感的场景(如高频交易、游戏引擎、实时控制系统),而 Java 更适合追求吞吐量 (Throughput) 的后端服务。
3.6.2. C++ 避坑指南
- **默认首选
std::unique_ptr**。除非你真的需要多个人共享所有权,否则别用shared_ptr。 - **绝不使用
new**。
- 用
std::make_unique<T>()代替new T()。 - 用
std::make_shared<T>()代替new T()。 - 这不仅代码短,而且能防止某些极端情况下的内存泄漏。
- 遇到循环引用,立刻想到把其中一边换成
std::weak_ptr。
现在,我们已经掌握了 C++ 内存管理的核心:对象默认在栈上,堆对象用 unique_ptr 管,共享对象用 shared_ptr 管,循环引用用 weak_ptr 破。
4. 结语
从 Java 的“全自动驾驶”切换到 C++ 的“手动挡”,最大的挑战往往不在于语法,而在于思维模式的转变。
C++ 将内存的控制权完全交还给了程序员,这既是绝对的自由,也是沉重的责任。通过本文,我们看到 RAII 赋予了我们确定性的资源释放能力,而移动语义和智能指针则在“极致性能”与“内存安全”之间架起了桥梁。
记住 C++ 现代开发的黄金法则:默认使用栈对象,堆内存首选 unique_ptr,共享资源用 shared_ptr,循环引用靠 weak_ptr 打破。 掌握了这些,我们就真正驾驭了这门语言最锋利的双刃剑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)