详解CNN:卷积神经网络
本文将重点介绍卷积神经网络的基本结构及原理,包括神经元、连接方式、激活函数以及神经网络模型的建立等方面,主要用于自己学习理解,部分内容参照了鱼书以及AI辅助生成,不足之处还请指正。
本文将重点介绍卷积神经网络的基本结构及原理,包括神经元、连接方式、激活函数以及神经网络模型的建立等方面,主要用于自己学习理解,部分内容参照了鱼书以及AI辅助生成,不足之处还请指正。
1.神经网络的组成
1.1 神经元:
是神经网络的基本组成单元,单个神经元只能做简单的线性判断,但成千上万的神经元按层连接,再搭配不同的激活函数,就能处理图像识别、语音翻译这种复杂任务。如下图所示
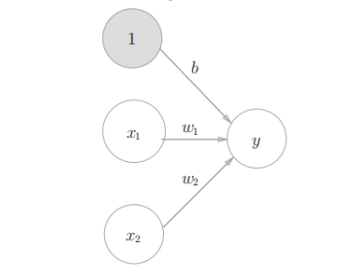
1:偏置单元;固定输入为 1,专门用来承载偏置 b,让公式更统一
X1,X2:输入信号;神经元接收的外部数据 / 上一层输出,是待处理的信息
W1,W2:权重参数;分别对应X1,X2的 “重要程度”,权重越大,该输入对输出影响越大
B:偏置;神经元的 “决策基线”,用来调整输出的整体偏移(类似线性方程的截距)
Y:神经元输出;是所有输入的加权和
![]()
1.2 激活函数:
引入”非线性”,让神经网络能处理 “弯弯曲曲” 的问题,激活函数会给加权和 a 做一个“非线性变换”,把直线变成曲线 / 分段线,让神经网络能拟合现实中复杂的规律。
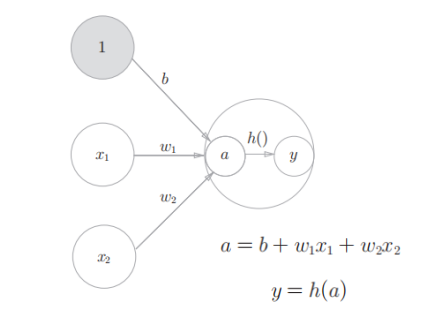
h():激活函数;对a做非线性变换,是神经元的”灵魂”。
常见的一些激活函数
Sigmoid表达式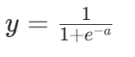
输出映射到 (0,1),适用于二分类输出层,易梯度消失。
ReLU表达式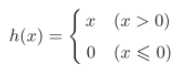
输入 > 0时输出自身,否则输出0,计算高效,缓解梯度消失,是当前主流。
Softmax表达式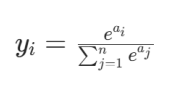
用于多分类输出层,将得分转换为概率分布,输出和为 1。
Tanh表达式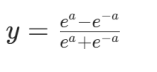
输出在-1~1之间,0 均值,比 Sigmoid 更”对称”,适用循环神经网络(RNN/LSTM)的隐藏层。
核心原则:激活函数必须是非线性的,否则多层网络等价于单层线性模型,无法拟合复杂数据。
1.3 层级结构:
”先收数据→分层提炼关键信息→输出最终结果”,每层只干自己的活, 分工越细(层数 / 神经元越多),处理复杂问题的能力越强。如下图所示
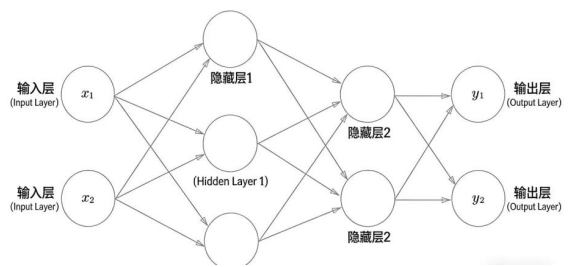
输入层:接收原始数据,神经元数等于特征维度。通俗理解一个数据需要n个关键信息 (特 征维度 = n),输入层就需要n个接收员(神经元数 = n),一一对应所有信息。
隐藏层:核心特征提取层,层数(≥ 1 层)主要由任务复杂度决定。
输出层:输出层的核心就是 “把隐藏层的‘半成品特征’,加工成你要的‘成品结果’”,即输出预测 结果。
2.层级结构的组成
2.1 输入层
它是网络的第一层,没有可学习参数(权重、偏置),只负责接收并传递数据。
神经元数量 = 输入数据的维度(比如 227×227×3 的图像,输入层神经元数就是 227×227×3 = 154,587)。代表的是 高度 × 宽度 × 通道数
作用:把原始数据(图像、文本、数值)转换成网络能处理的数值形式,并传递给下一 层。
如:
图像分类 → 输入层是像素值(227×227×3 的 RGB 图像)
文本分类 → 输入层是词向量(每个词对应一个向量)
房价预测 → 输入层是房屋特征(面积、房间数、地段等)
2.2 卷积层
卷积是卷积核在输入数据上滑动,对局部区域进行加权求和并生成特征映射的过程,本质是”特征检测器”,是特征提取的数学操作。
2.2.1卷积的核心运算:
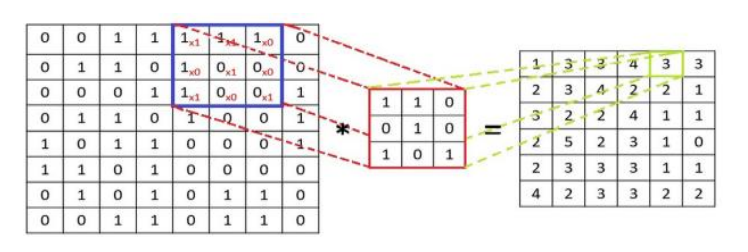
卷积核(图1红色矩阵):小矩阵(常见 3×3、5×5),每个核提取一种特定特征(如横线、 竖线、边缘),所以卷积核中参数是共享的,平移不变的,核的数量决定输出特征图数 量。
步长(Stride):卷积核滑动间隔,步长1逐像素滑动,步长2间隔1像素滑动,影 响输出特征图尺寸。
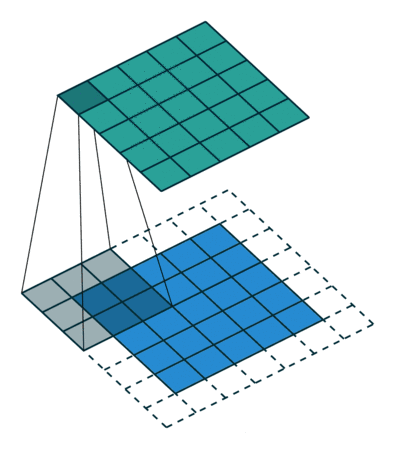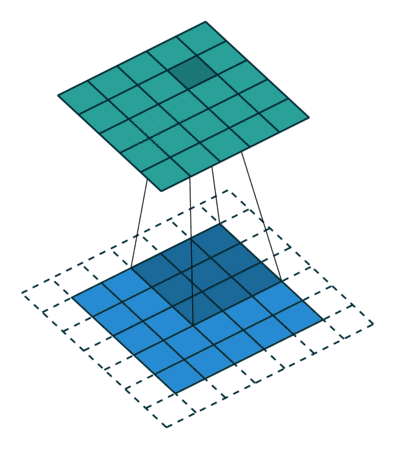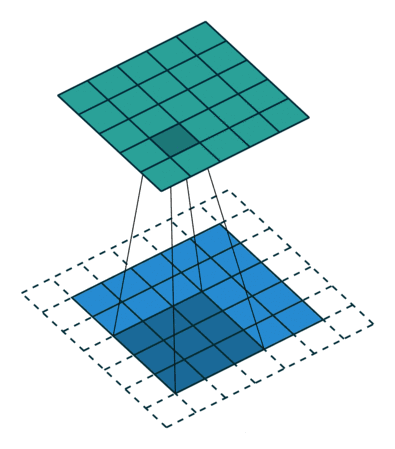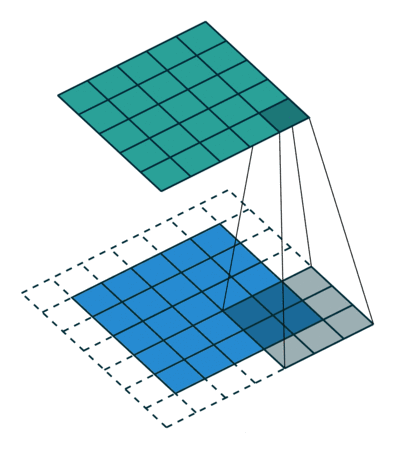
填充(Padding):在输入数据边缘补0 (0填充),用于控制输出特征图尺寸。如图2虚线部分
(图2中绿色矩阵为特征图,特征图正是由卷积核从初始位置滑动到最后,通过相乘求和计算而来,滑动时步长为1,虚线部分为填充部分padding = 1,蓝色矩阵为输入层输 入数据)
注:在刚开始训练之初,是随机初始化进来的数,无特殊含义,对图片也无信息处理能 力,随着网络的训练它会自我更新、变化、慢慢会发生变化。
2.2.2多通道问题:
计算机在存储一张图片时,存储了3个同样大小的独立的的二位灰度图(通道),每个矩阵对应一种颜色通道(R G B)
卷积核的通道数必须和输入的通道数完全一致,比如输入是 3 通道(RGB),那么一个卷积核就是 3×k×k 的三维结构(k 为卷积核大小,如 3×3)。
卷积运算时:逐通道做卷积 → 各通道结果相加 → 得到 1 个单通道的特征图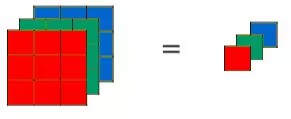
上图中左侧为输入图像的特征图(三通道),右侧为卷积核
2.3 池化层
作用是对卷积层输出的特征图进行下采样(降维压缩),在减少参数量和计算量的同时,增强特征的鲁棒性(对小幅度平移、缩放不敏感)
特点:
1.降维减参
卷积层输出的特征图空间尺寸较大(比如 224×224×64),直接送入全连接层会导致参 数量爆炸。池化层通过缩小特征图的高和宽,大幅减少后续层的计算量,同时避免模型 过拟合。
2.增强特征鲁棒性
池化会忽略特征图中的局部细节,只保留关键信息,让模型对输入的小幅度变化(比如 物体轻微平移、缩放)不敏感。
3.保留关键特征
池化操作不会改变特征图的通道数,每个通道的核心特征(如边缘、纹理)会被保留下 来,为后续层级的特征组合提供基础。
两种最常见的池化类型
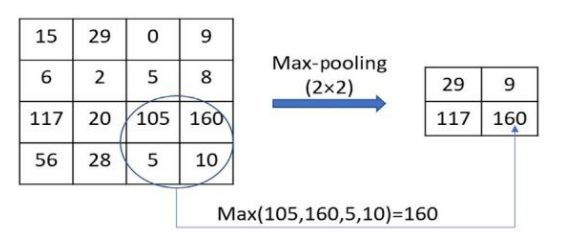
1. 最大池化(Max Pooling)
这是 CNN 中最常用的池化方式,核心规则是:在指定的局部窗口内,取最大值作为输 出。如下图所示
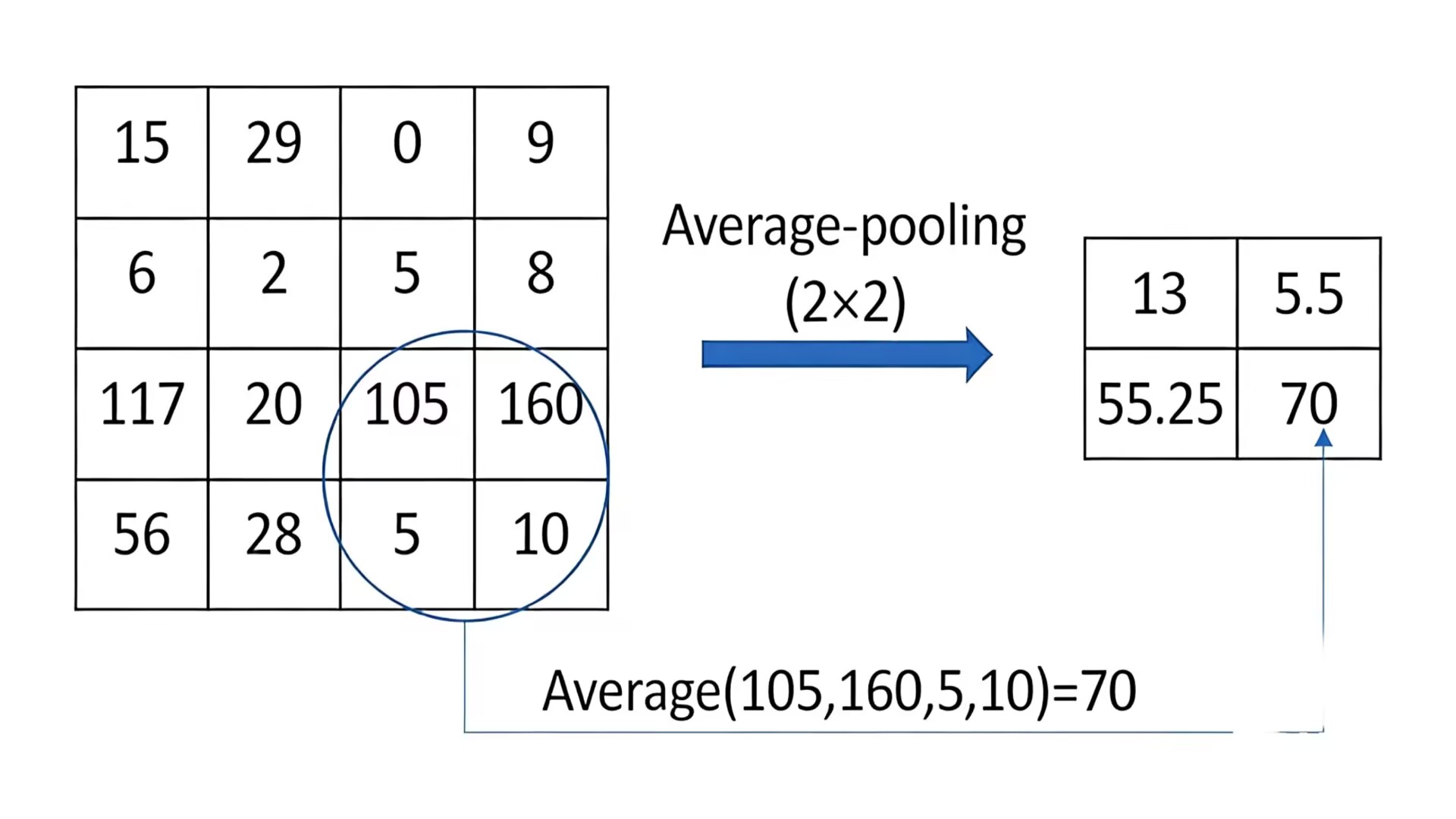
2. 平均池化(Average Pooling)
核心是:在指定的局部窗口内,取所有像素值的平均值作为输出。如下图所示
2.4 平铺层
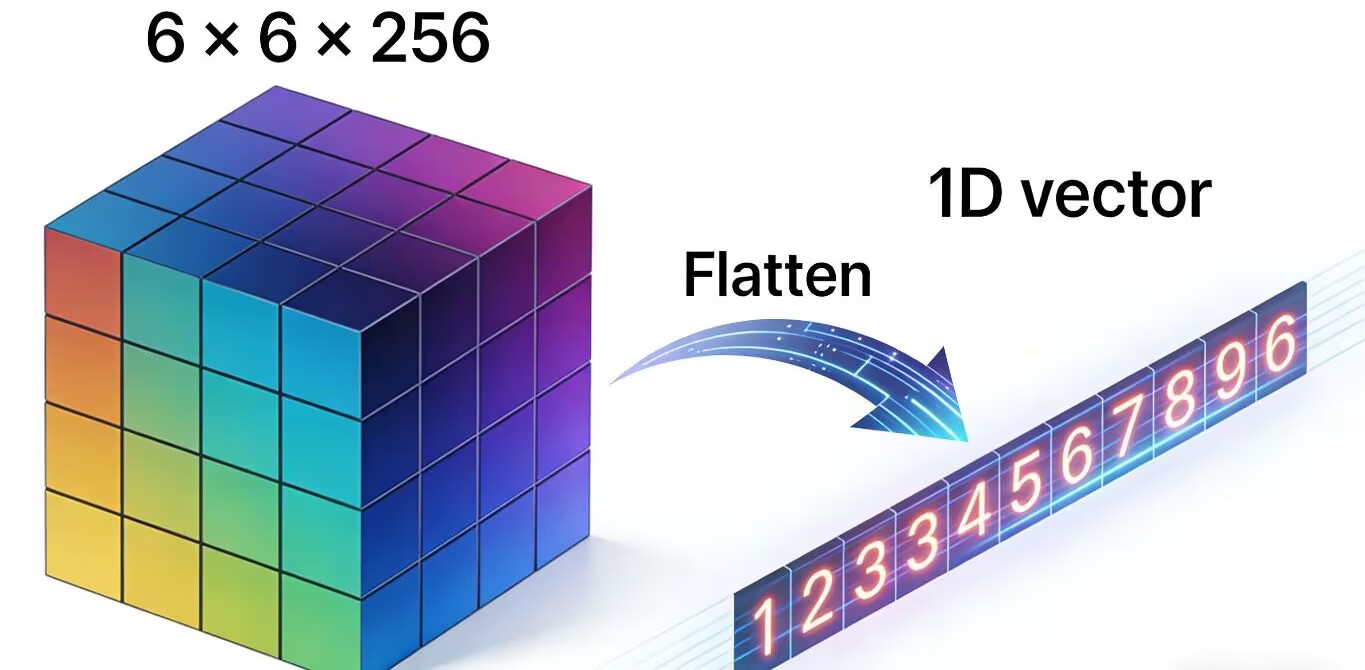
核心作用:维度转换
卷积层输出的是多维特征图,但全连接层(FC)只能处理一维向量。平铺层的任务就是:把 6×6×256 这样的多维数据,按顺序展开成 6×6×256 = 9216 维的一维向量,让全连接层能接收并处理。如下图所示
特点:
1.无参数:它不学习任何权重 / 偏置,只是做简单的重塑形状操作,不参与模型训练。
2.无计算:只是改变数据的 “排列方式”,不改变数据本身的数值。
3.位置固定:永远放在卷积层之后、全连接层之前,是二者的 “桥梁”。
2.5全连接层
是神经网络中负责特征整合与输出映射的核心层,其核心是通过线性变换(权重矩阵乘法 + 偏置)+ 非线性激活,将输入的一维特征向量映射为符合任务需求的输出向量。如下图所示
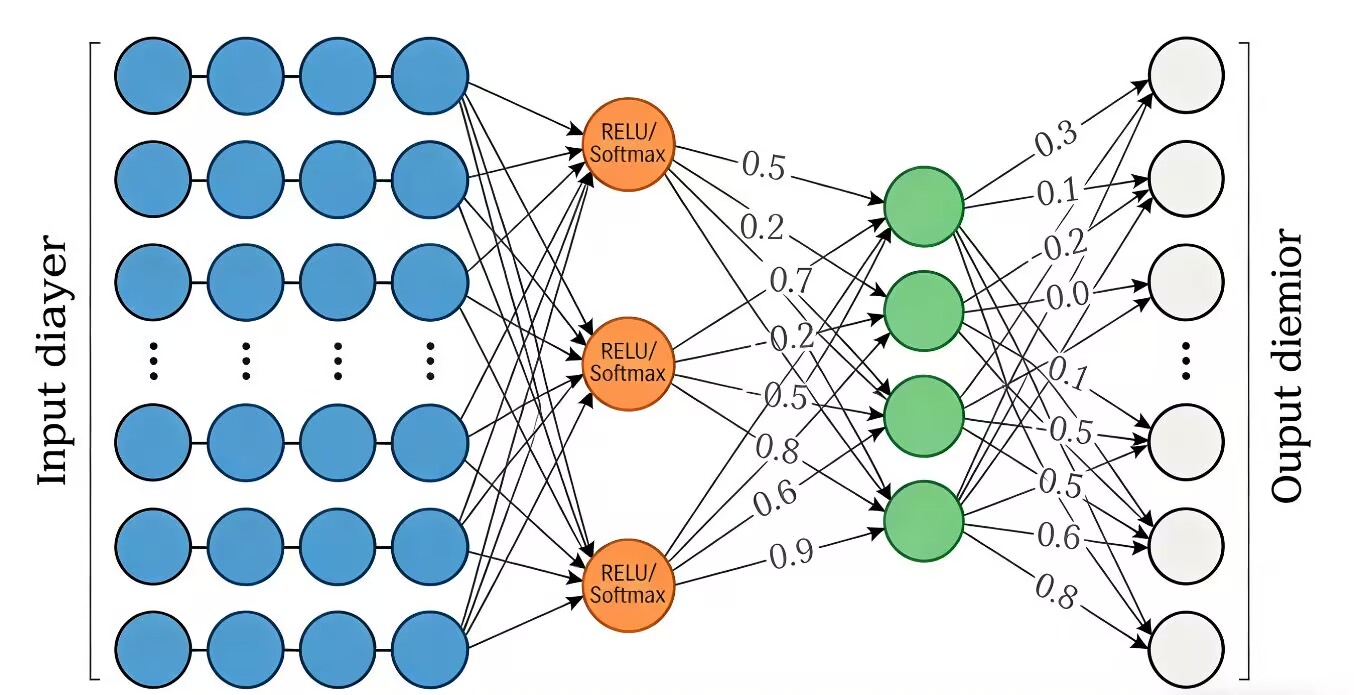
全连接层 = 橙色 “ReLU/Softmax” 节点 + 它与输入、输出之间的所有连线,这部分负责把输入特征通过权重加权和激活函数,映射成最终的输出结果。
2.6 输出层
它是网络的最后一层,有可学习参数(权重、偏置),负责把特征映射为任务结果。
神经元数量 = 任务的输出维度(比如 1000 分类 → 1000 个神经元;回归 → 1 个神 经元)
如:
图像分类 → 输出层是1000 个类别的概率(ImageNet)
二分类 → 输出层是2 个概率(猫的概率、狗的概率)
房价预测 → 输出层是1 个数值(预测的房价)
3.CNN经典模型LeNet-5全流程详解
整体结构概览
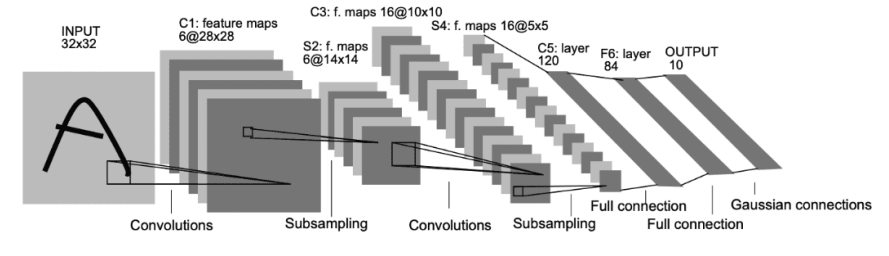
LeNet-5 是一个7 层网络(在统计网络层数时,输入层通常不算作 “可学习的网络层”: 只是数据入口,没有可学习的权重、偏置,也不做任何计算)
核心流程:输入图像 → 卷积(提取特征)→ 池化(降维:Subsampling)→ 卷积 → 池化 → 全连接(特征整合)→ 输出(分类)
输入:32×32 灰度图像(手写数字)
输出:10 维向量(对应 0-9 十个数字的概率)
1. 输入层(INPUT)
尺寸:32×32×1(灰度图像,单通道)
作用:作为网络的 “原材料”,传递给第一个卷积层。
2. C1:卷积层(Convolutions)
输入:32×32×1
输出:6@28×28(6个特征图,每个28×28)
卷积核:5×5,Stride = 1,Padding= 0(已知)
卷积核数量:6个(输出6个特征图)
3. S2:池化层(Subsampling)
输入:6@28×28
输出:6@14×14(6 个特征图,每个 14×14)计算:28 / 2 = 14
池化方式:平均池化(Avg Pooling),核 2×2,Stride = 2
4. C3:卷积层(Convolutions)
输入:6@14×14
输出:16@10×10(16 个特征图,每个 10×10)
卷积核:5×5,Stride = 1,Padding = 0
卷积核数量:16 个(输出 16 个特征图)
特殊设计:C3 并非全连接 S2 的 6 个特征图,而是部分连接(每个卷积核只连接 S2的部分 特征图),减少参数。
5. S4:池化层(Subsampling)
输入:16@10×10
输出:16@5×5(16 个特征图,每个 5×5)计算:10 / 2 = 5
平均池化,核 2×2,Stride = 2
6. C5:卷积层(Convolutions)
输入:16@5×5
输出:120(120 维向量)
卷积核:5×5,Stride = 1,Padding = 0
卷积核数量:120 个
注:C5 本质是全连接卷积层(输入尺寸与卷积核尺寸相同,等价于全连接)。
7. F6:全连接层(Full connection)
输入:120 维向量
输出:84 维向量
全连接:120 → 84
激活函数:Sigmoid
8. 输出层(OUTPUT)
输入:84 维向量
输出:10 维向量(对应 0-9 十个数字)
全连接:84 → 10
激活函数:高斯连接(Gaussian connections)
最终输出 10 个类别的概率,概率最大的即为识别结果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)