别让 AI “滥用” 资源!一文读懂 Agent 资源感知优化:分类路由、模型切换与成本控制全解析
Agent资源感知优化技术 资源感知优化使Agent能够动态监控和管理计算资源、时间和成本开销。与简单规划不同,该技术强调在资源约束下做出最优决策,通过权衡模型精度与成本来适应不同场景需求。典型应用包括:LLM成本优化(根据任务复杂度选择模型)、实时系统响应(优先速度而非完整性)、边缘计算能效管理等。文中提供了金融分析案例和代码实现,展示如何通过查询分类(简单/推理/网络搜索)动态选择处理路径,实
Agent的资源感知优化
现实世界的 Agent 系统必须经常根据偶然因素在多个潜在行动之间进行仲裁,例如环境状态、用户输入或前一操作的结果。这种动态决策能力,控制流向不同的专门函数、工具或子流程,是通过一种称为路由的机制实现的。
路由将条件逻辑引入 Agent 的操作框架,使其能够从固定执行路径转变为这样一种模型:Agent 动态评估特定标准以从一组可能的后续行动中进行选择。这允许更灵活和上下文感知的系统行为。
Agent的资源感知优化也是利用了这种路由机制。
路由模式的核心组件是执行评估并指导流程的机制。这种机制可以通过几种方式实现:
- 基于 LLM 的路由: 语言模型本身可以被提示分析输入并输出指示下一步或目的地的特定标识符或指令。例如,提示词可能要求 LLM “分析以下用户查询并仅输出类别:’订单状态’、’产品信息’、’技术支持’或’其他’。” Agent 系统然后读取此输出并相应地指导工作流。
- 基于嵌入的路由: 输入查询可以转换为向量嵌入(参见 RAG,第 14 章)。然后将此嵌入与代表不同路由或能力的嵌入进行比较。查询被路由到嵌入最相似的路由。这对于语义路由很有用,其中决策基于输入的含义而不仅仅是关键词。
- 基于规则的路由: 这涉及使用基于关键词、模式或从输入中提取的结构化数据的预定义规则或逻辑(例如,if-else 语句、switch case)。这可以比基于 LLM 的路由更快、更确定,但在处理细微或新颖输入方面的灵活性较差。
- 基于机器学习模型的路由: 它采用判别模型,例如分类器,该模型已经在小型标记数据语料库上专门训练以执行路由任务。虽然它与基于嵌入的方法在概念上有相似之处,但其关键特征是监督微调过程,该过程调整模型的参数以创建专门的路由功能。这种技术与基于 LLM 的路由不同,因为决策组件不是在推理时执行提示词的生成模型。相反,路由逻辑被编码在微调模型的学习权重中。虽然 LLM 可能在预处理步骤中用于生成合成数据以增强训练集,但它们不参与实时路由决策本身。
资源感知优化使得 Agent 能够在运行过程中动态监控和管理计算、时间和资源花费。这与简单的规划不同,后者主要关注动作序列的安排。资源感知优化要求 Agent 就动作执行做出决策,以在指定的资源预算内达成目标或优化效率。这涉及在更准确但昂贵的模型与更快速、成本更低的模型之间进行权衡,或者决定是否分配额外的计算资源以获得更精细的响应,还是返回更快但细节较少的答案。
例如,考虑一个被指派为金融分析师分析大型数据集的 Agent。如果分析师需要立即获得初步报告,Agent 可能会使用更快、更经济的模型来快速总结关键趋势。然而,如果分析师需要高度准确的预测用于关键投资决策,并且有更充裕的预算和时间,Agent 将分配更多资源来利用功能更强、速度较慢但更精确的预测模型。
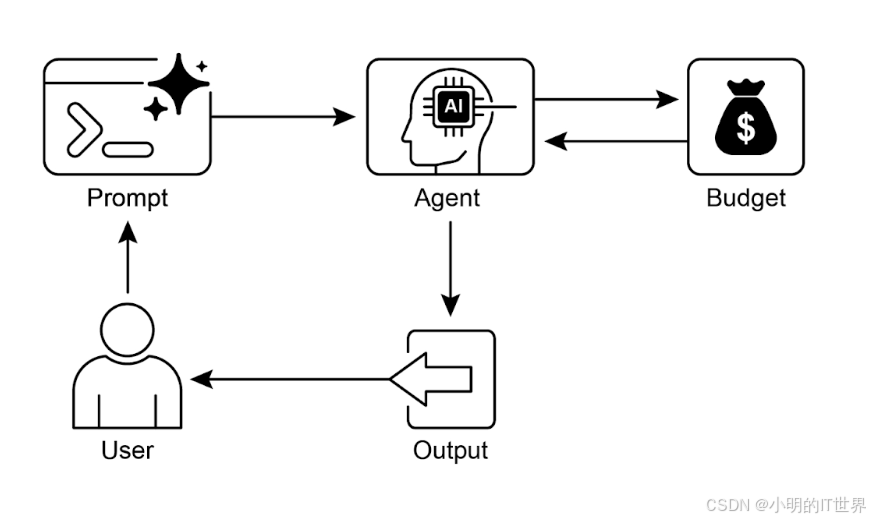
应用场景
- 成本优化的 LLM 使用:Agent 根据预算约束,决定是对复杂任务使用大型、昂贵的 LLM,还是对简单查询使用更小、更经济的 LLM。
- 延迟敏感操作:在实时系统中,Agent 选择更快但可能不够全面的推理路径以确保及时响应。
- 能源效率:对于部署在边缘设备或电力受限环境中的 Agent,优化其处理过程以延长电池寿命。
- 服务可靠性回退:当主要选择不可用时,Agent 自动切换到备用模型,确保服务连续性和优雅降级。
- 数据使用管理:Agent 选择摘要数据检索而非完整数据集下载,以节省带宽或存储空间。
- 自适应任务分配:在多 Agent 系统中,Agent 根据其当前计算负载或可用时间自行分配任务。
代码示例
代码可以在github上获取: code
该系统使用资源感知优化策略来高效处理用户查询。它首先将每个查询分类为三个类别之一,以确定最合适和最具成本效益的处理路径。这种方法避免在简单请求上浪费计算资源,同时确保复杂查询获得必要的关注。三个类别是:
- simple:用于可以直接回答而无需复杂推理或外部数据的简单问题。
- reasoning:用于需要逻辑推理或多步骤思考过程的查询,这些查询被路由到更强大的模型。
- internet_search:用于需要当前信息的问题,会自动触发 Google 搜索以提供最新答案
import os
import requests
import json
from dotenv import load_dotenv
from openai import OpenAI
# Load environment variables
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
GOOGLE_CUSTOM_SEARCH_API_KEY = os.getenv("GOOGLE_CUSTOM_SEARCH_API_KEY")
GOOGLE_CSE_ID = os.getenv("GOOGLE_CSE_ID")
if not OPENAI_API_KEY or not GOOGLE_CUSTOM_SEARCH_API_KEY or not GOOGLE_CSE_ID:
raise ValueError(
"Please set OPENAI_API_KEY, GOOGLE_CUSTOM_SEARCH_API_KEY, and GOOGLE_CSE_ID in your .env file."
)
client = OpenAI(api_key=OPENAI_API_KEY)
# --- Step 1: Classify the Prompt ---
def classify_prompt(prompt: str) -> dict:
system_message = {
"role": "system",
"content": (
"You are a classifier that analyzes user prompts and returns one of three categories ONLY:\n\n"
"- simple\n"
"- reasoning\n"
"- internet_search\n\n"
"Rules:\n"
"- Use 'simple' for direct factual questions that need no reasoning or current events.\n"
"- Use 'reasoning' for logic, math, or multi-step inference questions.\n"
"- Use 'internet_search' if the prompt refers to current events, recent data, or things not in your training data.\n\n"
"Respond ONLY with JSON like:\n"
'{ "classification": "simple" }'
),
}
user_message = {"role": "user", "content": prompt}
response = client.chat.completions.create(
model="gpt-4o", messages=[system_message, user_message], temperature=1
)
reply = response.choices[0].message.content
return json.loads(reply)
# --- Step 2: Google Search ---
def google_search(query: str, num_results=1) -> list:
url = "https://www.googleapis.com/customsearch/v1"
params = {
"key": GOOGLE_CUSTOM_SEARCH_API_KEY,
"cx": GOOGLE_CSE_ID,
"q": query,
"num": num_results,
}
try:
response = requests.get(url, params=params)
response.raise_for_status()
results = response.json()
if "items" in results and results["items"]:
return [
{
"title": item.get("title"),
"snippet": item.get("snippet"),
"link": item.get("link"),
}
for item in results["items"]
]
else:
return []
except requests.exceptions.RequestException as e:
return {"error": str(e)}
# --- Step 3: Generate Response ---
def generate_response(prompt: str, classification: str, search_results=None) -> str:
if classification == "simple":
model = "gpt-4o-mini"
full_prompt = prompt
elif classification == "reasoning":
model = "o4-mini"
full_prompt = prompt
elif classification == "internet_search":
model = "gpt-4o"
# Convert each search result dict to a readable string
if search_results:
search_context = "\n".join(
[
f"Title: {item.get('title')}\nSnippet: {item.get('snippet')}\nLink: {item.get('link')}"
for item in search_results
]
)
else:
search_context = "No search results found."
full_prompt = f"""Use the following web results to answer the user query:
{search_context}
Query: {prompt}"""
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": full_prompt}],
temperature=1,
)
return response.choices[0].message.content, model
# --- Step 4: Combined Router ---
def handle_prompt(prompt: str) -> dict:
classification_result = classify_prompt(prompt)
# Remove or comment out the next line to avoid duplicate printing
# print("\n🔍 Classification Result:", classification_result)
classification = classification_result["classification"]
search_results = None
if classification == "internet_search":
search_results = google_search(prompt)
# print("\n🔍 Search Results:", search_results)
answer, model = generate_response(prompt, classification, search_results)
return {"classification": classification, "response": answer, "model": model}
这段 Python 代码实现了一个提示词路由系统来回答用户问题。
- 它首先从 .env 文件加载 OpenAI 和 Google 自定义搜索的必要 API 密钥。核心功能在于将用户的提示词分类为三个类别:simple、reasoning 或 internet search。classify_prompt这个函数利用 OpenAI 模型进行此分类步骤。
- 如果提示词需要当前信息,则使用 Google 自定义搜索 API 执行 Google 搜索。
- generate_response函数然后生成最终响应,根据分类选择适当的 OpenAI 模型。对于互联网搜索查询,搜索结果作为上下文提供给模型。
- handle_prompt 函数编排此工作流,在生成响应之前调用分类和搜索(如果需要)函数。它返回分类、使用的模型和生成的答案。
该系统有效地将不同类型的查询引导到优化的方法以获得更好的响应。
运行结果
- 简单查询
test_prompt = "What is the capital of Australia?"
# test_prompt = "Explain the impact of quantum computing on cryptography."
# test_prompt = "When does the Australian Open 2026 start, give me full date?"
result = handle_prompt(test_prompt)
print("🔍 Classification:", result["classification"])
print("🧠 Model Used:", result["model"])
print("🧠 Response:\n", result["response"])
输出:
🔍 Classification: simple
🧠 Model Used: gpt-4o-mini
🧠 Response:
The capital of Australia is Canberra.
- 通过fuction calling使用外部工具的查询:
# test_prompt = "What is the capital of Australia?"
test_prompt = "When does the Australian Open 2026 start, and when does it end, give me full date with year?"
# test_prompt = "Explain the impact of quantum computing on cryptography."
result = handle_prompt(test_prompt)
print("🔍 Classification:", result["classification"])
print("🧠 Model Used:", result["model"])
print("🧠 Response:\n", result["response"])
输出:
🔍 Classification: internet_search
🧠 Model Used: gpt-4o
🧠 Response:
The Australian Open 2026 starts on 12 January 2026 and ends on 1 February 2026.
3.复杂的查询:
# test_prompt = "What is the capital of Australia?"
# test_prompt = "When does the Australian Open 2026 start, give me full date?"
test_prompt = "Explain the impact of quantum computing on cryptography."
result = handle_prompt(test_prompt)
print("🔍 Classification:", result["classification"])
print("🧠 Model Used:", result["model"])
print("🧠 Response:\n", result["response"])
输出:
🔍 Classification: reasoning
🧠 Model Used: o4-mini
🧠 Response:
Quantum computers leverage quantum‐mechanical phenomena—superposition and entanglement—to solve certain problems far more efficiently than classical machines. That efficiency has direct implications for today’s public‐key and even some symmetric cryptosystems. Here’s how quantum computing impacts cryptography and how the field is responding:
1. Threat to Public‐Key Cryptography
• Shor’s Algorithm (1994)
– Efficiently factors large integers and computes discrete logarithms in polynomial time.
– Breaks RSA, Diffie–Hellman, ElGamal and elliptic‐curve schemes (all rely on the hardness of factoring or discrete log).
• Timeline and Practicality
– Large‐scale, fault-tolerant quantum computers needed (likely thousands to millions of error-corrected qubits).
– Estimates vary, but many experts consider public-key systems in critical infrastructure at risk within 10–20 years if quantum advances continue.
2. Effect on Symmetric Cryptography
• Grover’s Algorithm (1996)
– Searches an unstructured database of N items in O(√N) time rather than O(N).
– Roughly halves the effective key length: a 128-bit key offers ≈64-bits of security against a full-scale quantum attacker.
• Mitigation
– Doubling key sizes (e.g. AES-256) restores security margins against quantum‐accelerated brute force.
3. Post‐Quantum (Quantum-Resistant) Cryptography
• Goal: Find classical algorithms for key exchange, signatures and encryption that remain hard even for quantum adversaries.
• Leading Approaches (NIST PQC finalists and others)
– Lattice-based cryptography (e.g. Learning With Errors, NTRU)
– Code-based cryptography (e.g. McEliece)
– Multivariate polynomial cryptography
– Hash-based signatures (e.g. XMSS, SPHINCS+)
– Isogeny-based cryptography (e.g. SIKE—though recent breaks illustrate ongoing research)
• Standardization and Transition
– NIST is in the process of standardizing several post-quantum algorithms (expected 2024–2025).
– Transition requires software and hardware updates, interoperability testing, and phased rollouts (much like the shift from SHA-1 to SHA-2/3).
4. Quantum Key Distribution (QKD)
• Uses quantum states (typically photons) to establish symmetric keys with information‐theoretic security.
• Eavesdropping detection: Any measurement disturbs the quantum states, alerting legitimate parties.
• Challenges: distance limitations, integration into existing networks, high costs.
5. Practical Considerations and Timelines
• “Harvest-Now, Decrypt‐Later” Attacks
– Adversaries may record encrypted traffic today with the hope of decrypting it once a quantum computer is available.
– Drives urgency for deploying quantum-resistant algorithms in long-lived systems.
• Hybrid Schemes
– Combine classical and post-quantum cryptography in parallel to ensure security even if one component is broken.
6. Summary of Impacts
• Public-key cryptography as we know it (RSA, ECC) will be vulnerable to sufficiently powerful quantum computers.
• Symmetric cryptography is less threatened but should use larger keys to counter Grover’s speed-up.
• The industry is actively developing, standardizing and deploying post-quantum algorithms.
• QKD offers an alternative paradigm for secure key exchange but faces practical hurdles.
• Organizations must plan migrations to quantum-safe systems now to protect long-term confidentiality.
In short, quantum computing represents both a potent threat to current cryptographic infrastructures and a catalyst for innovation in quantum-resistant and quantum-enhanced security technologies.
OpenRouter
对于这种资源感知的Router,已有现成的商业服务: OpenRouter 网站(https://openrouter.ai/),可以直接使用其API来实现路由功能。它提供了统一的API接口来对接上百个模型,自动选择最有性价比的模型同时自动处理回退。
除此之外还有很多类似的项目:
- 阿里的higress(https://higress.ai)
- vLLM社区的semantic-router(https://vllm-semantic-router.com/roadmap/v0.1/)
结论
资源感知优化对于智能 Agent 的开发至关重要,使其能够在现实世界约束内高效运行。通过管理计算、时间和资源预算,Agent 可以实现最佳性能和成本效益。动态模型切换、自适应工具使用和上下文修剪等技术对于实现这些效率至关重要。高级策略,包括学习型资源分配策略和优雅降级,增强了 Agent 在不同条件下的适应性和弹性。将这些优化原则集成到 Agent 设计中对于构建可扩展、强大和可持续的 AI 系统至关重要。
更多精彩内容,关注微信公众号 小明的IT世界
阅读更多

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)