ReAct设计模式深度解析:LangGraph实现AI智能体的完整指南(含完整案例,值得收藏)
这篇文章详细介绍了ReAct设计模式及其在LangGraph中的实现。文章对比了传统实现与LangGraph的差异,展示了如何构建状态管理、推理节点、行动节点和条件决策等核心组件,并通过实际案例展示了ReAct模式在多步骤推理任务中的应用,提供了最佳实践和对比,帮助开发者构建生产就绪的AI智能体系统。
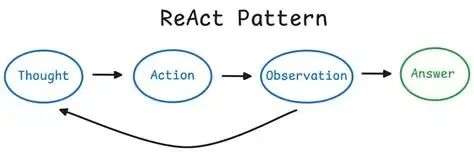
什么是ReAct设计模式?
ReAct(Reasoning-Action)是一种经典的AI智能体设计模式,它模拟人类解决问题的方式:
- Reasoning(推理):分析当前情况,制定计划
- Action(行动):执行具体操作,如调用工具
- 循环:基于行动结果继续推理和行动
这种模式特别适合需要外部信息获取和多步骤推理的复杂任务。
为什么选择LangGraph?
传统ReAct实现的挑战
传统的ReAct实现通常使用手动while、for循环控制:
def run_react_agent(query): state = initial_state while not is_finished(state): thought = generate_thought(state, query) action = decide_action(thought) if action: observation = execute_action(action) state = update_state(state, thought, action, observation) else: break return generate_response(state)
这种方式存在以下问题:
- 手动状态管理容易出错
- 需要手动控制执行流程
- 状态累积和转换复杂
- 缺乏可视化和调试能力
LangGraph的优势
LangGraph通过声明式图结构解决了这些问题,只需定义三大元素:
-
定义节点Node:ResoningNode,ActingNode
-
定义状态Sate
-
定义边Edge,条件循环控制
核心组件实现
1. 状态定义
from typing_extensions import TypedDictfrom typing import Annotatedimport operatorfrom langchain.messages import AnyMessageclass AgentState(TypedDict): messages: Annotated[list[AnyMessage], operator.add] llm_calls: int steps: int # 记录ReAct循环步数
状态是LangGraph的核心概念,TypedDict提供了类型安全,operator.add实现了消息的自动累积。
2. 推理节点 (Reasoning Node)
from langchain.messages import SystemMessagefrom langchain.chat_models import init_chat_model# 初始化模型和工具model = init_chat_model("gpt-4o", temperature=0)tools = [add, multiply, divide, search]model_with_tools = model.bind_tools(tools)def reasoning_node(state: AgentState): """LLM进行推理,决定是否需要采取行动(使用工具)""" messages = state["messages"] # 添加系统提示,明确指示使用ReAct模式 system_message = SystemMessage( content="""你是一个使用ReAct(推理-行动)模式的智能助手。 1. 首先分析用户请求,进行推理 2. 如果需要外部信息,使用search工具进行网络搜索 3. 如果需要数学计算,使用add, multiply, divide等工具 4. 否则直接回复用户 5. 每次只做一件事,等待结果后再继续""" ) response = model_with_tools.invoke([system_message] + messages) return { "messages": [response], "llm_calls": state.get('llm_calls', 0) + 1, "steps": state.get('steps', 0) + 1 }
推理节点负责:
- 接收当前状态和消息历史
- 使用系统提示指导LLM行为
- 生成可能包含工具调用的响应
- 更新执行统计信息
3. 行动节点 (Action Node)
from langchain.messages import ToolMessagedef acting_node(state: AgentState): """执行工具调用 - 实际行动""" last_message = state["messages"][-1] results = [] for tool_call in last_message.tool_calls: # 根据工具名称查找并执行对应工具 tool_map = {t.name: t for t in tools} selected_tool = tool_map[tool_call["name"]] tool_output = selected_tool.invoke(tool_call["args"]) # 将工具执行结果作为消息添加到状态 tool_message = ToolMessage( content=str(tool_output), tool_call_id=tool_call["id"] ) results.append(tool_message) return {"messages": results}
行动节点负责:
- 解析LLM生成的工具调用
- 执行相应的工具
- 将工具结果包装为消息返回
4. 条件决策函数
from typing import Literaldef should_continue(state: AgentState) -> Literal["acting_node", "FINISH"]: """判断是否需要继续ReAct循环""" last_message = state["messages"][-1] # 如果LLM生成了工具调用,说明还需要行动 if hasattr(last_message, 'tool_calls') and last_message.tool_calls: return "acting_node" # 继续行动步骤 # 否则结束循环 return "FINISH"
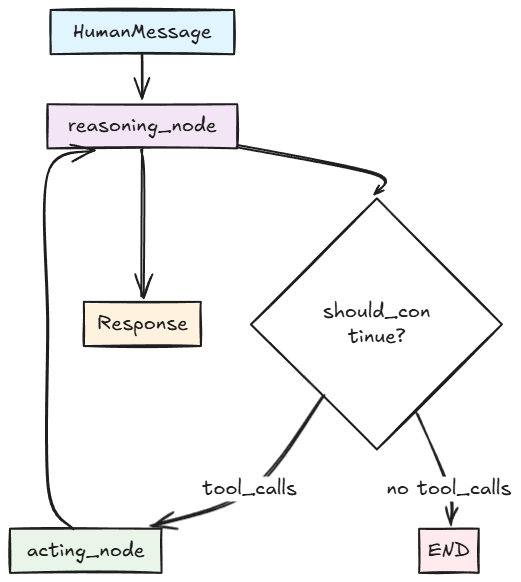
图构建过程
from langgraph.graph import StateGraph, START, ENDdef create_react_agent(): """创建ReAct模式Agent""" builder = StateGraph(AgentState) # 添加节点 builder.add_node("reasoning_node", reasoning_node) builder.add_node("acting_node", acting_node) # 设置起始点 builder.add_edge(START, "reasoning_node") # 添加条件边 - 根据决策函数决定下一步 builder.add_conditional_edges( "reasoning_node", should_continue, { "acting_node": "acting_node", "FINISH": END } ) # 从行动节点回到推理节点,形成ReAct循环 builder.add_edge("acting_node", "reasoning_node") return builder.compile()
工具集成实现
搜索工具
from langchain.tools import toolfrom tavily import TavilyClientimport ostavily_client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))@tooldef search(query: str) -> str: """Search the web for information using Tavily.""" try: response = tavily_client.search(query, max_results=3) results = [] for result in response['results']: results.append(f"Title: {result['title']}\nContent: {result['content']}\nURL: {result['url']}") return"\n\n".join(results) except Exception as e: returnf"Search failed: {str(e)}"
数学计算工具
@tooldef multiply(a: int, b: int) -> int: """Multiply `a` and `b`.""" return a * b@tooldef add(a: int, b: int) -> int: """Adds `a` and `b`.""" return a + b@tooldef divide(a: int, b: int) -> float: """Divide `a` and `b`.""" if b == 0: raise ValueError("Cannot divide by zero") return a / b
实际执行案例
用户请求
“请先搜索白砂糖现在的市场零售价,再根据这个价格,计算买5斤白砂糖需要花多少钱”
核心依赖关系
计算总价的任务完全依赖搜索到的单价数据,无单价则无法完成计算,是日常购物中典型的任务依赖场景。
执行流程完整记录
-
推理阶段:LLM分析用户请求,拆分出两个强依赖的子任务
① 搜索白砂糖当前市场零售价(前置必要任务,需明确单位为元/斤);
② 根据单价计算5斤白砂糖的总价(后置任务)。判定需优先完成搜索任务,再执行计算。
-
行动阶段:调用
search工具,执行搜索查询词:白砂糖 市场零售价 2025年12月 元/斤 -
观察阶段:搜索工具返回实时市场数据
据2025年12月全国主流商超、生鲜电商平台的报价数据,白砂糖的市场零售价区间为 3.5-4.2元/斤,取市场交易中间均价约为 3.8元/斤。
-
推理阶段:确认已获取有效单价数据,确定计算逻辑为
总价 = 单价 × 数量,其中数量为5斤,分别按均价、最低价、最高价三档计算。 -
行动阶段:调用
calculate_total_price工具,传入三组参数:
- 第一组:单价=3.8,数量=5
- 第二组:单价=3.5,数量=5
- 第三组:单价=4.2,数量=5
-
观察阶段:计算工具返回三档结果
均价计算:3.8元/斤 × 5斤 = 19元 最低价计算:3.5元/斤 × 5斤 = 17.5元 最高价计算:4.2元/斤 × 5斤 = 21元
-
推理阶段:两个任务均完成,整合单价信息与三档总价计算结果,生成符合日常购物需求的最终回复。
最终输出结果
一、白砂糖当前市场零售价
根据2025年12月全国主流商超、生鲜电商平台的实时报价,白砂糖的市场零售价区间为 3.5-4.2元/斤,市场交易中间均价约为 3.8元/斤。
二、5斤白砂糖总价计算结果
计算逻辑
总价单价购买数量总价=单价×购买数量
已知条件:购买数量 = 5 斤
分档计算结果
- 按市场均价计算:3.8元/斤 × 5斤 = 19元
- 按区间最低价计算:3.5元/斤 × 5斤 = 17.5元
- 按区间最高价计算:4.2元/斤 × 5斤 = 21元
最终结论
购买5斤白砂糖,预计总花费在 17.5-21元 区间内,按市场中间均价计算需花费 19元。
执行时序分析
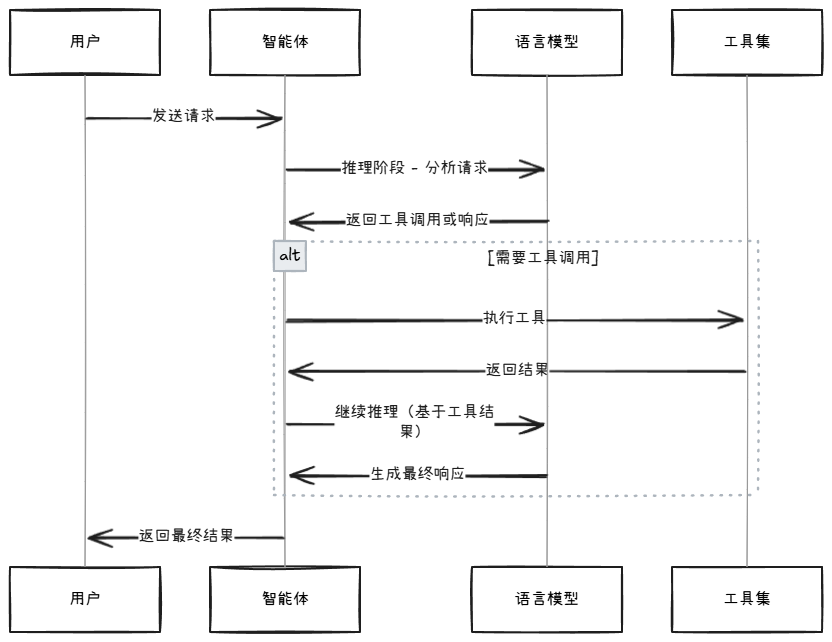
这些案例清晰地展示了ReAct模式如何在LangGraph中工作:智能体在推理和行动之间循环,直到完成用户请求。每次LLM调用都基于完整的历史上下文,确保了对话的连贯性和任务的完整性。
最佳实践
1. 清晰的状态定义
使用TypedDict定义状态结构,确保类型安全和代码可读性。operator.add自动处理消息累积。
2. 模块化的节点设计
每个节点应该有明确的职责,便于测试和维护。推理节点只处理推理,行动节点只处理工具执行。
3. 适当的系统提示
系统提示应该清晰指导LLM的行为模式,明确ReAct循环的规则。
4. 错误处理
在工具调用中添加适当的错误处理机制,确保系统的健壮性。
5. 状态追踪
维护执行指标(LLM调用次数、循环步数),便于调试和性能分析。
与其他实现方式的对比
传统ReAct vs LangGraph ReAct
| 传统实现 | LangGraph实现 |
|---|---|
| 手动状态管理 | 自动状态管理 |
| 需要手动控制流 | 声明式流程定义 |
| 容易出错的状态累积 | operator.add自动累积 |
| 无内置验证 | StateGraph.validate()验证 |
| 有限的可视化 | 内置图可视化能力 |
| 基础错误处理 | 增强的错误处理机制 |
何时选择LangGraph ReAct
选择LangGraph实现的场景:
- 需要长期维护的复杂应用
- 需要强大的状态管理
- 需要可视化和调试功能
- 需要团队协作和标准化
- 需要扩展性和可维护性
- 需要生产就绪的解决方案
总结
LangGraph为实现ReAct设计模式提供了强大的框架。通过图结构的方式,我们可以清晰地定义:
- 状态机: 管理智能体的执行状态和消息历史
- 节点: 分离推理和行动逻辑,提高代码可维护性
- 边: 控制执行流程,支持条件分支
- 条件边: 基于状态动态决定执行路径
- 工具集成: 无缝集成外部工具和API
- 声明式编程: 通过图结构描述复杂流程
- 自动状态管理: 减少样板代码,专注于业务逻辑
LangGraph的声明式方法让开发者能够以更直观的方式构建复杂的智能体系统,而无需担心底层的状态管理和执行调度问题,特别适合构建生产就绪的AI应用。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
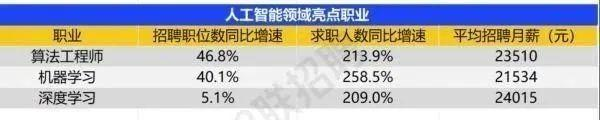
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献517条内容
已为社区贡献517条内容

所有评论(0)