大模型token究竟是啥?
本文通俗地解释了大模型中 "token" 的概念。Token 是大模型处理文本时切分成的最小单元,可以是单个字、词语、标点符号,甚至是词缀。分词器的作用是将文本拆解成 token,并赋予每个 token 一个数字编号,方便大模型进行计算和处理。不同的分词器分词方法不同,token 的划分结果也会有所差异。大模型通过计算 token 之间的关系来理解和生成文本,因此 token 的数量也直接关系到计
·
大模型token究竟是啥?
🤖 大模型 Token 究竟是啥?
🏷️ Token:大模型的基本单位
-
大模型的 Token 究竟是什么?简单来说,像 GPT 这样的大语言模型,背后都有一个“刀法精湛”的小弟,叫做分词器。当大模型接收到一段文字,分词器会把它切分成很多小块,每一个小块就叫做一个 Token。
-
一段话在大模型里可能会被切成这样:
- 单个的汉字可能是一个 Token
- 两个汉字构成的词语也可能是一个 Token
- 三个字构成的常见短语也可能是一个 Token
- 一个标点符号也可能是一个 Token
- 一个单词或者几个字母组成的一个词缀也可能是一个 Token
-
大模型在输出文字的时候,也是一个 Token 一个 Token 地往外“蹦”,所以看起来像在打字一样。
💡 Token 概念释疑
- Token 为什么可以是一个字,又可以是两个字,还可以是三个字,甚至是一个单词或半个单词呢?
- 换个方式解释:快速念几个单独的字:“旯妁圳侈”。是不是有点没认出来,或者需要愣两秒?但如果这些字出现在词语或成语里,你瞬间就能念出来。
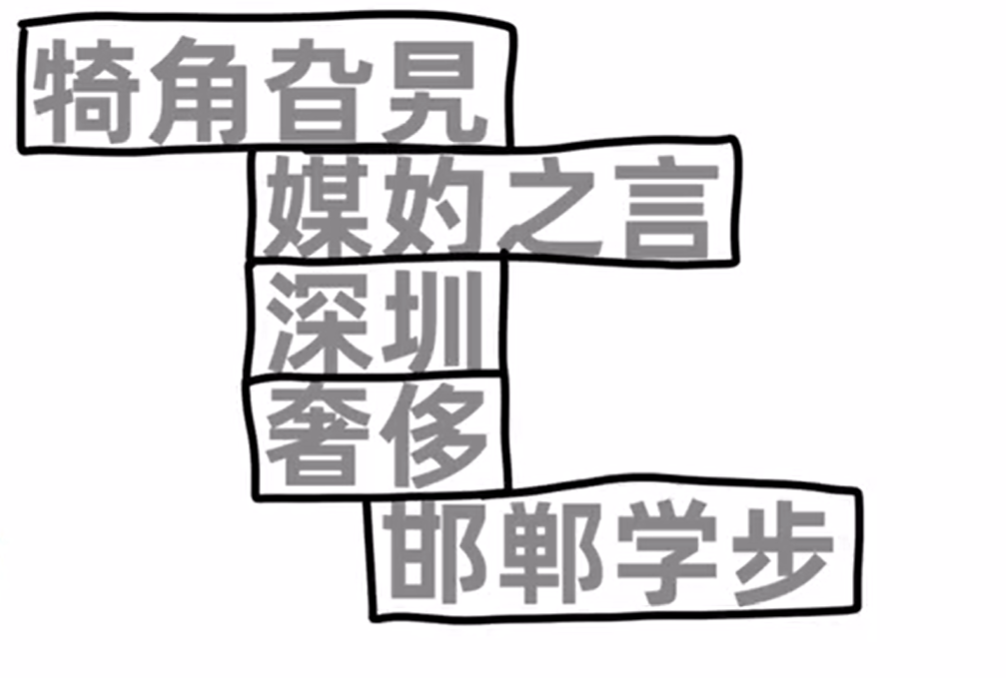
- 这是因为我们的大脑在日常生活中,喜欢把有含义的词语或短语优先作为一个整体来对待,不到万不得已不会一个字一个字地抠。这导致我们对这些词语很熟悉,但单看这些字却有点陌生。
- 大脑之所以这么做,是因为这样可以节省脑力。
🧠 大脑与 AI 分词
- 比如,“今天天气不错”这句话,如果一个字一个字地处理,一共需要有六个部分。但如果划分成三个常见且有意义的词,就只需要处理三个部分之间的关系,从而提高效率,节省脑力。
- 既然人脑可以这么做,那人工智能当然也可以。所以就有了分词器,专门帮大模型把大段的文字拆解成大小合适的 Token。
- 不同的分词器,分词方法和结果当然不一样。分的越合理,大模型就越轻松。这就好比餐厅里负责切菜的切配工,刀工越好,主厨做起菜来当然就越省事。
🍎 分词器简述
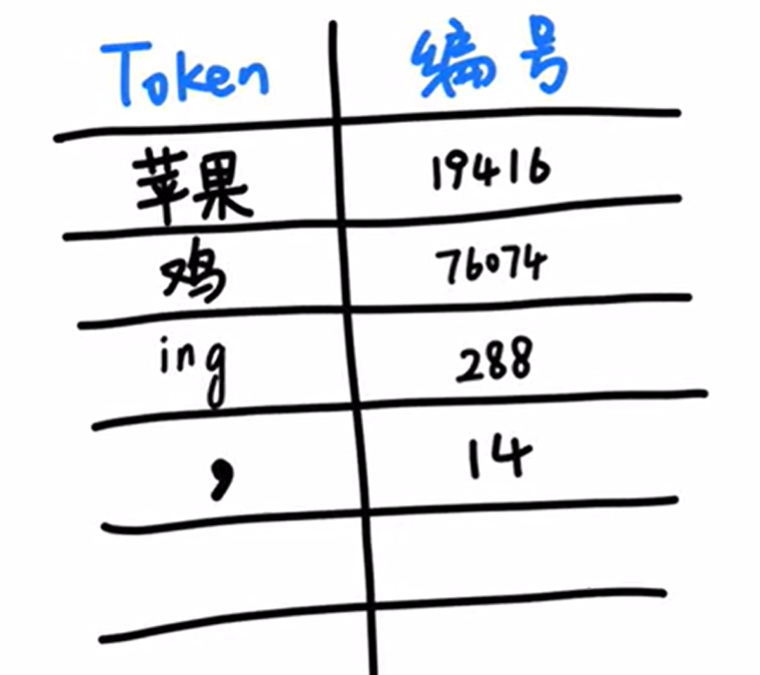
- 分词器是怎么分词的呢?其中一种方法是:分词器统计了大量文字以后,发现“苹果”这两个字经常一起出现,就把它们打包成一个 Token,给它一个数字编号,然后丢到一个大的词汇表里。这样下次再看到“苹果”这两个字,直接认出这个组合就可以了。

- 然后,它可能又发现“鸡”这个字经常出现,并且可以搭配不同的其他字。于是就把“鸡”这个字打包成一个 Token,配一个编号,并且丢到词汇表里。
- 它又发现“I”、“G”这三个字母经常一起出现,于是又把“I”、“G”打包成一个 Token,配一个编号,收录到表里去。
- 它又发现逗号经常出现,于是把逗号也作为一个 Token,给它一个编号,收录到表里去。
🏷️ Token 化简述
- 经过大量统计和收集,分词器就可以得到一个庞大的 Token 表,可能有 5 万个、10 万个甚至更多。Token 可以囊括我们日常见到的各种字词、符号等等。
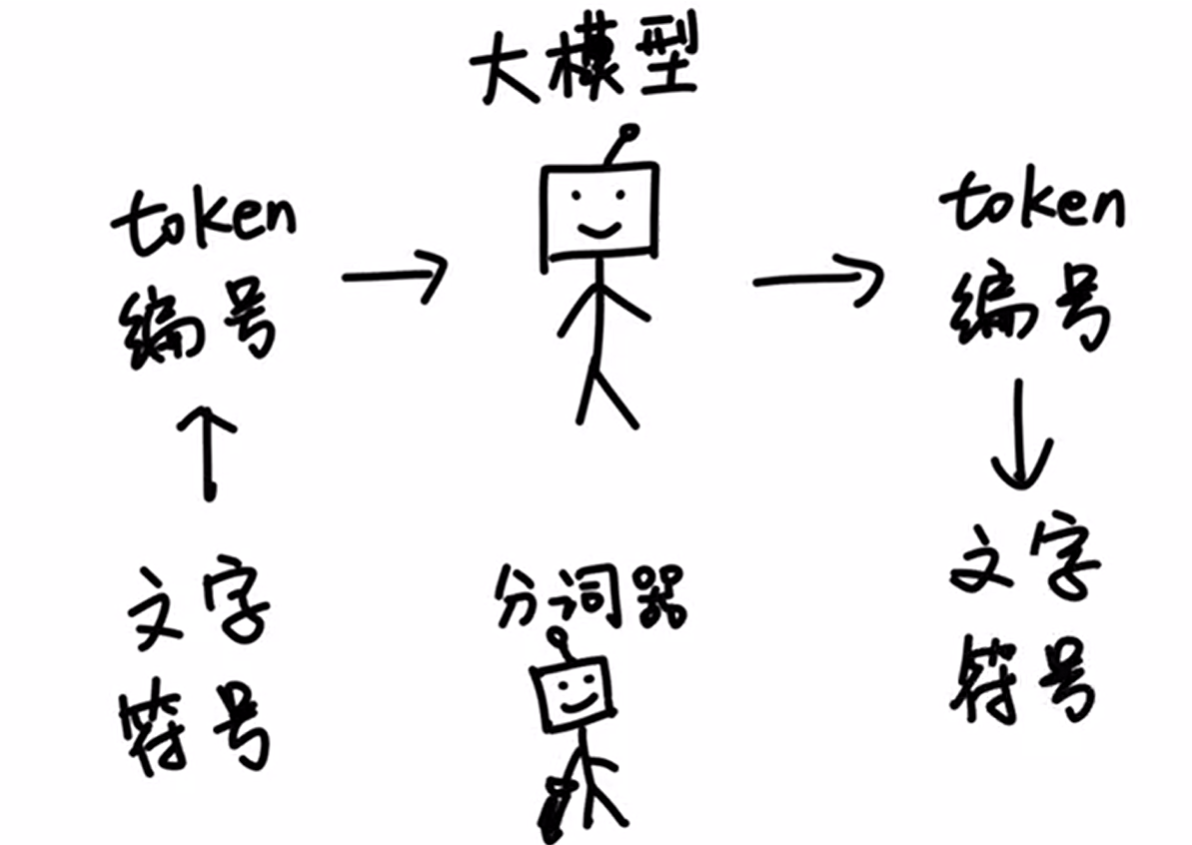
- 这样一来,大模型在输入和输出的时候,都只需要面对一堆数字编号就可以了,再由分词器按照 Token 表转换成人类可以看懂的文字和符号。这样一分工,工作效率就非常的高。
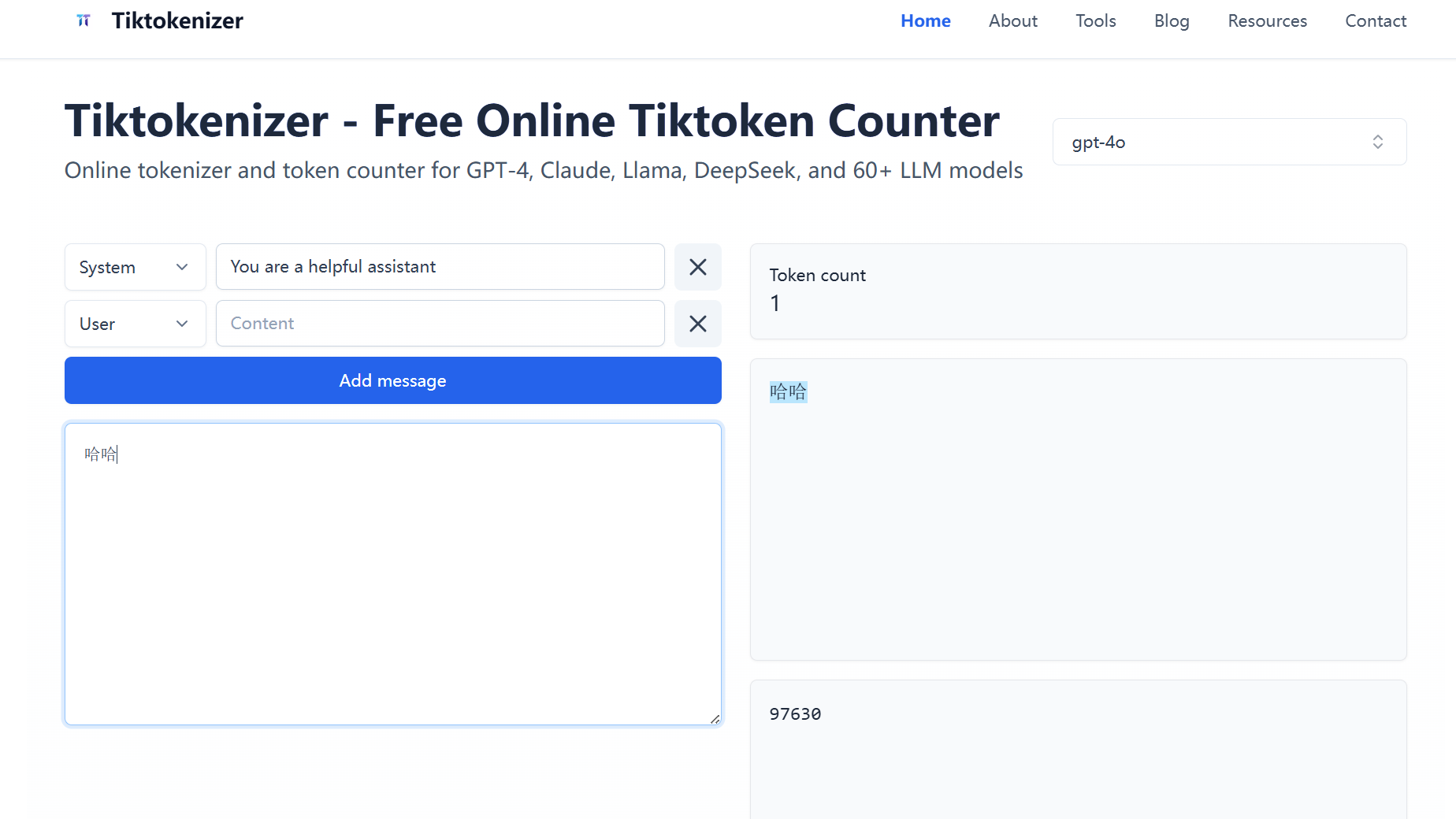
 有一些网站[Tiktokenizer - Free Online Tiktoken Counter & Tokenizer Tool | GPT-4, Claude, Llama],输入一段话,它就可以告诉你这段话是由几个 Token 构成,分别是什么,以及这几个 Token 的编号分别是什么。- 例如:
有一些网站[Tiktokenizer - Free Online Tiktoken Counter & Tokenizer Tool | GPT-4, Claude, Llama],输入一段话,它就可以告诉你这段话是由几个 Token 构成,分别是什么,以及这几个 Token 的编号分别是什么。- 例如:
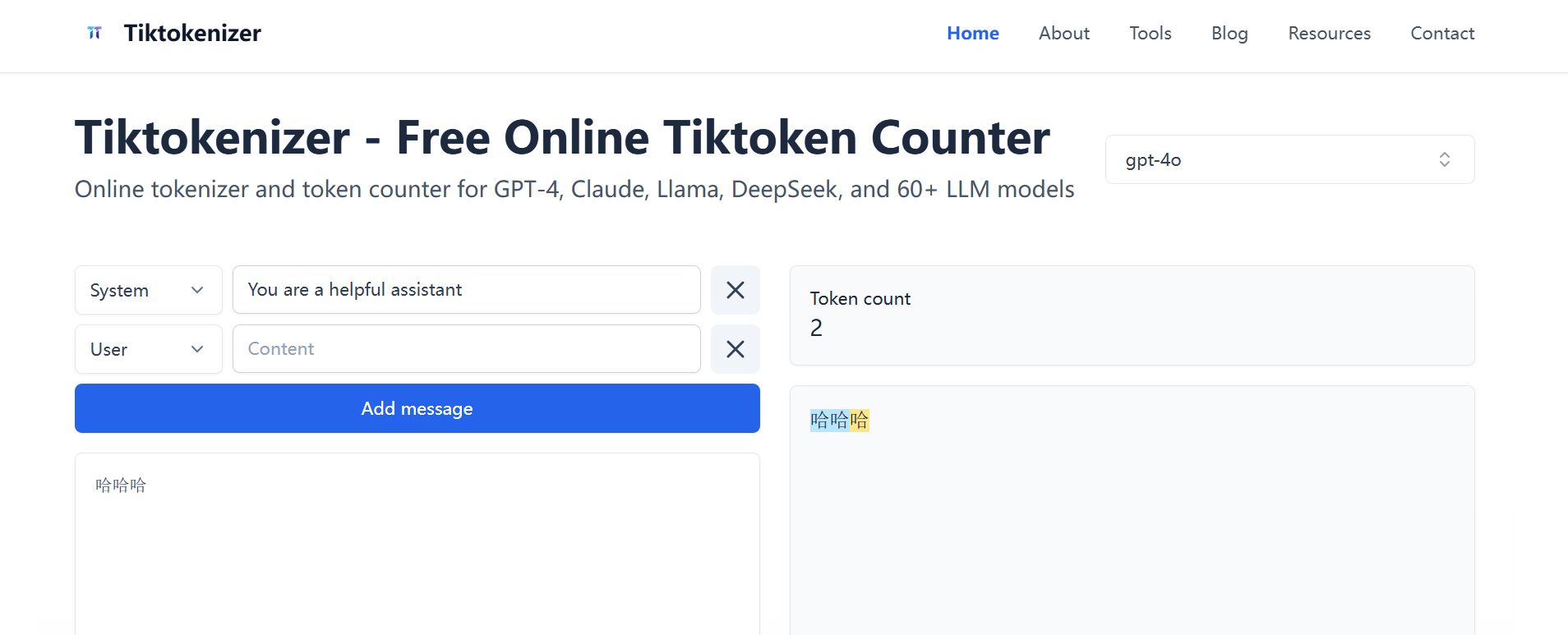
- “哈哈”是一个 Token
- “哈哈哈”是两个 Token
- “一心一意”是四个 Token
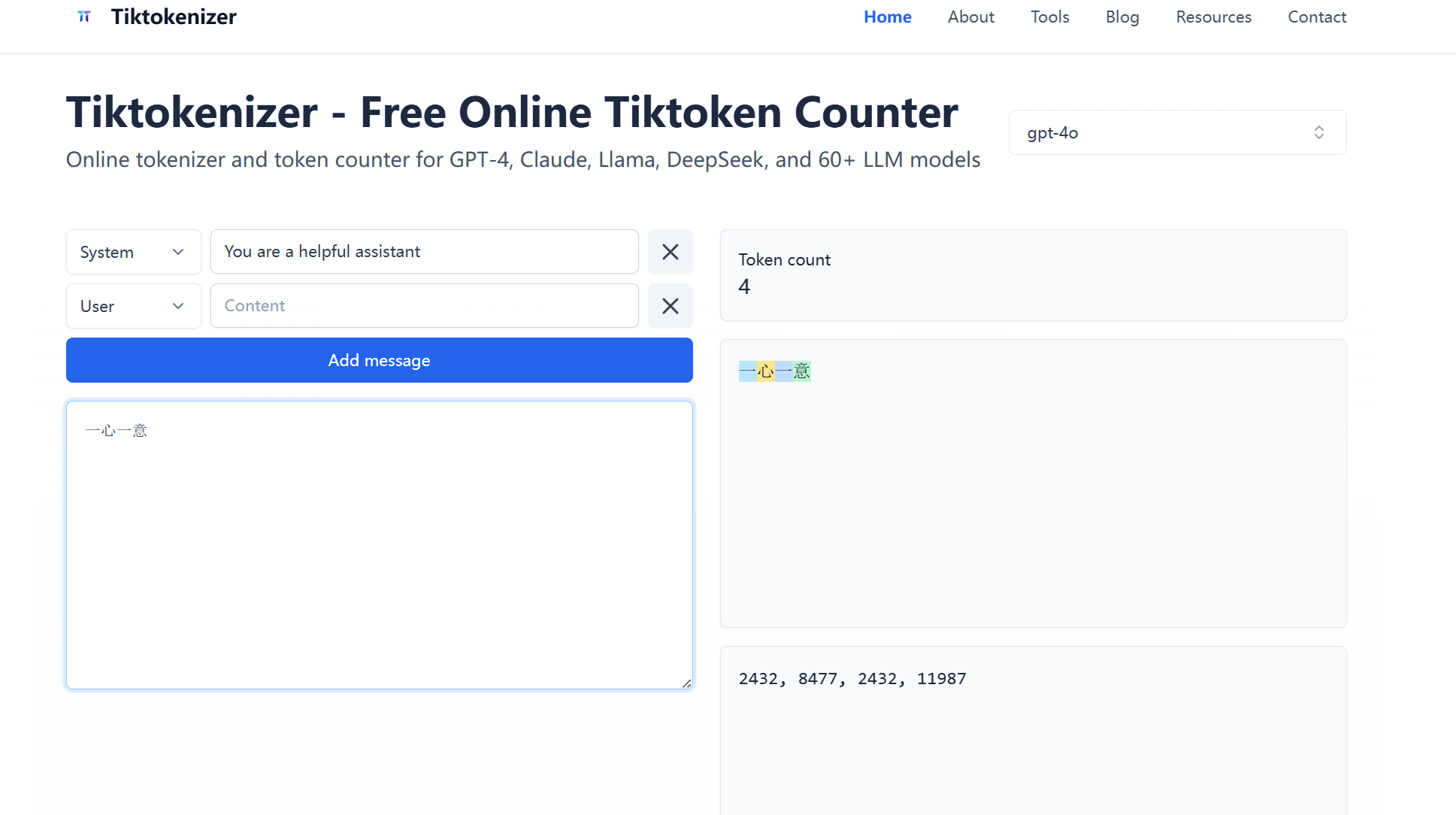
- 另外,不同的模型分词的结果可能会不同。比如“苹果的瓶子”在某个模型里是两个 Token,但在另一个模型里却是一个 Token。
🔑 Token 迷思
- Token 就是大模型世界里的一块块积木。大模型之所以可以理解和生成文字,就是靠计算这些 Token 之间的关系来推算出下一个 Token 最有可能是哪一个。
- 这也是为什么几乎所有大模型公司都是按照 Token 的数量来计费,因为 Token 的数量对应了背后的计算量。
- 最后,Token 这个词在人工智能领域之外的其他领域也经常出现。大家可以理解为只是碰巧都叫 Token 这个名字而已。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)