代码助手开发全攻略:让大模型真正理解你的代码库
文章详解构建专业代码助手的四大核心组件:代码解析(基于AST而非简单文本分割)、向量存储(按语义索引代码片段)、仓库地图(提供全局视角)和推理层。重点介绍了使用tree-sitter进行AST分块的方法,推荐向量数据库存储代码片段,以及如何构建系统提示让模型理解代码结构。对于大型项目,还介绍了Repo Map技术,将代码库压缩成树结构。目标是打造真正理解代码库的AI助手,而非简单代码补全工具。
很多人觉得做个AI助手就是调调OpenAI的接口,其实这样智能做出一个通用聊天机器人。
而代码助手需要专门为代码设计的上下文感知的RAG(Retrieval-Augmented Generation)管道,这是因为代码跟普通文本不一样,结构严格,而且不能随便按字符随便进行分割。
一般的代码助手分四块:代码解析把源文件转成AST语法树;向量存储按语义索引代码片段而非关键词匹配;仓库地图给LLM一个全局视角,知道文件结构和类定义在哪;推理层把用户问题、相关代码、仓库结构拼成一个完整的prompt发给模型。
代码解析:别用文本分割器
自己做代码助手最常见的坑是直接用文本分割器。
比如按1000字符切Python文件很可能把函数拦腰截断。AI拿到后半截没有函数签名根本不知道参数等具体信息。
而正确做法是基于AST分块。tree-sitter是这方面的标准工具,因为Atom和Neovim都在用。它能按逻辑边界比如类或函数来切分代码。
依赖库是tree_sitter和tree_sitter_languages:
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language
from langchain_community.document_loaders.generic import GenericLoader
from langchain_community.document_loaders.parsers import LanguageParser
# 1. Load the Repository
# We point the loader to our local repo. It automatically handles extensions.
loader = GenericLoader.from_filesystem(
"./my_legacy_project",
glob="**/*",
suffixes=[".py"],
parser=LanguageParser(language=Language.PYTHON, parser_threshold=500)
)
documents = loader.load()
# 2. Split by AST (Abstract Syntax Tree)
# This ensures we don't break a class or function in the middle.
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON,
chunk_size=2000,
chunk_overlap=200
)
texts = python_splitter.split_documents(documents)
print(f"Processed {len(texts)} semantic code chunks.")
# Example output: Processed 452 semantic code chunks.
保持函数完整性很关键。检索器拿到的每个分块都是完整的逻辑单元,不是代码碎片。
向量存储方案
分块完成后需要存储,向量数据库肯定是标配。
embedding模型推荐可以用OpenAI的text-embedding-3-large或者Voyage AI的代码专用模型。这类模型在代码语义理解上表现更好,能识别出def get_users():和"获取用户列表"是一回事。
这里用ChromaDB作为示例:
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
# Initialize the Vector DB
# Ideally, persist this to disk so you don't re-index every run
db = Chroma.from_documents(
texts,
OpenAIEmbeddings(model="text-embedding-3-large"),
persist_directory="./chroma_db"
)
retriever = db.as_retriever(
search_type="mmr", # Maximal Marginal Relevance for diversity
search_kwargs={"k": 8} # Fetch top 8 relevant snippets
)
这里有个需要说明的细节:search_type用"mmr"是因为普通相似度搜索容易返回五个几乎一样的分块,MMR(最大边际相关性)会强制选取相关但彼此不同的结果,这样可以给模型更宽的代码库视野。
上下文构建
单纯把代码片段扔给GPT还不够。它可能看到User类的定义,却不知道main.py里怎么实例化它。缺的是全局视角。
所以解决办法是设计系统提示,让模型以高级架构师的身份来理解代码:
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4-turbo-preview", temperature=0)
# The "Stuff" chain puts all retrieved docs into the context window
prompt = ChatPromptTemplate.from_template("""
You are a Senior Software Engineer assisting with a Python legacy codebase.
Use the following pieces of retrieved context to answer the question.
If the context doesn't contain the answer, say "I don't have enough context."
CONTEXT FROM REPOSITORY:
{context}
USER QUESTION:
{input}
Answer specifically using the class names and variable names found in the context.
""")
combine_docs_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(retriever, combine_docs_chain)
# Let's test it on that tricky legacy function
response = rag_chain.invoke({"input": "How do I refactor the PaymentProcessor to use the new AsyncAPI?"})
print(response["answer"])
这样AI不再编造不存在的导入,因为它现在能看到向量库检索出的AsyncAPI类定义和PaymentProcessor类。它会告诉你:“重构PaymentProcessor需要修改_make_request方法,根据上下文,AsyncAPI初始化时需要await关键字……”
代码地图:应对大型代码库
上面的方案对中小项目就已经够用了,但是如果代码的规模到了十万行以上,这些工作还远远不够覆盖。
Aider、Cursor这类工具采用的进阶技术叫Repo Map,也就是把整个代码库压缩成一棵树结构,塞进上下文窗口:
src/
auth/
login.py:
- class AuthManager
- def login(user, pass)
db/
models.py:
- class User
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
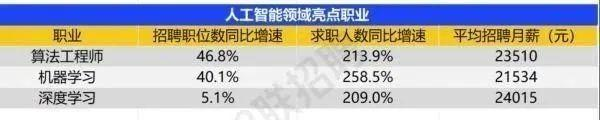
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献517条内容
已为社区贡献517条内容

所有评论(0)