高质量数据集≠数据治理,别再花冤枉钱了
我想强调的是,高质量数据集建设是一个系统工程,数据治理是它的基础,而不是全部。要么跳过基础直接搞数据集:结果发现底层数据一团糟,根本没法用要么以为治理完就够了:结果发现治理后的数据还是不能直接训练模型正确的路径是:先治理(建立信任),再应用(提供服务),最后针对AI场景定制数据集。三步走,一步都不能省。我一直坚持一个观点:数据质量是企业的核心竞争力。而搞清楚数据治理、高质量的数据、高质量数据集的关
先问大家一个问题:你们公司是不是也准备搞AI大模型了?
最近和几位企业数据负责人聊天,发现一个特别普遍的现象:很多公司听说要上AI,赶紧找供应商咨询"高质量数据集怎么建"。结果对方一看企业现状,直接劝退:"你们连数据治理都没做好,谈什么数据集?先把基础打牢再说。"
企业懵了:我花了几百万做数据治理,系统也上了,流程也建了,怎么就不算数了?
说实话,这种困惑我见得太多了。今天咱们就把这事儿说透:数据治理、高质量的数据、高质量数据集,这三个概念到底什么关系?你们公司现在处于哪个阶段?该往哪个方向投钱?
一、三个概念,一次搞清楚
很多人以为这三个词是一回事,其实差别大了。搞不清楚这三个概念,你就会在错误的阶段投错钱,最后发现钱花了、人累了、效果没出来。我用最直白的方式给你讲清楚:
1. 数据治理:这是个"过程"
说白了,数据治理就是让数据变得可信、可控、可管理的一整套方法。它要解决的核心问题是:"这个数据能不能信?"
具体来说,数据治理干这些事:
-
制定数据战略(数据往哪个方向发展)
-
建立数据标准(同一个字段全公司统一叫法)
-
元数据管理(搞清楚数据从哪来、是什么意思)
-
数据质量管理(监控数据准不准、全不全)
-
数据安全合规(别让敏感数据泄露了)
-
数据共享服务(让需要的人能用上数据)
数据治理关注的是:准确性、完整性、一致性、及时性——这些都是"信任"维度的指标。
你懂我意思吗?数据治理就像你家装修前要先做水电改造、定好插座位置、规划好动线,把基础打牢,后面才不会出乱子。
2. 高质量的数据:这是个"结果"
经过数据治理后,你得到的就是高质量的数据。这是企业的数据资产,是可信、可用的基础数据。
高质量的数据有这些特征:
-
有明确的Owner(知道谁负责这个数据)
-
有完整的元数据(知道数据从哪来、是什么意思)
-
有清晰的血缘(知道数据怎么加工出来的)
-
有统一的标准(全公司口径一致)
-
受控管理(有质量监控和问题修复机制)
它解决的问题是:"这个数据我能不能用?用起来放不放心?"
听着是不是清楚多了?这就像你家里的自来水,经过水厂的处理(数据治理),变成了干净、安全、符合标准的饮用水(高质量的数据),你可以放心喝。
3. 高质量数据集:这是个"专用产品"
高质量数据集是专门为AI模型训练设计的结构化数据产品。它不是简单的"干净数据",而是针对特定应用场景、经过系统化处理的"燃料"。
高质量数据集的特征:
-
场景牵引(为某个具体的AI应用服务)
-
高质量标注(数据打好了标签,模型才能学习)
-
结构化格式(训练集、验证集、测试集分好了)
-
数据增强(可能包含合成数据、增强数据)
-
丰富元数据(记录数据来源、处理过程、质量评价)
它解决的问题是:"这个数据集能不能让我的AI模型训练出好效果?"
继续用水来比喻:高质量数据集就像瓶装矿泉水,不仅干净安全(基础要求),还根据不同用途(运动、婴儿、美容)做了定制化处理。
三者关系一张图看懂
|
维度 |
数据治理 |
高质量的数据 |
高质量数据集 |
|---|---|---|---|
|
定位 |
过程/方法论 |
结果/资产 |
专用产品 |
|
解决问题 |
能不能信 |
能不能用 |
模型能不能训 |
|
关注重点 |
准确性、一致性、完整性 |
可信性、可用性 |
场景适用性、标注质量 |
|
数据来源 |
业务真实数据 |
业务真实数据 |
真实数据+合成增强数据 |
|
使用场景 |
日常业务运营、报表分析 |
各类数据应用 |
AI模型训练 |
|
典型工作 |
建标准、做监控、管权限 |
提供可信数据服务 |
数据标注、特征工程、数据增强 |
听着是不是清楚多了?核心就一句话:数据治理是手段,高质量的数据是基础,高质量数据集是针对AI场景的专用产品。它们是递进关系,不是并列关系。
二、一个案例,看懂关键差异
还是有点抽象?我给你讲个真实场景你就明白了。
假设你在管理一个动物园的数据系统。
数据治理的做法:
-
为每只动物建立电子档案(照片、出生日期、毛发颜色、饮食偏好、饲养员信息等)
-
制定数据标准:"毛发颜色"字段只能填标准色值,不能乱写
-
质量监控:如果系统显示有一只黑豹的皮毛被录成"白色",那就是数据错误,必须立即修正
-
数据治理的原则:追求"事实真实",错了就要改
高质量数据集的做法:
-
动物园要开发一个"动物图像识别"大模型,需要训练数据
-
现实中动物园没有白豹,导致模型对白豹的识别准确率很低
-
数据团队用数据增强技术,把黑豹照片通过图像处理生成"合成白豹"
-
这些合成数据虽然不是真实存在的动物个体,但符合动物形态学规律,具备"逻辑真实性"
-
高质量数据集的原则:允许"理论真实"或"功能真实",只要对模型训练有价值
你看出差别了吗?
如果把合成的白豹数据混入动物园的正式档案系统,数据治理会视其为"数据污染",必须清除。但在AI模型训练中,这些合成数据恰恰是高价值样本。
这就是为什么"数据治理做得好"≠"能直接用来训练模型"。搞清楚你现在在哪个阶段,才能知道该往哪投钱、投多少。
三、大部分企业在哪个阶段?
说实话,根据我这些年的观察,80%以上的企业还在第一阶段(数据治理)挣扎,连高质量的数据都没做好,更别提数据集了。
你可以对照一下,看看你们公司是不是有这些情况(如果下面的问题你中了3个以上,说明你还在数据治理阶段挣扎):
数据治理层面:
-
不同部门对同一个指标的定义不一样,销售额、客户数对不上
-
子公司、事业部各自为政,集团根本不知道下面有多少数据
-
重复数据一堆,同一个客户录了好几次
高质量数据层面:
-
数据没有Owner,出问题了不知道找谁
-
数据血缘关系不清楚,不知道这个报表的数据是怎么算出来的
-
业务人员不信数据,宁愿用Excel手工统计
高质量数据集层面:
-
想做AI应用,发现数据根本没标注
-
数据样本不均衡,某些场景的数据太少
-
没有训练集、验证集、测试集的划分
如果你中了一大半,别慌,这很正常。如果前两类问题你都有一大堆,那坦白说,你现在的重点应该是做好数据治理和高质量数据建设,而不是着急搞什么数据集。
地基都没打牢,直接盖高楼,那不是找崩盘吗?
四、正确的建设路径是什么?
说了这么多,到底该怎么做?根据我的经验,企业数据建设应该分三步走:
第一阶段:夯实数据治理基础(解决"能不能信")
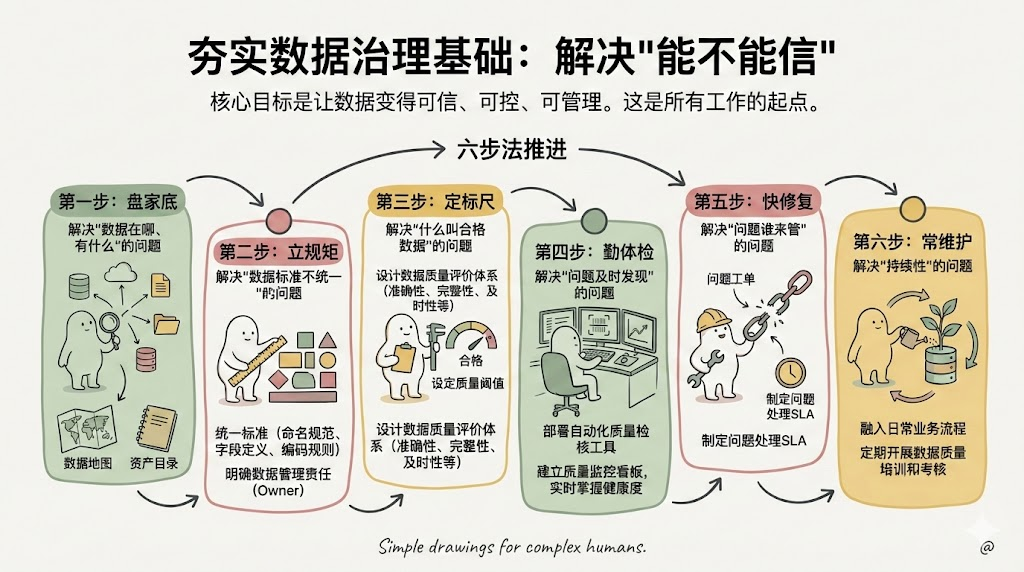
这是所有工作的起点,核心目标是让数据变得可信、可控、可管理。没有这个基础,后面啥都干不了。六步法推进:
第一步:盘家底——解决"数据在哪、有什么"的问题
-
用元数据管理工具,把散落在各个系统的数据摸清楚
-
建立数据资产目录,画清楚数据地图
第二步:立规矩——解决"数据标准不统一"的问题
-
制定统一的数据标准(命名规范、字段定义、编码规则)
-
明确数据管理责任,每个数据域都要有Owner
第三步:定标尺——解决"什么叫合格数据"的问题
-
设计数据质量评价体系(准确性、完整性、及时性等维度)
-
为每个关键指标设定质量阈值
第四步:勤体检——解决"问题及时发现"的问题
-
部署自动化质量检核工具,定期扫描数据问题
-
建立质量监控看板,实时掌握数据健康度
第五步:快修复——解决"问题谁来管"的问题
-
建立问题工单系统,发现问题立即分配责任人
-
制定问题处理SLA,不能让问题堆积
第六步:常维护——解决"持续性"的问题
-
把数据质量管理融入日常业务流程
-
定期开展数据质量培训和考核
我见过一家制造企业,做完这六步后,数据准确率从不到70%提升到95%以上,报表对账时间从2天压缩到半天。
说到工具支持,用过来人的经验告诉你,数据治理这事儿光靠人工是干不过来的,必须有自动化工具支撑。我这些年接触下来,睿治数据治理平台EDG在元数据管理、数据血缘、质量监控这几块做得比较扎实,能把很多手工活变成自动化规则。如果你正在选型,可以先试用看看是不是符合你的场景:https://tinyurl.com/55rzk8pr
第二阶段:构建高质量的数据(解决"好不好用")
数据治理做好后,要让数据真正"用得起来",关键是持续运营——根据用户反馈优化数据质量,扩充高价值数据资产,持续提升数据服务能力。
关键点:高质量的数据必须有这些特征:
-
有Owner(明确责任人)
-
有元数据(来源、含义、标准清清楚楚)
-
有血缘(加工逻辑可追溯)
-
有标准(口径统一)
-
受控管理(质量持续监控)
具体怎么做?
-
搭建统一的数据服务平台,提供标准化的数据接口和API
-
建立数据申请和授权流程,让需要的人能用上数据
-
监控数据服务的使用情况,收集用户反馈和痛点
-
根据反馈持续优化数据质量,扩充高价值数据资产
这个阶段做好了,你的BI报表、数据分析、业务决策才能真正依赖数据。
第三阶段:按需构建高质量数据集(解决"模型能不能训")
只有在前两个阶段打好基础后,才适合针对特定AI场景建设数据集。这个阶段的核心目标是为AI模型训练提供高质量、可用的数据燃料。五步法推进:
第一步:明确场景需求——解决"要什么数据"的问题
-
这个AI应用要解决什么业务问题?
-
需要什么类型的数据?需要多大的数据量?
第二步:数据采集与预处理——解决"数据哪里来"的问题
-
从高质量的数据中筛选相关数据
-
进行清洗、转换、归一化处理
-
必要时进行数据增强(合成、采样、融合)
第三步:数据标注——解决"模型怎么学"的问题
-
根据模型训练需求设计标注规范
-
组织专业团队进行数据标注
-
建立标注质量控制机制
第四步:数据集构建——解决"数据怎么用"的问题
-
按比例划分训练集、验证集、测试集
-
确保数据分布的均衡性和代表性
第五步:质量评价与迭代——解决"效果好不好"的问题
-
在模型训练中验证数据集质量
-
根据模型反馈调整数据集
你会发现,这个阶段的工作和前两个阶段完全不同。它不是简单的"把数据整理干净",而是针对特定AI任务的"定制化加工"。
五、说到最后
我想强调的是,高质量数据集建设是一个系统工程,数据治理是它的基础,而不是全部。
很多企业犯的错误是:
-
要么跳过基础直接搞数据集:结果发现底层数据一团糟,根本没法用
-
要么以为治理完就够了:结果发现治理后的数据还是不能直接训练模型
正确的路径是:先治理(建立信任),再应用(提供服务),最后针对AI场景定制数据集。三步走,一步都不能省。
我一直坚持一个观点:数据质量是企业的核心竞争力。而搞清楚数据治理、高质量的数据、高质量数据集的关系,是少走弯路、少花冤枉钱的关键。
最后给你三个建议:第一,先评估你们公司现在处于哪个阶段,别盲目跟风; 第二,如果基础还没打牢,先把数据治理做扎实,地基不牢地动山摇; 第三,选对工具和方法论,能少走很多弯路。
如果你也在做数据建设,遇到过类似的困惑,欢迎留言交流。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)