JFM | 浙江大学郑畅东、谢芳芳等:基于Transformer网络的上下文学习跨翼型的主动流动控制策略
近年来,基于强化学习的主动流动控制(AFC)技术备受关注。然而,强化学习策略对大量试错数据的需求在实际应用中形成了显著障碍,同时限制了跨案例智能体的训练。针对强化学习样本需求量较大的问题,课题组前期提出了专家演示策略加速方法,在训练数据中掺入“伪专家”给出的指导数据,引导控制律高效、合理、有针对性地进行探索和试错,大幅减少了探索数据需求量[1]。针对跨案例智能体训练问题,本研究提出了一种基于强化学
基于Transformer网络的上下文学习跨翼型的主动流动控制策略
Transformer-Based In-Context Policy Learning for Efficient Active Flow Control across Various Airfoils
郑畅东、谢芳芳*、季廷炜、周宏杰、郑耀
浙江大学航空航天学院,浙江,310027

引用格式:
Zheng, C., Xie, F.*, Ji, T., Zhou, H. and Zheng, Y., 2024. Transformer-based in-context policy learning for efficient active flow control across various airfoils. Journal of Fluid Mechanics, 1001, p.A53.
摘要
近年来,基于强化学习的主动流动控制(AFC)技术备受关注。然而,强化学习策略对大量试错数据的需求在实际应用中形成了显著障碍,同时限制了跨案例智能体的训练。针对强化学习样本需求量较大的问题,课题组前期提出了专家演示策略加速方法,在训练数据中掺入“伪专家”给出的指导数据,引导控制律高效、合理、有针对性地进行探索和试错,大幅减少了探索数据需求量[1]。针对跨案例智能体训练问题,本研究提出了一种基于强化学习数据的上下文主动流动控制策略学习框架。该框架引入基于Transformer的策略改进算子,将强化学习过程建模为因果序列,并通过自回归方式,在面对新的、未见过的案例时,结合足够长的上下文进行决策。在流动分离问题中,该框架展示了成功学习并应用高效流动控制策略的能力,适用于多种翼型配置。与传统强化学习方法相比,这种无需更新网络参数的学习方式效率更高。研究还提出了一项新技术,利用单一的Transformer模型解决不同翼型的流动分离控制问题。此外,研究创新性地将基于强化学习的流动控制与气动形状优化相结合,显著提升了整体性能。这一方法在形状优化过程中有效减少了新流动控制策略的训练负担,为未来车辆的跨学科智能协同设计提供了新的可能性。
研究背景
提升气动性能一直是航空研究人员和制造商的核心目标,主要驱动因素包括经济效益、能源节约和军事需求。为此,气动形状优化和主动流动控制(AFC)等技术得到了广泛发展。然而,由于各自问题的复杂性,这些技术通常分开研究。AFC通过在车辆表面安装执行器引导流动扰动,以实现延迟流动分离和消除振动等多种目标。近年来,强化学习作为一种无需模型的控制方法在AFC中展现出巨大潜力,但其对大量数据的需求和高昂的训练成本限制了实际应用。为解决这些挑战,研究者们引入了Transformer模型,利用其处理序列和上下文信息的能力,并通过算法蒸馏技术(Algorithm Distillation)在无需额外训练的情况下提升控制策略。
方法介绍
算法蒸馏(Algorithm Distillation)是一种创新的策略学习方法,结合了强化学习(Reinforcement Learning)、离线策略蒸馏(Offline Policy Distillation)和上下文学习(In-Context Learning)等技术。其核心理念是,如果Transformer模型的上下文足够长,能够包含由学习更新带来的策略改进,则它不仅能表示固定策略,还能通过关注先前的状态、动作和奖励,作为策略改进算子。这意味着,基于强化学习数据训练的算子能够在新的流动控制案例中提取和改进策略。具体过程包括:
1.数据生成:首先,通过强化学习算法在多个子案例(如不同翼型或流动场景)上进行训练,生成大量的训练数据。每个案例的训练历史被保存,包括状态、动作、奖励等信息,构成数据缓冲区D,公式如下:
其中,其中,N 是生成数据的案例数量,每个案例对应一个独立强化学习智能体的训练过程。数据集合 D 包含了所有案例的历史轨迹。
2.模型训练:通过最小化负对数似然损失函数(NLL),训练一个序列模型 ,使其能够将长历史序列 映射到动作概率分布。损失函数定义为:
其中 为策略神经网络的系数, 为状态转移概率, 分别为单一案例强化学习智能体训练过程中的动作、观测状态和奖励。通过最小化该损失,模型学习到如何基于过去的状态和奖励历史预测最优动作。
3.策略提取:训练完成后,模型能够基于新案例的历史数据,自动预测并生成改进后的动作策略,无需额外的网络参数更新。
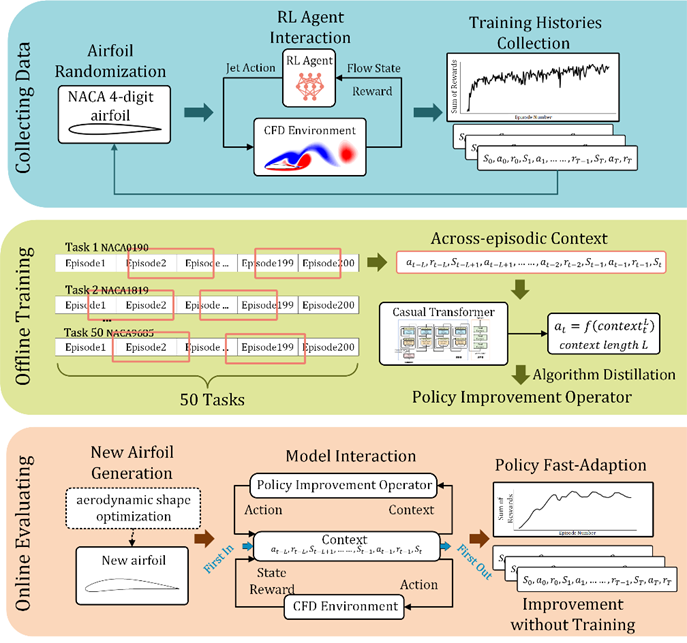
基于上述算法蒸馏方法,上下文主动流动控制策略学习框架(In-context AFC Policy Learning Framework)主要包含三个阶段:数据收集、离线训练和在线评估。
1.数据收集:在不同翼型的模拟环境中,多个强化学习智能体进行交互并优化控制策略,记录所有学习历史,构建包含多种案例的庞大数据缓冲区。
2.离线训练:在Transformer模型上训练策略改进算子,包括嵌入网络、Transformer网络和动作网络。模型通过最小化预测动作与真实动作之间的均方误差,学习从历史数据中预测高效的控制动作序列。
3.在线评估:在气动形状优化过程中,利用训练好的策略改进算子对新翼型进行控制策略预测,并记录奖励以评估策略的改进效果。
环境配置
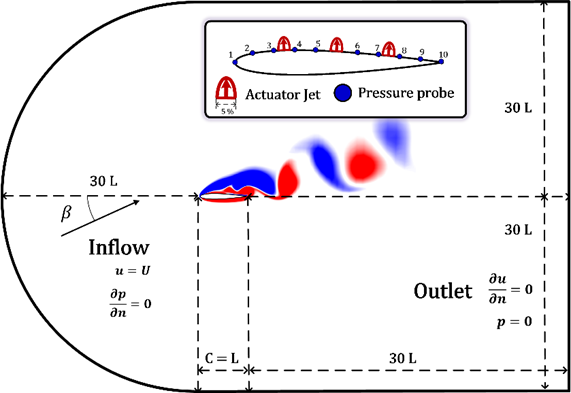
本研究通过计算流体力学(CFD)对翼型流动分离进行数值模拟,以配置主动流动控制系统。翼型形状随机变化,带来不同的流动边界条件和流场结构,增加了学习的复杂性。模拟中,翼型位于 (x = 0, y = 0),翼弦长度为1米,计算域从 x = -30m 延伸到 x = 30m,横向范围为 y = -30m 到 y = 30m。入流速度为1 m/s,迎角为20度,雷诺数设定为1000。翼型上布置了10个压力探针用于捕捉压力信息,作为强化学习的状态输入,三个执行器喷嘴分别位于上表面的25%、50%和75%处,每个喷嘴宽度为5%。
结果展示
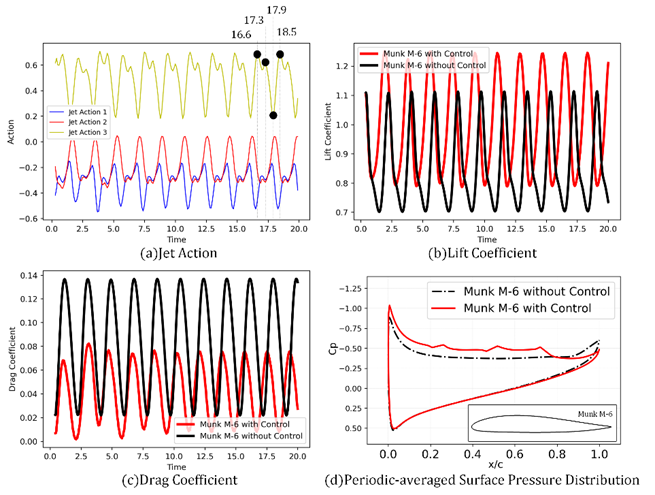
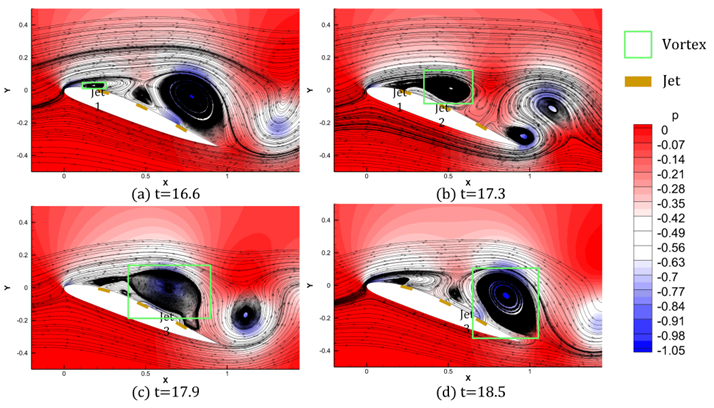
将提出的上下文主动流动控制(AFC)策略学习框架应用于翼型流动分离环境,通过对50个NACA-4位数字翼型的学习历史数据进行收集,评估策略改进算子在12个新翼型上的学习能力。结果显示,策略改进算子在不同翼型上均表现出逐步优化的趋势,相较于无控制条件下,奖励总和显著提高。以Munk M-6翼型为例,应用控制策略后,平均阻力系数从0.079335降低到0.042523,升力系数从0.908699提高到1.018136,流场快照和周期平均压力分布进一步证明了流动控制对提升气动性能的有效性。
进一步将该策略学习框架扩展应用于翼型的气动优化,通过结合代理模型和贝叶斯优化方法,优化后的翼型在升阻比上较基准翼型实现了41.23%的提升。贝叶斯优化通过构建代理模型对气动性能进行预测,从而有效减少了计算成本,同时加速了优化过程。在优化过程中,主动流动控制策略被引入,以进一步改善翼型的流场结构,减少流动分离和阻力,进而提升升力和降低阻力。最终,结合主动流动控制后的优化翼型,其升阻比较基准翼型进一步提升至54.72%。
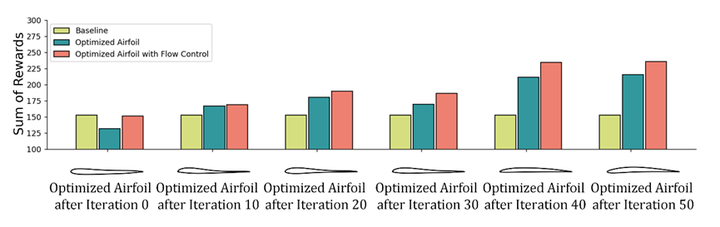
结论
本研究提出了一种创新的主动流动控制(AFC)策略学习框架,采用Transformer模型作为策略改进算子,并通过近端策略优化(PPO)算法从多个案例中收集学习历史。该框架将强化学习过程视为因果序列预测问题,使智能体在面对新翼型等新案例时,能够在上下文中直接改进策略,无需更新网络参数,从而展示了高效和适应性。在翼型流动分离的实验结果表明,智能体在不同案例中均能成功学习和优化控制策略。此外,该框架与翼型优化设计的集成显著提高了设计效率,证明了将强化学习与Transformer结合在流动控制领域的潜力,为未来智能化流动控制和气动设计提供了新的方法。
参考文献
[1] Zheng, C., Xie, F., Ji, T., Zhang, X., Lu, Y., Zhou, H. and Zheng, Y., 2022. Data-efficient deep reinforcement learning with expert demonstration for active flow control. Physics of Fluids, 34(11).
公众号原文链接(文末附论文资源):
https://mp.weixin.qq.com/s/QeJ2f2xeltdth-NSEO0zpQ
注:本文由论文原作者整理并投稿分享,获作者授权发布。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)