Gen_AI 补充内容 RAG
RAG(检索增强生成)技术通过结合检索系统与大语言模型,构建了一个高效的知识问答系统。其核心流程包括知识库预处理、相关段落检索、提示增强和最终答案生成。系统采用混合检索策略,同时使用BM25稀疏检索和神经网络稠密检索,通过倒数排名融合方法取长补短。在分块优化方面,需平衡分块大小与重叠区域,推荐采用语义分块和元数据增强策略。RAG技术能有效减少模型幻觉,支持动态知识更新,同时保护数据隐私,是提升大模
一、什么是 RAG?
类比理解:RAG 就像一个图书管理员系统。
- 图书馆 = 外部知识库(大量文档资料)
- 图书管理员 = 检索系统 + 大模型
- 读者提问 = 用户查询
我们不直接翻阅整栋图书馆,而是询问"图书管理员",由他快速定位相关资料,再结合知识回答问题。
核心优势
|
优势 |
说明 |
|
减少幻觉 |
输出绑定外部可验证数据,有据可查 |
|
动态知识更新 |
无需重新训练模型,即可处理领域特定或最新知识 |
|
数据隐私保护 |
私有数据无需嵌入模型参数,仅在检索时使用 |
|
高效计算 |
仅提供相关信息,节省模型处理整个知识库的成本 |
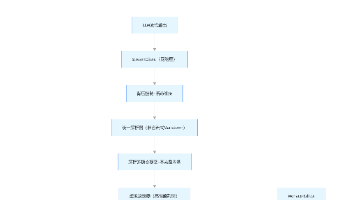
二、RAG 标准工作流
详细流程:
- 预处理阶段:将资料划分为 Chunk(文本块),建立索引
- 检索阶段:根据用户输入,检索相关 Chunk
- 增强阶段:将检索结果与查询合并,格式化为 Prompt
- 生成阶段:LLM 基于增强后的 Prompt 生成最终回答
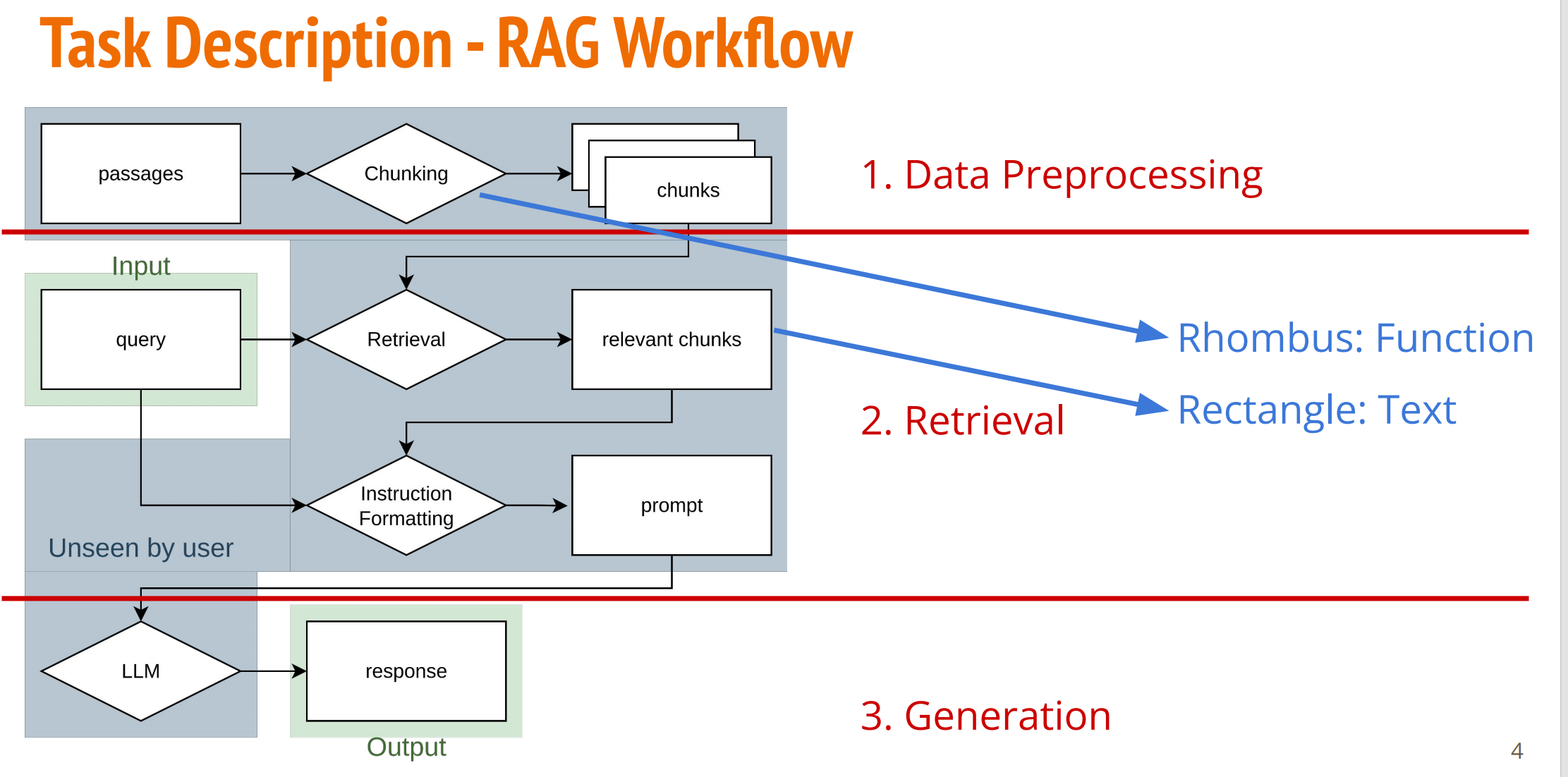
三、检索方法对比
3.1 稀疏检索:BM25
核心机制:基于词频的离散表示(稀疏向量)
- BM25 将查询和文档段落转化为一系列离散的词元(稀疏检索),然后进行相似度计算
-
- 例如:"信息检索系统可以从文档集合中找到相关资料" → [信息, 检索, 系统, 可以, 从, 文件, 集合, 找到, 相关, 资料]
- 相似度基于关键词匹配
-
- [信息, 检索] 与 [信息, 检索, 系统, 可以, 从, 文件, 集合, 找到, 相关, 资料] → 相似度较高 👍
- [信息, 检索] 与 [这, 篇, 论文, 探讨, 机器, 学习, 在, 影像, 检索, 领域] → 相似度较低 👎
- 优点
-
- 无需大量领域特定调优即可良好工作
- 公式相对简单,计算效率高
- 缺点
-
- 默认无法处理同义词或词形变化(例如:地震 vs. 地牛翻身)
- 无法捕捉语义相关性(例如:只看字面不懂语义,用词不同时找不到相关内容)
3.2 稠密检索:Embedding 模型
核心机制:神经网络将文本编码为语义向量(稠密向量)
- 嵌入模型将查询和文档段落转化为一系列浮点数(稠密检索),然后进行相似度计算
-
- 例如:"信息检索系统可以从文档集合中找到相关资料" → [5.6, 0.8, -7.2, …](嵌入向量)
- 优点
-
- 嵌入能够捕捉短语或句子的语义,而非仅仅是词频
- 部分嵌入模型支持跨语言或跨模态(如文本–图像)
- 缺点
-
- 训练与推理需要 GPU
- 若未经领域微调,跨领域的性能可能下降
3.3 典型失败案例对比
|
查询 |
文档内容 |
BM25 |
Embedding |
|
"如何提升睡眠品质" |
"改善失眠的方法" |
❌ 失败(无关键词重叠) |
✅ 成功(语义相关) |
|
"GPT-4" |
出现精确术语 "GPT-4" |
✅ 精准命中 |
⚠️ 可能分散注意力 |
四、混合检索(Hybrid Retrieval)
4.1 为什么需要混合?
单一检索方式各有盲区,现代 RAG 系统通常同时使用两种方法,取长补短。
|
检索类型 |
代表算法 |
核心机制 |
擅长场景 |
|
稀疏检索 |
BM25、TF-IDF |
词频 × 逆文档频率 |
精确关键词匹配、罕见术语、ID、专业术语 |
|
稠密检索 |
BERT、Contriever、GTE、M3E |
神经网络语义向量 |
语义理解、同义词、跨语言、上下文含义 |
4.2 融合策略:倒数排名融合(RRF)
问题场景:
- BM25 排名:
[c₁, c₄, c₃, c₅, c₂] - Embedding 排名:
[c₅, c₁, c₃, c₄, c₂]
RRF 公式:
RRF(c)=∑r∈Rk+rankr(c)1
|
符号 |
含义 |
|
c |
某个文本片段(chunk) |
|
R |
所有检索模型的集合 |
|
k |
平滑常数(通常取 60) |
|
rankr(c) |
片段 c 在模型 r 中的排名 |
计算示例
|
最终融合排名:[c₁, c₅, c₄, c₃, c₂]
RRF 核心思想:
- 🥇 排名越靠前 → 倒数越大 → 贡献分数越高
- 🛡️ 常数 k=60:平滑处理,避免第 1 名和第 2 名差距过大,给靠后排名竞争机会
- 🎯 无参数融合:不需要训练,不依赖具体相似度分数,仅使用排名位置
五、分块策略优化
5.1 分块大小(Chunk Size)
|
大小 |
效果 |
适用场景 |
|
较大分块(512-1024 tokens) |
提供更广泛的上下文背景 |
需要综合理解、跨段落推理的复杂问题 |
|
较小分块(128-256 tokens) |
更紧凑、聚焦,精确度和相关性更高 |
事实性查询、精确匹配、降低噪声 |
5.2 步幅/重叠(Stride / Overlap)
|
步幅设置 |
特点 |
权衡 |
|
较大步幅(重叠少) |
索引快、存储成本低、查询速度快 |
可能切断跨边界的关键信息 |
|
较小步幅(重叠多,如 50%) |
保留上下文连贯性,捕捉跨边界事实 |
存储成本增加,索引时间延长 |
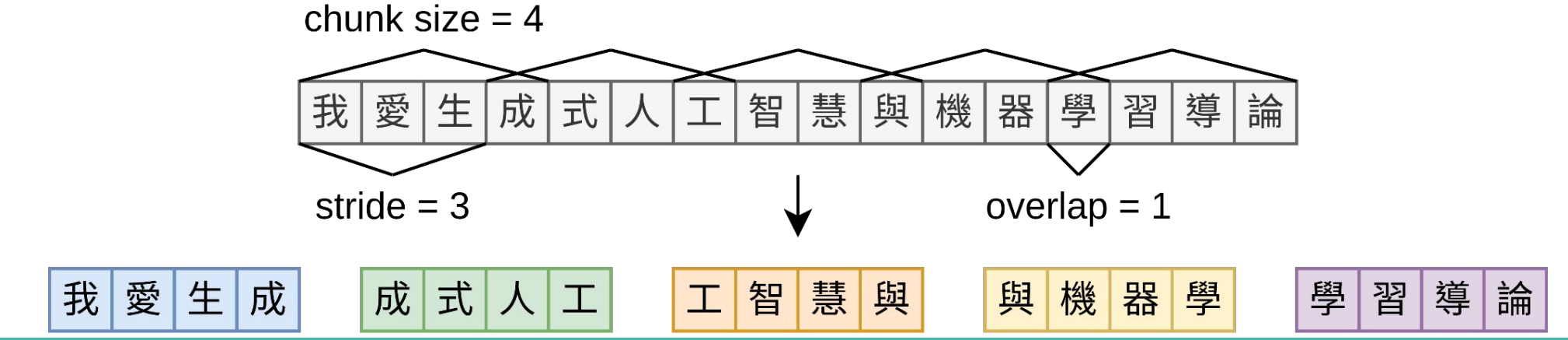
5.3 分块策略最佳实践
┌─────────────────────────────────────────────────┐
│ 原始文档: "RAG 技术能提升大模型的知识准确性..." │
└─────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ Chunk 1: "RAG 技术能提升大模型的知识准确性,通过 │
│ 检索外部知识库来..." │
│ ▲ ▲ │
│ └───────── 重叠区域 ───────────┘ │
┌─────────────────────────────────────────────────┐
│ Chunk 2: "检索外部知识库来减少幻觉现象,同时 │
│ 保护数据隐私..." │
└─────────────────────────────────────────────────┘建议:
- 语义分块:按段落、章节自然边界分割,而非固定长度
- 元数据增强:为每个 chunk 添加标题、来源、时间等标签
- 递归检索:先检索粗粒度文档,再在其内部精确定位段落

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)