打通数据变现“最后一公里”:基于逻辑数据架构构建面向 AI 的资产化服务层
摘要:随着AI大模型和数据资产化的兴起,传统"物理集成"的数据治理模式显现弊端。逻辑数据架构(LDA)和数据服务层(DSL)成为新趋势,通过计算与存储解耦实现"零数据搬运",构建虚拟数据访问层。数据服务层将数据封装为API产品,实现价值计量与安全管控,满足AI实时调用需求。该架构以最小成本快速释放数据价值,使数据从"笨重集装箱"转变为&q
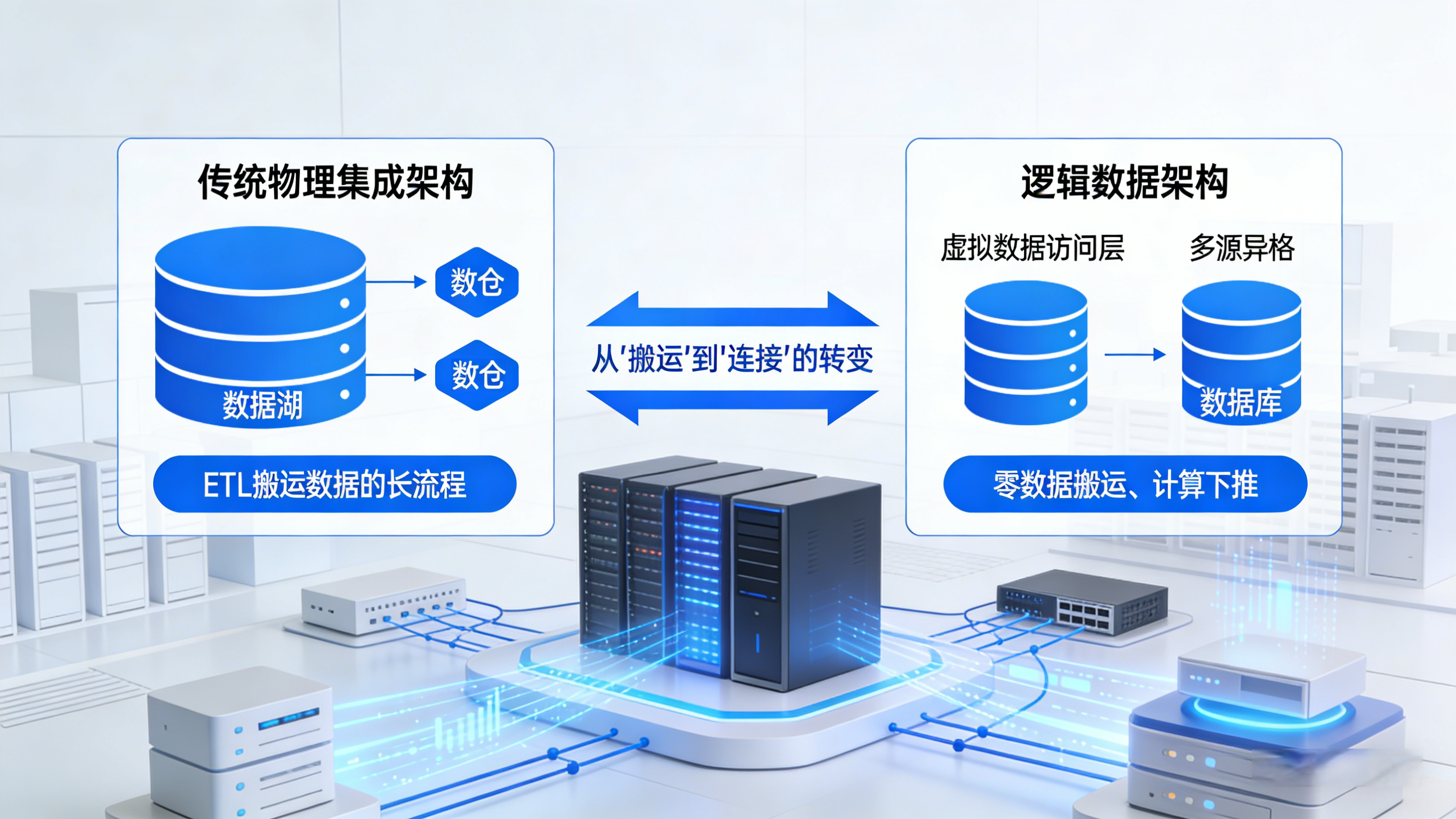
过去十年,企业数据治理的主旋律是“物理集成”。我们建设了庞大的数据湖和数据仓库,试图将 ERP、CRM、日志等所有数据通过 ETL 搬运到一个物理存储中心(Single Source of Truth)。
但在 AI 大模型与数据资产入表的双重浪潮冲击下,这种“大一统”的物理架构开始显露疲态:
-
AI 等不及: 大模型应用需要实时访问最新的业务数据和非结构化文档,T+1 的数仓搬运速度太慢。
-
资产算不清: 数据堆在湖里只是“库存”,只有被业务消费了才是“资产”。物理存储层缺乏对消费行为的精细化计量能力。
-
成本扛不住: 随着数据量爆炸,将所有数据都复制一份到数仓的存储和计算成本已成天价。
于是,逻辑数据架构 (Logical Data Architecture, LDA) 和 数据服务层 (Data Service Layer, DSL) 开始成为架构师的新宠。我们不再执着于“搬运数据”,而是专注于“连接数据”。
一、 核心理念:从 Data Warehouse 到 Data Fabric 的跃迁
逻辑数据架构的核心,在于计算与存储的彻底解耦。
在传统架构中,数据必须先被 ETL 抽取到数仓才能被查询。而在逻辑架构(常被称为 Data Fabric 或 Data Virtualization)中,我们构建了一个虚拟的数据访问层:
-
零数据搬运 (Zero-Copy): 逻辑层直接连接源端的 MySQL、ClickHouse、S3 对象存储,数据保留在原地。
-
计算下推 (Push-down): 查询引擎会自动判断,将过滤(Where)和聚合(Group By)操作下推到源端数据库执行,仅将结果集返回逻辑层进行合并。
-
统一语义: 无论底层是 SQL 还是 NoSQL,逻辑层向上暴露的都是统一的表结构或 API 接口。
这种架构为“数据变现”提供了最关键的基础——敏捷性。新业务上线,无需等待漫长的 ETL 排期,配置一个逻辑视图即可。
二、 关键组件:构建“可计量”的数据服务层 (DSL)
如果说逻辑架构解决了“数据怎么连”的问题,那么数据服务层(通常由 API 网关技术承载)则解决了“数据怎么卖”的问题。
在数据资产化的语境下,API 是数据价值交换的唯一通用货币。直接开放 JDBC 连接是无法进行资产计价的,唯有将数据封装为服务(Service),才能实现商业闭环。
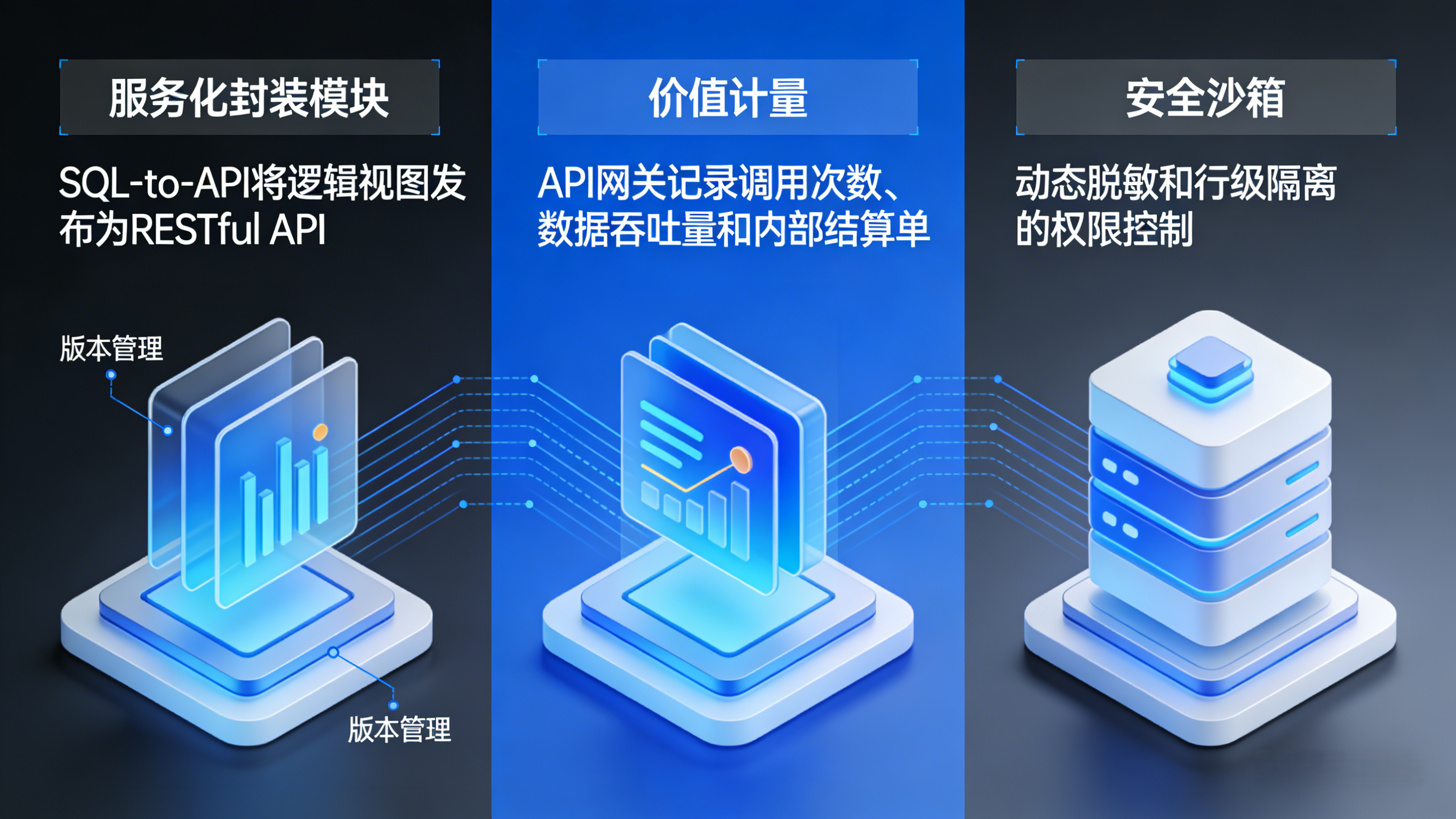
1. 服务化封装 (Service Encapsulation)
利用 SQL-to-API 技术,将逻辑层的查询视图快速发布为 RESTful API。
-
资产产品化: 原始表是“素材”,API 是“成品”。例如,将“用户表”和“交易表”关联后,发布为“用户信用评分 API”,这就是一个高附加值的数据产品。
-
版本管理: 对数据服务进行版本控制(v1.0, v2.0),确保下游 AI 应用或业务系统的稳定性,这是资产长期运营的基础。
2. 价值计量与计费 (Metering & Billing)
这是数据入表的必修课。API 网关必须充当“智能电表”的角色。
-
多维度计量: 不仅记录调用次数,还要记录数据吞吐量(Token数/字节数)、计算耗时。
-
内部结算: 企业的 AI 部门调用了数据部门的 10 万次 API,网关自动生成内部结算单,证明数据的经济效益。
3. 安全与隐私沙箱 (Security Sandbox)
当数据作为资产对外流通时,安全边界至关重要。
-
动态脱敏: 网关层根据调用者的 Token 权限(如合作伙伴 vs 内部员工),实时对身份证、金额等敏感字段进行掩码处理。
-
行级隔离: 确保 A 客户只能拉取属于 A 客户的数据,防止资产泄露。
三、 面向 AI:逻辑架构如何喂饱大模型?
AI 时代的数据服务层,不仅要服务于传统的 BI 和 App,更要成为 LLM(大语言模型) 和 Agent(智能体) 的核心供油管道。
1. 为 RAG 提供实时上下文
通用大模型缺乏企业私有知识。通过逻辑数据架构,我们可以将企业内部的实时库存、客户状态封装为 API。 当 Agent 接收到用户提问时,通过 Function Calling 调用这些数据服务 API,获取实时信息并注入到 Prompt 中。这比传统的向量数据库方案更具时效性和准确性。
2. Text-to-SQL 的语义中间层
直接让 AI 写 SQL 去查原始数据库是非常危险且准确率低的(表名晦涩、关系复杂)。 数据服务层提供了一层清晰的语义抽象:
-
AI 面对的不是成千上万张原始表,而是经过治理的、带有清晰注释的几十个逻辑视图或 API 定义。
-
这极大降低了 LLM 理解数据的难度,提高了 Text-to-Data 的准确率。
四、 落地路径:打通变现的“最后一公里”
企业如何从零开始构建这套体系?
-
盘点与连接(Inventory & Connect): 不急着搬数据。使用支持多源异构的逻辑网关工具,先将企业内的 MySQL、Oracle、Hive 等数据源连接起来,形成统一的“数据地图”。
-
逻辑建模与服务化(Model & Serve): 识别高价值场景(如风控、营销)。在逻辑层通过 SQL 定义虚拟视图,并直接一键发布为 API。
-
挂载计量体系(Meter): 开启 API 网关的详细日志审计。结合前文提到的成本计算模型,开始为每一个 API 接口算账。
-
对接 AI 生态(Integrate): 将核心 API 注册到大模型的工具库(Tools/Plugins)中,让 AI 能够“读取”并“使用”企业数据资产。

五、 总结
在 AI 与数据资产化的双重浪潮下,“逻辑数据架构 + API 服务化” 是企业以最小成本、最快速度释放数据价值的最优解。
它改变了数据的交付形态——从“笨重的集装箱(数据表)”变成了“灵活的自来水(API)”。只有当数据能够被 AI 实时调用、被财务精准计量、被业务安全复用时,企业才算真正打通了数据变现的“最后一公里”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)