提示词工程的5个意外真相:如何像专家一样与AI对话?
摘要: 提示词工程的核心并非编程,而是精准沟通。本文揭示5个关键真相:1)采样控制(温度、Top-K/P)需平衡随机性与确定性,避免死循环;2)后退式提示通过先思考通用原则再解决细节,提升回答质量;3)**思维链(CoT)**分步推理可纠正AI逻辑错误;4)多用正向指令(如“限制140字”)而非负向约束(如“不要写长”),减少模型困惑;5)ReAct模式(思考-行动-观察)结合外部API,使AI能
提示词工程的5个意外真相:如何像专家一样与AI对话?
1. 引入:为什么你的AI总是“听不懂人话”?
你是否也曾感到挫败?当你试图让AI帮你梳理逻辑或创作内容,它却给出了模棱两可、甚至完全偏离目标的回答。这种感觉就像是在与一个博学但却无法沟通的怪才交流。很多人认为,要写好提示词(Prompt),必须具备深厚的计算机科学背景或算法知识。
作为一名AI提示词架构师,我经常告诉团队:提示词工程的本质不是编程,而是精准的沟通。
“You don’t need to be a data scientist or a machine learning engineer – everyone can write a prompt.”
(你不需要成为数据科学家或机器学习工程师——每个人都能编写提示词。)
掌握这项技术的关键,在于理解大语言模型(LLM)作为“概率预测引擎”的底层逻辑,并学会通过精细的调优引导其输出。
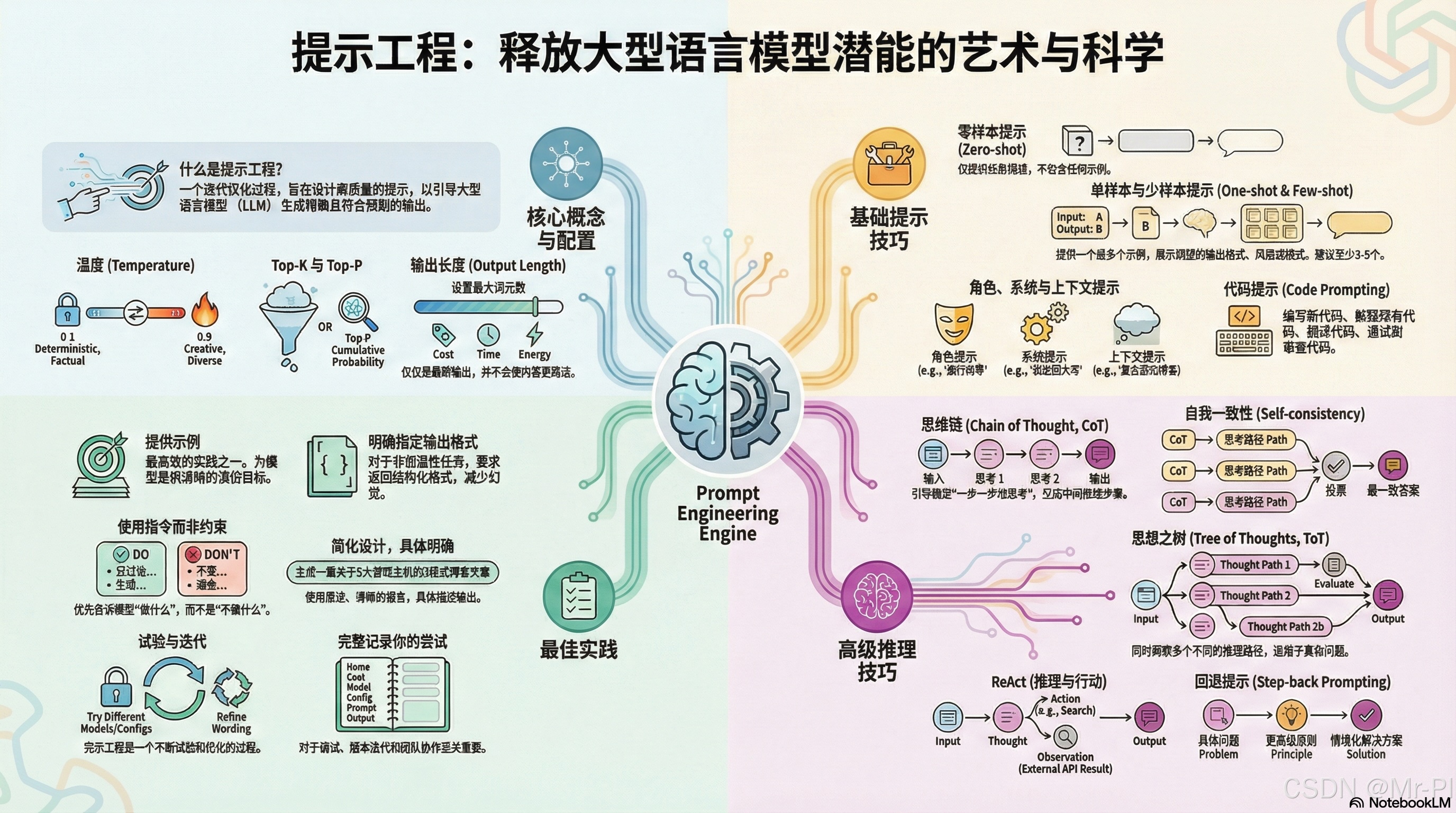
2. 真相一:采样控制的悖论——为什么“随机性”可能导致“死循环”?
在技术层面,AI的输出并非完全不可控。通过调节温度(Temperature)、Top-K和Top-P这三个核心配置,我们可以决定AI是“循规蹈矩”还是“天马行空”。
- 温度(Temperature): 控制 token 选择的随机程度。
- Top-K 与 Top-P: 通过限制模型考虑的高概率候选词范围,来控制输出的丰富度。
重复循环漏洞(Repetition Loop Bug)的深层逻辑 一个反直觉的真相是:AI陷入死循环(不断重复同一个词句)可能发生在极端高或极端低的温度设定下,但原因截然不同。在低温度下,模型变得过于确定,僵化地坚持“概率最高路径”,一旦路径闭环,就会陷入死循环;而在极高温度下,输出变得极其随机,由于搜索空间巨大,模型可能在概率碰撞中偶然“撞回”之前的状态,从而引发状态循环。
此外,即使你将温度设为0(贪婪解码),AI也不一定是绝对确定性的,因为当两个词概率完全相同时,模型内部的“平局处理”机制仍可能导致微小的输出差异。
专家推荐的“黄金配置”起始点:
- 平衡模式: Temp 0.2, Top-P 0.95, Top-K 30(适用于大多数逻辑任务)。
- 创意模式: Temp 0.9, Top-P 0.99, Top-K 40。
- 精确模式: 对于数学或单一答案任务,请直接将 Temp 设为 0。
Gemini 的采样控制与机器学习中的 softmax 函数极为相似:低温度强调单一路径的确定性,而高温度则允许在更广泛的可能范围内进行采样,以容纳不确定性。
3. 真相二:退后一步,反而能更快抵达终点(后退式提示)
当我们要求AI处理极其具体的任务时,它往往会因为直接跳入细节而忽略了全局逻辑。**后退式提示(Step-back Prompting)**的核心在于:在解决具体问题前,先引导模型思考一个更宽泛、更通用的原则。
这种技术的精妙之处在于**“参数激活”**。通过先问一个通用的背景问题,模型能够激活其内部参数中原本处于休眠状态的相关背景知识,从而建立更稳固的推理框架。
案例分析:视频游戏关卡设计
- 传统提示词: “为第一人称射击游戏写一个具有挑战性的关卡剧情。”(结果通常流于表面)。
- 后退式提示词:
- 第一步: “基于热门射击游戏,哪些关键设定能贡献出具有挑战性和参与感的关卡剧情?”(模型可能会列出:废弃基地、赛博朋克城市、水下设施等要素)。
- 第二步: “基于以上要素,写一个剧情。”
这种方法不仅能显著减少AI的偏见,还能让生成的回答具备更高的准确性和逻辑深度。
4. 真相三:AI也会“算错账”?逻辑链条的力量(CoT)
思维链(Chain of Thought, CoT) 是提示词架构中最重要的工具。由于LLM本质上是预测下一个 token 出现的概率,而非运行严密的算术逻辑,因此在处理需要多步推理的问题时经常翻车。
数学翻车案例: 如果你问:“我3岁时伙伴年龄是我的3倍。现在我20岁,我伙伴几岁?” 没有CoT的AI可能会直接回答:“63岁!”(它错误地应用了 20 × 3 的概率关联)。
CoT的修正逻辑: 通过在指令中加入**“让我们一步步思考”**,AI会强制进入逻辑分步模式:
- 3岁时伙伴是 3 × 3 = 9岁。
- 年龄差是 9 - 3 = 6岁且恒定。
- 现在 20 岁,伙伴是 20 + 6 = 26岁。
CoT的架构价值在于它赋予了模型**“可解释性”,更重要的是,研究表明 CoT 能提高模型在不同版本更迭时的稳健性(Robustness)**。这意味着带有推理链的提示词在模型升级时更不容易失效。
5. 真相四:少说“不”,多说“做”(指令优于约束)
在提示词架构设计中,正向指令(Instruction)的效果远好于负向约束(Constraint)。
底层的“Token 路径”逻辑 当你使用负向约束(如“不要列出游戏名称”)时,你实际上是在增加模型决策时的“概率不确定性”,因为它知道不能做什么,但不知道确切该往哪条路径走。过多的约束往往会导致指令冲突,导致输出质量雪崩。相反,正向指令直接为模型划定了清晰的“Token 路径”。
错误(仅负向约束) 正确(正向指令)
不要列出视频游戏名称。 仅讨论控制台、制造商、年份和总销量。
不要写得太长。 将解释限制在推文长度(140字符)之内。
明确的目标不仅符合人类的沟通偏好,更能让AI在定义的边界内发挥最大的创造力。
6. 真相五:从对话到行动——ReAct模式的崛起
提示词工程正从简单的“文本交互”进化为**“ReAct(推理与行动)”**范式。这是通往“AI Agent(智能体)”的必经之路。
ReAct 模式模仿人类解决复杂问题的过程:思考(Thought)- 行动(Action)- 观察(Observation)。通过将 LLM 与外部 API(如 SerpAPI 搜索引擎)连接,AI 能够突破其预训练数据的实时性限制。
案例研究:查询 Metallica 乐队成员的孩子总数 在 ReAct 范式下,AI 不会瞎编,而是通过以下循环:
- 思考: 我需要先确定乐队成员名单。
- 行动: 调用搜索 API(Scraping)抓取“Metallica 成员”。
- 观察: 获得名单。
- 思考/行动: 分别搜索每位成员的孩子数量并进行数学求和。
这种模式通过模拟人类处理现实问题的逻辑,在复杂任务的处理上表现优于任何单一的提示词工程方法。
7. 总结:掌握迭代的艺术
提示词工程绝非一蹴而就,而是一个严密的工程化过程。要像架构师一样工作,你必须建立自己的“提示词日志”。
核心建议:文档化(Documentation) 不要只在对话框里盲目调试。建议使用以下 8 个关键字段记录你的每一次实验:
- Name: 提示词名称与版本。
- Goal: 本次尝试的一句话目标。
- Model: 使用的模型名称与版本。
- Temperature: 随机性设定(0-1)。
- Token Limit: 输出长度限制。
- Top-K: 采样范围设定。
- Top-P: 核采样设定。
- Prompt & Output: 完整的输入与输出记录。
通过这种结构化的迭代,你不仅是在对话,而是在构建一个可预测、可扩展的智能系统。
如果未来的 AI 不再仅仅是回答问题,而是开始根据你的提示独立行动,你准备好给它下达第一个正确的指令了吗?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)