Tool-to-Agent Retrieval 论文深度解读:构建可扩展的LLM多智能体系统
本文提出Tool-to-Agent Retrieval框架,解决LLM多智能体系统中的工具路由问题。该方法将工具和智能体统一嵌入共享向量空间,通过元数据连接二者,实现细粒度检索。相比传统层次路由方法,该框架能同时保留工具级精度和智能体级上下文,在LiveMCPBench基准测试中Recall@5提升17.7%,nDCG@5提升19.4%。实验表明,该方法在不同嵌入模型上均保持性能提升,为复杂任务的
论文标题: Tool-to-Agent Retrieval: Bridging Tools and Agents for Scalable LLM Multi-Agent Systems
作者: Elias Lumer, Faheem Nizar, Anmol Gulati, Pradeep Honaganahalli Basavaraju, Vamse Kumar Subbiah (PwC美国)
论文链接: arXiv:2511.01854
发表时间: 2025年11月
一、背景与动机
1.1 问题的提出
随着大型语言模型(LLM)多智能体系统的快速发展,现代AI助手已经能够协调数百甚至数千个MCP服务器或工具。想象一下,你有一个智能助手,它可以帮你写代码、查数据库、搜索网页、发送邮件...每个任务都由专门的"子助手"(子智能体)来处理,而每个子助手又掌握着几十个具体的工具。
🌰 举个例子: 假设你说:"帮我分析上个月的销售数据,生成一份报告并邮件发给团队"。这个请求可能需要:
- 数据库智能体: 连接销售数据库,提取数据
- 数据分析智能体: 进行统计分析
- 文档生成智能体: 创建报告
- 邮件智能体: 发送邮件
每个智能体可能包含多个工具(如SQL查询工具、图表生成工具、PDF导出工具等)。
1.2 核心挑战:路由问题
这就引出了一个关键问题:给定用户查询,系统应该选择特定工具,还是利用整个智能体(如MCP服务器)?
现有方法的困境:
| 方法 | 问题 |
|---|---|
| Agent-first(智能体优先) | 只匹配智能体级别的粗略描述,可能隐藏高度相关的工具 |
| Tool-only(仅工具) | 独立处理每个工具,忽略多步骤任务中工具组合的协同效应 |
🌰 具体例子:
假设有一个"邮件智能体",它的描述是"提供邮件相关功能"。它包含以下工具:
send_email: 发送邮件schedule_email: 定时发送邮件create_template: 创建邮件模板track_opens: 追踪邮件打开率
Agent-first的问题: 用户查询"帮我设置明天早上8点发送会议提醒",系统只看到"邮件智能体"的粗略描述"提供邮件相关功能",可能无法识别这个智能体包含schedule_email这个精确匹配的工具。
Tool-only的问题: 用户查询"分析销售数据并生成可视化报告",需要多个智能体的协同工作。如果只检索单个工具,可能只找到数据分析工具,却忽略了报告生成和可视化工具,导致任务无法完整完成。
1.3 上下文稀释问题
论文指出了一个更深层的问题:上下文稀释。
🌰 例子: 一个MCP服务器有26个工具,把所有工具描述一起发送给模型会消耗超过4,600个token!这不仅昂贵,而且会让模型"眼花缭乱",难以准确选择。
二、核心贡献
2.1 三大创新点
论文提出了Tool-to-Agent Retrieval框架,实现了三个核心贡献:
贡献1: 统一检索框架
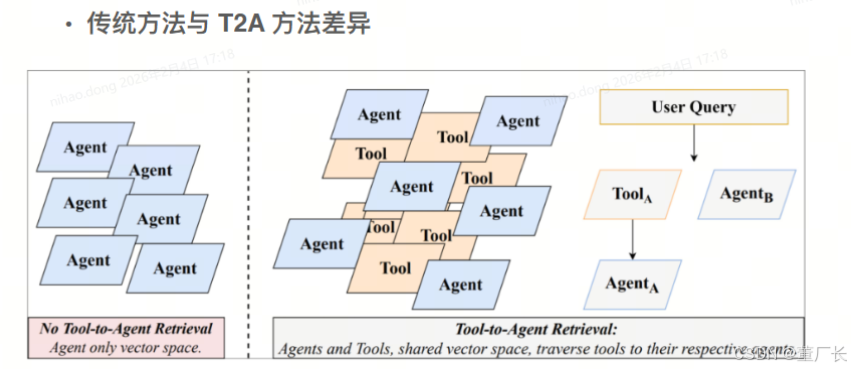
将工具和其父智能体嵌入到共享的向量空间中,通过元数据关系连接它们,实现统一检索。
这是什么意思?
想象一个图书馆:
- 传统方法: 要么只检索书名(智能体级别),要么只检索章节(工具级别)
- Tool-to-Agent: 同时索引书名和章节,并记录它们之间的关系。当你搜索"机器学习"时,系统可以返回整本书,也可以返回具体讲"神经网络"的章节
贡献2: 细粒度路由机制
保留工具级别的细粒度细节,同时保留智能体级别的上下文,缓解粗略摘要带来的上下文稀释问题。
关键洞察: 不是简单地把所有工具压缩成一个智能体描述,而是让每个工具都能被独立检索,同时保留"这个工具属于哪个智能体"的信息。
贡献3: 全面评估
在LiveMCPBench基准上使用8种嵌入模型进行评估,相比之前的最先进方法,Recall@5提升17.7%,nDCG@5提升19.4%。
三、方法详解
3.1 问题建模
论文将整个系统建模为一个二分图:
G = (A, T, E)
- A: 智能体(Agents)集合,如不同的MCP服务器
- T: 工具(Tools)集合,如API调用、函数、动作
- E: 边,表示工具与智能体之间的所有权关系
🌰 可视化例子:
┌─────────────────┐
│ 邮件智能体 │
│ (Agent A1) │
└────────┬────────┘
│
┌────────────────┼────────────────┐
│ │ │
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ send_email │ │schedule_email│ │create_template│
│ (Tool t1) │ │ (Tool t2) │ │ (Tool t3) │
└──────────────┘ └──────────────┘ └──────────────┘
3.2 索引构建
系统构建一个统一的工具-智能体目录 C,包含两个子集:
工具语料库 C_T
- 包含工具名称和描述
- 每个工具条目包含元数据,明确链接到其父智能体
- 表示为:
owner(T) = A
🌰 具体例子:
{
"tool_id": "schedule_email",
"name": "Schedule Email",
"description": "Schedule an email to be sent at a specific time",
"owner": "email_agent", // ← 关键:链接到父智能体
"parameters": {
"recipient": "string",
"subject": "string",
"body": "string",
"send_time": "datetime"
}
}
智能体语料库 C_A
- 包含智能体名称和描述
- 代表更高级别的能力
- 在检索图中作为父节点
{
"agent_id": "email_agent",
"name": "Email Agent",
"description": "Provides comprehensive email functionality including sending, scheduling, templates, and tracking",
"tools": ["send_email", "schedule_email", "create_template", "track_opens"]
}
3.3 检索流程(核心算法)
论文提出了组合式工具-智能体Top-K检索算法(Algorithm 1):
输入: 查询q, 语料库C(智能体∪工具), 类型函数τ(·), 所有者映射own(·), 相似度s(q,·), 截断值N,K
输出: K个最相关的智能体集合A*
1. 从统一目录C中检索Top-N个实体(按语义相似度排序)
2. 初始化空集合A
3. 遍历Top-N列表中的每个实体e:
- 如果e是智能体: 直接加入A
- 如果e是工具且有所属智能体: 找到其所有者智能体,加入A
- 如果e是工具但没有所有者: 跳过
4. 返回A中的前K个唯一智能体
🌰 完整执行例子:
假设用户查询: "设置明天早上8点发送会议提醒"
步骤1: 语义检索Top-N(N=10)
| 排名 | 实体 | 类型 | 相似度 | 所有者 |
|---|---|---|---|---|
| 1 | schedule_email |
工具 | 0.92 | 邮件智能体 |
| 2 | send_email |
工具 | 0.85 | 邮件智能体 |
| 3 | create_reminder |
工具 | 0.83 | 日历智能体 |
| 4 | 邮件智能体 | 智能体 | 0.80 | - |
| 5 | set_alarm |
工具 | 0.78 | 时钟智能体 |
| 6 | create_template |
工具 | 0.75 | 邮件智能体 |
| 7 | 日历智能体 | 智能体 | 0.72 | - |
| 8 | track_opens |
工具 | 0.68 | 邮件智能体 |
| 9 | send_notification |
工具 | 0.65 | 通知智能体 |
| 10 | schedule_meeting |
工具 | 0.62 | 会议智能体 |
步骤2: 聚合到智能体级别(K=3)
遍历列表,提取唯一智能体:
schedule_email→ 邮件智能体 ✓(第1个)send_email→ 邮件智能体 ✗(已存在)create_reminder→ 日历智能体 ✓(第2个)- 邮件智能体 → 邮件智能体 ✗(已存在)
set_alarm→ 时钟智能体 ✓(第3个)
最终结果: [邮件智能体, 日历智能体, 时钟智能体]
关键优势:
- 即使排名第1的是工具,我们也能找到它的父智能体
- 避免了只返回智能体而错过精确工具匹配的问题
- 同时保留了智能体级别的上下文信息
3.4 查询策略
论文评估了两种查询范式:
直接查询(Direct Querying)
- 直接使用用户的高级问题作为检索查询
- 不进行预处理
- 适合简单、单一意图的查询
🌰 例子:
- 用户: "发送邮件给张三"
- 检索: 直接使用"发送邮件给张三"
逐步查询(Step-wise Querying)
- 将原始查询分解为一系列子任务
- 每个步骤独立提交给检索器
- 适合复杂、多步骤的查询
🌰 例子:
- 用户: "分析上个月的销售数据,生成报告并邮件发给团队"
- 分解:
- "提取上个月销售数据" → 数据库智能体
- "分析销售数据趋势" → 数据分析智能体
- "生成销售报告" → 文档智能体
- "发送邮件给团队" → 邮件智能体
四、实验与评估
4.1 数据集
LiveMCPBench:
- 70个MCP服务器
- 527个工具
- 95个真实世界问题
- 每个问题平均2.68个步骤
- 每个问题涉及2.82个工具和1.40个MCP智能体
🌰 数据集例子:
{
"question": "查询我下周的会议安排,找出与项目评审相关的会议,并发送提醒邮件给参会者",
"steps": [
{
"step": "查询下周日历",
"tools": ["query_calendar"],
"agent": "calendar_agent"
},
{
"step": "筛选项目评审会议",
"tools": ["filter_events"],
"agent": "calendar_agent"
},
{
"step": "获取参会者列表",
"tools": ["get_attendees"],
"agent": "calendar_agent"
},
{
"step": "发送提醒邮件",
"tools": ["send_email"],
"agent": "email_agent"
}
]
}
4.2 评估指标
| 指标 | 全称 | 含义 |
|---|---|---|
| Recall@K | Recall at K | 前K个结果中正确检索的比例 |
| mAP@K | mean Average Precision at K | 平均精确率的均值 |
| nDCG@K | normalized Discounted Cumulative Gain at K | 归一化折损累计增益,考虑排序质量 |
🌰 Recall@5的解释:
假设一个查询需要3个智能体:[邮件智能体, 日历智能体, 数据分析智能体]
系统返回的Top-5: [邮件智能体, 日历智能体, 通知智能体, 文档智能体, 数据分析智能体]
Recall@5 = 2/3 = 0.67(因为只找到了2个正确的:邮件和日历,数据分析虽然也在但位置靠后)
4.3 主要结果
表1: 与基线方法的对比
| 方法 | Recall@1 | Recall@3 | Recall@5 | nDCG@5 |
|---|---|---|---|---|
| BM25 | 0.20 | 0.20 | 0.20 | 0.14 |
| Q.Retrieval | 0.31 | 0.47 | 0.56 | 0.32 |
| MCPZero | 0.44 | 0.66 | 0.70 | 0.41 |
| ScaleMCP | 0.49 | 0.68 | 0.74 | 0.40 |
| Tool-to-Agent | 0.61 | 0.77 | 0.83 | 0.46 |
关键发现:
- Recall@5从0.74提升到0.83,相对提升12.2%
- nDCG@5从0.41提升到0.46,相对提升12.2%
- 相比最强的基线ScaleMCP,Recall@5提升19.4%,nDCG@5提升17.7%
表2: 跨嵌入模型的性能(对比MCPZero)
| 嵌入模型 | Recall@5 ( ours ) | Recall@5 ( MCPZero ) | 提升 |
|---|---|---|---|
| Vertex AI text-embedding-005 | 0.87 | 0.74 | +17.6% |
| Gemini Embedding 001 | 0.86 | 0.74 | +16.2% |
| Amazon Titan v2 | 0.85 | 0.66 | +28.8% |
| OpenAI text-embedding-3-large | 0.87 | 0.74 | +17.6% |
| All-MiniLM-L6-v2 | 0.80 | 0.67 | +19.4% |
关键洞察:
- 提升在不同嵌入模型上一致存在
- 即使是开源模型(MiniLM)也能达到接近商业模型的性能
- 说明方法本身的鲁棒性,不依赖于特定的嵌入模型
4.4 为什么有效?
论文分析了检索结果的组成:
- 39.13% 的Top-K检索结果直接来自智能体语料库 C_A
- 34.44% 匹配的Top-K工具也追溯到智能体语料库
这意味着:
- 联合索引不仅支持细粒度的工具匹配
- 还保留了智能体级别的上下文
- 实现了工具级精度和智能体级上下文的平衡
五、相关工作对比
5.1 工具检索的发展
| 研究方向 | 代表工作 | 核心思想 |
|---|---|---|
| 基础工具检索 | ToolLLM, APIBench | 嵌入工具描述,选择Top-K工具 |
| 混合检索 | PLUTO, Re-Invoke | 结合语义和词汇匹配 |
| 图结构方法 | ToolNet, ControlLLM | 用图组织工具关系 |
| 迭代方法 | ToolReAGT, ProTIP | 逐步分解复杂任务 |
| 层次路由 | ScaleMCP, MCPZero | 先选MCP服务器,再选工具 |
5.2 Tool-to-Agent的独特之处
与层次路由方法的区别:
| 特性 | 层次路由 (ScaleMCP/MCPZero) | Tool-to-Agent |
|---|---|---|
| 决策方式 | 两阶段:先选智能体,再选工具 | 单阶段:同时在工具和智能体上检索 |
| 灵活性 | 必须预先承诺智能体选择 | 不需要预先承诺,动态决定 |
| 细粒度 | 可能错过工具级匹配 | 保留工具级细节 |
| 上下文 | 智能体描述可能稀释工具信息 | 通过元数据链接保留上下文 |
🌰 对比例子:
用户查询: "设置定时邮件提醒"
层次路由的问题:
- 第一阶段:看智能体描述
- "邮件智能体": "提供邮件功能" → 匹配度一般
- "日历智能体": "管理日程和提醒" → 匹配度更高
- 选择日历智能体
- 第二阶段:在日历智能体中找工具
- 发现没有"邮件"相关工具
- 失败!
Tool-to-Agent的优势:
- 同时在工具和智能体上检索
- 发现
schedule_email工具(邮件智能体)匹配度最高 - 直接返回邮件智能体
- 成功!
六、实际应用价值
6.1 适用场景
- 企业级AI助手: 协调多个部门系统(HR、财务、IT等)
- 开发工具集成: 连接IDE、版本控制、CI/CD等
- 智能家居中枢: 统一控制不同品牌的智能设备
- 医疗辅助系统: 整合电子病历、影像系统、药品数据库
6.2 实施建议
步骤1: 构建工具-智能体图谱
# 伪代码示例
tool_agent_graph = {
"agents": {
"email_agent": {
"description": "邮件功能",
"tools": ["send_email", "schedule_email"]
}
},
"tools": {
"schedule_email": {
"description": "定时发送邮件",
"owner": "email_agent"
}
}
}
步骤2: 统一嵌入
- 使用相同的嵌入模型处理工具和智能体描述
- 确保它们在同一个向量空间中
步骤3: 实现检索算法
- 先检索Top-N(N >> K)
- 遍历并聚合到智能体级别
- 返回Top-K唯一智能体
步骤4: 查询分解(可选)
- 对复杂查询使用LLM分解为子任务
- 每个子任务独立检索
七、局限性与未来方向
7.1 当前局限
- 依赖嵌入质量: 如果工具描述写得不好,检索效果会下降
- 静态图谱: 没有考虑工具之间的动态依赖关系
- 查询分解: 论文假设查询已经分解好,实际应用中需要额外的分解步骤
7.2 未来研究方向
- 动态图谱更新: 根据使用频率和反馈动态调整工具-智能体关系
- 多跳推理: 支持跨智能体的复杂工作流
- 个性化路由: 根据用户历史偏好调整检索策略
- 实时学习: 从新工具和用户反馈中持续学习
八、核心概念速查表
| 术语 | 英文 | 解释 |
|---|---|---|
| LLM | Large Language Model | 大型语言模型,如GPT、Claude |
| MCP | Model Context Protocol | 模型上下文协议,标准化AI与外部工具的连接 |
| 多智能体系统 | Multi-Agent Systems | 多个协作智能体组成的系统 |
| 上下文稀释 | Context Dilution | 大量信息压缩导致重要细节丢失 |
| 二分图 | Bipartite Graph | 顶点分为两个集合,边只连接不同集合的图 |
| Recall@K | Recall at K | 前K个结果中正确检索的比例 |
| nDCG@K | normalized DCG at K | 考虑排序质量的评估指标 |
| RAG | Retrieval-Augmented Generation | 检索增强生成,结合检索和生成的技术 |
| 嵌入模型 | Embedding Model | 将文本转换为向量的模型 |
| 语义相似度 | Semantic Similarity | 基于向量空间中的距离衡量文本相似性 |
九、总结
Tool-to-Agent Retrieval通过将工具和智能体统一嵌入到共享向量空间,解决了LLM多智能体系统中的关键路由问题。其核心创新在于:
- 统一表示: 工具和智能体在同一空间,通过元数据链接
- 灵活路由: 不需要预先承诺工具-only或智能体-first
- 细粒度保留: 避免上下文稀释,保留工具级细节
- 实证有效: 在8种嵌入模型上 consistently 提升17-19%
一句话总结:
就像图书馆既让你搜索书名也让你搜索章节,并告诉你章节属于哪本书——Tool-to-Agent Retrieval让AI助手既能找到精确的工具,也知道这个工具属于哪个智能体,从而实现更智能、更灵活的任务路由。
十、延伸阅读
相关论文:
- ScaleMCP: 动态MCP工具同步
- MCPZero: 自主工具发现
- ToolNet: 通过工具图连接LLM
- Graph RAG-Tool Fusion: 图检索与工具融合
开源资源:
本文是对论文《Tool-to-Agent Retrieval: Bridging Tools and Agents for Scalable LLM Multi-Agent Systems》的深度解读。如有理解偏差,请以原论文为准。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)