小参数也能 “卷” 赢大模型?阿里 Qwen3-Coder-Next:编程智能体的效率革命
阿里推出轻量级开源编程模型Qwen3-Coder-Next,采用混合注意力+MoE架构,仅激活3B参数却性能出色。该模型通过智能体专属训练流程提升能力,在多项编程基准测试中表现优异,性能接近更大参数模型。其"性能-效率"平衡突出,适合本地部署编程智能体,可应用于Web开发、终端操作等多种场景。目前已在ModelScope和HuggingFace开源,支持研究和商业用途。
最近阿里通义千问团队扔出了个 “轻量猛将”——Qwen3-Coder-Next,一款专门为编程智能体和本地开发设计的开源模型。别瞅它激活参数才 3B,性能却能和一堆大参数模型掰手腕,今天咱们就拆解下这个模型,还得好好扒一扒它的性能数据图~
一、这模型啥来头?—— 轻量但能打的 “编程智能体专属选手”
Qwen3-Coder-Next 是基于 Qwen3-Next-80B-A3B-Base 构建的,但它玩了个巧:用 “混合注意力 + MoE(混合专家模型)” 的新架构,总参数虽然有 80B,但每次推理只激活 3B 参数—— 既压了显存 / 算力成本,又没丢编程能力,专门瞄准 “本地部署的编程智能体” 场景。
二、它咋练这么强?—— 不堆参数,堆 “智能体训练信号”
这模型没走 “参数越堆越大” 的老路,而是靠 “智能体专属训练流程” 提能力:
- 持续预训练:在 “代码 + 智能体” 数据上打底,夯实编程基础;
- 监督微调:用真实智能体交互轨迹优化,贴合实际开发;
- 领域专精训练:针对软件工程、Web 开发等细分领域 “开小灶”;
- 专家能力蒸馏:把多个领域专家的能力融到一个模型里,兼顾多场景和轻量部署。
关键是:训练全程结合 “可执行环境”—— 模型写的代码能跑起来,错了会从环境反馈里学,不是死记硬背静态代码。
三、数据说话!两张图看透它的实力
咱们重点扒这两张性能图,直接看懂它为啥能打:
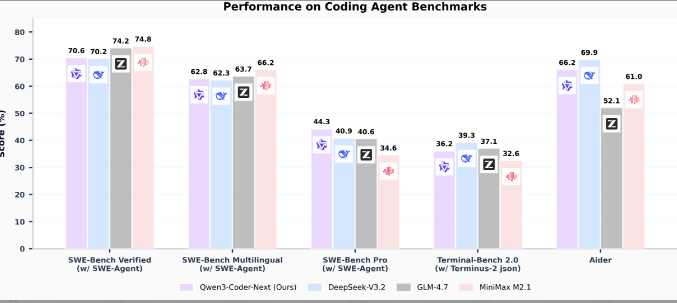
这张图是不同模型在 5 个编程智能体核心基准里的得分(越高越好),咱们逐个看 Qwen3-Coder-Next 的表现:
- SWE-Bench Verified(权威编程任务):Qwen3-Coder-Next 拿了 70.6 分,接近 GLM-4.7 的 74.8 分,还比 DeepSeek-V3.2 高一点;
- SWE-Bench Multilingual(多语言编程):62.8 分,和 DeepSeek、GLM 等模型基本持平;
- SWE-Bench Pro(更难的编程任务):44.3 分,是这几个开源模型里的最高分;
- TerminalBench 2.0(终端操作任务):36.2 分,和 DeepSeek-V3.2 的 39.2 分差得不多;
- Aider(代码辅助工具测试):66.2 分,仅次于 DeepSeek 的 69.9 分。
结论:Qwen3-Coder-Next 以 3B 的激活参数,在多个核心编程场景里,性能追平甚至超过更大参数的模型。
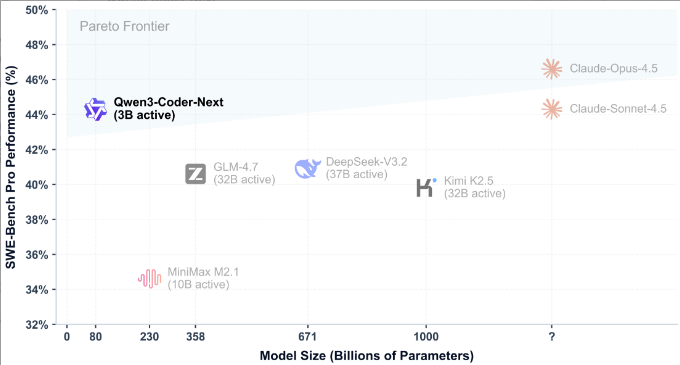
这张图是模型激活参数规模(横轴,十亿级)和 SWE-Bench Pro 性能(纵轴)的关系,重点看 “帕累托前沿”—— 这个区域的模型,是 “性能” 和 “效率(参数成本)” 的最优平衡(想提性能就得加参数,想减参数性能必降):
- Qwen3-Coder-Next(3B 激活)直接站在前沿上,性能约 44%;
- 对比其他模型:GLM-4.7(32B 激活)性能才 42%,DeepSeek-V3.2(37B 激活)只有 40%,MiniMax M2.1(10B 激活)更是只有 34%。
结论:Qwen3-Coder-Next 是 “用最少的参数换最顶的性能”,低成本部署编程智能体,它是优选。
四、能用来干啥?—— 覆盖主流开发场景的 “全能助手”
这模型能无缝集成到各种开发工具里,比如:
- Web 开发:自动生成聊天界面、可玩的网页五子棋;
- 终端操作:用自然语言清理桌面、执行命令;
- 其他场景:生成多色动画、浏览器代理搜索亚马逊产品。
甚至能 “无人工干预” 完成 “需求→代码→部署测试” 全流程 —— 比如给个 “做个网页五子棋” 的需求,它能直接交出可玩的成品。
五、能白嫖吗?—— 开源安排上了!
Qwen3-Coder-Next 已经在两大平台开源(支持研究 / 商业用):
- ModelScope:https://www.modelscope.cn/collections/Qwen/Qwen3-Coder-Next
- Hugging Face:https://huggingface.co/collections/Qwen/qwen3-coder-next
未来还会优化推理能力、扩展更多场景,迭代速度拉满~
这个轻量又能打的 Qwen3-Coder-Next,是不是已经让你心动想试试了?
END
如果觉得这份基础知识点总结清晰,别忘了动动小手点个赞👍,再关注一下呀~ 后续还会分享更多有关开发问题的干货技巧,同时一起解锁更多好用的功能,少踩坑多提效!🥰 你的支持就是我更新的最大动力,咱们下次分享再见呀~🌟

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)